

- ナレッジセンター
- 匠コラム
プログラミングなしでできる機械学習-Splunkを使った教師あり機械学習-
- 匠コラム
- データ利活用
- AI
ビジネス推進本部 応用技術部
クラウドデータインフラチーム
片野 祐
最近、"AI"という言葉を聞かない日がないくらい、この分野は盛り上がりを見せています。本コラムでは、プログラムを書くことなく実行できる機械学習のご紹介をいたします。
| 連載インデックス |
|---|
はじめに
"機械学習"と聞くと、プログラミングや統計学の知識が必要で難しそうと感じるかもしれません。しかし最近ではデータさえ手元にあれば、自分でコードを書くことなく、またGUI上で直感的に使うことができる機械学習ツールがいくつも出てきており、機械学習を始める敷居が下がってきているように思います。そこで本コラムでは機械学習をプログラミングなしで実行できるSplunk社のツールを紹介し、どういった点に気をつけながら機械学習を進めていけば良いか、プログラミングなしでできる機械学習ツールでどのようなことができるのかについて、共有したいと思います。
Splunkとは
Splunkは機器から出されるあらゆるデータ(ログ、カウンター等)を取り込み、検索や分析を高速に行うことができるソフトウェアです。検索や分析の結果をダッシュボードにすることで、可視化も行うことが可能です。
SplunkにはAppsという機能拡張のための機能セットが1000以上公開されています。このAppsはSplunk社自身が作成し公開しているものもあれば、他のベンダーが作成し公開しているものもあり、このAppsを使うことでSplunkと他ベンダーの機能連携を比較的容易に行うことができるようになります。Appsは無償で公開されているものも多くあり、今回紹介するSplunk Machine Learning Toolkit(MLTK)もSplunk社が公開している無償のAppsのひとつです。(MLTKの参考はこちら)

第三次AIブームと言われている中、2017年9月に行われたSplunk社のカンファレンスであるSplunk .conf 2017においても、機械学習の新たなメインストリームを作ることが明言されており、Splunk社としても機械学習は注力していく分野であると言えます。(参考はこちら)
Splunk Machine Learning Toolkit(MLTK)で行う機械学習
Splunk Machine Learing Toolkit(MLTK)は、Splunk上で機械学習を行うのに使うAppsです。MLTKはバージョン1.0が2016年3月にリリースされ、着々とバージョンアップが進み、2018年1月現在ではバージョン3.1がリリースされています。ダウンロードは2.5万件を超えていることからも、多くの方がこの機械学習に興味を持っていることがわかります。MLTKにはサンプルのデータセットやシナリオが準備されているため、機械学習を行うデータが手元になくてもMLTKがどのようなものか簡単に試すところから始めることができます。
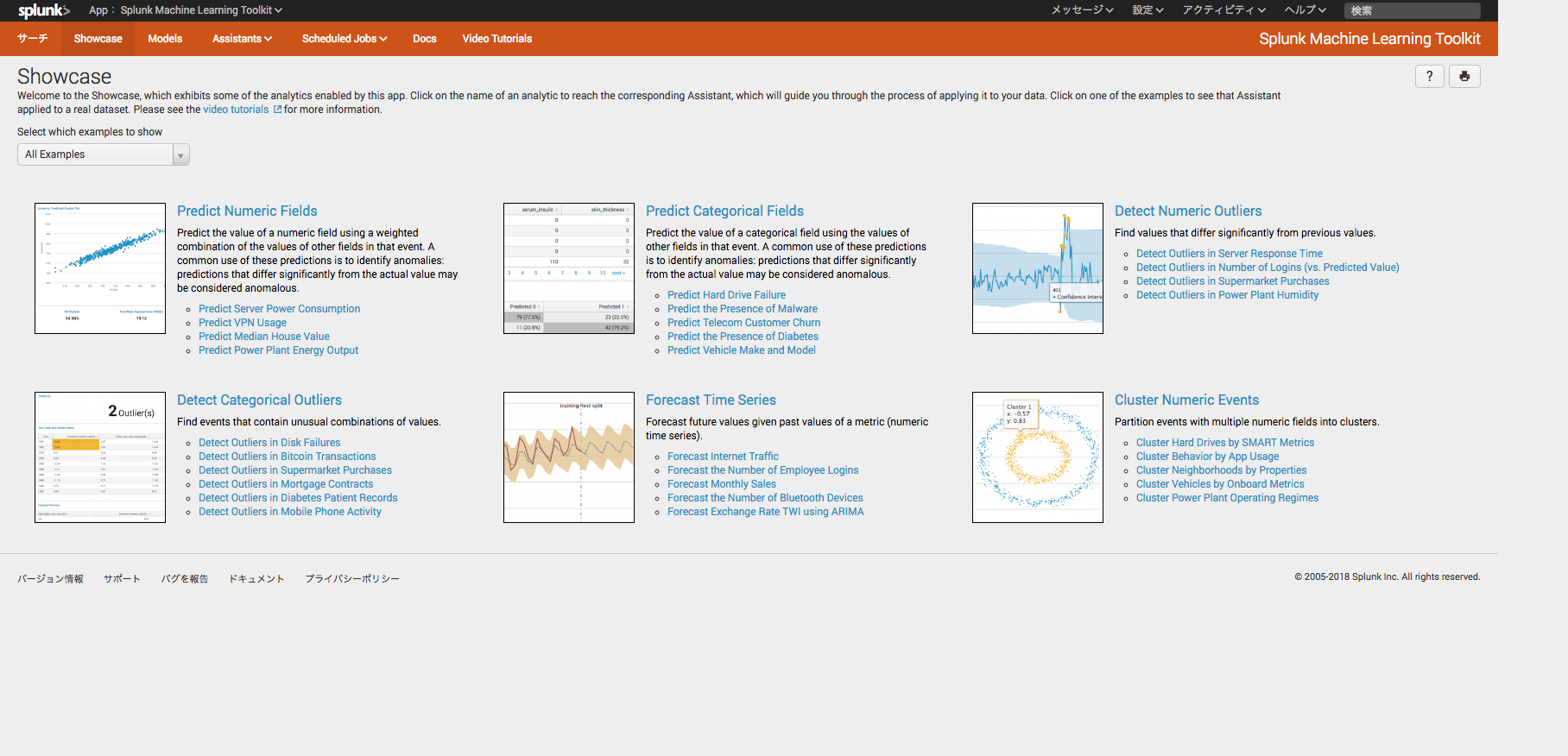
MLTKのShowcaseにアクセスすると、図2の画面が表示されます。MLTKを使用した機械学習には大きく以下の6種類あります。
- Predict Numeric Fields(数値の予測)
- Predict Categorical Fields(カテゴリの予測)
- Detect Numeric Outliers(数値的な外れ値の検知)
- Detect Categorical Outliers(カテゴリの外れ値の検知)
- Forecast Time Series(時系列データの将来予測)
- Cluster Numeric Events(数値的なイベントのクラスタリング)
それぞれのカテゴリにおいて、IT, Security, Business, IoTの分野のサンプルが準備されています。今回はPredict Numeric Fieldsの中のITのサンプルであるPredict Server Power Consumptionを例にとり、どのような流れで機械学習が進むのか紹介していきます。今回紹介するものは教師あり機械学習の例となります。
※教師あり機械学習...事前に与えられたデータ(正解の入っているデータ)を "教師データ" として学習させ、モデル作成に使うことで、未知のデータに対して分類や回帰を行うもの。
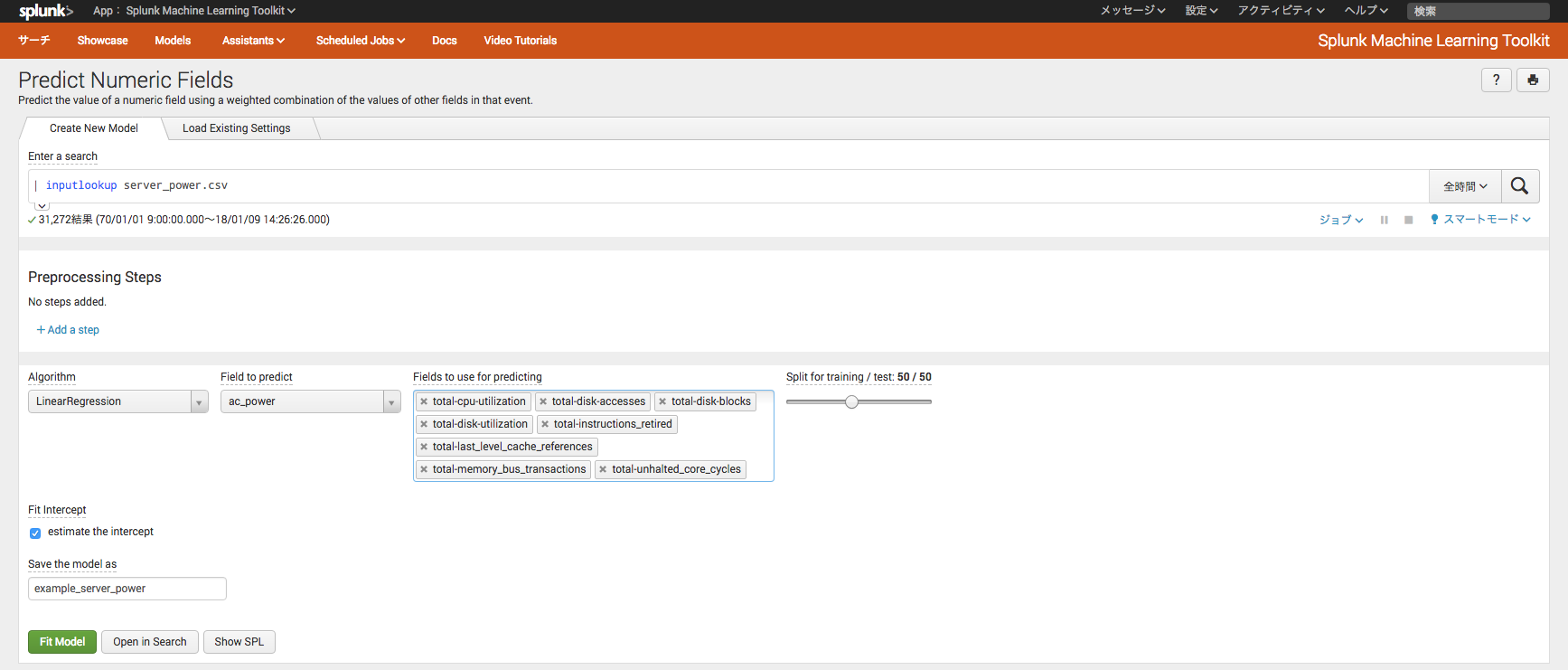
Predict Server Power Consumptionのシナリオは、過去に測定したサーバのCPU使用率やディスク使用率、ディスクアクセス数、消費電力等のデータから、特定の条件下におけるサーバの消費電力を予測したい、というものです。図3は機械学習を行うために必要なパラメータを設定する画面です。
今回消費電力の予測を行うために、以下のような流れで行います。
1.データ入っているCSVファイルを読み込む
今回使用するserver_power.csvというCSVファイルを読み込みます。今回はSplunk内部にある静的なデータだけを用いていますが、ストリーミングデータを使うことも可能です。
2.使用するアルゴリズムを選択する
消費電力の予測に、LinearRegression(線形回帰)というアルゴリズムを使用します。その他にもあらかじめ、RandomForestRegressor, Lasso, KernelRidge, ElasticNet, Ridge, DecisionTreeRegressorというアルゴリズムが用意されています。利用するデータや予測したい事象によって、適したアルゴリズムを選択する必要があります。
3.予測したいカラムを指定する(目的変数の設定)
サーバの消費電力を予測したいので、目的変数にac_powerを指定します。目的変数とは、その名の通り求める目的とする変数です。読み込んでいるCSVファイルにはカラム名があらかじめ含まれているため、Splunkはそれを自動で認識してカラム名を表示してくれます。
4.予測に使うカラムを指定する(説明変数の設定)
サーバの消費電力を予測するために使う説明変数を指定します。説明変数とは、目的変数の値を予測する際に、参考とする変数です。今回は以下の変数を指定しています。
- - total-cpu-utilization
- - total-disk-accesses
- - total-disk-blocks
- - total-disk-utilization
- - total-instructions_retired
- - total-last_level_cache_references
- - total-memory_bus_transactions
- - total-unhalted_core_cycles
使用する説明変数により、機械学習の結果が変わってくるため、どの変数を選ぶかも一つのポイントになってきます。例えば今回は "_time" という日時が含まれているカラムは使っていません。
5.トレーニングデータとテストデータの分割の割合を決める
50:50を指定します。
※作成した機械学習のモデルの予測精度を確かめるために、データを分割して片方(トレーニングデータ)でモデルを作り、もう片方(テストデータ)を予測に使用します。テストデータにも実測値は含まれているため、実測値と予測値を使って精度を計算することができます。
6.モデル構築と予測を開始し、精度を評価する
Fit Modelボタンを押すことでモデルの構築を開始し、作成されたモデルを使って予測を行います。その結果はあらかじめ用意されているダッシュボードに反映されます。
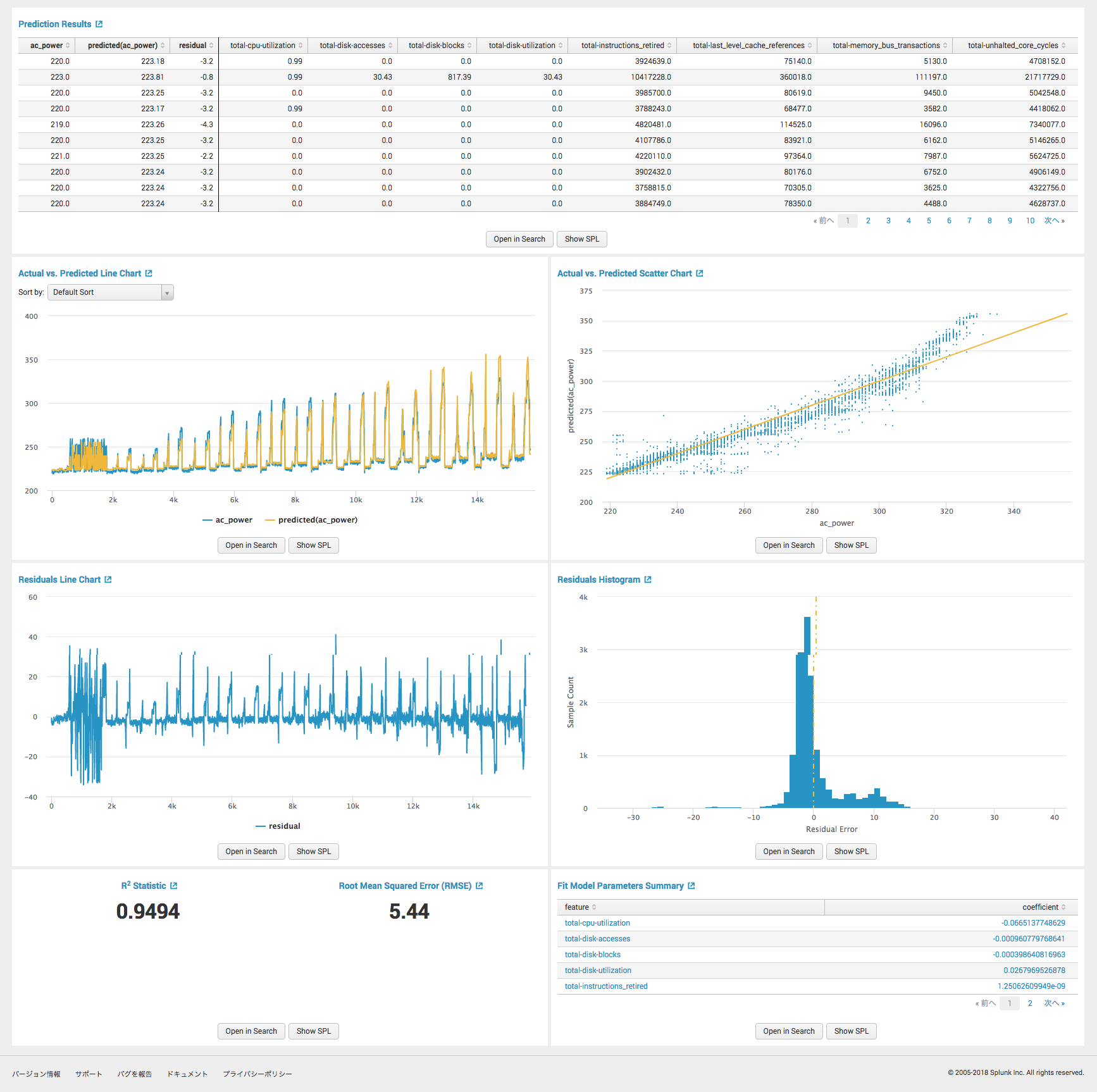
今回行ったサーバの消費電力の予測の例では、図4に表すように結果が表示されます。以下では、作成されたグラフを一つずつ簡単に解説しています。
・Prediction Results
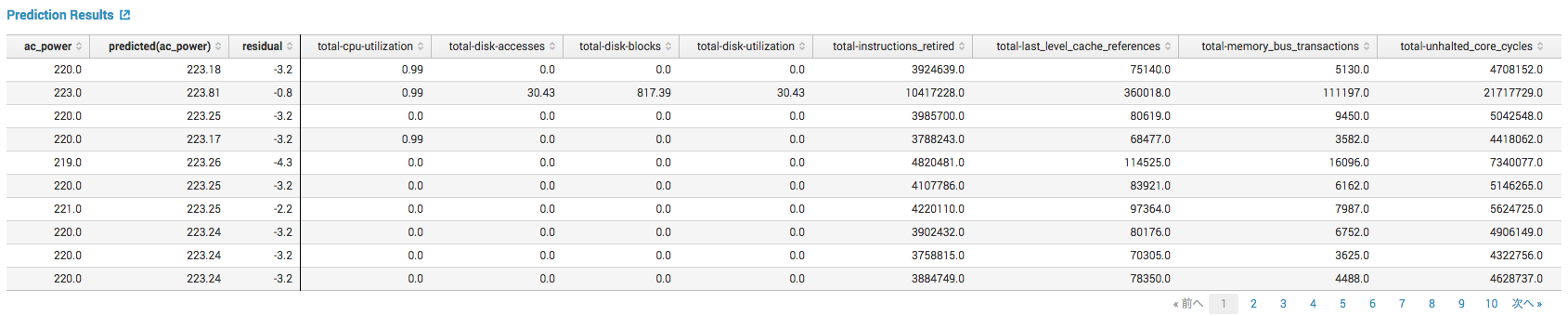
目的変数、予測値、残差、説明変数が表形式で表示されます。
・Actual vs. Predicted Line Chart
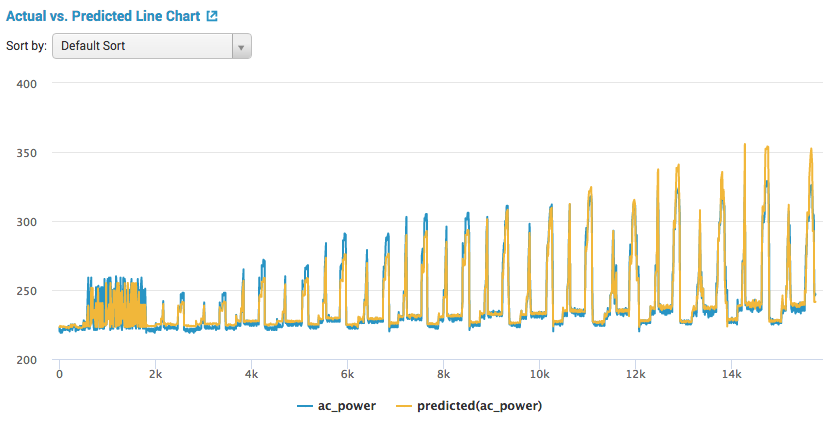
テストデータの実測値と機械学習によって予測された値を折れ線グラフで比較。青い線と黄色い線が重なっているほど、予測精度が高いと言えます。
・Actual vs. Predicted Scatter Chart
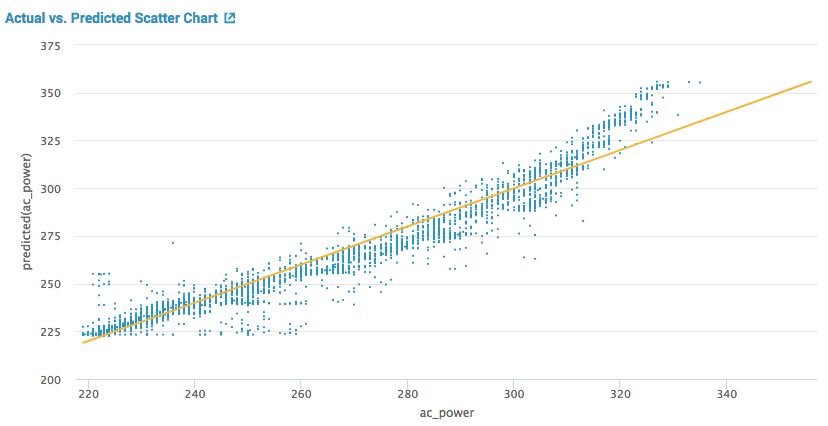
テストデータの実測値と機械学習によって予測された値を散布図で比較。黄色の直線はx=yの線であり、実測値(x)と予測値(y)が同じ値のとき、この直線上に点が打たれます。
・Residuals Line Chart
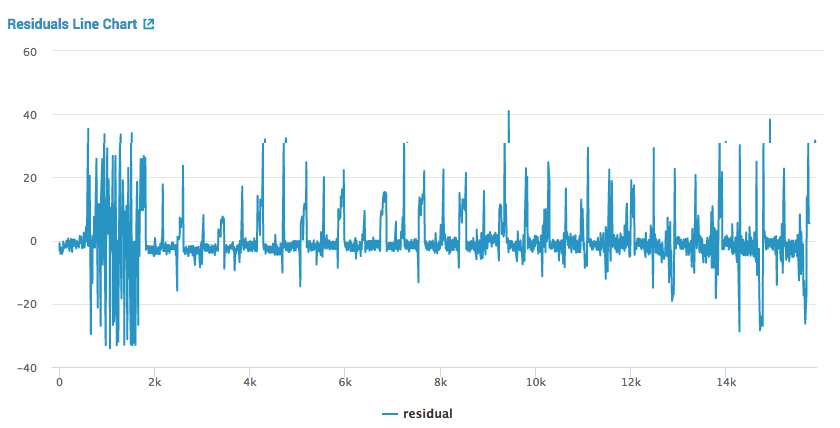
テストデータの実測値と機械学習によって予測された値の残差を折れ線グラフで比較。予測精度が高いとき、グラフは0に近い値を取ります。
・Residual Histogram
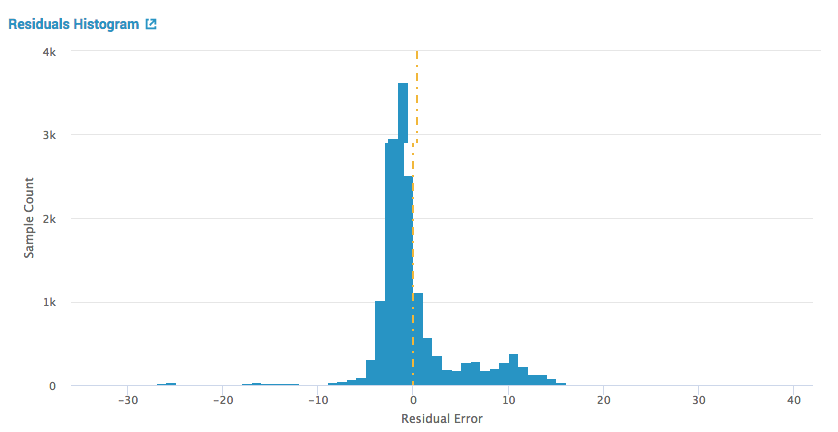
テストデータの実測値と機械学習によって予測された値の残差のヒストグラム。残差のばらつきを見ることができます。
・R2 Statistic, Root Mean Squared Error(RMSE)

R2は決定係数と呼ばれる値で、1に近いほど残差が少ないことが示されます。また、RMSEは平均平方二乗誤差と呼ばれる値で、小さいほど予測誤差が小さいことが示されます。
・Fit Model Parameters Summary
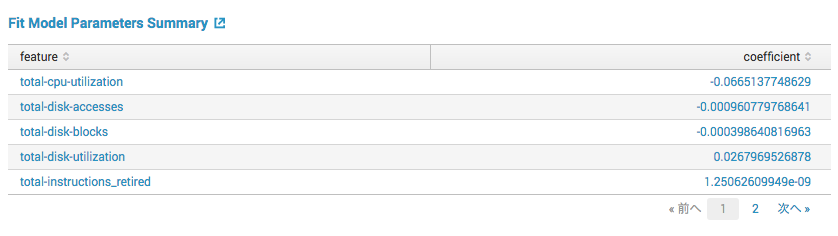
今回選択したLinearRegressionというアルゴリズムでは、内部で直線の数式を作って値を予測しています。この数式の各説明変数の係数がここに示されます。この係数が大きいと、予測値に対する説明変数の影響度が高くなります。また、interceptは切片を表します。
試しに説明変数を少し減らして学習させてみると、図5のような結果になります。
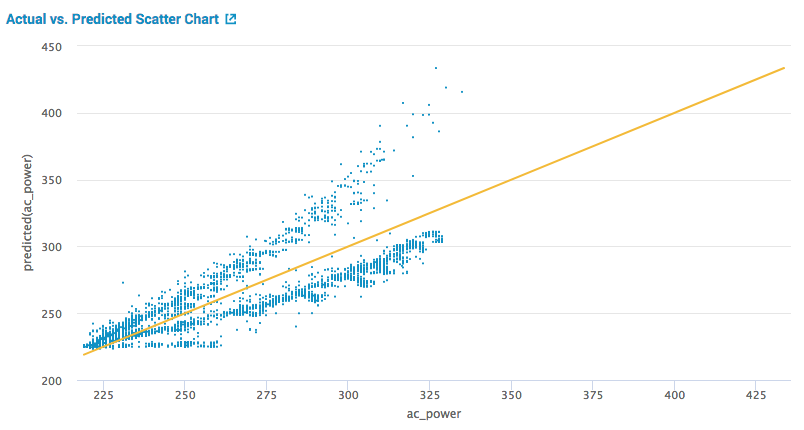

図5の"Actual vs. Predicted Scatter Chart"を見ると、図4に比べて実測値と予測値が一致していることを表す黄色い線から青い点が外れていることや、"R2 Statistic"の値が小さくなっていること、"RMSE"の値が大きくなっていることがわかります。このことから、今回説明変数を減らしたことにより、予測精度が下がってしまったことがわかります。このように、少しパラメータを変えるだけで、結果が(良くも悪くも)大きく変わることもありますので、試行錯誤しながら最適なパラメータを選択することになります。
以上のように、プログラミングを一切することなく、GUIのみで機械学習を実行することができました。ここで作成された機械学習モデルは保存できるので、これから得られる未知のデータに対してこのモデルを適用することで目的変数の値を予測することができます。
どのような点に注意すべきなのか?
今回の例ではある程度精度の高いモデルができましたが、精度の低いモデルができることももちろんあります。そのため、さらに予測精度を上げたい場合は、アルゴリズムの変更や説明変数の変更といったチューニングをする必要があります。プログラミングなしの機械学習ツールでは簡単に機械学習を行える反面、チューニングできる部分が少ないこともあるので注意が必要です。
また、機械学習の知識がほとんどなくても機械学習が行えるようになりましたが、機械学習の結果を判断したり、適したアルゴリズムを選択したり、パラメータのチューニングを行う際には、ある程度の機械学習の知識が必要になります。簡単に機械学習を行えますが、学習にかかるコストはゼロではないことに注意が必要です。
機械学習モデルは一度作ったら終わりというものではありません。新しいデータが取得できた場合は、そのデータを使って新しいモデルを作ったほうがより良いモデルになると思われます。そのため、リアルタイムにデータを取り込む仕組みや、機械学習モデルを定期的に改良することをあらかじめ視野に入れておくことをおすすめします。
おわりに
今回のコラムではSplunkのMLTKを使った機械学習を紹介しました。今回紹介した部分は無償で使うことができるため、機械学習を行ってみたいと考えている方は、まず使ってみてはいかがでしょうか。他にもいくつかプログラミングなしで簡単に使える機械学習ツールがありますが、次回のコラムではプログラミングなしで教師なし機械学習を行うことができるElastic社のツールをご紹介します。
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス推進本部
応用技術部 クラウドデータインフラチーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索