

- ナレッジセンター
- 匠コラム
vSphere with Kubernetes (Project Pacific)
- 匠コラム
- プロダクト
- 仮想化
ビジネス開発本部 第1応用技術部
第2チーム
奈良 昌紀
はじめに
VMware Tanzuはモダンアプリケーションの開発(Build)・実行(Run)・管理(Manage)を実現するソリューションのポートフォリオです。昨年米国で開催されたVMworld 2019ではVMware Tanzuにおける「実行(Run)」を実現するソリューションとしてProject Pacificが発表されました。先日VMwareが発表したvSphere 7ではこのProject Pacificと呼ばれていた機能を「vSphere with Kubernetes」機能として搭載し、vSphere環境をコンテナ実行環境として活用することを実現しています。本記事ではvSphere with Kubernetesの詳細に関してご説明します。
コンテナとモダンアプリケーション
コンテナは2013年にDockerが登場したことで大きく注目を集めることになりました。コンテナはDocker登場以前からLinux上でコンテナを利用することは可能でしたが、コンテナを隔離した環境で起動するためにはLinuxの様々な機能を設定する必要があり、コンテナを起動することやコンテナイメージを作成することが非常に煩雑でした。Dockerはこの煩雑なコンテナの利用のハードルを大きく下げ、開発者が必要とする一貫したアプリケーションの実行環境を提供しました。仮想マシンもアプリケーションをパッケージングするためのコンテナの一種と考えることができますが、コンテナイメージが必要なライブラリやアプリケーション実行環境だけで構成されるのと比べると、仮想マシンイメージはOS部分を含むためその容量には大きな差があります。また、起動時間もコンテナがプロセスレベルで起動できるのに対して仮想マシンはOSの起動時間が必要になるためコンテナはその軽量さとポータビリティという点で仮想マシンに勝っています。
Dockerによるコンテナの利用拡大に続き2014年にGoogleがKubernetesを発表しました。Kubernetesは複数のコンテナ実行用ホストをクラスター化しコンテナのオーケストレーションを実現します。KubernetesではコンテナをPodという単位で管理し、DeploymentやReplicaSetと呼ばれるリソースによりPodのバージョンを管理します。また、Pod間の通信やクラスター外部に対するアプリケーションの公開方法もServiceやIngressと呼ばれるリソースで制御することが可能です。Kubernetesの大きな特徴として宣言的(Declarative)にワークロードやサービスを管理できるという点があります。従来のインフラストラクチャはワークロードやサービスを命令的(Imperative)にワークロードを構成する方式が一般的です。例えば新たにVMを起動する場合に、テンプレートから3台のVMをクローンし、それぞれをPowerOnするという操作をクラスターに対して行います。これは目的の状態を作るために必要な手順を命令としてクラスターに指示していることになります。一方、Kubernetesでは、例えば3つのPodを起動したい場合、マニフェストファイルでPod数(replicas)を3として指定すると、Kubernetesクラスターはマニフェストの内容と現在のクラスターの現在の状態を照合し、差分を埋めるよう制御します。この照合と差分を埋める処理はMasterノードによって継続的に行われるため、Podの1つが何らの理由で停止してしまった場合もクラスターは自律的に新しいPodを起動しPod数が3になるようにします。Pod数を増やしたい場合もマニフェストファイルのPod数を更新することで、新しいPodが起動されます。この挙動は突き合わせループ(Reconciliation Loop)と呼ばれ、Kubernetesが宣言的な構成管理と自動化を実現するための役割を果たします。
コンテナやKubernetesがアプリケーションの実行環境として利用される一方で、アプリケーションの形も変わりつつあります。従来の一般的なアプリケーションは必要とする機能を単一のプログラムが提供するモノリシックと呼ばれるアーキテクチャで構成されています。モノリシックアーキテクチャのアプリケーションはパフォーマンスを改善する際に、アプリケーションを実行する仮想マシン単位でスケールアウトするため機能レベルで最適なリソースを割り当てることは困難です。また、アプリケーションに対する機能の追加や変更に際して、アプリケーション全体を修正する必要があるため、開発やテストのハードルは比較的高くなります。そこで、アプリケーションが必要とする機能をそれぞれ小さなサービスとして実装し、各機能同士がネットワークを介して連携することでアプリケーション機能を提供するマイクロサービスアーキテクチャが注目されることになりました。マイクロサービスアーキテクチャで構成されたアプリケーションは分散システムとして機能し、必要なサービスだけをスケールアウトする事が可能です。また、各サービスの独立性が高いため新しい機能の追加や変更もサービスレベルで行うことができるため、開発やテストのハードルを大きく下げることで、アプリケーション利用者が必要とする機能を速やかに実装することが可能になります。実際にNetflixやTwitterなどがマイクロサービスアーキテクチャを導入することで顧客のニーズに対して迅速に機能を提供し、成功を収めたことで、モダンなアプリケーションのアーキテクチャとして大きく注目されます。Kubernetesはこのようなモダンなアプリケーションのプラットフォームとして広く利用されています。
vSphereのコンテナ対応とvSphere with Kubernetes
vSphereは仮想マシンを実現するハイパーバイザーであるESXiと、vCenterと呼ばれるハイパーバイザー管理サーバーによって構成されます。仮想マシンはvCenterを通じて一元的に管理され、仮想マシンのライブマイグレーションを実現するvMotionや、仮想マシンの可用性を高めるvSphere HA、ハイパーバイザークラスター内で仮想マシンをスケジューリングするvSphere DRSなどの強力な機能が支持を得て広く導入が進みました。vCenterの持つAPIを利用して仮想マシンを管理することができるためインフラの自動化の基盤としてvSphereを利用されるケースも多く、IaaS基盤として広く利用されています。しかし、アプリケーションのモダナイゼーションが進むことでワークロードの形式が仮想マシンからコンテナに広がります。vCenterだけではこれら全てのワークロードを管理することは困難です。そこでVMwareは2014年頃から対外的にコンテナに対する取り組みを開始しました。2014年のVMworldでTechnology PreviewとしてProject Fargo、2015年にProject Bonnevilleを発表しました。Project Fargoは仮想マシンをコンテナの様に高速に起動するために現在のインスタントクローンの機能を活用するものでした。Project BonnevilleはvSphereをDockerホストのように利用することを可能にし、コンテナの代わりに軽量なVMを起動することで、コンテナのような高速な起動と、仮想マシンならではの高い隔離性を実現するものです。Project Bonnevilleは現在vSphere Integrated Container(VIC)として提供されています。Project Pacificはこれらのコンテナに対する取り組みの延長として、2019年のVMworldで発表されました。VICと同じ様にハイパーバイザーをコンテナの実行環境として活用し、vSphere環境内にKubernetes互換の独自のコントロールプレーンを実装することで、vSphereクラスターをKubernetesクラスターとして利用することを実現します。従来のインフラ管理者の視点で見ると、vSphereクラスターとして管理可能で、vSphereクラスターを利用する開発者の目線で見るとKubernetesのように利用することが可能になります。
コンテナの代わりに軽量なVMを利用するテクノロジーはワークステーション向けにも開発が進められています。現在Project NautilusとしてVMware Fusion 20H1 Pro Tech Previewが公開されています。
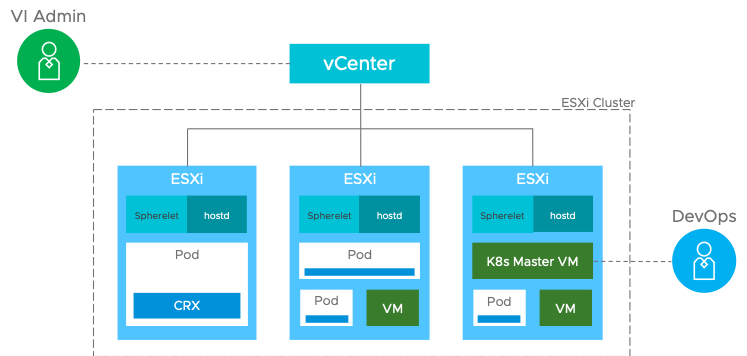
出典 : https://blogs.vmware.com/vsphere/2019/08/project-pacific-technical-overview.html
Supervisor Cluster
ワークロード管理
「vSphere with Kubernetes」を利用するにはvSphere Client上の「ワークロード管理」画面でKubernetesの機能を有効化する必要があります。ワークロード管理を有効化するためのウィザードが提供されており、Kubernetesクラスターとして利用する際に利用するネットワークに関する情報を指定することにより、NSXの論理ネットワークが構成され、vSphereクラスターをKubernetesクラスターとして利用するための準備が整います。
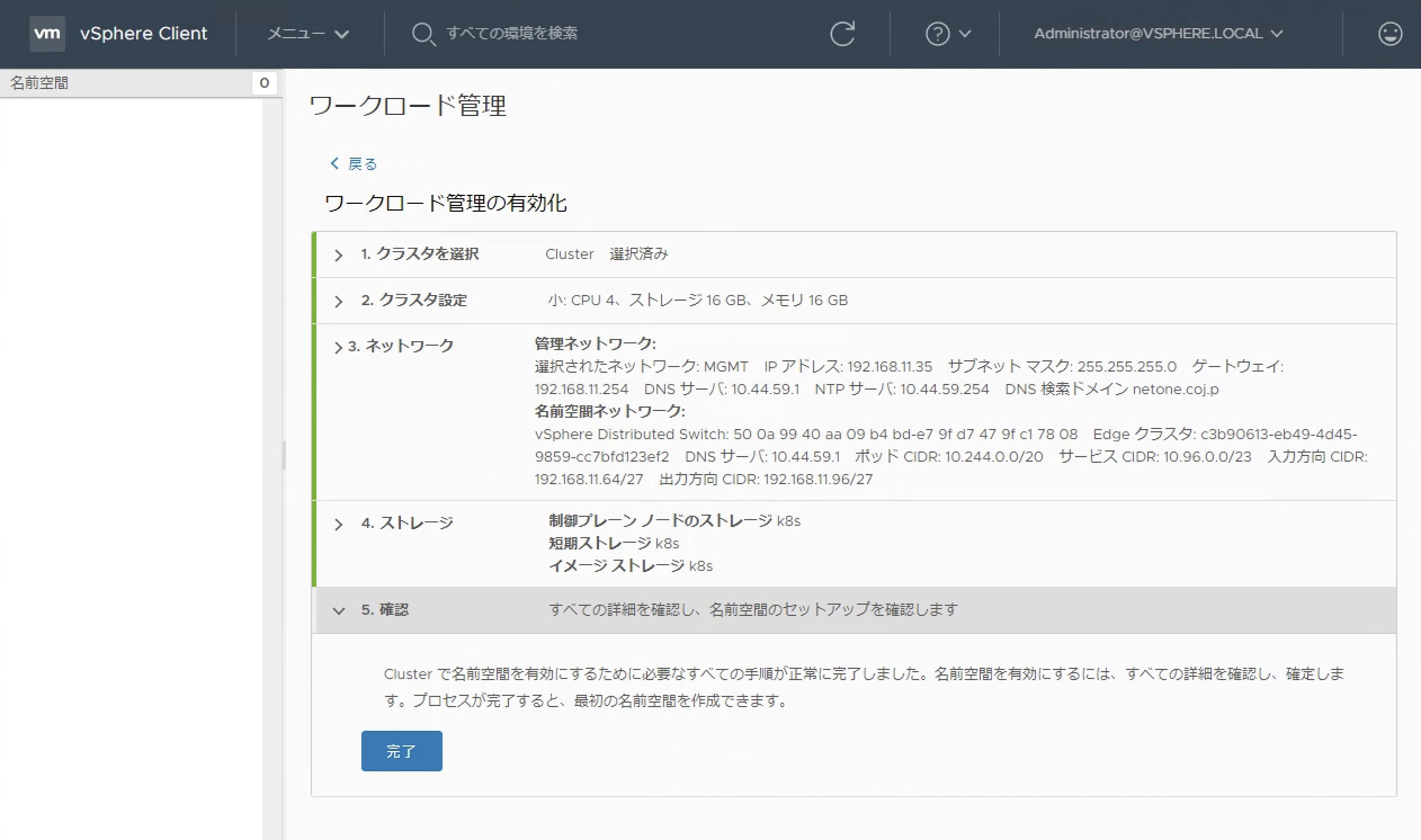
vSphereクラスターをKubernetesクラスターとして利用するには、Kubernetes APIをvSphere APIに変換する機能が必要です。これを実現するのがSupervisor Control VMです。Supervisor Control VMは3台の仮想マシンで構成されるクラスターです。通常のKubernetesクラスターではMasterと呼ばれる3台のノードがapiserver, controller, scheduler等の管理機能を持ちますが、vSphere with Kubernetesでは3台のSupervisoer Control VMがこれらの機能を提供します。各ESXiホストにはSphereletと呼ばれるモジュールが追加され、Supervisor Control VMと通信しています。vSphere with Kubernetesを有効化し、Supervisor Clusterのノードを確認するとControl VMがMasterとして存在し、クラスターのESXiホストがNodeとして機能していることを確認することができます。
# kubectl get nodes NAME STATUS ROLES AGE VERSION 421c04f095e468b5a0813982db08e6a9 Ready master 99m v1.16.7-2+bfe512e5ddaaaa 421c24039a9a086df55f443c92f991da Ready master 98m v1.16.7-2+bfe512e5ddaaaa 421c8103321f0ef8a4babdefb1cf7d41 Ready master 108m v1.16.7-2+bfe512e5ddaaaa pesx1 Ready agent 89m v1.16.7-sph-4d52cd1 pesx2 Ready agent 89m v1.16.7-sph-4d52cd1 pesx3 Ready agent 89m v1.16.7-sph-4d52cd1 pesx4 Ready agent 89m v1.16.7-sph-4d52cd1
ネームスペース(名前空間)
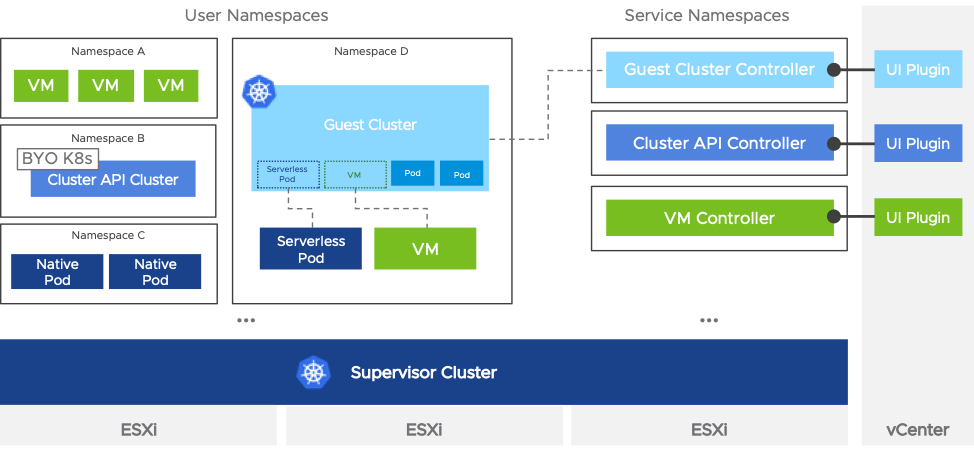
Kubernetesではネームスペースリソースによりクラスター内を論理的に分離することが可能です。Supervisor Clusterでもネームスペースを利用することが可能です。ネームスペースの実体としてvSphereのリソースプールとフォルダオブジェクトが作成され、ネームスペース単位でリソースを制限し、ネームスペース内にNative Podや後述するGuest Clusterを作成することが可能です。作成したネームスペースはvSphere Client上で稼働状況を確認することが可能です。
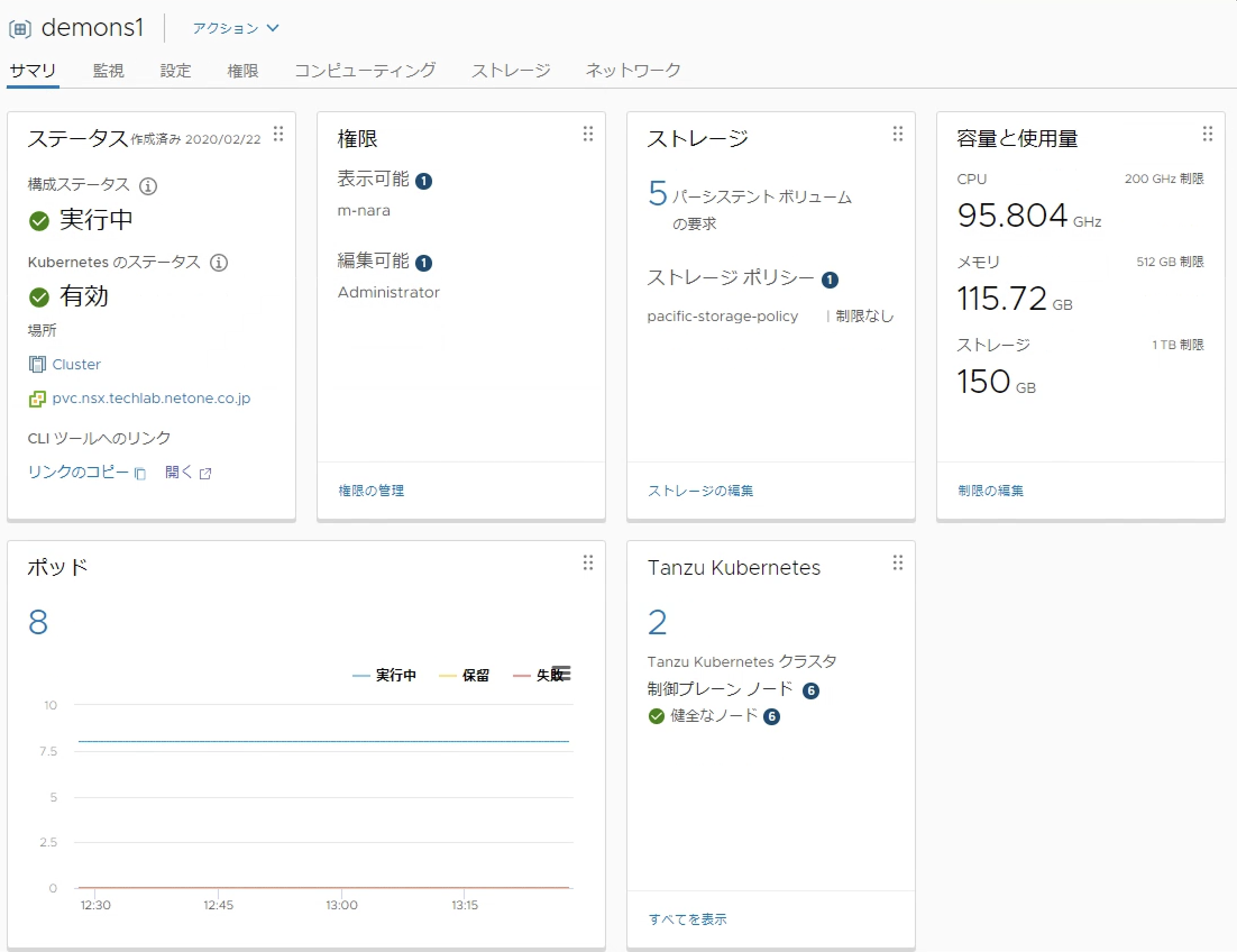
また、各ネームスペース内で論理的に分離されるため同じ名前のリソースを配置することが可能になります。また、各ネームスペースには表示だけ可能なユーザー、編集可能なユーザーの割当を行うことができ、ネームスペース利用者に対するアクセス制御が可能です。
コンピュート機能
Kubernetes環境ではPodと呼ばれる単位でコンテナを管理します。vSphere with KubernetesではこのPodをESXiホスト内のCRXと呼ばれる技術で、ハイパーバイザーに統合されたLinuxカーネルを利用して非常に軽量な仮想マシンとして起動します。この仮想マシンはNative Podと呼ばれ、vSphereクライアント上でNative Podとして管理されます。通常のKubernetesと同じ様に単一のNative Pod内で複数コンテナを実行することも可能です。Native Podは通常の仮想マシンと異なり、編集したりvMotionすることはできません。
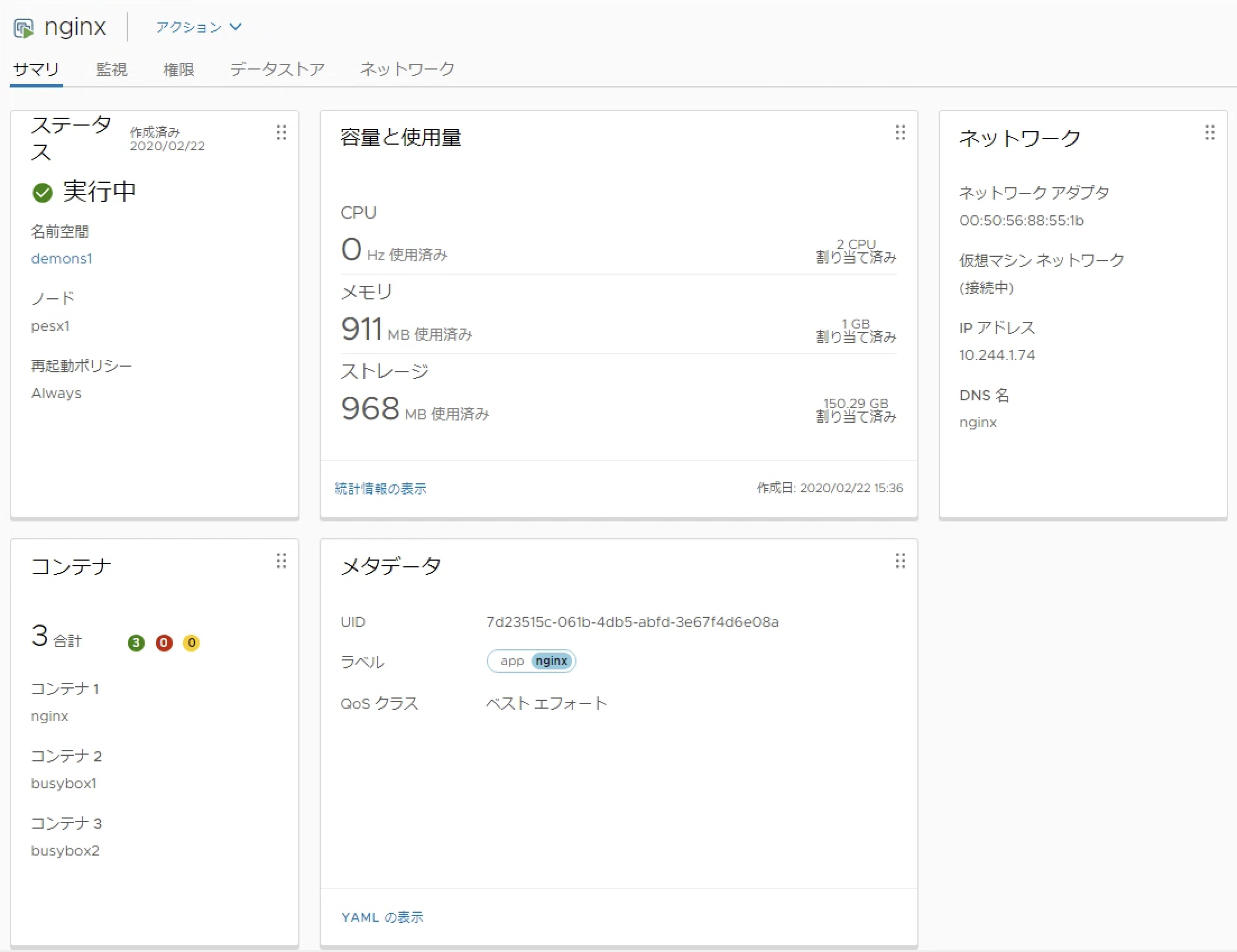
VMwareによるとNative Podは、通常のLinux上で起動するPodと比べて8%パフォーマンスが良いとされています。(How Does Project Pacific Deliver 8% Better Performance Than Bare Metal?)これはハイパーバイザーであるESXiがCPUのNUMA(Non-Uniform Memory Access)アーキテクチャを配慮したCPUスケジューリング行うためで、Native Pod上のvCPU処理を同じNUMAノードにスケジューリングすることで、キャッシュヒット率を高めているためです。通常Podにはコンピュートリソースの制限をかけることが可能です。Native Podでも同じ様にリソース制限をかけることが可能です。例えば以下のようなマニフェストを利用してPodを作成した場合、Native Podは以下のように構成されます。
- Podのマニフェスト
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
containers:
- image: nginx:alpine
name: nginx
resources:
limits:
cpu: 2000m
memory: 2000Mi
requests:
cpu: 300m
memory: 500Mi
- 実際の割当
| vCPUの数 | 2 |
| CPUの予約値 | 748MHz |
| CPUの制限値 | 4.99GHz |
| RAMの割り当て容量 | 2.3GB |
| RAMの予約値 | 780MB |
| RAMの制限値 | 2.3GB |
CPUは1000m = 1vCPUとして計算されるためlimitとして指定した2000m = 2vCPUが割当られています。ノードであるサーバーのCPUが2.5GHZであるため、2vCPU分の4.99GHzが制限値として構成されます。requestは300mを指定しており、2.5GHzに対する30%となるため、周波数として約750Hzが予約値として設定されます。
メモリーはlimitとして2000Miを指定しています。Native PodはVMとして起動しOS部分のメモリーとして250MBが加算されるため、Native Podに対するメモリー割当と制限値は2,250MB(≒2.3GB)が設定されます。予約値に関してはrequestが500Miであり、OS部分の250MBが加算されるため780MBが予約値として設定されます。
Podに対するリソース制限をしない場合、Native Podに対してvCPU/メモリーの制限値は設定されませんがvCPUはNative Pod内のコンテナ数 * 0.5個、RAMは250MB + (250MB * コンテナ数)MBが割り当てられます。Native PodのvCPUとRAMはダイナミックに変更されることは無いため、コンテナがNative Podのメモリーを使い果たすとOOM(Out Of Memory)でPodが強制的に停止されます。通常のKubernetesでは制限値がないPodはホストのメモリーを利用することができますが、Native Podでは暗黙的な制限値が存在するため注意が必要です。
ネットワーク機能
Supervisor ClusterではNSXが非常に重要な役割を担います。一般的なKubernetes環境ではクラスター内のPod間通信を実現するために様々なソリューションがありますが、オーバーレイネットワークを利用してPod間の通信を実現するのが一般的です。(Kubernetesのネットワークに関してはこちらのブログでご説明しています)Supervisor ClusterではNSXを活用し、Geneveと呼ばれるカプセル化方式によりパケットをカプセル化することでオーバーレイネットワークを実現し、Native Pod間の通信を可能にします。vSphereクラスターでvSphere with Kubernetesを有効化すると、NSXのEdgeが構成され論理的なルーターとしてT0ゲートウェイ/T1ゲートウェイが構成されます。Supervisor Clusterに作成されるNative Podはこのネームスペース毎に独立したT1ゲートウェイ配下に配置されます。T1ゲートウェイ配下には/28単位でセグメントが作成され、最大13のPodが接続可能です。Pod数が増えると自動的にNSXから論理セグメントが払い出され同じ、T1ゲートウェイ配下に接続されます。各セグメントはタグによりどのネームスペース向けなのかを識別することが可能です。また、Kubernetes上で利用することができるServiceと呼ばれるリソースは各ESXiホストで実行される分散ロードバランサー機能と、T1ゲートウェイ上の論理ロードバランサーによって提供されます。
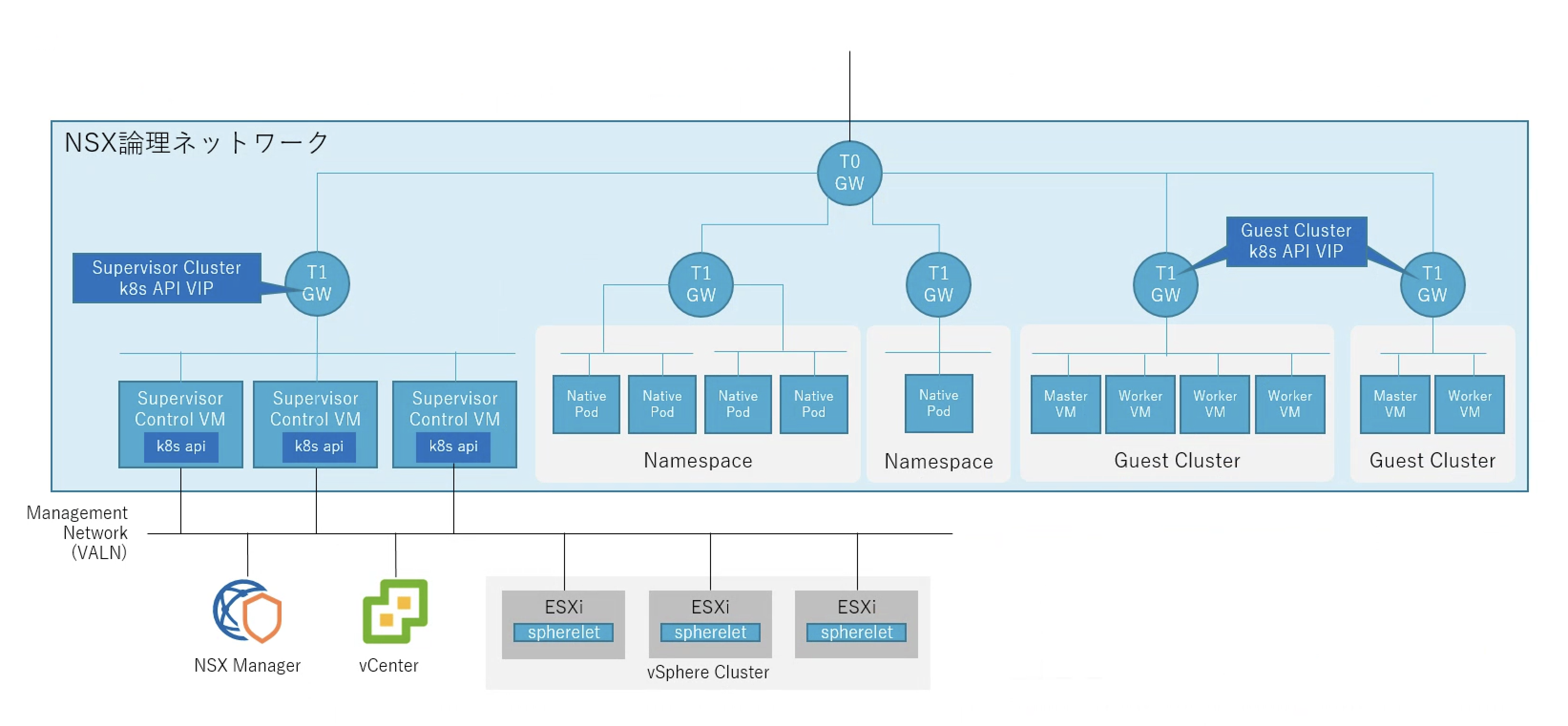
KubernetesにはNetwork Policyと呼ばれるPod間通信を制御するための機能があり、Network Policyの機能はNSXの分散ファイアウォール機能によって実現されています。デフォルトではネームスペース間の通信は拒否されているため、異なるネームスペースに存在するNative Pod間の通信は拒否されています。Pod間の通信を許可するにはNetwork Policyにより通信を許可するポリシーを適用する必要があります。
ストレージ機能
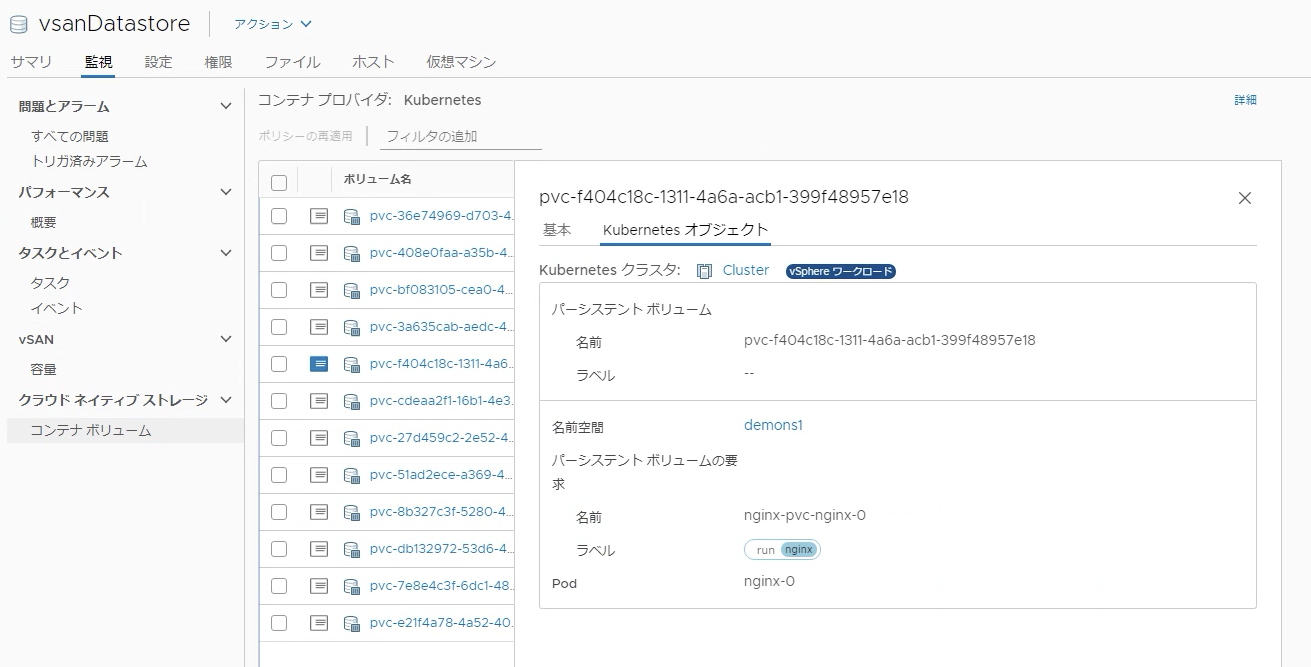
KubernetesではPodが利用する永続的なストレージとしてPersistent Volumeを利用することができますが、Supervisor ClusterでもPersistent Volumeを利用することが可能です。(Kubernetesのストレージに関してはこちらのブログでご説明しています)Persistent Volume作成時にvSphere上で構成したStorage Profileを指定することで、任意のストレージにPersistent VolumeをVMDKファイルとして作成することが可能です。従来のvSphereでは独立したVMDKをvSphere上でオブジェクトとして管理することができませんでしたが、vSphere 6.7U3からクラウドネイティブストレージ機能が追加され、Supervisor ClusterではNative Pod向けに作成したPersistent VolumeをvCenter上でオブジェクトとして管理することが可能になっています。
Registry機能
通常コンテナイメージを格納するための場所としてRegistryを利用します。vSphere with KubernetesではSupervisor Cluster内にHarbor Registryを構成することが可能です。Harbor Registryは複数のNative Podにより構成されコンテナイメージの格納先として利用することができます。Supervisor Clusterに作成した各ネームスペース毎にProjectが作成され、ネームスペース単位でレポジトリ(コンテナイメージ)を管理することが可能です。
この様にSupervisor ClusterではKubernetesに存在する様々な機能がvSphereとNSXによって実現され、KubernetesのAPIを利用してvSphereクラスターを利用することが可能になっています。
Guest Cluster (Tanzu Kubernetes Grid)
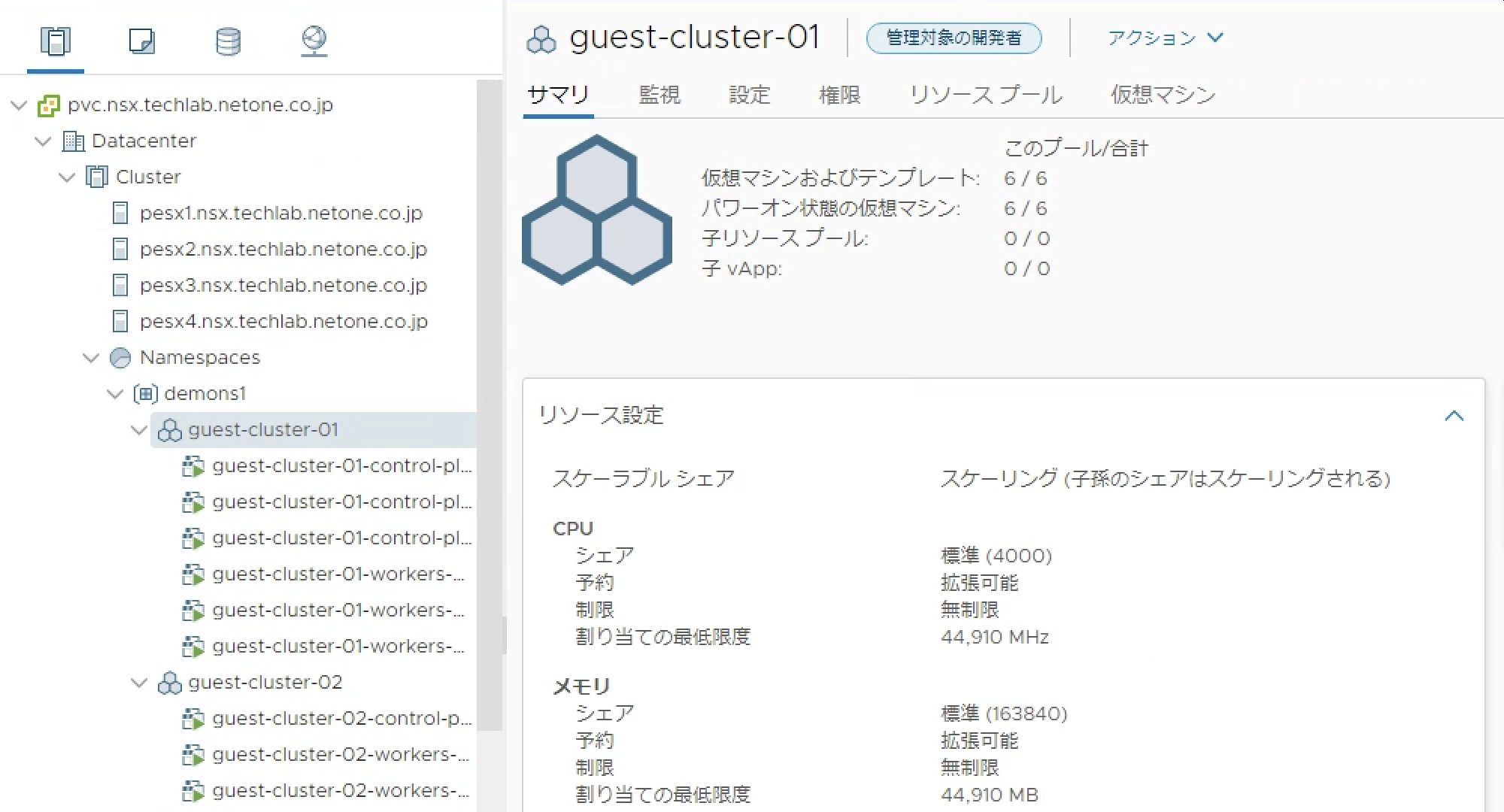
これまでの説明はvSphereクラスターをKubernetesクラスターのように利用する機能でした。しかし、Kubernetesのように利用することはできますが、Native Podの実体はVMでありSupervisor Clusterは独自のKubernetesであるため、Kubernetesと完全な互換性を提供することができません。そこで、Supervisor Cluster上にGuest Clusterと呼ばれるVMで構成されるKubernetesクラスターを構成することが可能です。このKubernetesクラスターはCluster APIと呼ばれるオープンソースで実装されており、KubernetesのAPIを活用してKubernetesクラスターを作成することを可能にします。Cluster APIは様々なインフラストラクチャに対応しており、Tanzu Mission ControlではCluster APIを利用してパブリッククラウド上にKubernetesクラスターを作成することが可能です。vSphere with KubernetesのCluster APIはSupervisor Clusterにホストされており、Guest ClusterをKubernetesリソースとしてマニフェストにより定義する事が可能です。
apiVersion: run.tanzu.vmware.com/v1alpha1
kind: TanzuKubernetesCluster
metadata:
name: guest-cluster-01
spec:
topology:
controlPlane:
count: 3
class: guaranteed-xsmall
storageClass: k8s
workers:
count: 3
class: guaranteed-large
storageClass: k8s
distribution:
version: v1.16.8
settings:
network:
cni:
name: calico
services:
cidrBlocks: ["198.51.100.0/12"]
pods:
cidrBlocks: ["192.0.2.0/16"]
単一のネームスペース内に複数のGuest Clusterを作成することができ、作成されたGuest Cluterはマニフェストの編集によりノードをスケールアウトすることが可能です。(現状スケールインには対応していません)
仮想マシンリソース
VMworld 2019では通常の仮想マシンもSupervisor Clusterのマニフェストによって管理することができるという説明がありましたが、初期リリースのvSphere with Kubernetesでは実装されていないようです。今後仮想マシンもSupervisor Clusterのリソースとして管理できるようになることが期待されます。
出典 : https://blogs.vmware.com/vsphere/2019/08/project-pacific-technical-overview.html
おわりに
今回はvSphere 7で新しく追加されたvSphere with Kubernetesに関してご紹介いたしました。弊社ではお客様向けのデモと実際に触って頂けるラボ環境をご用意しています。ご興味がある方は是非弊社の担当営業までご連絡ください。また、現在弊社のラボ環境では今回ご紹介したvSphere 7のvSphere with Kubernetesだけではなく、Tanzu Mission ControlやAWS/Azure等と接続してお客様がテストを行うことができる環境の準備を進めております。近日中にお客様にご案内できる予定ですので、ご期待ください。
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索