

- ナレッジセンター
- 匠コラム
番外編:OSSツールで作る、Telemetry初めの一歩 - 後編 -
- 匠コラム
- 監視/分析
- ネットワーク
- 可視化
ビジネス推進本部 第1応用技術部
コアネットワークチーム
井上 勝晴
ハディ ザケル
これまで3回に渡り、本連載コラムでは次世代SNMPとも呼べる「Telemetry」について、その登場背景や技術要素を説明しました。今回は前編に続き、「Telemetry」技術ををより身近に触れられるよう、OSS(OpenSourceSoftware)を活用した「Telemetry環境の構築方法」をご紹介したいと思います。
| 連載インデックス |
|---|
前編のおさらい
本コラムの、前編では、仮想アプライアンスの入手方法、Kafka の構築手順をご紹介しました。後編では、Frontendツール、Elastic Stackの構築手順を記載します。
Collector:cisco/bigmuddy-network-telemetry-pipeline
cisco/bigmuddy-network-telemetry-pipeline は、Gitで公開されているFreeのTelemetry Collectorであり、OpenConfig / gRPCに対応しています。Telemetry DataをGPBデシアライズし、人が読めるテキスト形式でシステムに出力する事が出来ます。今回の構成では、GPBデシアライズ後にKafkaへ送信するシステムを作成します。
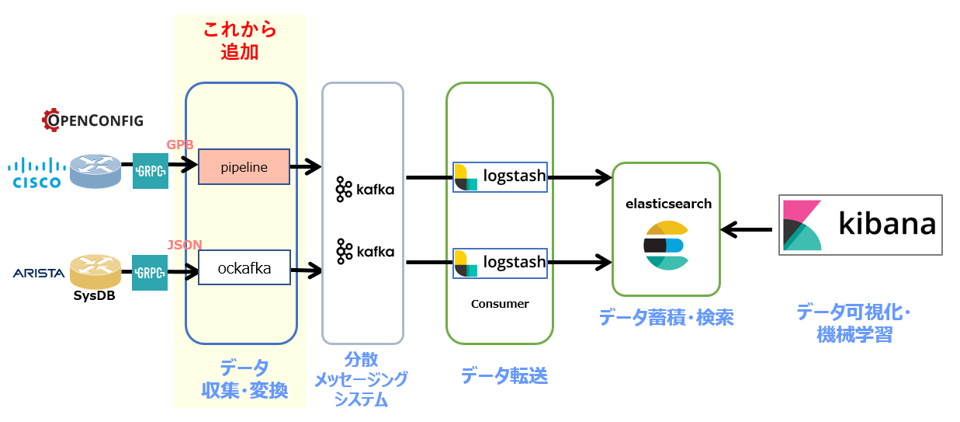
<Collectorの設定と起動>
| 1. Docker取得 |
docker pull janogtelemetryworkinggroup/bigmuddy-network-telemetry-pipeline:001 |
| 2. Container起動 |
docker run -it docker.io/janogtelemetryworkinggroup/bigmuddy-network-telemetry-pipeline:001 |
| 3. Configurationの変更 |
・RouterのIP Address/Port sed -i -e s/"server = 10.44.101.71:10000"/"server = 1.2.3.4:10000"/ /data/pipeline.conf ・KafkaのIP Address/Port sed -i -e s/"brokers = 10.44.160.98:32768"/"brokers = 5.6.7.8:32768"/ /data/pipeline.conf ・Routerのセンサーパス情報 sed -i -e s/"subscriptions = Sub1"/"subscriptions = Subx"/ /data/pipeline.conf ※ 黄色でハイライトした部分は、環境に応じて変更します。 |
| 4. Telemetry Collector起動 |
/pipeline -log=/data/pipeline.log -config=/data/pipeline.conf
※起動後、User名/Passwordを入力します
|
<起動後の確認(内部Dumpファイルにて)>
| 1. (もう1つTerminalを立ち上げて、)Container ID確認 |
docker ps | grep bigmu |
| 2. Containerへ接続 |
docker exec -it 4fd5f011cc8f /bin/bash
※Docker IDは前Stepで確認したIDを指定します。
|
| 3. 取得Telemetry Dataの確認 |
tail -f /data/dump.txt |
上記3項で以下の様なTelemetry Dataが出力されるはずです。
| tail -f /data/dump.txt |
------- 2018-06-27 03:34:57.831927049 +0000 UTC -------
Summary: GPB(common) Message [10.44.101.71:10000(XRv1)/
openconfig-interfaces:interfaces/interface msg len: 5821]
{
"Source": "10.44.101.71:10000",
"Telemetry": {
"node_id_str": "XRv1",
"subscription_id_str": "Sub1",
"encoding_path": "openconfig-interfaces:interfaces/interface",
"collection_id": 26324,
|
また、Kafka側に取得したTelemetry Dataが展開されているかの確認もします。
<起動後の確認(Kafkaにて)>
| 1. (もう1つTerminalを立ち上げて、)Container ID確認 |
docker ps | grep kafka
|
| 2. Containerへ接続 |
docker exec -it 24b9252916a8 /bin/bash
※Docker IDは前Stepで確認したIDを指定します。
|
| 3. 取得Telemetry Dataの確認 |
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic telemetry_cisco_xrv
|
上記3項で以下の様なTelemetry Dataが出力されるはずです。
| kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic telemetry_cisco_xrv |
{
"Source": "10.44.101.71:10000",
"Telemetry": {
"node_id_str": "XRv1",
"subscription_id_str": "Sub1",
"encoding_path": "openconfig-interfaces:interfaces/interface",
"collection_id": 26396,
"collection_start_time": 1530080102572,
"msg_timestamp": 1530080102572,
"collection_end_time": 1530080102634
},
"Rows": {
"Timestamp": 1530080102584,
"Keys": {
"name": "GigabitEthernet0/0/0/0"
},
"Content": {
"subinterfaces": {
"subinterface": {
"index": 0,
"state": {
"admin-status": "DOWN",
"counters": {
"in-broadcast-pkts": 0,
"snip"
※1行の JSON として表示されますが、ここでは改行を入れて見やすくしています。 |
Collector:aristanetworks/goarista/ockafka
aristanetworks / goarista / ockafka は、Gitで公開されているFreeのTelemetry Collectorです。OpenConfig, gRPCに対応しており、JSON形式でTelemetry Dataを取得・出力します。本コラムではベンダーNativeなData形式でTelemetryを取得するシステムを構築します。
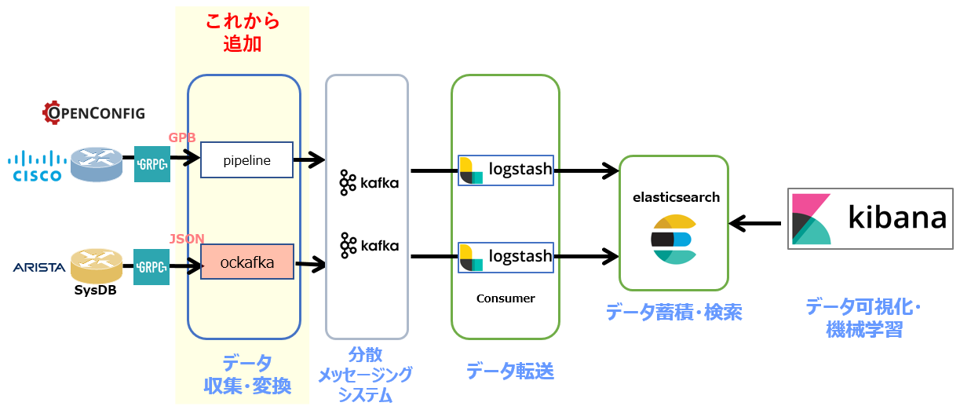
| 1. Docker取得 |
docker pull janogtelemetryworkinggroup/ockafka:latest |
| 2. Container起動 |
docker run -p 45968:45968 docker.io/janogtelemetryworkinggroup/ockafka:latest
--kafkatopic telemetry_arista_ockafka -addrs 10.44.101.81 -kafkaaddrs 10.44.160.189:32768 -subscribe
/Sysdb/sys/net/config,/Sysdb/inteace/counter/eth/slice/phy/1/intfCounterDir/Ethernet1/intfCounter/current,
/Sysdb/sys/net/config,/Sysdb/interface/counter/eth/slice/phy/1/intfCounterDir/Ethernet2/intfCounter/current,
/Sysdb/sys/net/config,/Sysdb/interface/counter/eth/slice/phy/1/intfCounterDir/Ethernet3/intfCounter/current
※赤:Kafka上のTopic、青:RouterのIP、緑:KafkaのアドレスとPort、灰:センサーパス情報 |
Kafka側に取得したTelemetry Dataが展開されているかの確認もします。
<起動後の確認(Kafkaにて)>
| 1. (もう1つTerminalを立ち上げて、)Container ID確認 |
docker ps | grep kafka
|
| 2. Containerへ接続 |
docker exec -it 24b9252916a8 /bin/bash ※Docker IDは前Stepで確認したIDを指定します。 |
| 3. 取得Telemetry Dataの確認 |
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic telemetry_arista_ockafka --from-beginning
|
上記3項で以下の様なTelemetry Dataが出力されるはずです。
| kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic telemetry_arista_ockafka –from-beginning |
{
"dataset": "10.44.101.81",
"timestamp": 1530085097880,
"update": {
"Sysdb": {
"sys": {
"net": {
"config": {
"domainList": {},
"domainListMetadata": {
"head": 0,
"tail": 0
},
"domainName": "nos.com",
"hostname": "vEOS2",
"snip"
※1行の JSON として表示されますが、ここでは改行を入れて見やすくしています。 |
Collector:Elastic Stack
Kafka に集約したTelemetry DataをElastic Stackへ展開し、Telemetry Dataに対して可視化や分析を可能な仕組みを構築します。
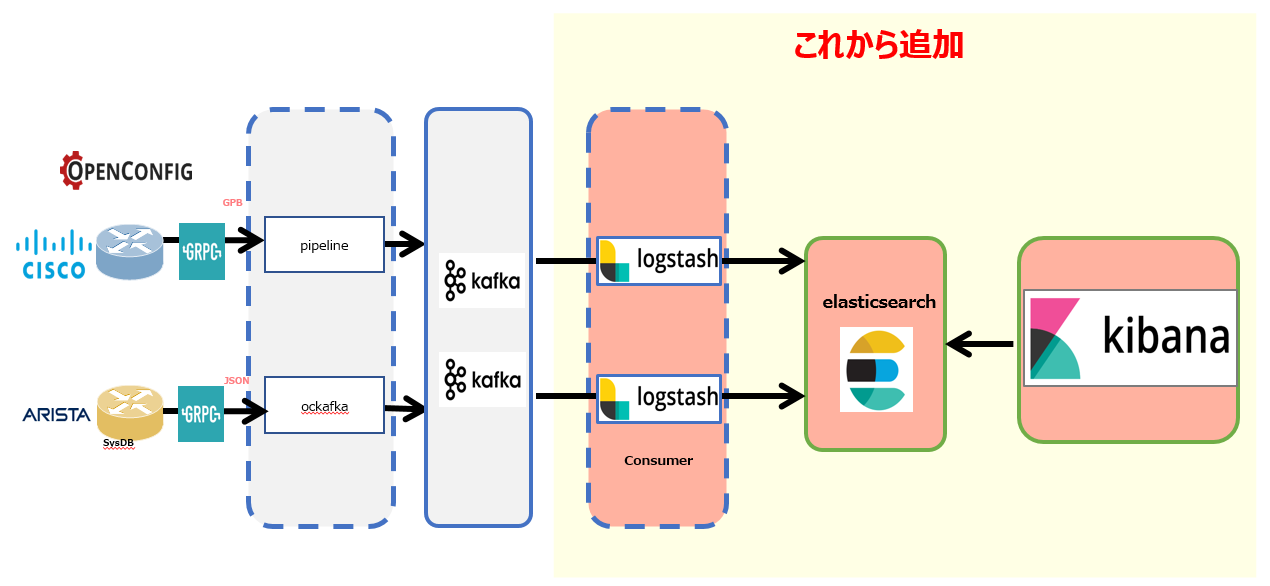
Collector:Elastic Stack – Elastic Search
Elastic Searchは検索エンジンに相当し、本システムでは取得したTelemetry Dataに対する検索機能を提供します。
| 1. docker-compose.ymlの作成 |
version: '2.0'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-platinum:6.1.3
container_name: elasticsearch
environment:
- cluster.name=docker-cluster-test01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- ELASTIC_PASSWORD=changeme
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- esnet
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch-platinum:6.1.3
container_name: elasticsearch2
environment:
- cluster.name=docker-cluster-test01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.zen.ping.unicast.hosts=elasticsearch"
- ELASTIC_PASSWORD=changeme
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata2:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- esnet
volumes:
esdata1:
driver: local
esdata2:
driver: local
networks:
esnet:
|
| 2. $ sudo sysctl -w vm.max_map_count=262144 ※virtual memoryの変更 |
| 3. docker-compose up このコマンドで起動 ※ docker-compose.yml のあるフォルダで実行する事 ※ 停止する時は、docker-compose down にてContainerがStop(削除)します |
Collector:Elastic Stack – Kibana
Kibanaはデータの可視化・分析ツールであり、本システムでは取得したTelemetry Dataに対する可視化と分析を担います。
| 1. docker-compose.ymlの作成 |
version: '2'
services:
kibana:
image: docker.elastic.co/kibana/kibana:6.1.3
volumes:
- ./kibana.yml:/root/kibana_docker/kibana.yml
ports:
- 5601:5601
networks:
- esnet
environment:
SERVER_NAME: kibana.example.org
ELASTICSEARCH_URL: http://10.44.160.97:9200
networks:
esnet:
※ ハイライト部は環境に合わせ変更(Elastic SearchのIPアドレスをしています。)
|
| 2. kibana.yamlの作成 |
elasticsearch.username: "elastic"
elasticsearch.password: "changeme"
|
| 3. docker-compose up このコマンドで起動 ※ docker-compose.yml のあるフォルダで実行する事 ※ 停止する時は、docker-compose down にてContainerがStop(削除)します |
Collector:Elastic Stack – Logstash
Logstashはデータ処理パイプラインであり、Dataを取得して変換し、任意の場所に格納します。本システムではKafkaに展開されたTelemetry Dataを取得してElastic Searchへ展開します。※本構成では、ベンダー単位で別TopicをKafkaに作成してTelemetry DataをProduceしているため、後段にあるLogstashもベンダー単位でContainerを作成しています。(LogstashをCisco/Arista用に2つ起動)
| 1. Container用コンフィグレーション保存フォルダの作成 # mkdir /config-dir |
| 2-1. Cisco用:Logstash Configrationを作成し、Config-dirに保存します。 |
input {
kafka {
group_id => "test01"
bootstrap_servers => "10.44.160.189:32768"
topics => "telemetry_cisco_xrv"
}
}
filter {
date {
match => [ "timestamp", "UNIX_MS" ]
remove_field => [ "timestamp" ]
}
json {
source => "message"
remove_field => "message"
}
}
output {
elasticsearch {
hosts => "10.44.160.189:9200"
user => elastic
password => changeme
index => "telemetry_cisco_sampling_xrv_%{+YYYY.MM}"
}
}
※ハイライト部は環境に合わせて変更します。
bootstrap_servers:KafkaのアドレスとPort、topics:Kafka上でのTopic、
hosts:Elastic SearchのアドレスとPort
|
| 2-2. Arista用:Logstash Configrationを作成し、Config-dirに保存します。 |
input {
kafka {
group_id => "test01"
bootstrap_servers => "10.44.160.189:32768"
topics => "telemetry_arista_ockafka"
}
}
filter {
date {
match => [ "timestamp", "UNIX_MS" ]
remove_field => [ "timestamp" ]
}
json {
source => "message"
remove_field => "message"
}
}
output {
elasticsearch {
hosts => "10.44.160.189:9200"
user => elastic
password => changeme
index => "telemetry_arista_sampling_veos_%{+YYYY.MM}"
}
}
※ハイライト部は環境に合わせて変更します。
bootstrap_servers:KafkaのアドレスとPort、topics:Kafka上でのTopic、
hosts:Elastic SearchのアドレスとPort
|
| 3. Logstash Containerの実行 # cd /config-dir/ # docker run -d -v “$PWD”:/config-dir logstash -f /config-dir/cisco_logstash.conf # docker run -d -v “$PWD”:/config-dir logstash -f /config-dir/arista_logstash.conf |
可視化手順
では、今までの手順で収集した情報をどう見えるかについてですが、可視化部分を担当する、Kibana を使って見ていきたいと思います。ブラウザから Kibana へアクセスし、初期はログイン情報が求められます。本コラムで記載させていただいた手順通りでは、初期のログイン名は elastic、パスワードは changeme になります。※最新版では、username/password でログイン可能。
Kibana から Telemetry データを確認するには、Kibana の初期設定として Index Pattern の作成が必要です。作成時に、対象となる Index Pattern の指定します。図5にありますとおり、対象データの定義とデータの性質(今回だと時系列データ)を指定します。
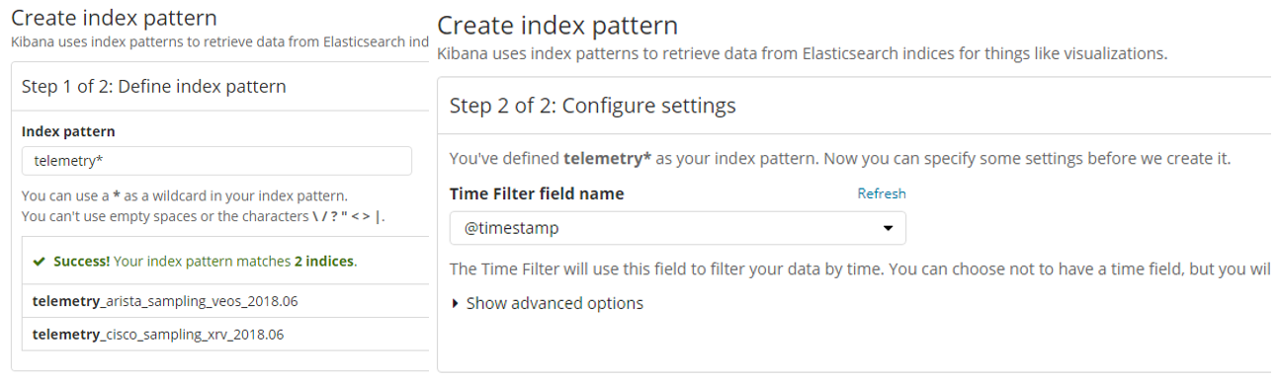
上記のとおり、Step1 では Cisco と Arista で共通している、文字列 telemetry* で文字列を指定し、データの性質として、時系列データ(@timestamp)であるという指定を実施します。
これらの初期設定後、Kibana の Dashboard 上からデバイスから発信されている Telemetry 情報の確認ができます。
○ Cisco デバイスからの情報
図6は Cisco IOS XRv からの情報になりますが、この例では1つのMessage内に複数のJSONが内包されており、Kibana上での可視化に問題がありました。(図6の GibabitEthernet0/0/0/0, GibabitEthernet0/0/0/1, GibabitEthernet0/0/0/2 が message 項目の中に含まれている様子を表しています)
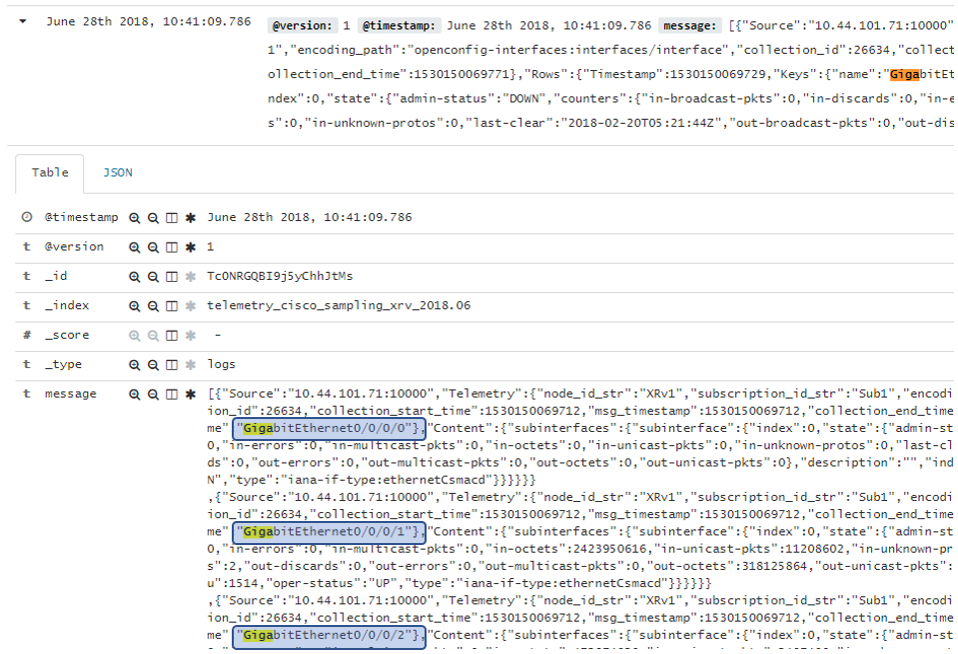
この問題に対し、弊社はMessageの変換コンポーネントを作成し、1つのMessageには1つのJSONとなるように対処しました。(参考:ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 後編 –)

○ Arista デバイスからの情報
次にArista vEOS からの情報となります。下記の例ではKey部分に"Ethernet2" と"Ethernet3"のような変数が含まれている事が分かります。
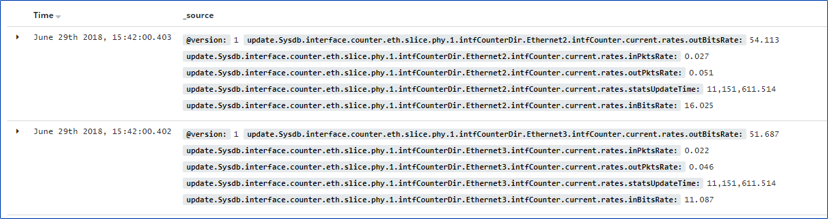
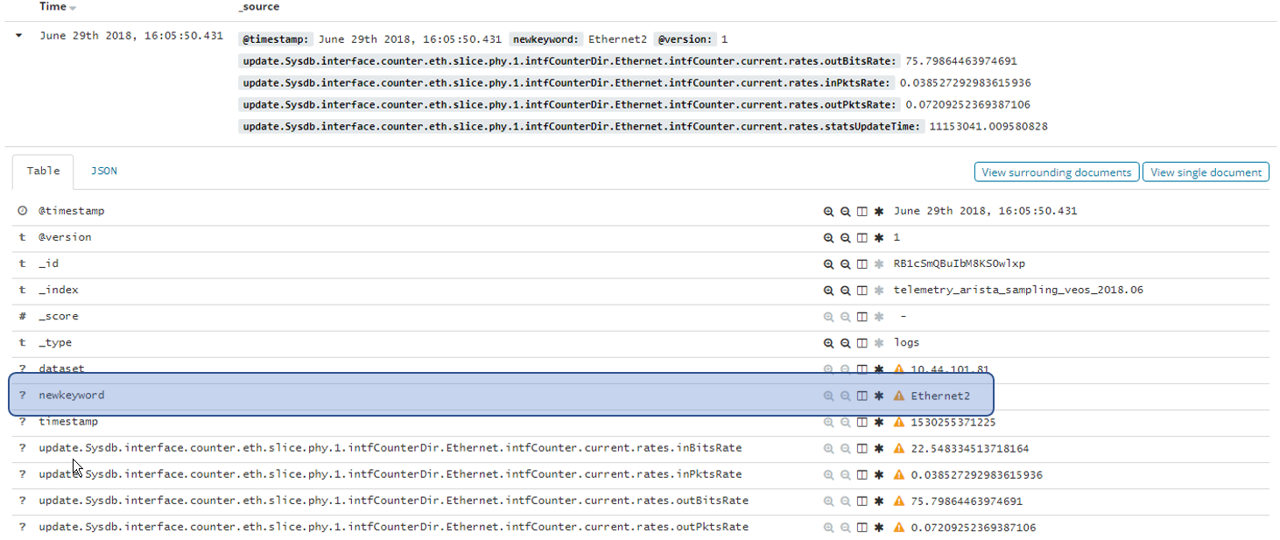
このような表示形式でも問題はありませんが、Key部分には変数を含めずに固定とする方がデータ構造が綺麗となりますので、弊社はKeyに含まれる変数(Ethernet2やEthernet3)を取り除き、新たなKey(newkeyword)に格納する変更を加えています。
○ Juniper デバイスからの情報
前編に記載させていただいたとおり、Juniper vMX からの Telemetry 情報の可視化には、さらなるデータ加工が必要です。GitHub のJTIMONを利用した場合、図10の様に複数の JSON に分割されてしまうのと、情報要素毎の JSON になってしまう問題がありました。

そのため、弊社の PoC ではJTIMONを変更し、データの加工を実施しております。データを加工した後の可視化では、下記の通り、綺麗に表示することができます。

まとめ
今回のコラム(前後編に渡り)では、OSS ツール、仮想アプライアンスを用いた、Telemetry 情報の収集から可視化方法について記載しました。各種ツールが揃いつつある現段階では、より簡単に PoC 作成は可能になっていますが、デバイスから送信される情報にばらつきがあるため、データ加工は必要不可欠であることもわかりました。本連載の次回以降では、きれいなデータを用いたユースケースのご紹介、更にネットワークの運用自動化へ適用検討をテータにご紹介をさせていただきます。
関連記事
- ネットワン NFV の全貌と市場への挑戦①
- ネットワン NFV の全貌と市場への挑戦②
- NFV動向: NFVとOpenStack①
- NFV動向: NFVとOpenStack②
- NFV動向: NFVとOpenStack③
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 - 前編 –
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 - 後編 –
- ネットワークが創生する価値 再考①:Hyper Scale DC Architectureとその手法
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 前編 –
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 後編 –
- 番外編:OSSツールで作る、Telemetry初めの一歩 – 前編 –
執筆者プロフィール
井上 勝晴
ネットワンシステムズ株式会社 ビジネス推進本部 応用技術部 コアネットワークチーム所属
エンタープライズ・サービスプロバイダのネットワーク提案・導入を支援する業務に、10年以上にわたり従事
現在はSDN・クラウドのエンジニアになるべく格闘中
- MCPC1級
ハディ ザケル
ネットワンシステムズ株式会社 ビジネス推進本部 応用技術部 コアネットワークチーム所属
主にハイエンドルータ製品の担当として、評価・検証および様々な案件サポートに従事
現在は、SP-SDN分野、コントローラ関連、標準化動向について調査及び連携検証を実施中
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索