

- ナレッジセンター
- 匠コラム
ネットワークが創生する価値 再考③:Data Platform のビジネス利用
- 匠コラム
- データ利活用
- AI
ビジネス開発本部 第1応用技術部
第1チーム
片野 祐
ここまでの連載ではHyper Scale Playerの動向やTelemetryによるリアルタイムなデータの取得、弊社で構築した「Telemetry PoC」の紹介をしてきました。本コラムでは「Data Platform のビジネス利用」と題して、PoCから実環境で使っていくためにどのようなことを検討しているのかについて、紹介したいと思います。
| 連載インデックス |
|---|
マネジメントツールの必要性
ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 後編 –で弊社のTelemetry PoCの概要を紹介しました。そこで紹介した特徴をおさらいすると、以下の3点が挙げられます。
Point 1:マルチベンダー対応
Point 2:Micro Service 化
Point 3:Machine Learning
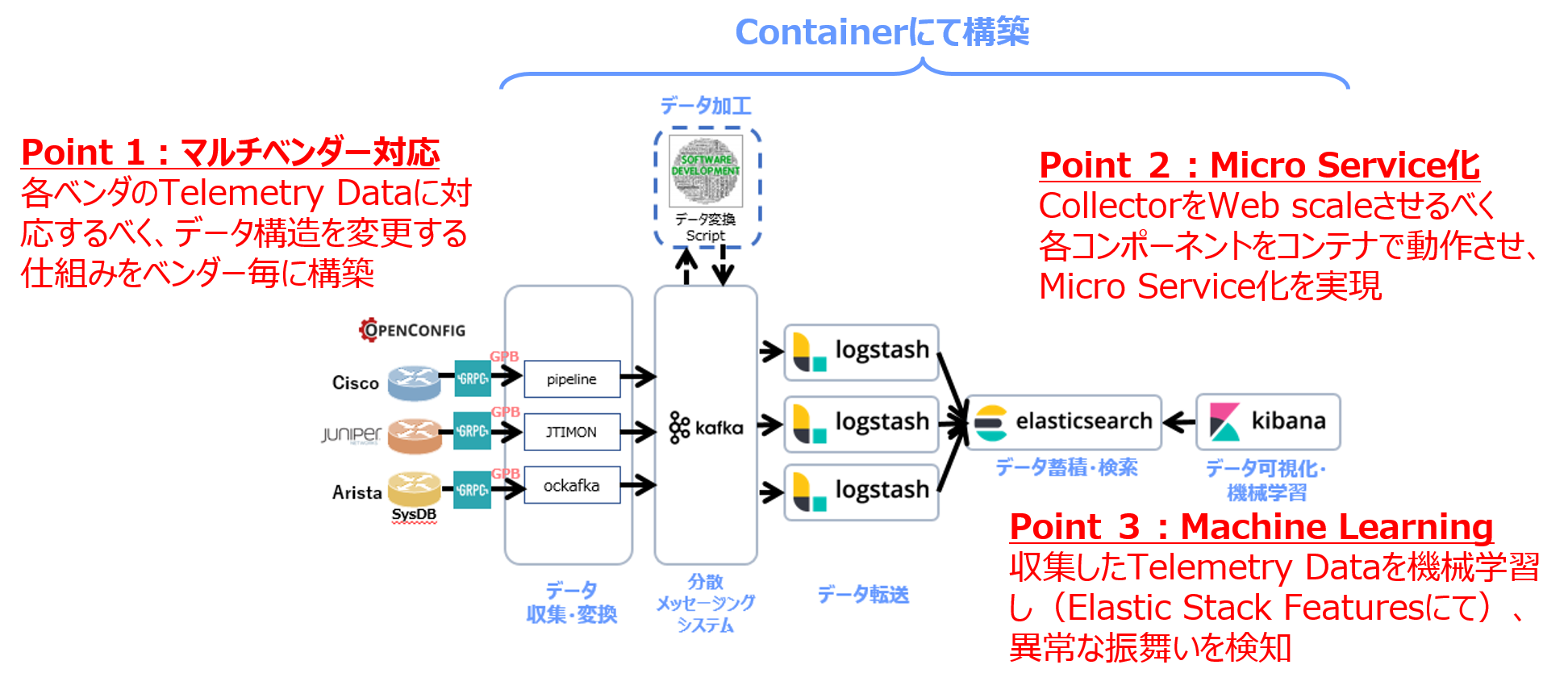
【Telemetry PoCの概要】
ネットワーク機器数の増加や保存しておくデータ容量に柔軟に対応すべく、各コンポーネントをコンテナで構築していました。番外編:OSSツールで作る、Telemetry初めの一歩で環境の構築方法を簡単に共有しましたが、各コンポーネントをDocker上で動かすのが現在の構成になっています。ネットワーク機器が増えていくにつれて、コレクター等のコンテナも増えていきますが、それらを個別に管理するのは非常に大変です。また、実環境で使うことを想定すると、何かが原因でコンテナが落ちた際に自動復旧をしてくれると、障害の影響が広がらずに済みます。そこで今回の環境ではKubernetesによる管理を始めました。
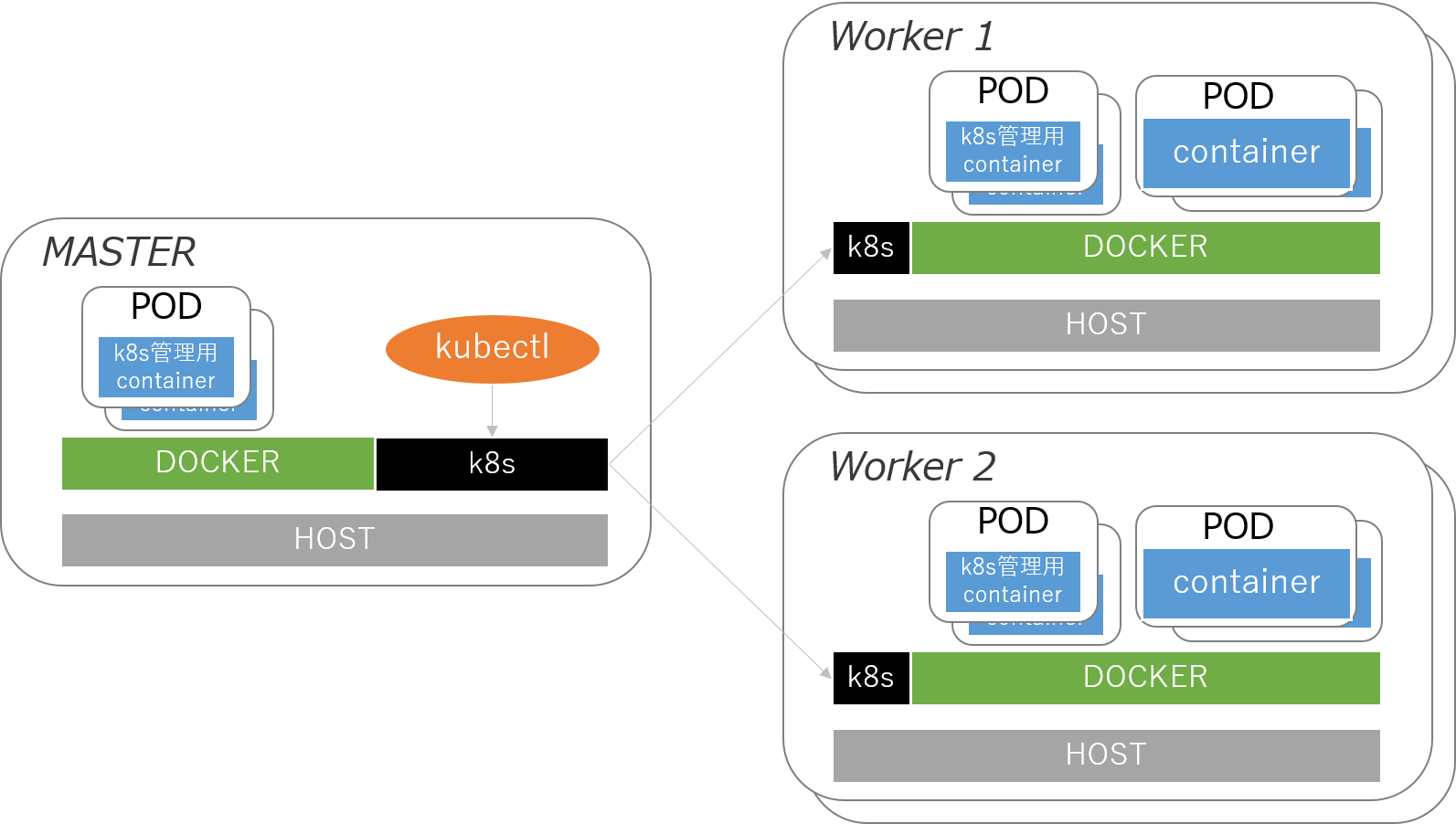
【Kubernetesによるコンテナの管理】
どこまで大きな環境まで耐えられるかについては今後検討していく必要がありますが、運用のベースとなるリソースの確認やコンテナのステータス確認が容易になりました。
Telemetry PoC自身の健全性の確認
実環境では基盤が正常に動いていることを担保する必要もあるかと思います。最近ではobservability(可観測性)という言葉もよく聞くようになりました。基盤の監視のために新たな基盤を入れるのはコスト面でも運用面でも現実的ではないように思うので、できることならTelemetry PoCと同じ基盤上で自身の監視もできるとより良いのではないでしょうか。この内容に関しては過去にコラムを公開しているので、こちらをご覧いただければと思います。
データソースの多様性
これまでの連載では特にTelemetryに注目して話を進めてきましたが、データの取得方法をすべてTelemetryで置き換える必要はないとも考えています。もちろん、リアルタイムにデータを収集、可視化を行い、過去のデータに対しても検索可能なのであれば良いですが、それを実現するには相応のデータの保管場所も必要になります。また、Telemetryに対応していない機器、OSも存在しているため、すべてをTelemetryで情報収集すると、機器すべてを変更する必要が出てくる場合もあります。それはあまり現実的ではないかもしれません。
「データの活用」という視点では、ネットワーク機器以外からもデータを取得し、組み合わせることでさらに価値を生み出すこともできるかもしれません。サーバやストレージ、それらの上で動くソフトウェアやアプリケーション等のメトリック、ログを収集することで、相関を見ることができるようになります。相関が見れると、発生した事象の原因分析に役立てたり、基盤を俯瞰して見ることができるようになります。そのため、当初の自律化ネットワークの構想に追加し、今では以下のような全体像になっています。
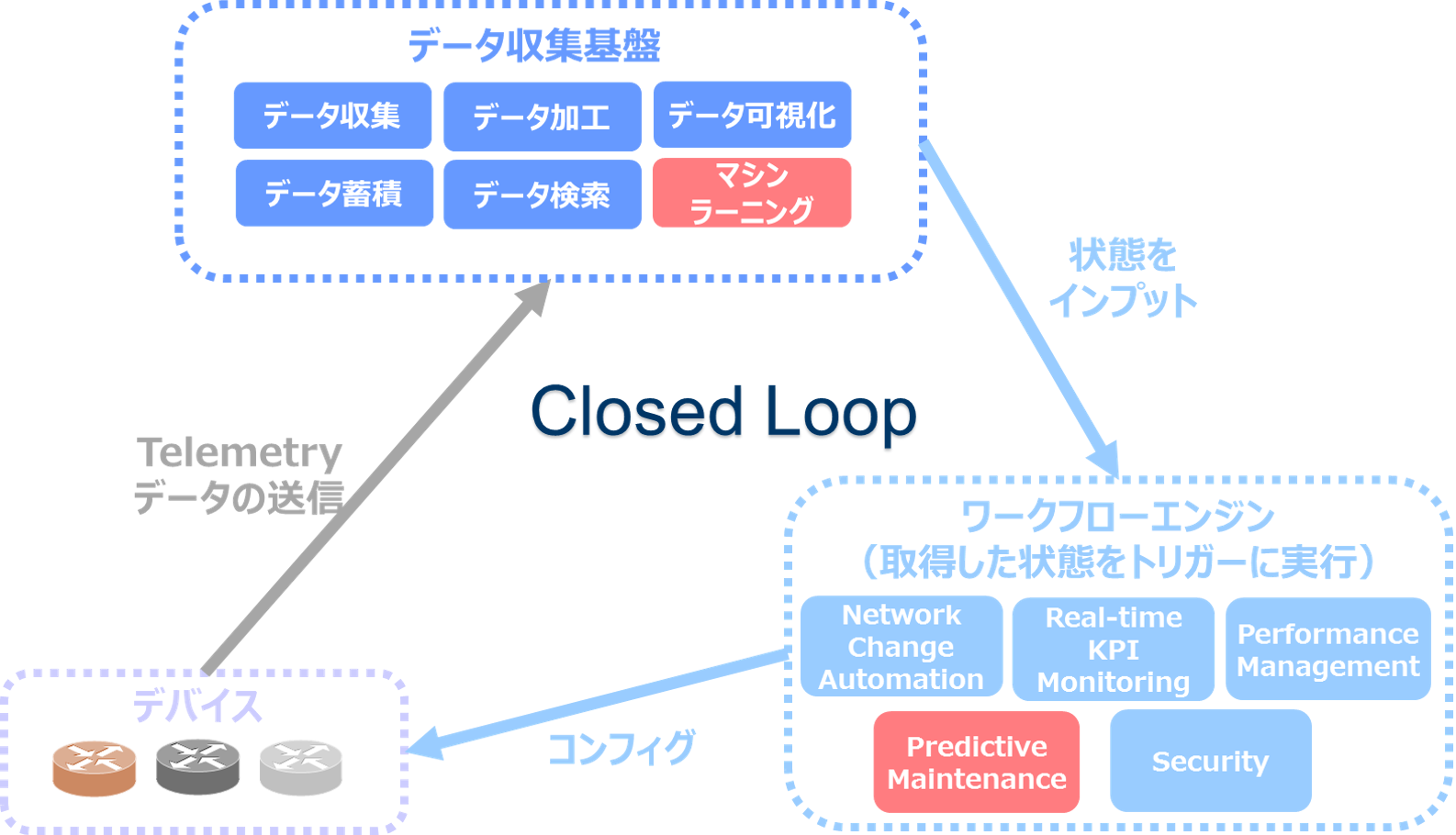
【当初の自律化ネットワークの構想】
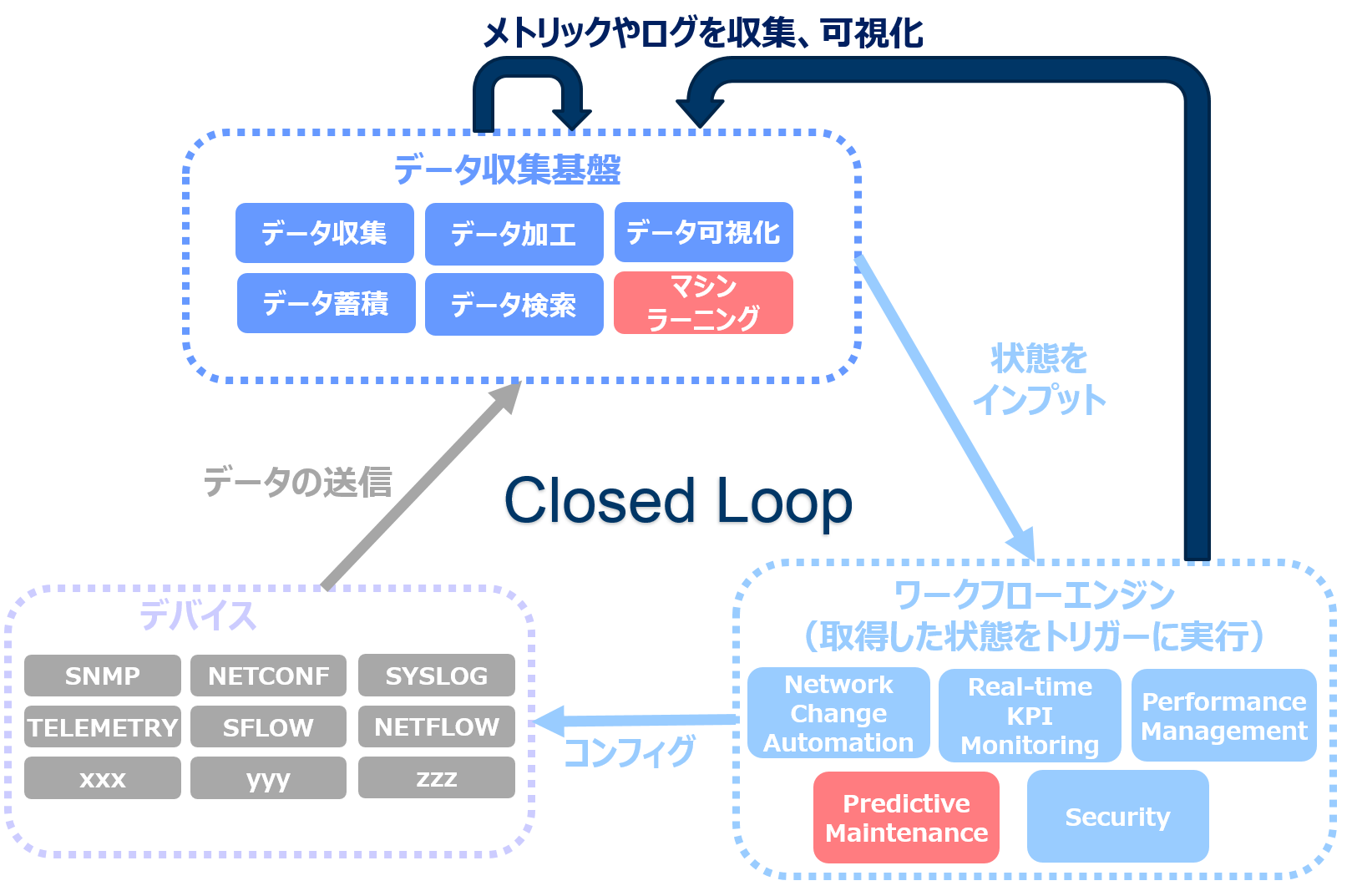
【現在の自律化ネットワークの構想】
機械学習を使うことのメリット
Machine Learningを使うことによって人間の目では気づきにくい微小な変化を捉えることができましたが、そのほかにもメリットはあります。例えば動的な閾値を使った異常検知です。
基本的な監視は今までの経験をもとに人間が定めた静的な閾値をもとに、異常を検知するものでしたが、機械学習を使って今までの振る舞いを学習しモデル化することで、人間が閾値を決めることなく、 “今までと振る舞いが異なる” (≒動的に閾値を決める)ことで異常検知ができるようになります。実際、今回のデータ収集基盤としているElastic Stackにはこの機械学習の機能が含まれているので、ネットワークの振る舞いが変わったことをトリガーに検知や通知をすることができます。これについての詳細は次回のコラムでご説明します。
機械学習を使うことで、将来の予測をすることも可能になります。ネットワーク機器のCPU使用率やメモリ使用率のほか、消費電力やファンの回転数、温度等を活用することもできるかもしれません。予測をうまく使うことで得られるメリットの例として
- リソースの枯渇を未然に防ぐことができ、拡張計画が立てやすくなる
- 機器に問題が起こる(故障する)前に交換の計画を立てられる(予知保全)
が挙げられます。Time Based MaintenanceをCondition Based Maintenanceにすることで必ずしもコスト削減につながるとは限りませんが、前持った準備ができることで余裕を持った運用ができるのではないでしょうか。
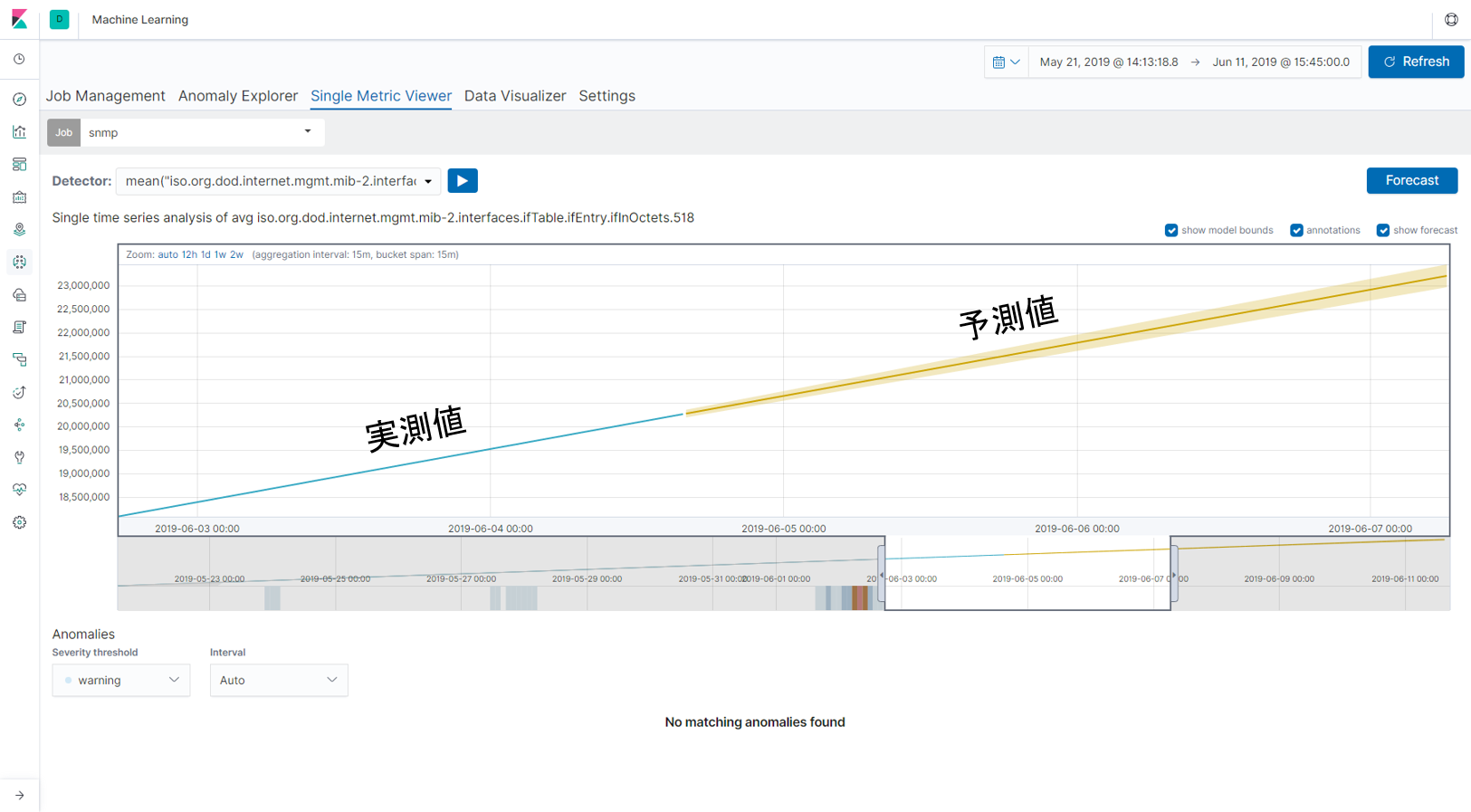
【機械学習を使った値の予測】
まとめ
本コラムではTelemetry PoCを実環境で使っていくために検討してきた内容をご紹介しました。上記の検討は完全なものではなく、実際に使っていきながら改良を加えていこうと考えています。また、当初は人間の手を介さない完全自律化を目指していましたが、実運用を考えると人間が判断する部分を残しても良いのではないか、という意見も出てきています(コンフィグ変更を実行するかしないかは人間が判断する等)。今後も更なる検討を進めていく予定です。
本コラムは概念的な紹介がメインでしたが、次回のコラムでは今回検討した、自律型ネットワークの現実解の一つであるWorkflowエンジンによる管理の自動化について、実際に動作確認をしたものを紹介します。
関連記事
- ネットワン NFV の全貌と市場への挑戦①
- ネットワン NFV の全貌と市場への挑戦②
- ネットワン NFV の全貌と市場への挑戦③
- NFV動向: NFVとOpenStack①
- NFV動向: NFVとOpenStack②
- NFV動向: NFVとOpenStack③
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 – 前編 –
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 – 後編 –
- ネットワークが創生する価値 再考①:Hyper Scale DC Architectureとその手法
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 前編 –
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 後編 –
- 番外編:OSSツールで作る、Telemetry初めの一歩 – 前編 –
- 番外編:OSSツールで作る、Telemetry初めの一歩 – 後編 –
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス開発本部
第1応用技術部 第1チーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索