

- ナレッジセンター
- 匠コラム
仮想アプライアンスの提案で直面する致命的な課題とその対策 (DPDKに代表されるネットワークパフォーマンス改善手法) - 後編 -
- 匠コラム
- 効率化・最適化
- ネットワーク
ビジネス推進本部 応用技術部 コアネットワークチーム
井上 勝晴
2013年にETSI NFV ISGによりNFVの全体像を形作るGroup Specificationが公開されてから3年が経過し、「NFV」という単語を当たり前のように耳にするようになりました。
弊社ネットワンシステムズはNFV PoC(Proof-of-Concept)を自社ラボに構築し、「可用性、運用保守性、柔軟性」をKeywordとした幾つかの実証試験を行いました。(ネットワン NFV の全貌と市場への挑戦②)
このような活動の中、複数のお客様より、NFVが汎用x86サーバー上で提供されるが故のパフォーマンス面への懸念点を多く頂戴しました。そのような背景もあり、NFV環境におけるパフォーマンス課題とその解決方法について、実環境である弊社PoCを用いて実証実験を行いましたので、その結果を本コラムにて前編・後編に分けてご紹介したいと思います。(後編)
| 連載インデックス |
|---|
スループット向上手法
NFVの様な仮想化環境においては、複数個所にボトルネックが存在し、それらへの対処が必要である事を前編にてご説明致しました。ではこのようなボトルネック問題に対し、どのような方策が提供されているのでしょうか。その幾つかを、本コラムにてご紹介させていただきます。
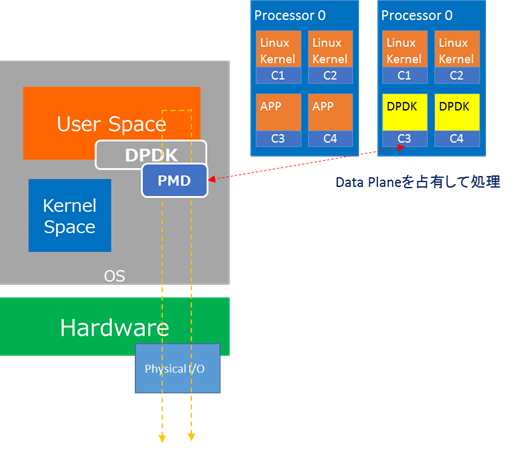
DPDK(Data Plane Development Kit)
DPDKは、Packetの高速処理を目的とした複数ドライバと複数ライブラリより構成されています。
Kernel Space上で動作していたネットワーク処理機能を、User Space上の1つのアプリケーションとして動作させるものになります。
下図にありますように、特定のCPUコアをデータプレーン処理用途に占有させる事により、パフォーマンスを向上させる事が可能となります。Poll mode driverにて、KernelをbypassしてPhysical Interfaceに届いたPacketを直接処理します。
このように、Kernel space上のネットワーク処理のボトルネックを解消するアプローチになります。
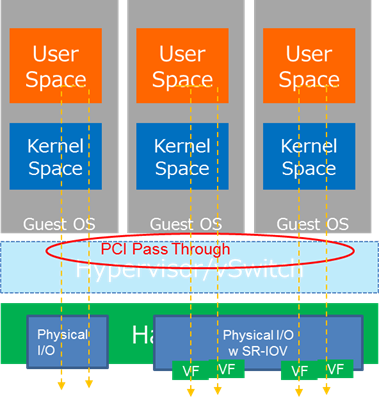
PCI Pass Through with SR-IOV(Single Root I/O Virtualization)
通常の仮想化環境ではVMはHost上の各種Deviceに直接アクセスする事は不可であり、仮想化レイヤがエミュレートした仮想Deviceを利用する形を取ります。
そのため、この仮想レイヤの負荷に引きずられる形でパフォーマンスの低下が発生します。
PCI Pass Throughは、VMがホスト側のPCI Deviceに直接アクセスする事を可能とする技術です。仮想レイヤをBypassしてDeviceを直接制御するため、細かな制御も可能となり、Nativeに近いパフォーマンスが可能になると言われています。
PCI Pass Throughの実現方法として、Intel社からIntel VT-dが、AMD社ではAMD I/Oが、機能として提供されています。
次にSR-IOVですが、この技術はPCIデバイス側で仮想化をサポートする規格になります。
下図で説明しますと、左のトラッフィックにありますように、PCI Pass ThroughでGuest OSから直接物理Portを参照可能としますと、その物理Portが1つのVMに占有される事となります。その為、VMが増えるとその分、物理ポートが必要となります。
SR-IOVによるPCIデバイスの仮想化により、1つの物理ポートは複数の仮想ポートに分割され、中央と右側トラッフィクにありますように、複数VMで共有する事が出来るようになります。
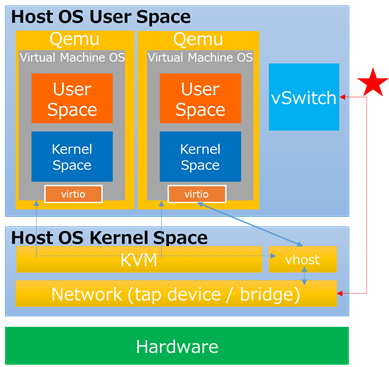
vhost-User
前述のDPDKをOVSに適用させると、OVSプロセスがUser Spaceに存在する事になります。これは、VMからのトラッフィックには、OVSがHost kernelとVMの間に介在する事を意味します。
このようなUser Space内に複数アプリが介在するTrafficパターンでは、(Host Kernel内にvhost backedが存在する)従来のvhost-netによるqemuのバイパスでは不十分であり、煩雑なContext switchが依然存在する事となります。(下図★)
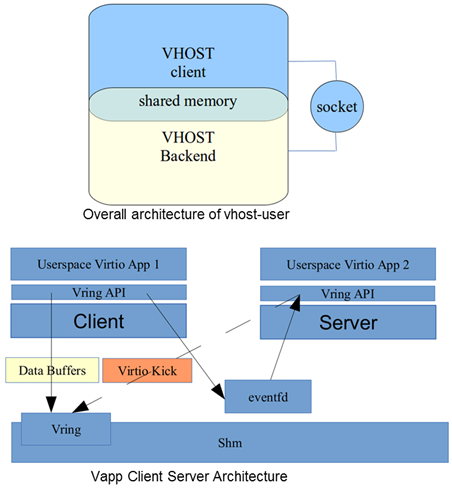
このようなケースに対する方策としてvhost-userが考案され、OVSが介在するケースにおいてもContext switchの削減が可能になります。
では、このvhost-userの仕組みを簡単に説明したいと思います。
基本的なコンセプトは、
「従来のvhost-netではKernel内に存在したvhost backendをUser Spaceに設置し、User Space内で動作する2つのアプリ間でダイレクトコネクトを提供する事によりContext switchの削減を達成する。」、
となります。
vhost clientとvhost backend(server)のより構成され、2つのアプリ間でやり取りされるデータは共有メモリ上で実行されます。利用シーンとしては、vhost backend機能を備えたOVSとvhost clientでディプロイしたVMとで動作する事により、2つのアプリ間で最適化され、Context switchの削減が達成されます。(下図)
仮想化環境への適用
これまでご紹介した内容を纏めると以下のようになります。
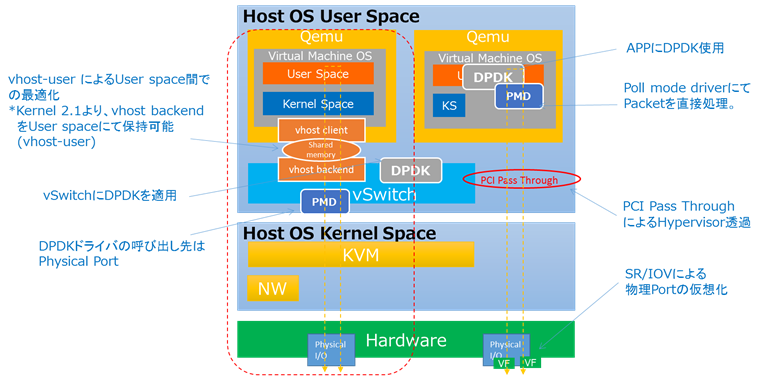
弊社NFV PoC環境に、上図赤枠で括った技術要素を適用し試験実施しましたので、以降にその結果をお伝えしたいと思います。
測定(効果比較)
前編の冒頭にあった試験環境Openstackに対しDPDKを有効にし(OVSをDPDK化)、且つ、VMをvhost user環境でディプロイし、同試験を実施致しましたので、結果をご下記の通りご説明致します。
Result 3. ovs折り返し(DPDK-OVS)
OVSの折り返し試験結果は以下となりました。
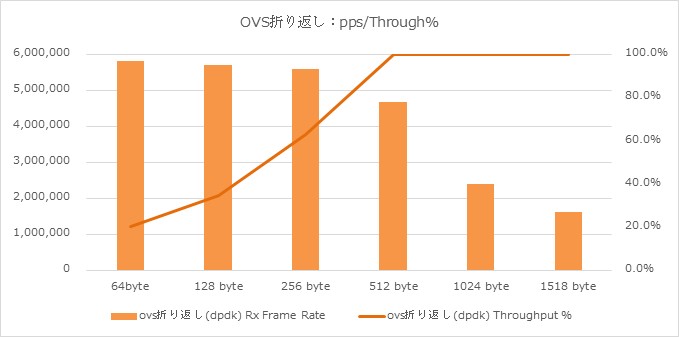
- 512Byeから1518Byteでラインレートを達成
- 256Byte長では約60%程度、64Byte長では約20%程度のスループットを達成
- Frame rateでは600万PPS弱を達成
と言う結果でありました。
Result 4. VM折り返し(DPDK-OVS with vhost-user)
VMの折り返し試験結果は以下となりました。
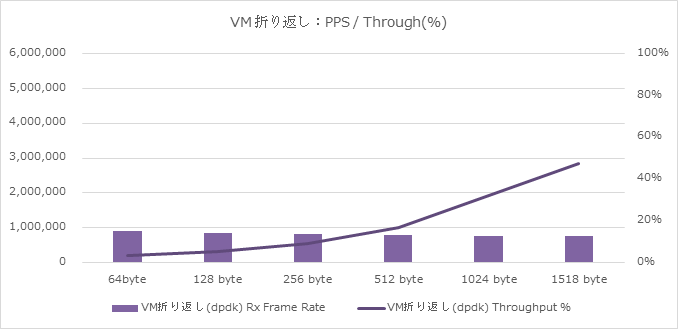
同様に20G双方向印可に対する達成率を記載していますが、
- 1518Byteで約50%を達成
- システムレベルでは90万PPS弱を達成
という結果になりました。
比較:OVS折り返し / VM折り返し(DPDK-OVS with vhost-user)
下記は、「OVS折り返し」と「VM折り返し」の試験結果を纏めたデータとなります。
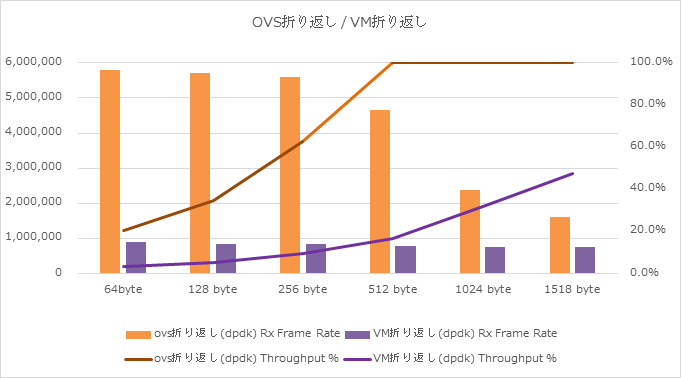
では、通常OVSとDKDP-OVSとを比較し、パフォーマンス改善具合を見たいと思います。
効果比較1:OVS折り返し(non-DPDK) / OVS折り返し(DPDK)
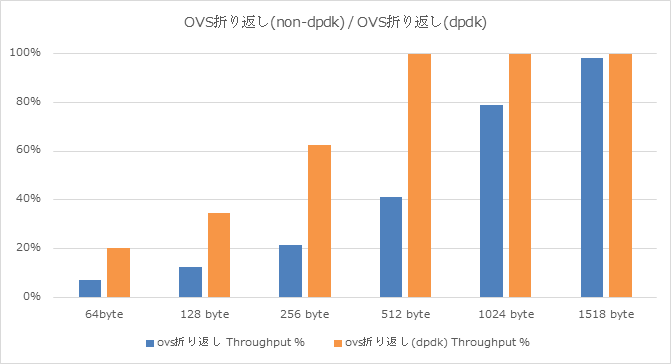
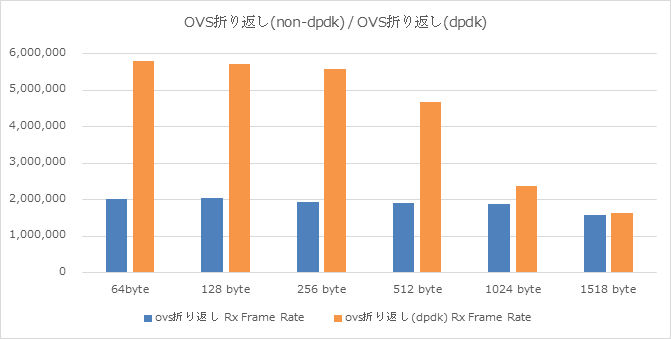
上記はOVS折り返しパターンにて、通常OVSとDPDK-OVSとを比較したグラフであり、
- 512 byte長にて約2.5倍
- 256 byte長にて約3倍
の効果を確認出来ています。
効果比較2:VM折り返し(non-DPDK) / VM折り返し(DPDK with vhost-user)
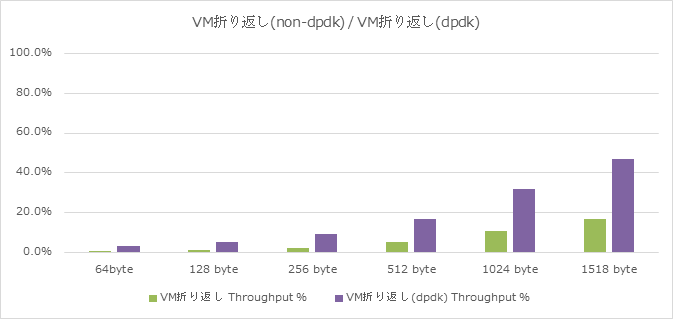
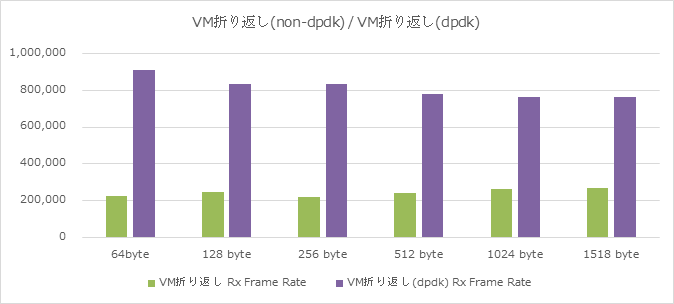
上記はVM折り返しパターンにて、通常OVSとDPDK-OVSとを比較したグラフであり、
- 512 byte長にて約3倍強
- 64byte長にて約4倍強
の効果を確認出来ています。
ご覧頂きましたように、仮想化環境のボトルネック対策として一定の効果を確認する事が出来ました。
まとめ
以上の検証データより、下記3点を纏めとして記します。
1. DPDKにより、基盤側と呼べるNFVI(OVS)のパフォーマンス改善が可能
(パフォーマンスはDPDKにアタッチするコア数に依存)
2. 性能低下が顕著であったVM部分についてもvhost-userとDPDKを組み合わせる事により、パフォーマンス改善が可能
3. VMの多重度や、East-West traffic(VM-VM間通信)を基に、基盤側(OVS)で必要となるパフォーマンスを検討する必要あり
弊社ネットワンシステムズは、各ベンダー様の協力を基に、本分野への取り組み強化しております。ご検討内容があれば、ご連絡頂ければと思います。
関連記事
執筆者プロフィール
井上 勝晴
ネットワンシステムズ株式会社 ビジネス推進本部 第1応用技術部 コアネットワークチーム
所属
エンタープライズ・サービスプロバイダのネットワーク提案・導入を支援する業務に、10年以上にわたり従事
現在はSDN・クラウドのエンジニアになるべく格闘中
- MCPC1級
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索