

- ナレッジセンター
- 匠コラム
プログラミングなしでできる機械学習-Elasticを使った教師なし機械学習-
- 匠コラム
- データ利活用
- AI
ビジネス推進本部 応用技術部
クラウドデータインフラチーム
片野 祐
最近、”AI”という言葉を聞かない日がないくらい、この分野は盛り上がりを見せています。本コラムでは、プログラムを書くことなく実行できる機械学習のご紹介をいたします。
| 連載インデックス |
|---|
はじめに
第二回のコラムではプログラミングなしで教師あり機械学習を行う、Splunk社の提供するMachine Learning Toolkit(MLTK)を紹介しました。本コラムではElastic社が提供しているElastic Stackの拡張機能であるX-Packの一機能"Machine Learning" を用いてプログラミングなしで行う教師なし学習を紹介していきます。
※教師なし機械学習…教師ありのように正解データは特に決められず、そのデータにある構造や法則を見つけるもの。
※Elastic社の提供する機械学習の機能が"Machine Learning" という名称のため、混同を防ぐため本コラムでは一般的な機械学習を表す際は日本語表記、機能名を表す際は英語表記を取っています。
Elastic Stackとは
Elastic Stackとは、Elastic社が提供しているオープンソースのプロダクト群であり、全文検索エンジンである"Elasticsearch" 、データの取り込みや加工処理、転送を行う"Logstash" 、Elasticsearchに取り込まれたデータを可視化するためのGUIツールである"Kibana" 、データ取り込みに特化した非常に軽いエージェントである"Beats" から成ります。今回紹介するElasticの"Machine Learning" は、拡張機能のプラグインであるX-Packに含まれる機能です。

2017年5月にリリースされたElastic Stackバージョン5.4でMachine Learningのベータ版が公開され、7月にリリースされたバージョン5.5で正式リリースされました。2018年1月現在ではバージョン6.1になり、データの統計情報を簡単に見ることのできるData Visualization機能や、時系列データの将来予測をするためのForecast機能が追加され、着々と機能が追加されています。
Elastic社の提供するMachine Learningは、他のプログラミングレスな機械学習ツールと比較しても、非常に簡単で直感的に行うことができるのが特徴となっています。機械学習の深い知識は必要ありません。それではここからもう少し詳しくElasticのMachine Learningについて見ていきます。
Elasticの提供するMachine Learning
このMachine Learningは、時系列データに対して「いつもと違う」データや、「まわりと違う」データを検知するものです。教師あり機械学習のように、いわゆる正解となるデータがあるわけではなく、データの振る舞いを学習してモデルを作っていきます。そのため、機械学習のモデルを作成するために、正常に動作しているときのデータを集めることが必要になります。また、時系列データの周期的な特性をモデルに反映させるために最低でも4-5周期分のデータが必要になり、機械学習の精度を上げるためにはより細かい間隔でのデータ取得が必要になります。
ElasticのMachine Learningのような機械学習では、図2で示すような、従来行っているような閾値をベースとした監視では検知できない、いつもとは違う異常な振る舞いを検知できるようになることが期待されます。
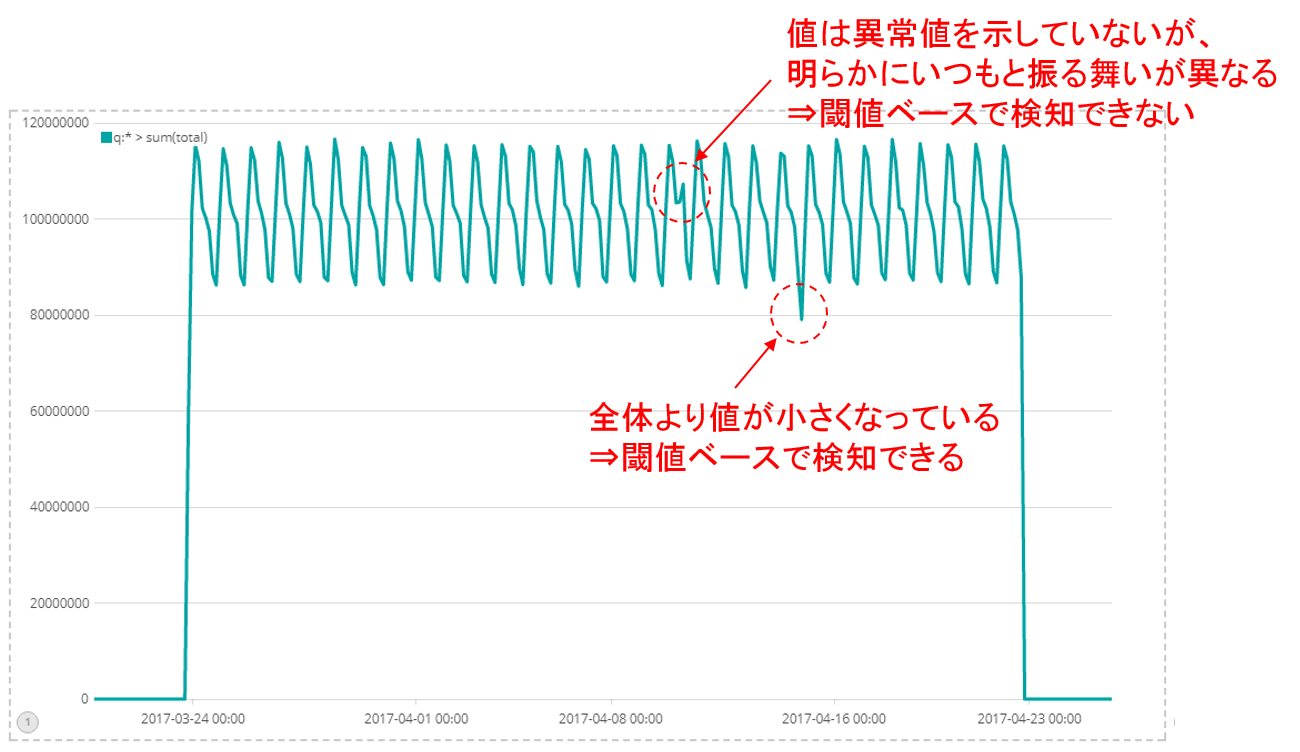
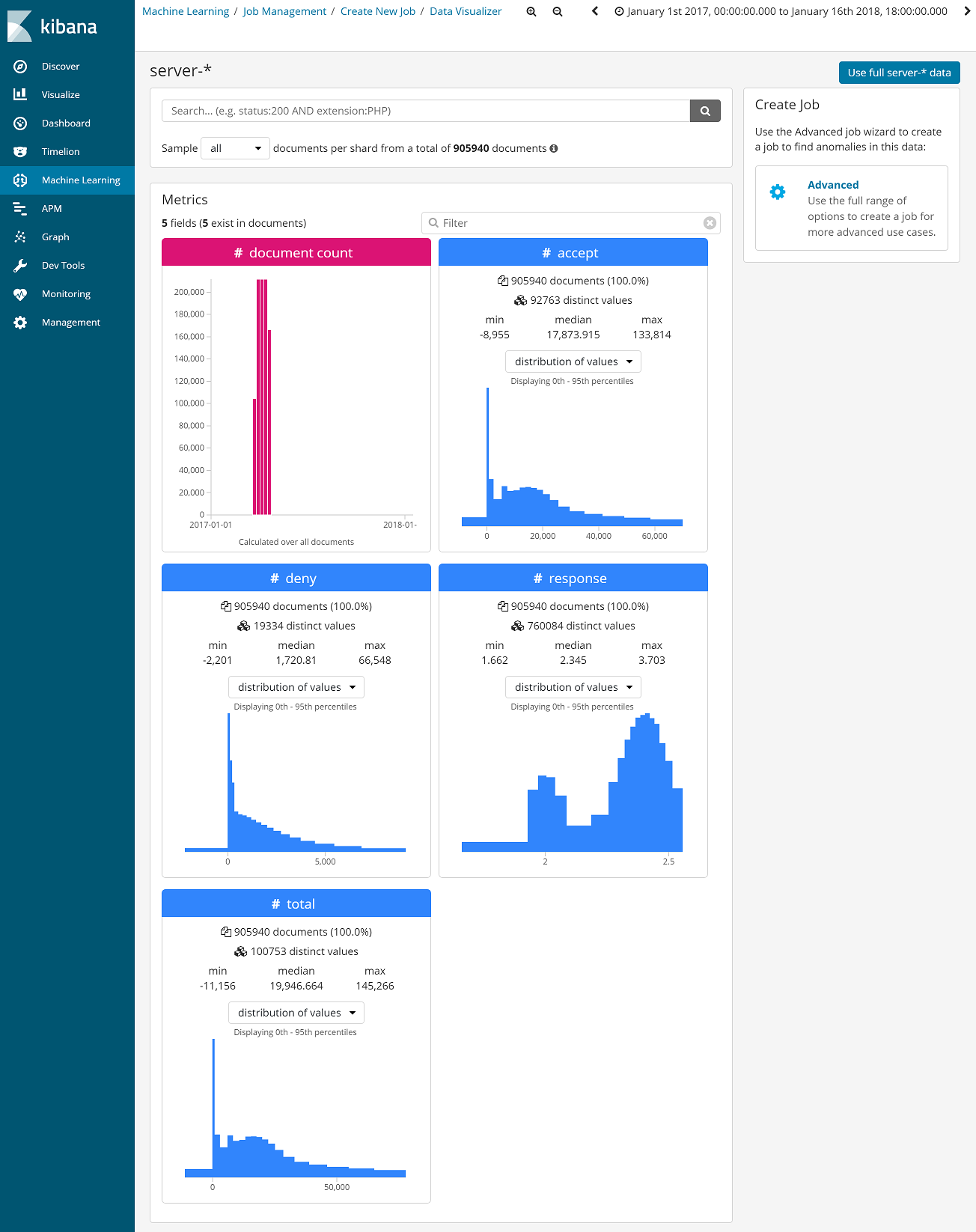
機械学習を行うにあたり、扱うデータの概要を把握することは非常に重要です。特に今回のように正常時のデータをモデル化するような場合、収集したデータに外れ値や意図していないデータがあると、せっかく機械学習を行っても正しいモデルが作られないことも考えらえます。ElasticではMachine Learningの一機能であるData Visualizerを使うことで図3,4のようにある時間幅にどれだけデータが含まれているのか、ユニークな値はいくつあるのか、含まれる数値の最小値、中央値、最大値はいくつなのか、そのヒストグラム等を簡単に表示することができます。まずはこの画面でデータを見ることで、機械学習を行おうとしているデータの概要を把握します。場合によってはこの可視化によって、異常が発生していることに気付くことができます。
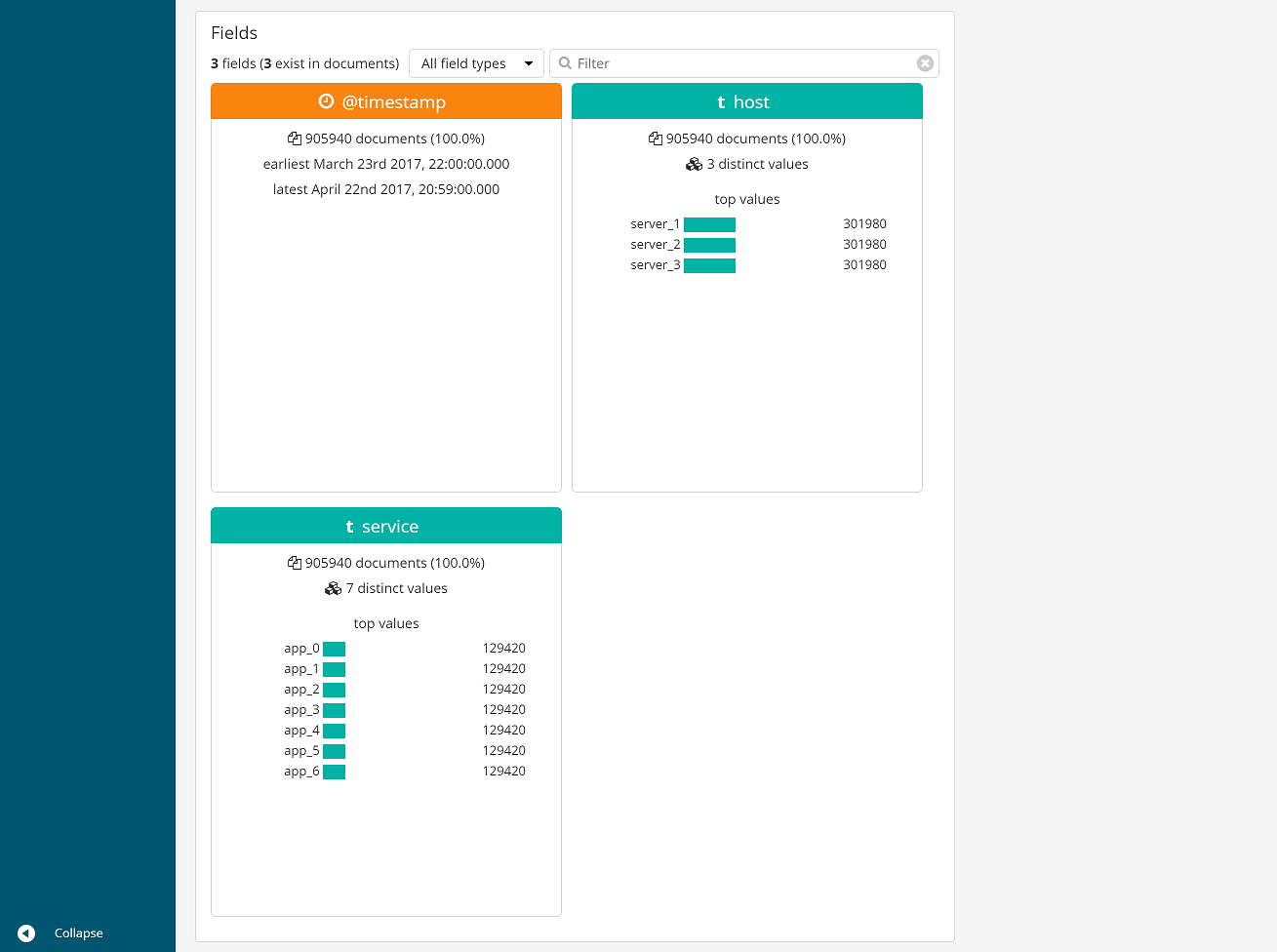
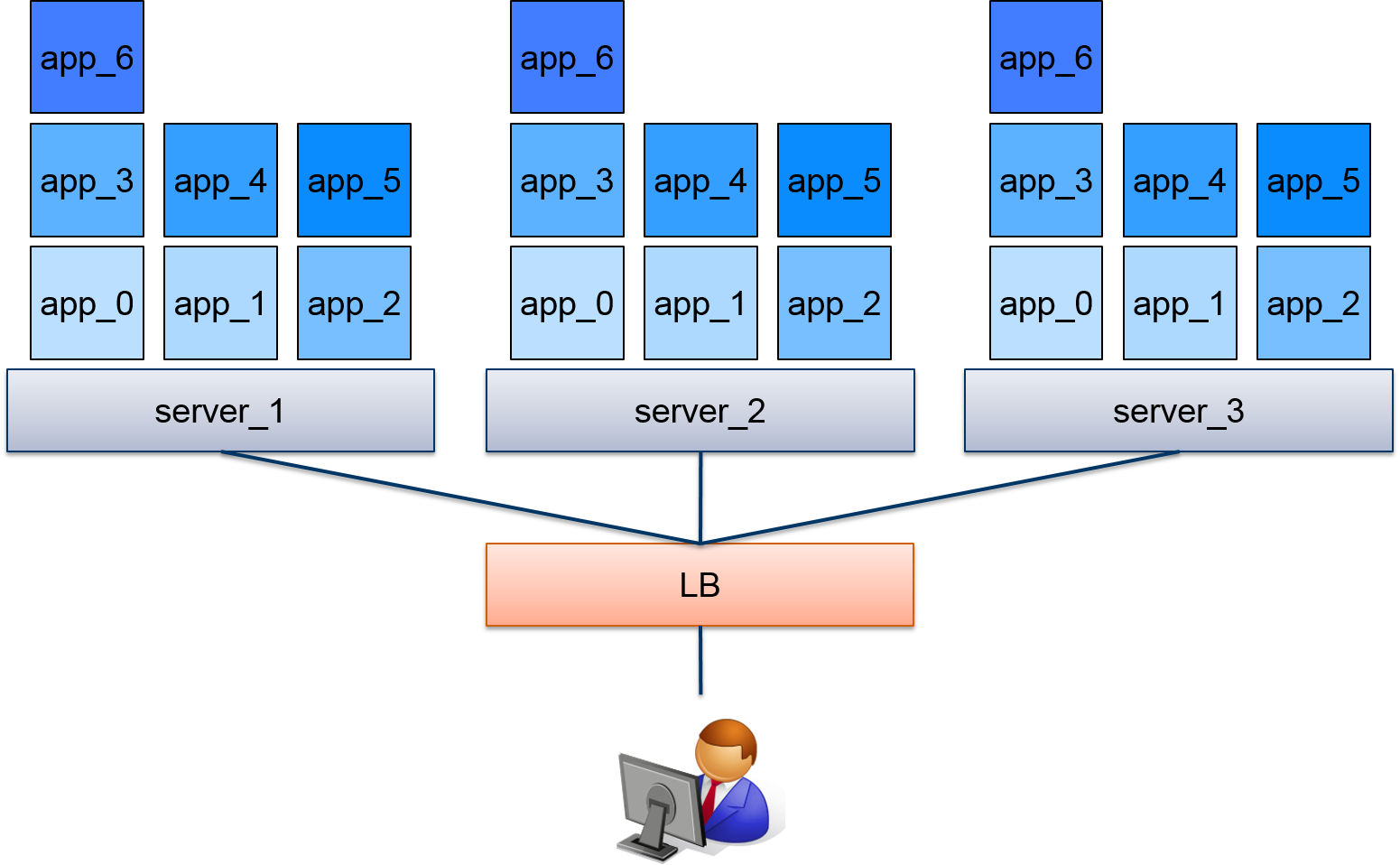
では、実際に上記で概要を見たデータを使って機械学習を行ってみます。想定しているケースは、図5ように3台のサーバ上でそれぞれ7つのアプリケーションが動作しており、それぞれのアプリケーションへのアクセス数(total, accept, deny)を記録しElasticsearchに保存している、というものです。このデータに対して機械学習を行い、サーバやアプリケーションへのアクセスが想定していない、いつもと異なる挙動を示していないかを見つけることが目的となります。
Machine Learningの設定画面を開くと、以下のような画面が表示されます。今回は一つのメトリックに対して機械学習を行う"Single Metric job"を例に挙げて説明していきます。
Single Metric jobで機械学習を行うために設定するのは以下の4つのみです。
・Aggregation(一定時間内のデータ数を見るのか、平均値を見るのか等)
・Field(どの変数を対象にするか)
・Bucket Span(どのくらいの時間をひとまとめにするか)
・Time Range(どの期間をMachine Learningの対象にするか)
今回はAggregationにSum、Fieldsにtotal(何回のアクセスが来たか)、Bucket Spanに30m、Time Rangeはデータが含まれている時間全体を指定して、機械学習を行っていきます。ここまで設定を行うと、今回扱う時系列データの概要を見ることができるので、"Create job"ボタンを押して機械学習を開始させます。
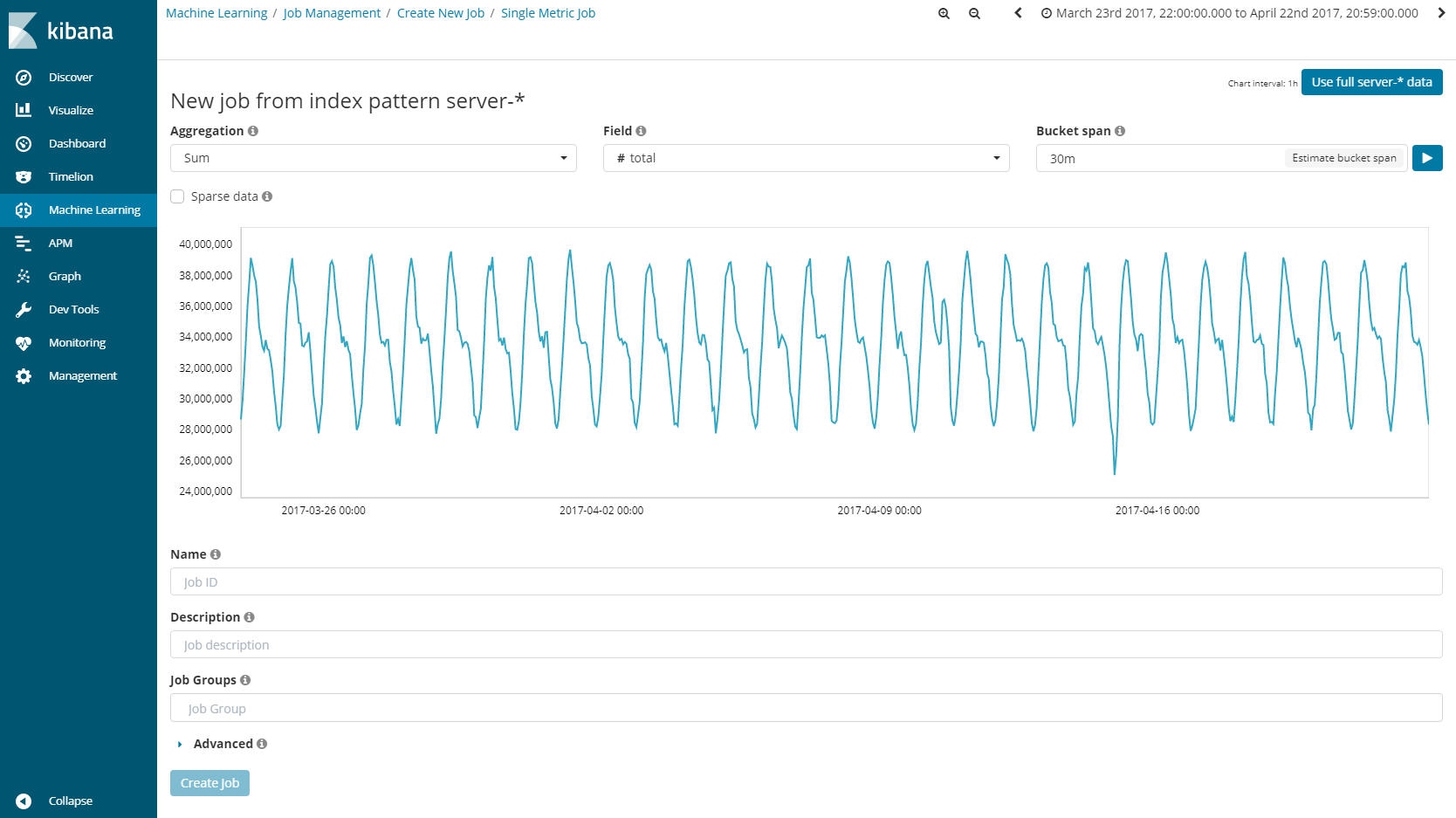
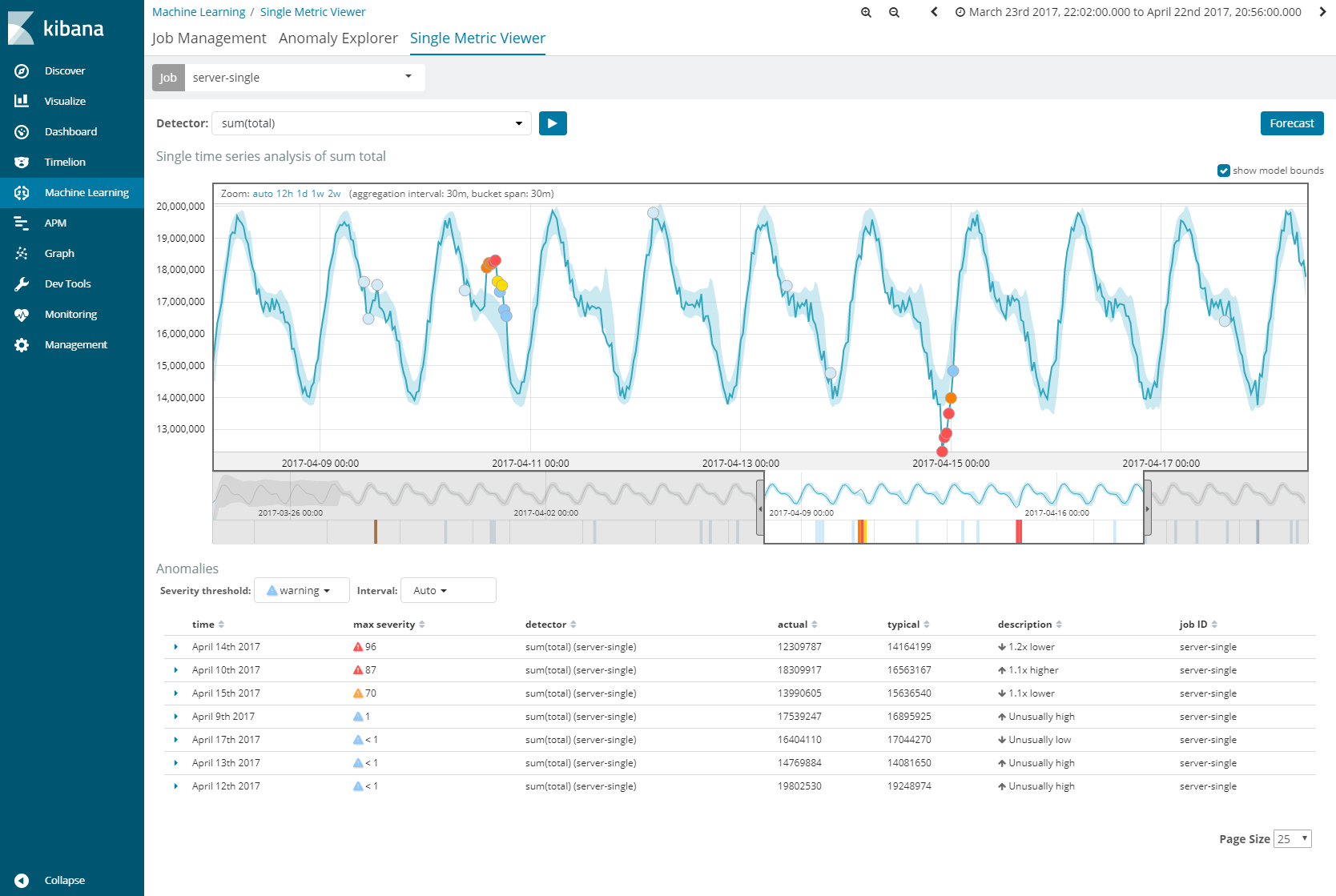
図7は機械学習を行った後の画面です。濃い青色の実線が取得した値を表し、水色で表されるエリアが機械学習により予測された値の範囲で、このエリアから外れると、異常として検知(赤やオレンジの点)されます。この異常と検知された点については、異常具合を数値化したAnomaly Scoreや実際の値と予測された値がどれだけ異なるのか等、詳しい情報が表示されます。閾値をベースとした検知とは異なり、いつもと違うデータを検知するため、設定した閾値には届かないが値が急増(急減)した場合等も検知することができます。
バージョン6.1のMachine Learningからは、学習させたモデルから将来予測ができるforecast機能も付いています。この機能もSingle Metric jobを実行したあと、右上に表示されるforecastボタンを押し、予測したい期間を決めるだけで実行することができます。図8のように、黄色の実線で予測値を表し、薄い黄色のエリアが信頼できる範囲を表しています。
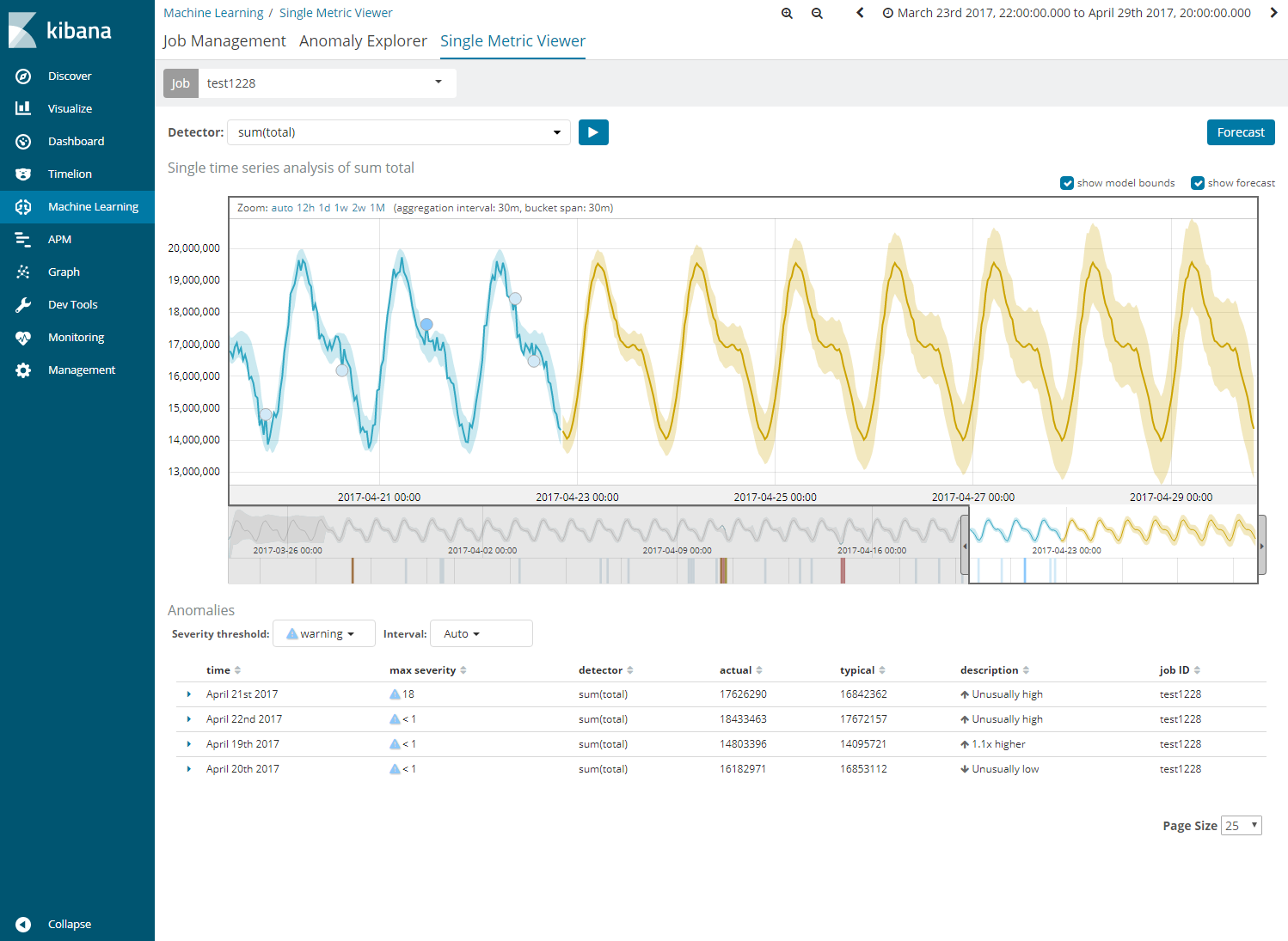
このforecastがどれだけの精度で予測できているのか、評価を行ってみました。今回の評価は、30日分のデータのうち、1-27日を使ってモデルを作成し、28-30日を予測した上で実測値と比較する方法をとりました。
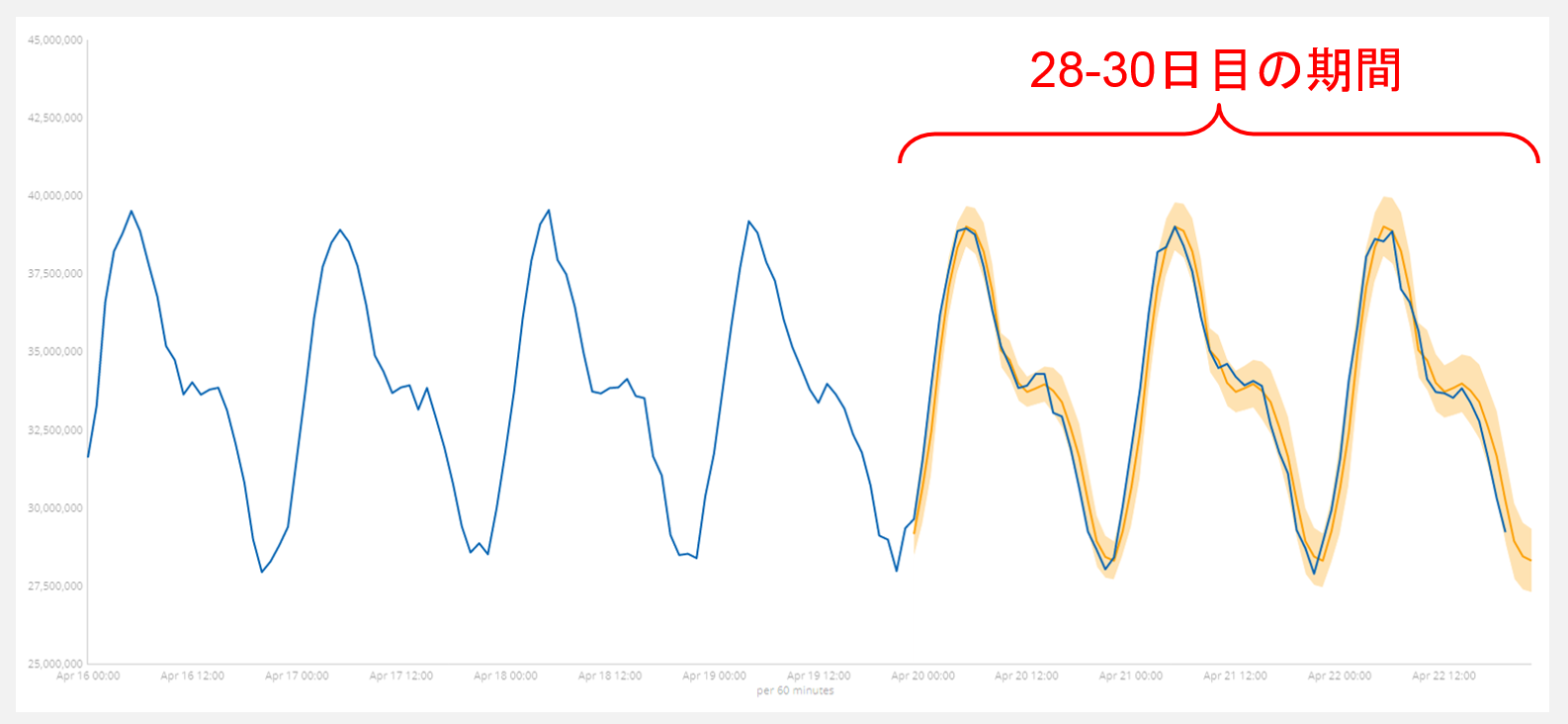
図9がその結果です。黄色で示される予測値の領域の中に、実測値である青の実線が入り込んでいることから、今回用いたデータでは、比較的良い精度で値を予測できたことがわかります。ただし、モデルを作成するデータによっては、良い予測ができない可能性もあることに注意してください。
これまでに示してきたような周期的に値が変わっていくデータだけではなく、他にも様々な時系列データが考えられます。例えばカウンターのような徐々に増えていく値に対して、このforecastを行うとどのようになるでしょうか。試してみた結果が図10になります。
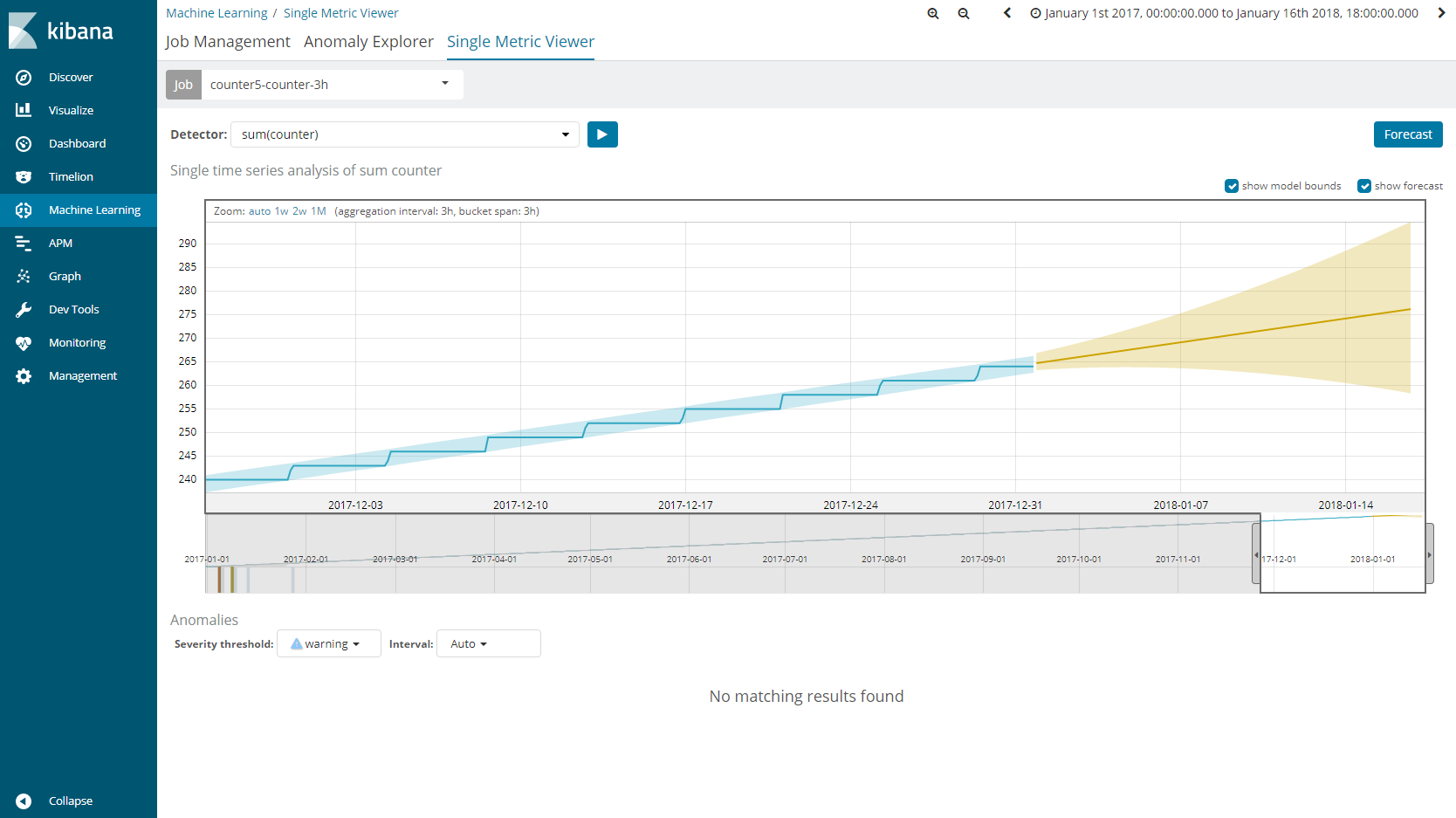
予測値である黄色い実線は直線的ですが、比較的現実的な値の増加を予測をできているように思えます。そのため、ある基準値に達するのはいつになるのかをここから推定することも可能です。ただし、これらの結果も過去にどれだけのデータを取得しているか、データのばらつき等に左右されることに注意してください。まずはElasticのMachine Learningを使ってみて、意図したような結果が出るのかを検証し、その結果からデータの取得間隔等をあらためて見直すことも重要になってきます。
なにか異常を検知した際に、それを通知する仕組みもX-Pack含まれるAlertingというコンポーネントで実行することができ、Machine Learningと連携できるため、こちらも簡単に実装することができます。
どのような点に注意すべきなのか?
第二回、第三回のコラムで、プログラミングレスな機械学習ツールを紹介してきましたが、このような非常に簡単に機械学習が行えるツールは、手軽さゆえに裏側で動くアルゴリズムについては詳しく解説されていないこともあります。そのため、どのように検知を行っているのか、深くまで知りたいと思っている方にはあまり得策ではないかもしれません。しかし、機械学習を行ってみることで、人間の目では気づくことのできなかったことに気づける可能性があります。
また、チューニングできる点もそれほど多くないことから、異常検知の精度を上げていくことにも苦労するかもしれません。これについてはデータの取得間隔を短くする等、データ収集の観点からも工夫が必要になります。初回のコラムにも書いたように、機械学習が上手く動くことが目的ではなく、解決したい課題が解決できているかを忘れずに進めましょう。
おわりに
今回紹介したElasticのMachine Learningについて、ルータから取得できるテレメトリー情報に対して行ってみた結果が過去の匠コラムにも書かれていますので、こちらもご参照ください。現在使われているSNMPがテレメトリーに置き換わることでデータの取得間隔が小さくなり、より多くのデータ取得が可能になるため、機械学習を使う場面も増えてくるのではないかと考えています。
全3回にわたり機械学習に注目し、機械学習を行う際の注意点やプログラミングレスのツール等を紹介しました。第三次AIブームが来ている今、自身の持つデータについて一度見直してみてはいかがでしょうか。難しそうとあまり構えず、まずやってみることをおすすめします。
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス推進本部
応用技術部 クラウドデータインフラチーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索