

- ナレッジセンター
- 匠コラム
コンテナで構築したシステムのメトリックやログの可視化と一元管理
- 匠コラム
- データセンター
ビジネス推進本部 第1応用技術部
第1チーム
片野 祐
はじめに
システムの基盤が最初は物理マシンであったものから、仮想マシンに代わり、最近ではコンテナをベースとしたものへ移っているのではないでしょうか。私も最近までは仮想マシンベースで検証を行っていたのですが、最近の流行に乗り遅れないようにコンテナを使い始めるきっかけを探していました。そこで、弊社で取り組んできたTelemetry環境の構築(こちら や こちら)でコンテナが使われていたので、これを機にコンテナベースの検証環境を構築してみました。過去の匠コラムではDockerによる構築例が紹介されていますが、コンテナオーケストレーションツールのKubernetesも使いながら環境を作りました。本来の目的はネットワーク機器のTelemetry情報をElasticsearchに格納し、Kibanaで可視化するところにありましたが、その際いくつかのポイントでハマり、その度にメトリックやログをマシンやコンテナに入って確認する、ということに非常に時間がかかり不便だったので、それらのデータもElasticsearchに送り込み、Kibanaで見てしまおうというモチベーションのもと、実施してみました。本コラムではその可視化イメージを共有します。
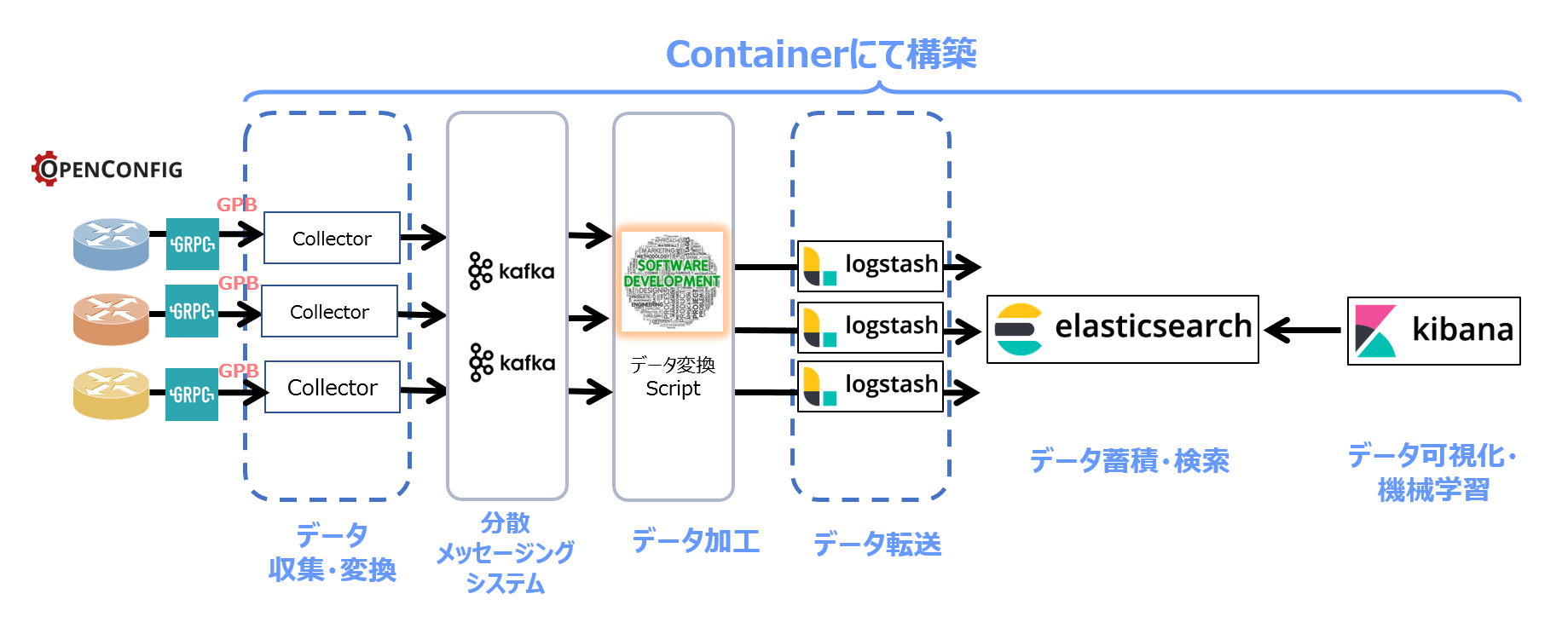
【構築したTelemetry情報収集基盤】
環境と諸注意
本コラムを書くにあたり、検証では以下のソフトウェアバージョンを使用しました。また、一部ベータ版の機能を含んでいるため、今後修正が入る場合があるのでご注意ください。Elastic Stackの概要はこちらのコラムに書かれているので、併せてご覧ください。
- Docker: 18.06.1-ce
- Kubernetes: 1.13.1
- Elasticsearch: 6.6.0
- Kibana: 6.6.0
- Metricbeat: 6.6.0
- Filebeat: 6.6.0
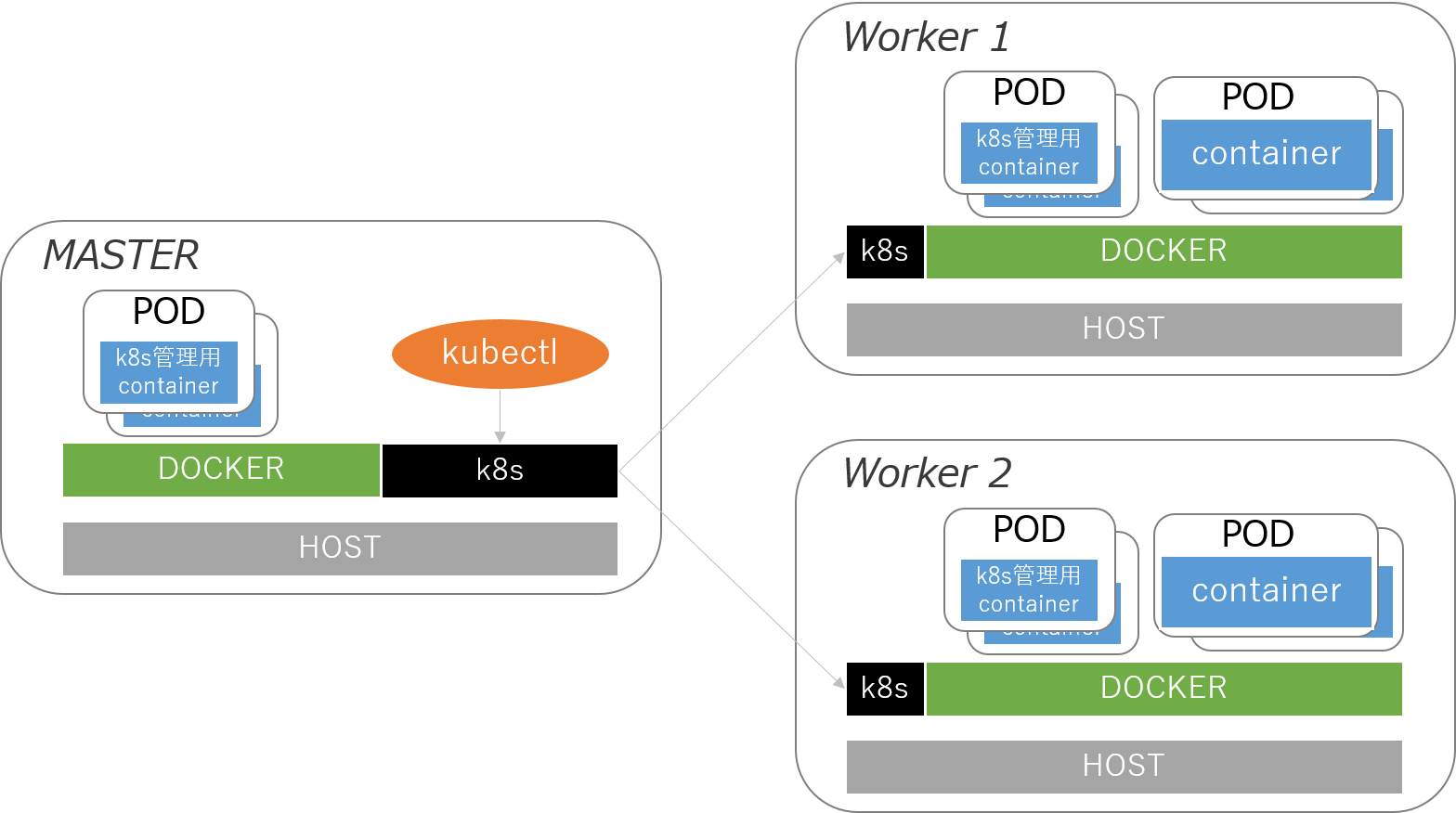
【コンテナ環境の全体像】
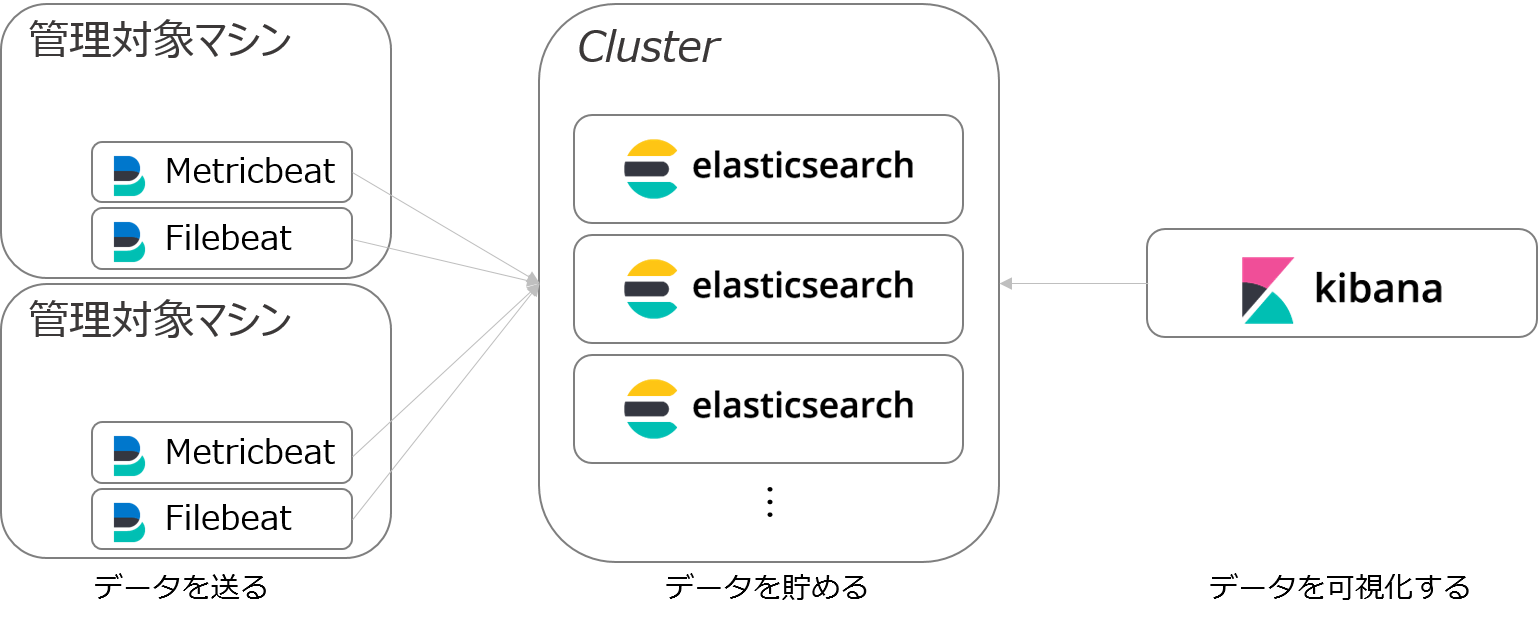
【Elastic Stackのコンポーネントの関係性】
メトリックの可視化
まずはコンテナ環境のメトリック(例:CPU使用率やMemory使用率)を可視化してみました。本環境はKubernetesで管理される1台のmaster nodeと2台のworker nodeで構成されており、それぞれのマシンのメトリックと、各コンテナのメトリックを収集しました。メトリックの収集方法はElastic社から提供されているMetricbeatというエージェントを各マシンに入れ、メトリックをElasticsearchに送るだけです。Metricbeatにはモジュールがいくつか準備されており、それを用いることで簡単に使い始めることができます。
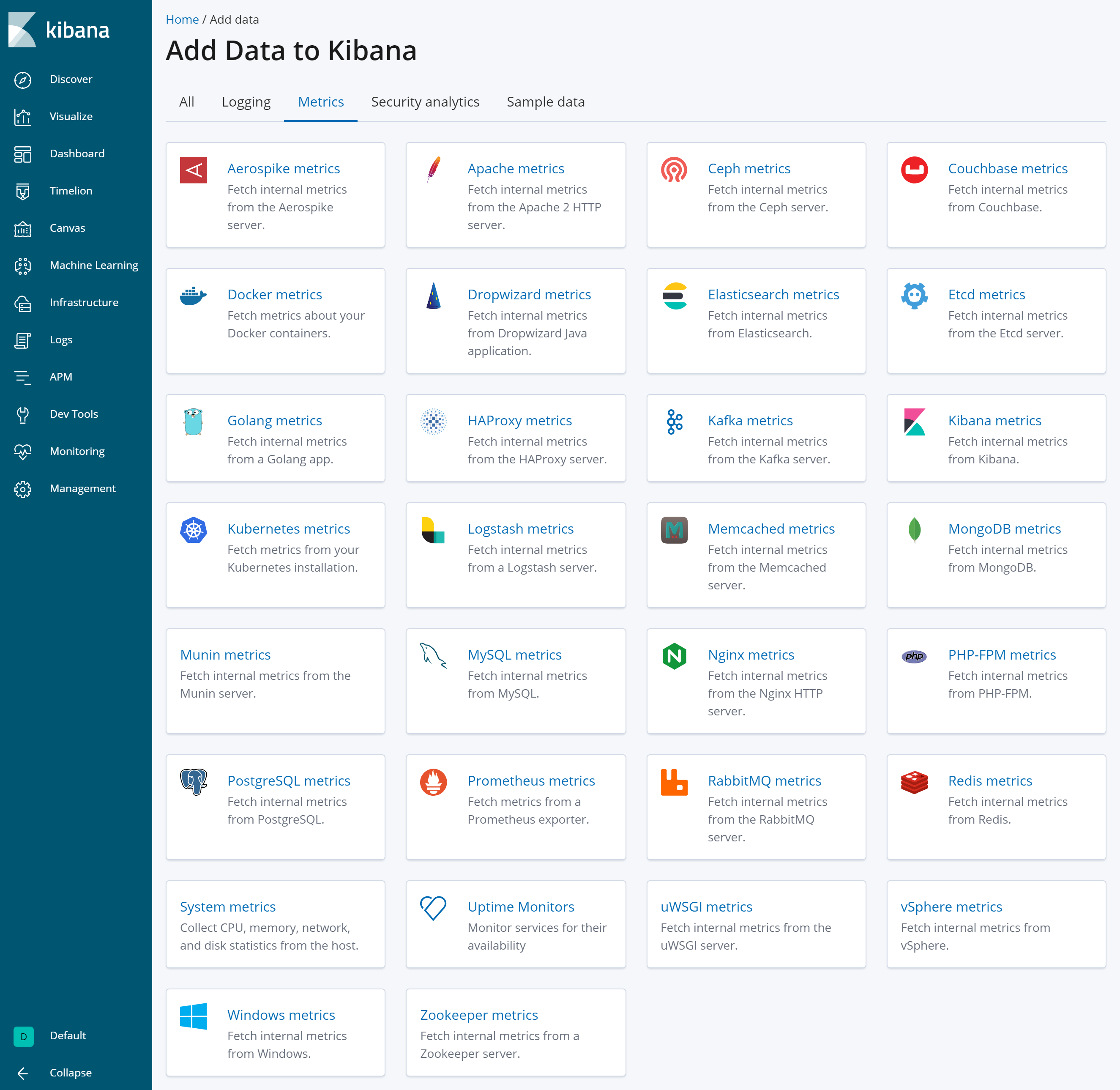
【モジュール一覧】
それぞれのモジュールを選択することで、設定の方法も確認することができます。今回はSystemモジュールとDockerモジュールを使用しています。さらにここにあるモジュールのうち、いくつかにはKibanaのダッシュボードがあらかじめ準備されており、可視化のためのダッシュボードを作る時間を短縮することができます。例えばマシンのメトリックを収集すると、システム全体の状態を俯瞰することが可能で、そこから特定のマシンにドリルダウンして詳細を確認する、というような使い方もできます。
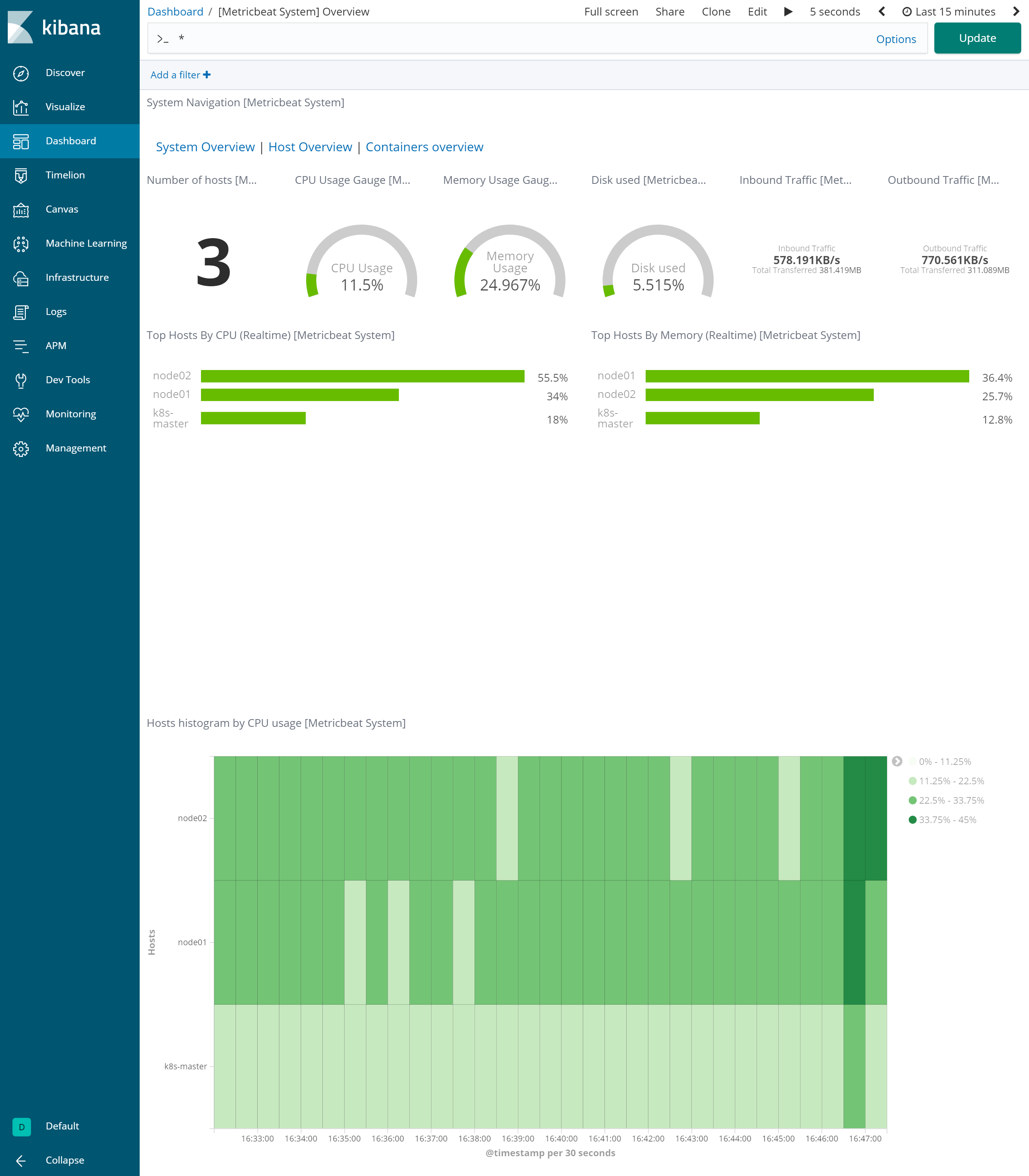
【システム全体のメトリック情報】
各マシンのCPU使用率やMemory使用率を表示し、画面下部ではCPU使用率の時系列変化を見ることができる。
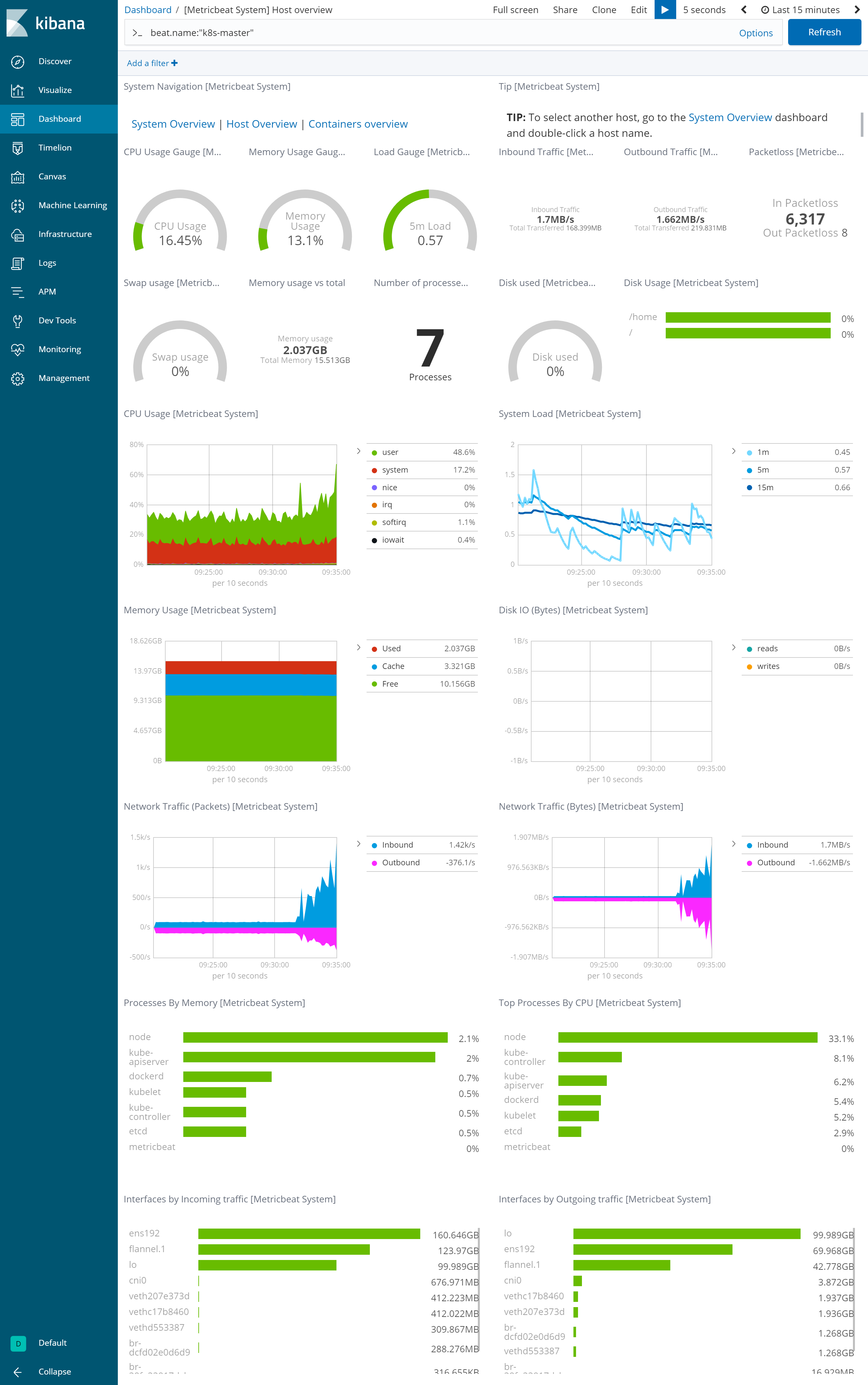
【特定のマシンのメトリック情報】
システム全体より細かく、例えばCPU使用率の内訳等を見ることができる。
Dockerモジュールを使用した場合はDockerのメトリックを収集することができるようになり、以下のようなダッシュボードが作られます。
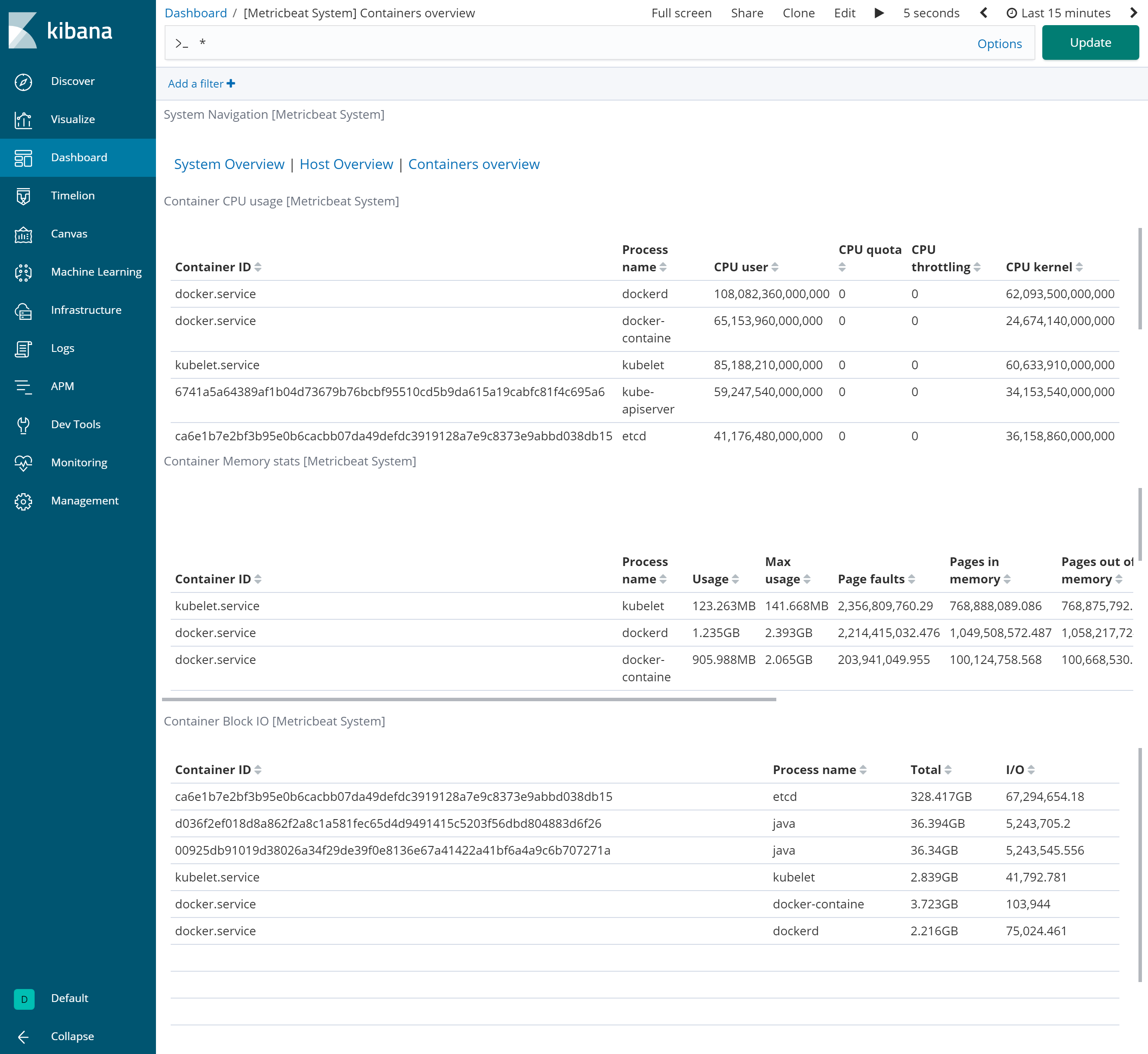
【Docker環境の全体像】
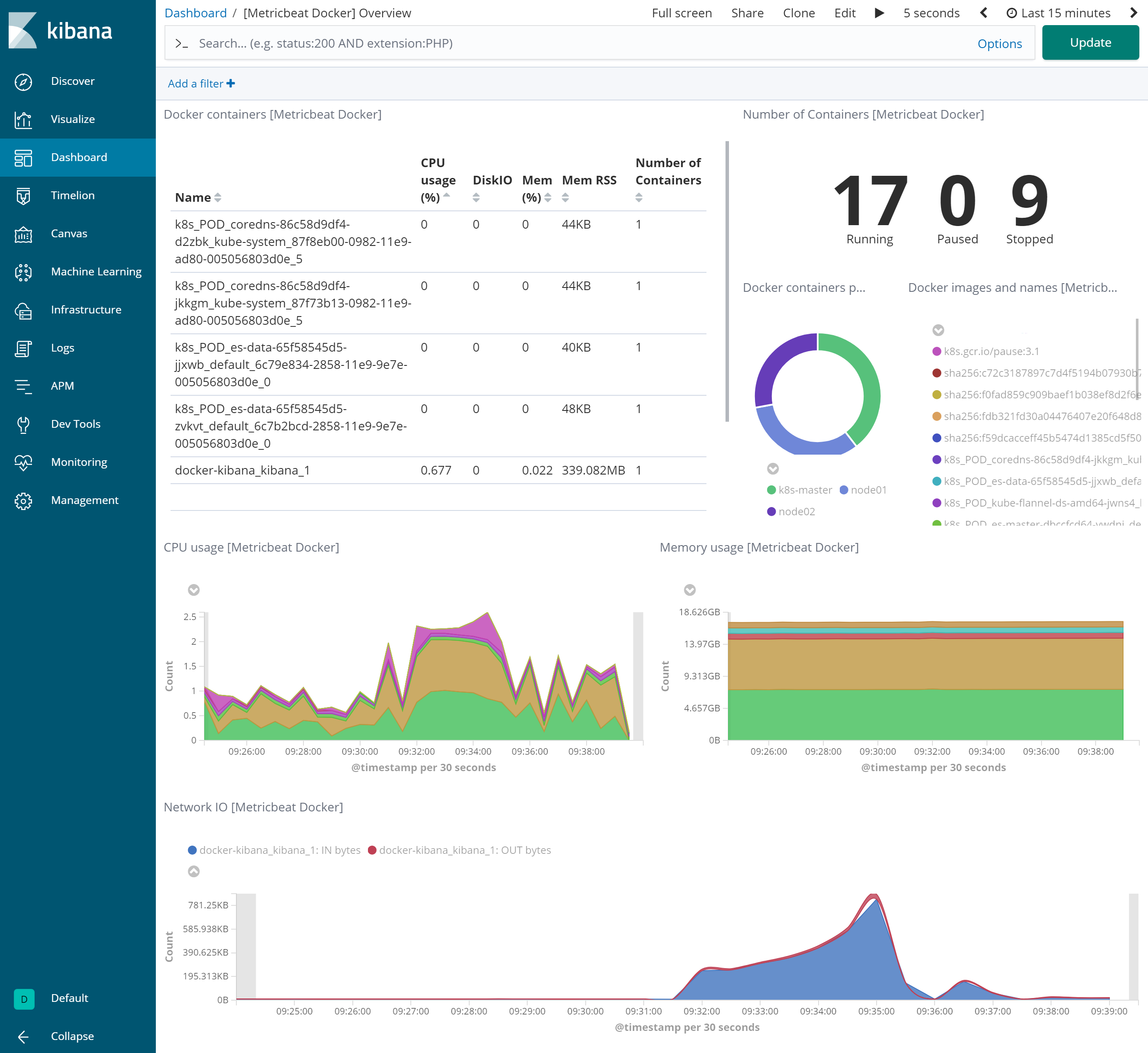
【Dockerのコンテナ単位まで可視化したダッシュボード】
これらのダッシュボードはあらかじめ準備されており、利用者が作る必要がないためすぐに使い始められますが、これらのグラフを作る基となったデータはElasticsearchに格納されているため、さらに自分の見やすいように加工、追加することも可能です。また、ダッシュボードの画面の上部には検索窓があり、ここで可視化の対象を絞り込んでいくことができたり、表示の時間幅を柔軟に変更できるのも、Kibanaの使いやすさの一つかと思います。
また、今回使用したバージョンのKibanaではさらにインフラの状態を簡単に見れるようになっています(画面左側のInfrastructureタブ)。CPUの使用率やMemoryの使用率を各マシンやコンテナ毎、Availability ZoneやID別に見れるようになっています。例えばCPU使用率が高いコンテナがあった場合には、色が濃く(100%に近ければ赤く)なるので、そのコンテナのメトリックを時系列を追って調べていく、ということができるようになります。
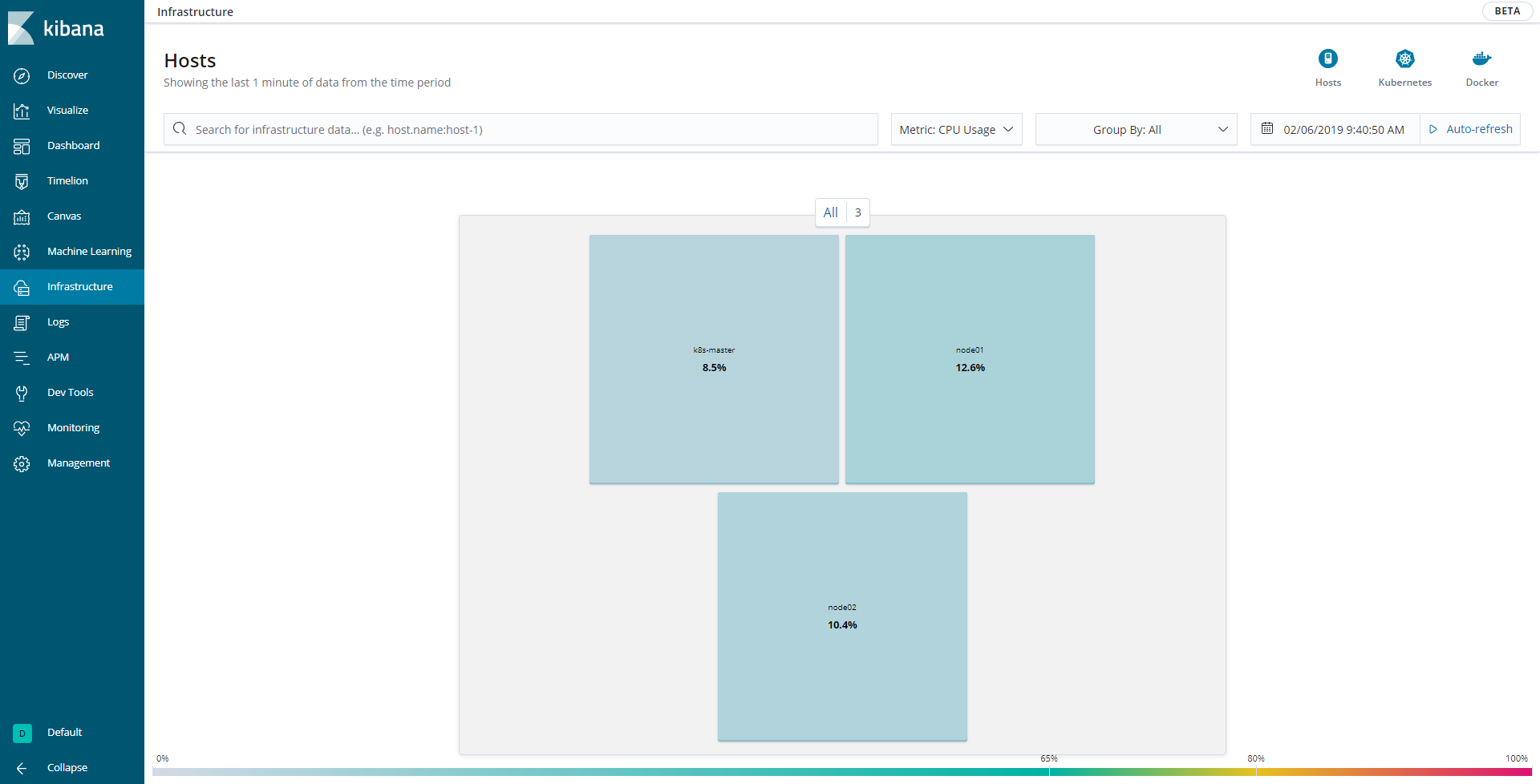
【マシンのCPU使用率をパネルで表示】
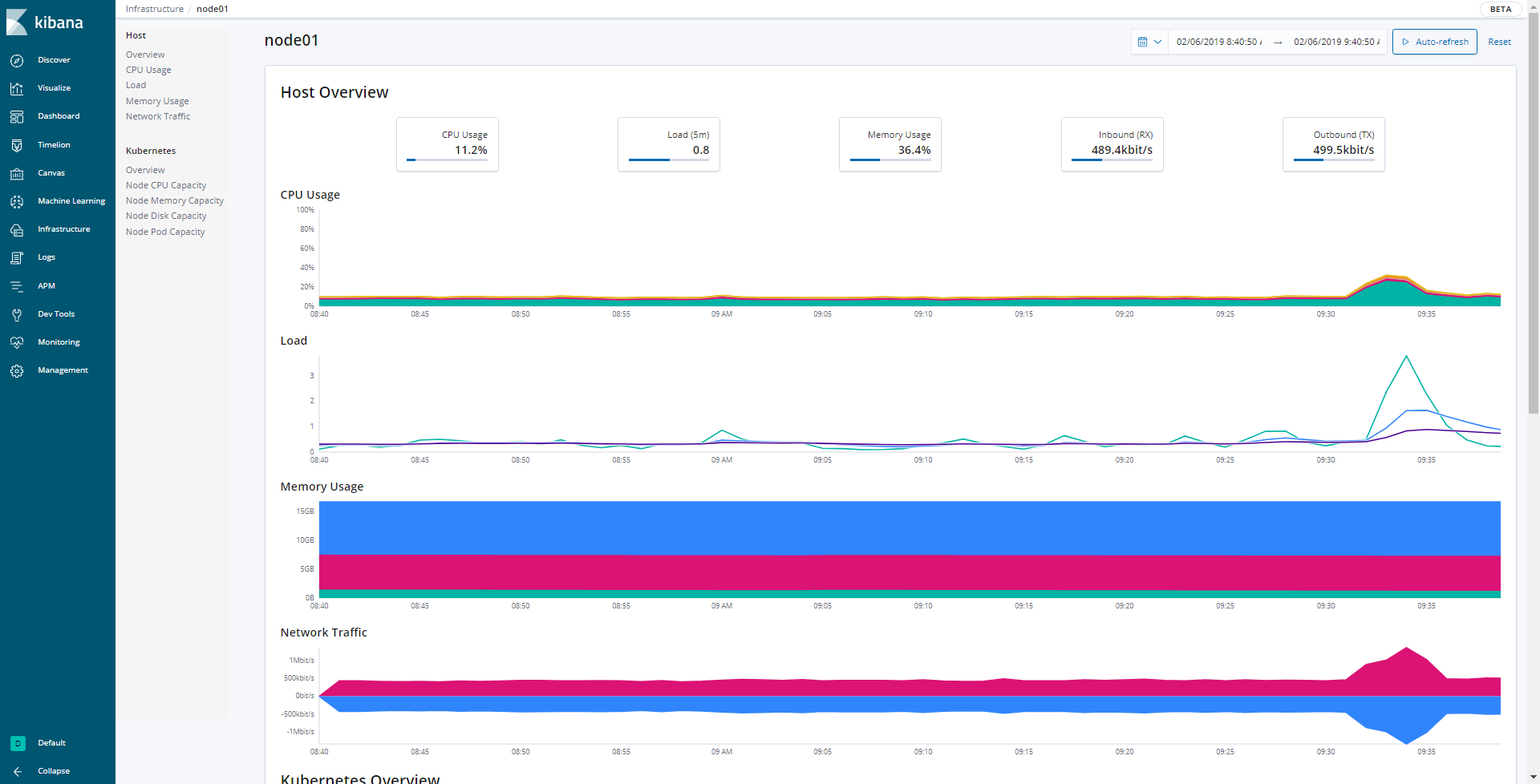
【特定のマシンのメトリックを時系列表示】
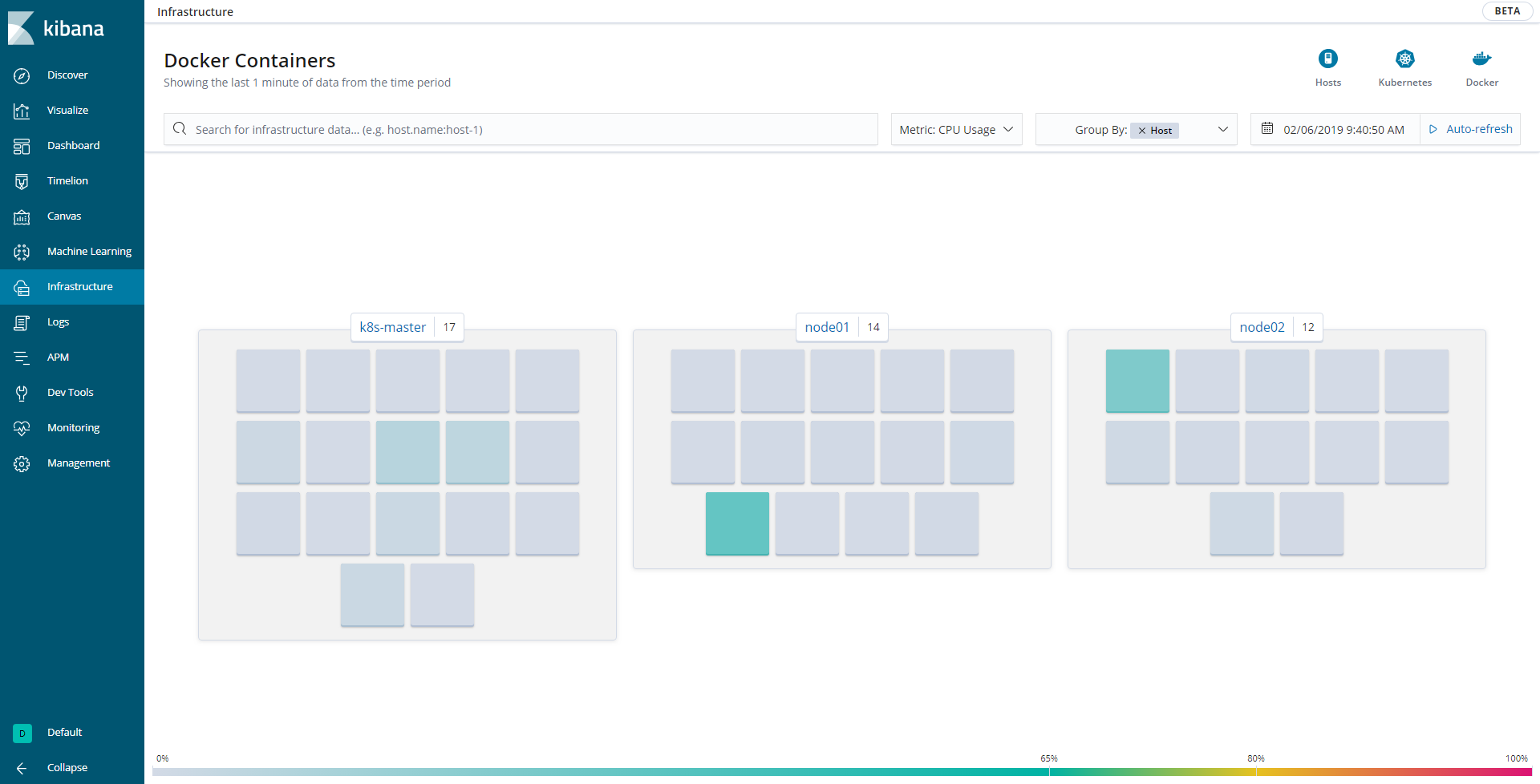
【各マシン上で動くDockerのCPU使用率をパネルで表示】
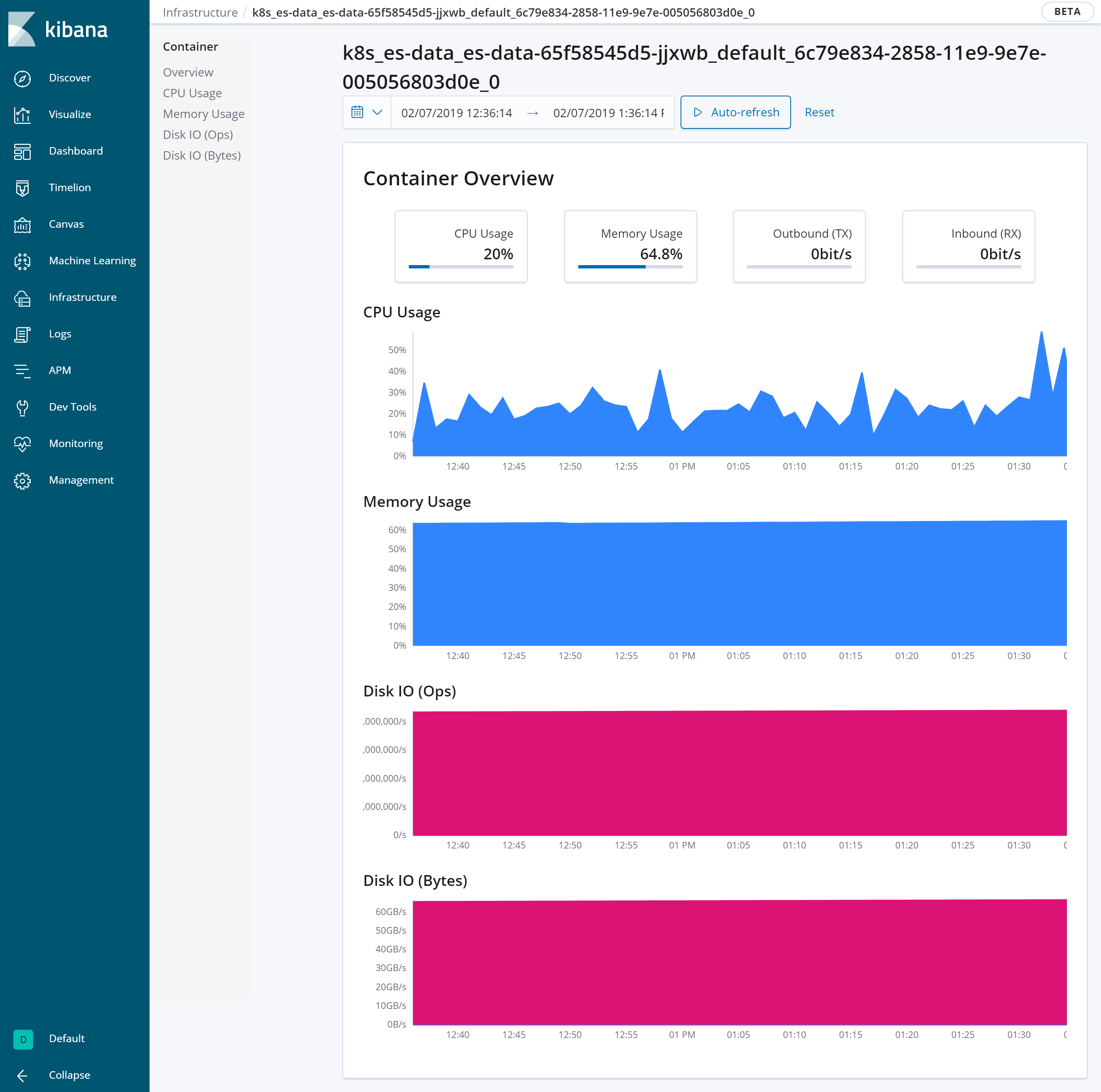
【特定のDockerのメトリックを時系列表示】
環境で何か障害が発生したときも、時系列をさかのぼってメトリックの変化を追うことができるので、これらのデータを蓄積しておくことで、「障害発生時に実はCPUの使用率が高騰していた」という事実を見つけられるかもしれません。何かが起こる前に、データを収集しておくことは非常に重要です。
ログの可視化
メトリックをKibanaで可視化できるようになりましたが、Docker/Kubernetesを使って検証を始めていくと、他にもKibanaで可視化したいものが出てきました。検証環境を作っている際に、何か予期せぬ挙動があったときはログを確認しますが、一つずつ各マシンにsshで接続し、各コンテナに入りログを見る、ということを繰り返していると、非常に多くの時間を使ってしまいます。そもそもElasticsearchはログ蓄積やログ分析でも使われているソフトウェアなので、これらのログもElasticsearchに送るようにし、Kibanaで可視化することにしました。こちらはFilebeatというエージェントを使って指定したログをElasticsearchに送るように指定するだけで、使えるようになります。Filebeatを使ってログをElasticsearchに入れると、このようにKibanaの画面からログを確認することができます。
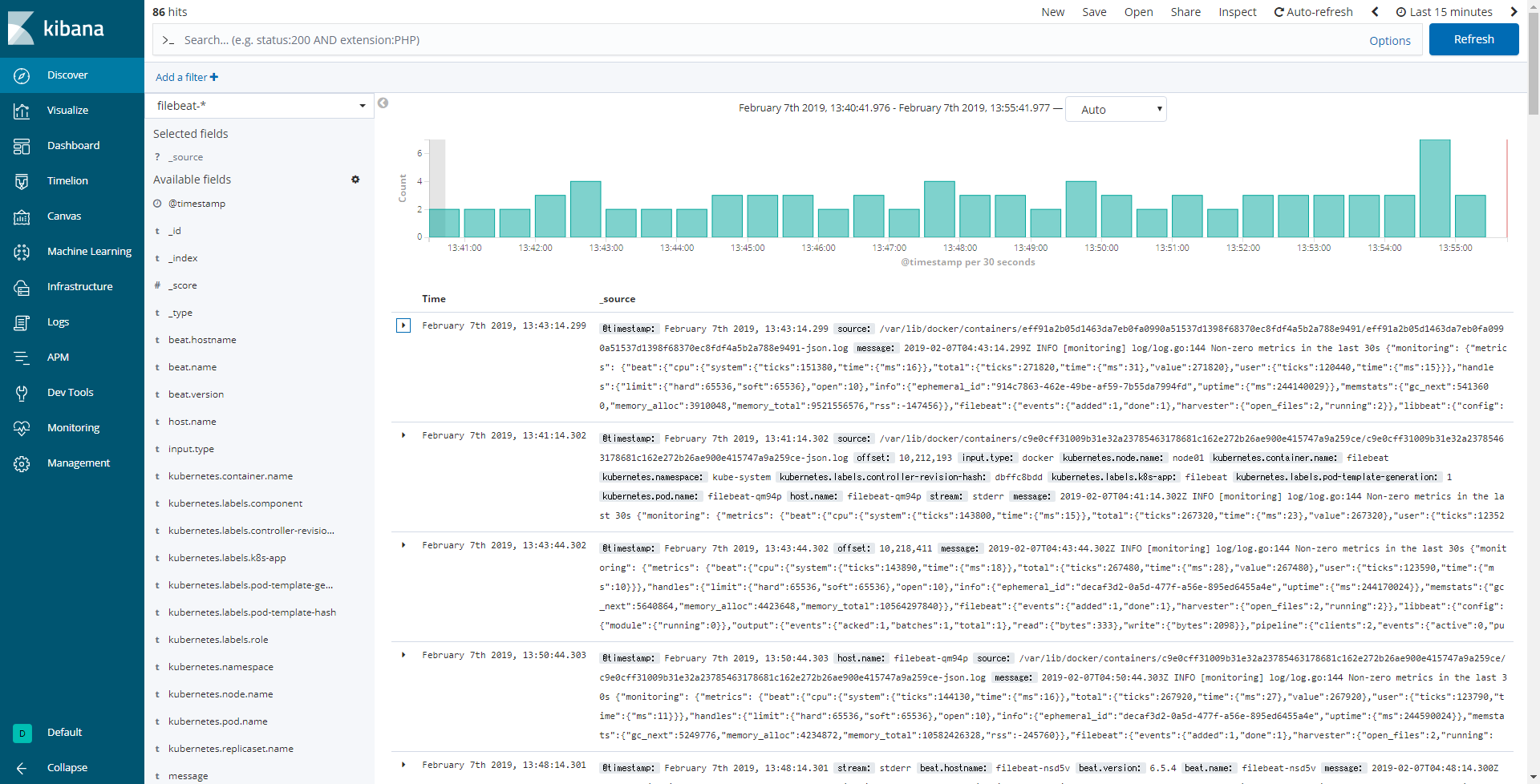
【Filebeatを使って送ったログの可視化】
このDiscoverの画面から、どれくらいのログが送られてきているのか簡単に見ることができ、検索や絞り込みを行えます。ログ分析の際に見るべき指標が決まっている場合には、ダッシュボードを作成して、そちらでログ分析を行えます。また、こちらもメトリック同様、今回使用しているバージョンのKibanaでは、よりログを見るのに適した画面が準備されています(画面左側のLogsタブ)。
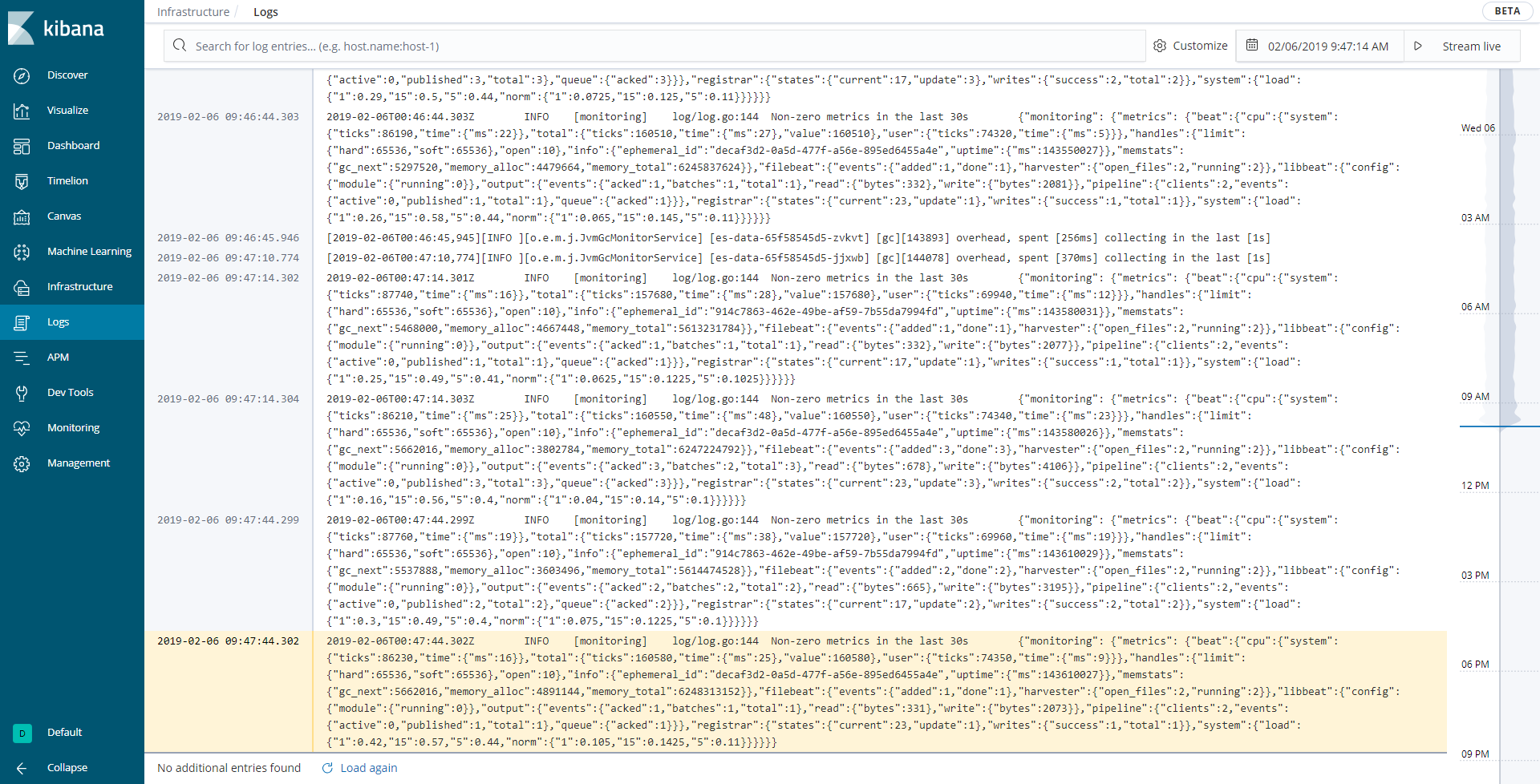
【ログの時系列表示】
このように、画面下側に最近のログが表示されるようになっており、右側にはどのくらいの量のログが送られてきているのかわかるようになっています。時系列でログが並び、自動更新されていくように設定ができるので、今までコンソールでtail -fをして確認していたような画面がKibana上で見れるようになりました。また、この画面には先ほどのメトリックを見ていた画面から遷移してくることもできるので、対象のマシンやコンテナのログを簡単にみることができるようになります。簡単な障害切り分けであれば、Kibana上で行うことができそうです。新しい運用や障害対応の方法となることに期待しています。
データのライフサイクル管理
さて、メトリックとログの可視化と分析について紹介しましたが、これらは監視対象が増えていったり、さかのぼりたい期間が長いほど、データ容量が大きくなります。これらはストレージを圧迫していくだけでなく、本来の目的であるTelemetry情報の可視化や検索に影響を及ぼしかねません。そこで不必要になったデータを自動で削除する機能を最後に紹介します。こちらもKibanaで設定することができるようになりました。
※検索や可視化を行う頻度によって、hot, warm, coldという属性を付けて管理することもできますが、今回は対象外とします。
上記はIndex Lifecycle Managementという機能で実現します。設定はライフサイクルポリシーを作成し、適用するのみです。
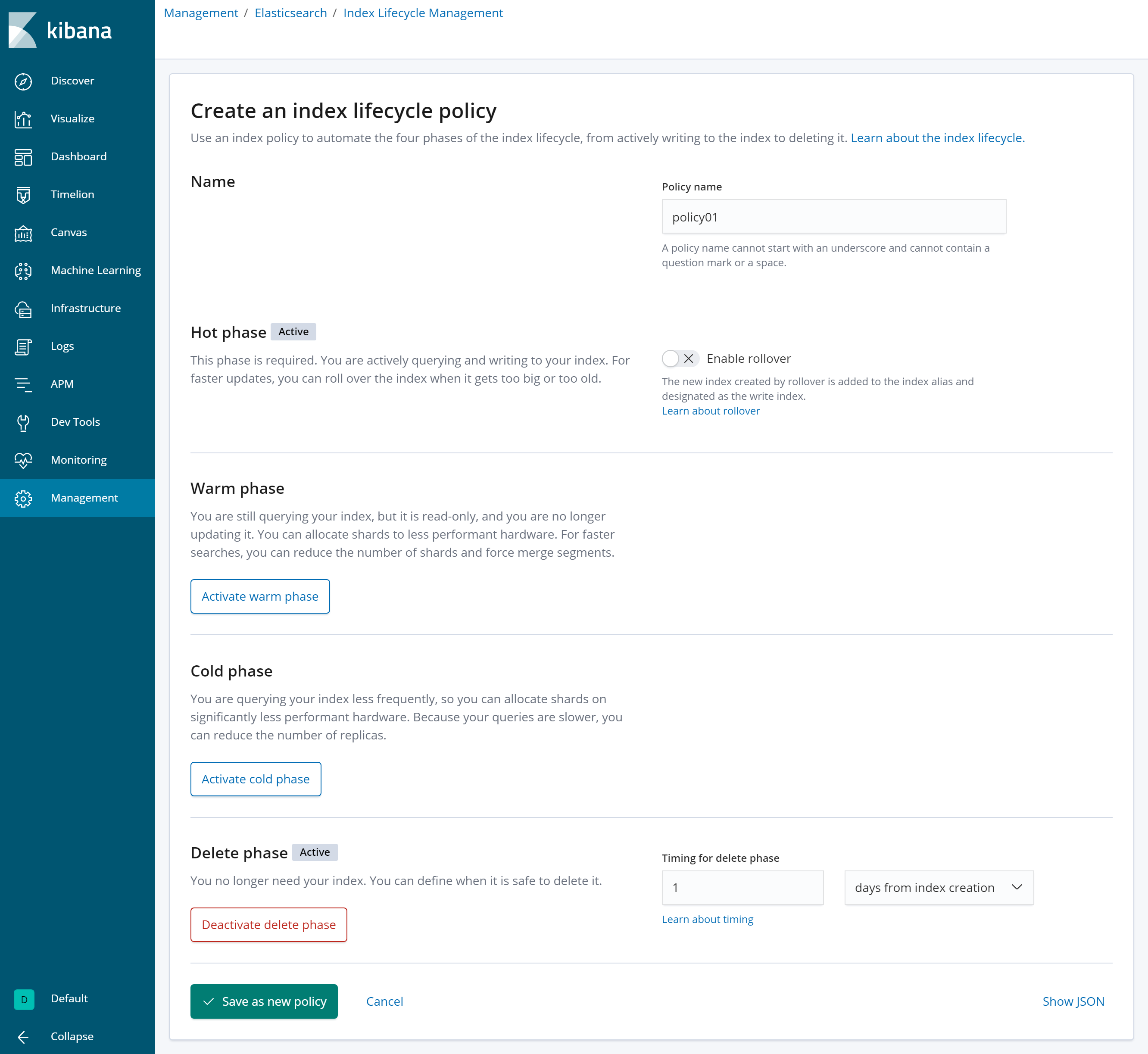
【ポリシーの設定画面】
今回はライフサイクルを1日に設定し、 “metricbeat-6.6.0-*” というIndexに対してポリシーを設定しました。すると、以下のように1日経過したIndexが削除されていることがわかります。
※metricbeat-6.6.0-2019.02.08のみ残り、その他のmetricbeat-6.6.0-*がついたindexは削除されています。
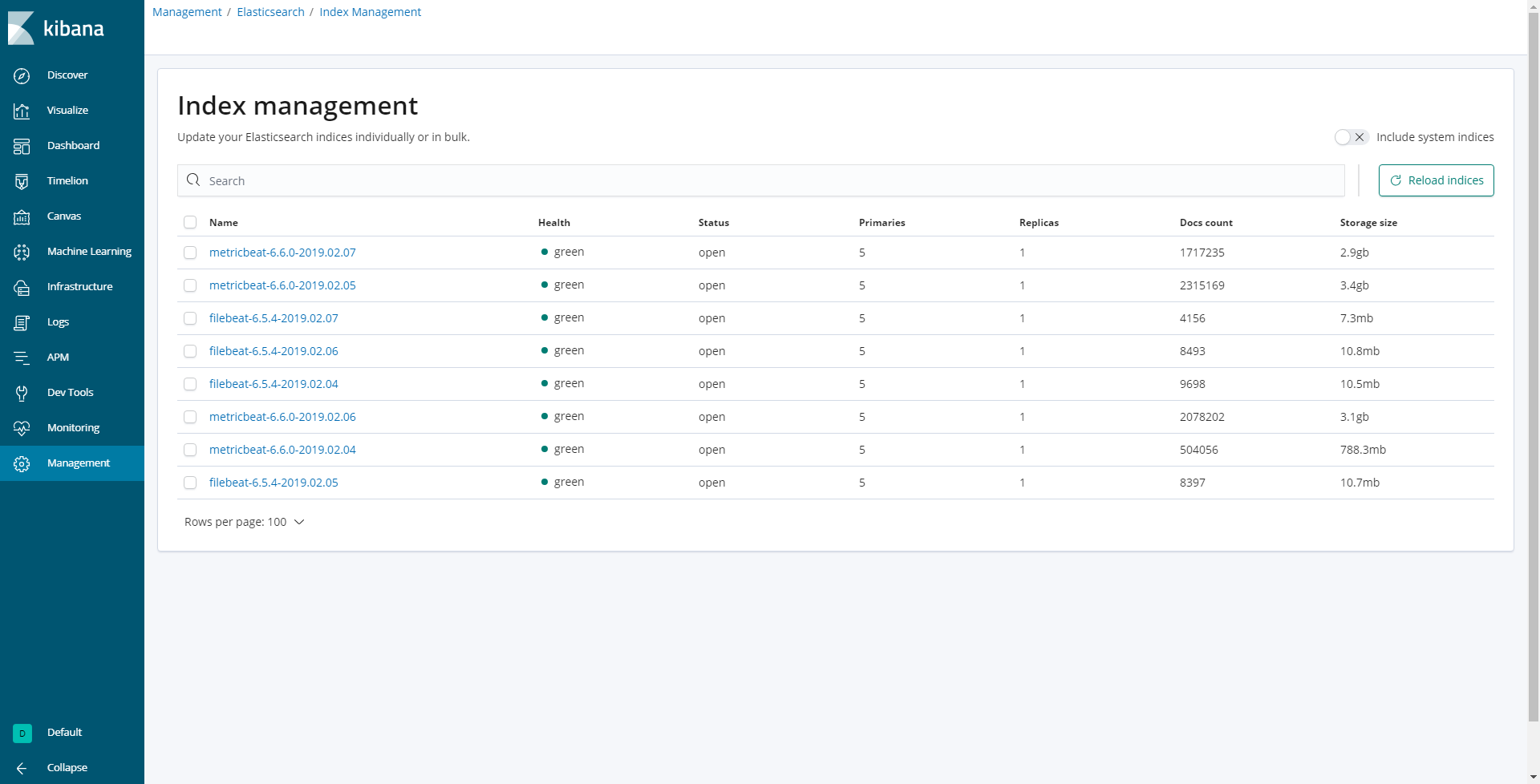
【ポリシー適用前のindex一覧】
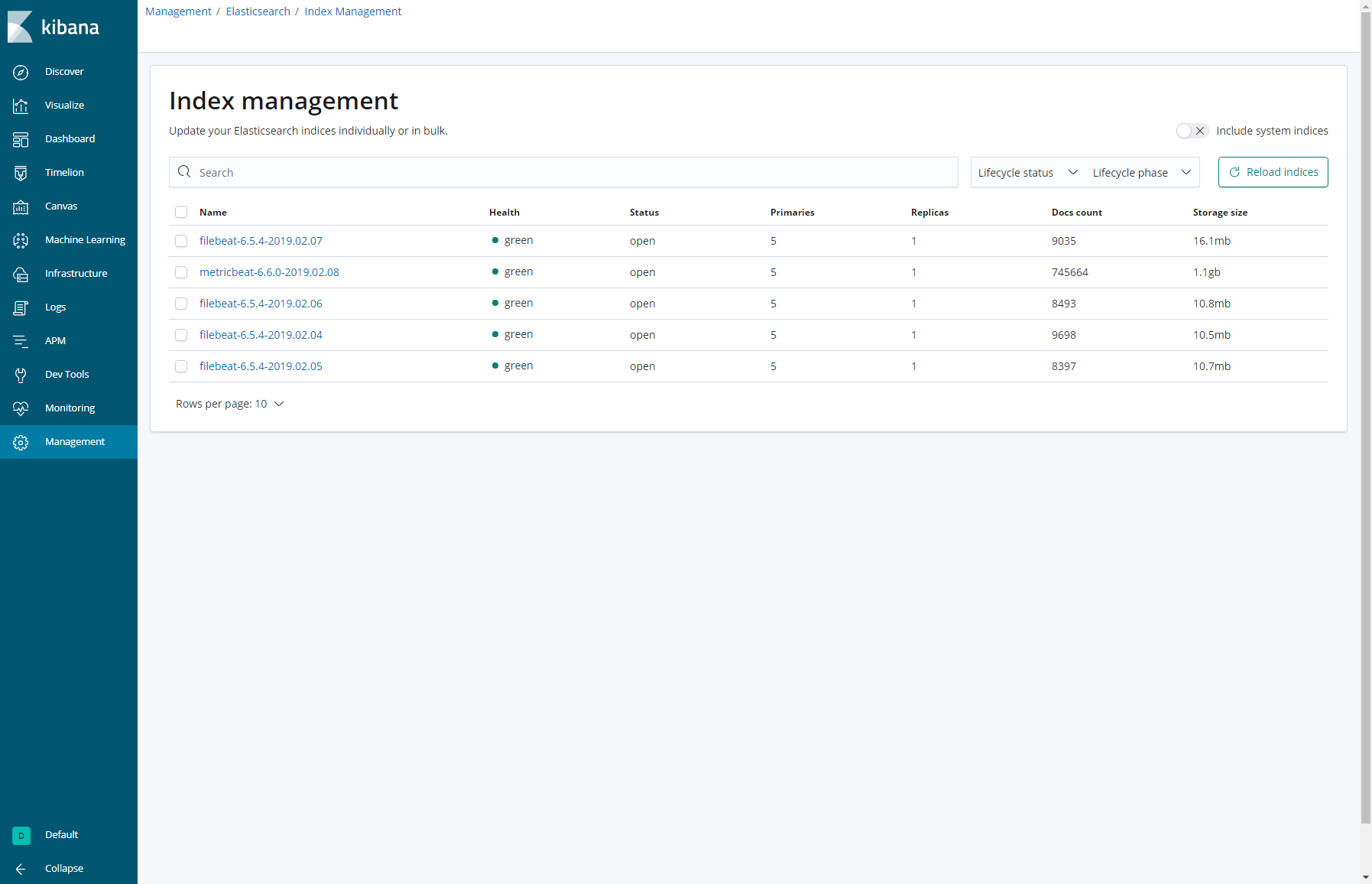
【ポリシー適用後のIndex一覧】
この機能を使えば必要な分だけElasticsearchに保存することができるため、index増加によって突然検索性能が落ちた、ということも防げるように思います。
おわりに
様々なコンポーネントで作られているシステムは各地にログが散らばっていたり、管理すべき対象が増えていくと、運用が徐々に大変になっていきます。今回のようにメトリックもログも一元管理できてしまえば、運用コストも下げられ、さらに分析も簡単にできるようになるのではないでしょうか。また、ElasticはMachine Learningの機能も持っているので、これらのメトリックやログを使って異常検知をし、アラートをあげるようなこともできます。閾値を用いた監視ではなく、いつもと異なる状態を検知してくれることで、障害を未然に防ぐことができるかもしれません。
今回Docker/KubernetesをベースとしたTelemetry環境の構築を行っていて行き着いたのがElasticによるメトリックとログの一元管理でした。もちろん仮想マシンや物理マシンベースの環境でも同様にメトリックやログの一元管理を行うことができるので、参考にしていただければと思います。
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス推進本部
第1応用技術部 第1チーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索