
ネットワンシステムズ 吉田です。
今回は生成AIとロボットを使ったAIエージェントの実装方法をご紹介します。
ロボットを用いることで現実世界とのインターフェースを持ったAIエージェントが誕生します。

- ライター:吉田 将大
- システムインテグレータでソフトウェア開発業務を経験した後、2018年にネットワンシステムズに入社。
前職での経験を活かした開発案件の支援や、データ分析基盤製品・パブリッククラウドの導入を支援する業務に従事。
保有資格: AWS認定ソリューションアーキテクトプロフェッショナル
目次
2030年にIT運用人材は79万人不足と予測
日本では少子高齢化の進行に伴い、2030年には深刻なIT技術者不足が予測されています。経済産業省の報告によれば、IT技術者の需要と供給のギャップは今後さらに拡大し、2030年までに最大で約79万人もの人材が不足するとされています。
この背景には、デジタルトランスフォーメーション(DX)の加速によりIT分野への需要が急速に増加している一方で、若年層の人口減少や新しいスキルを持つ技術者の育成の遅れがあると考えられます。
こうした状況において、企業は限られたリソースを効率的に活用し、IT運用の自動化や効率化を進める必要があります。
AIエージェントとは?
AIエージェントの活用は、深刻な人材不足の有力な解決策として注目されています。
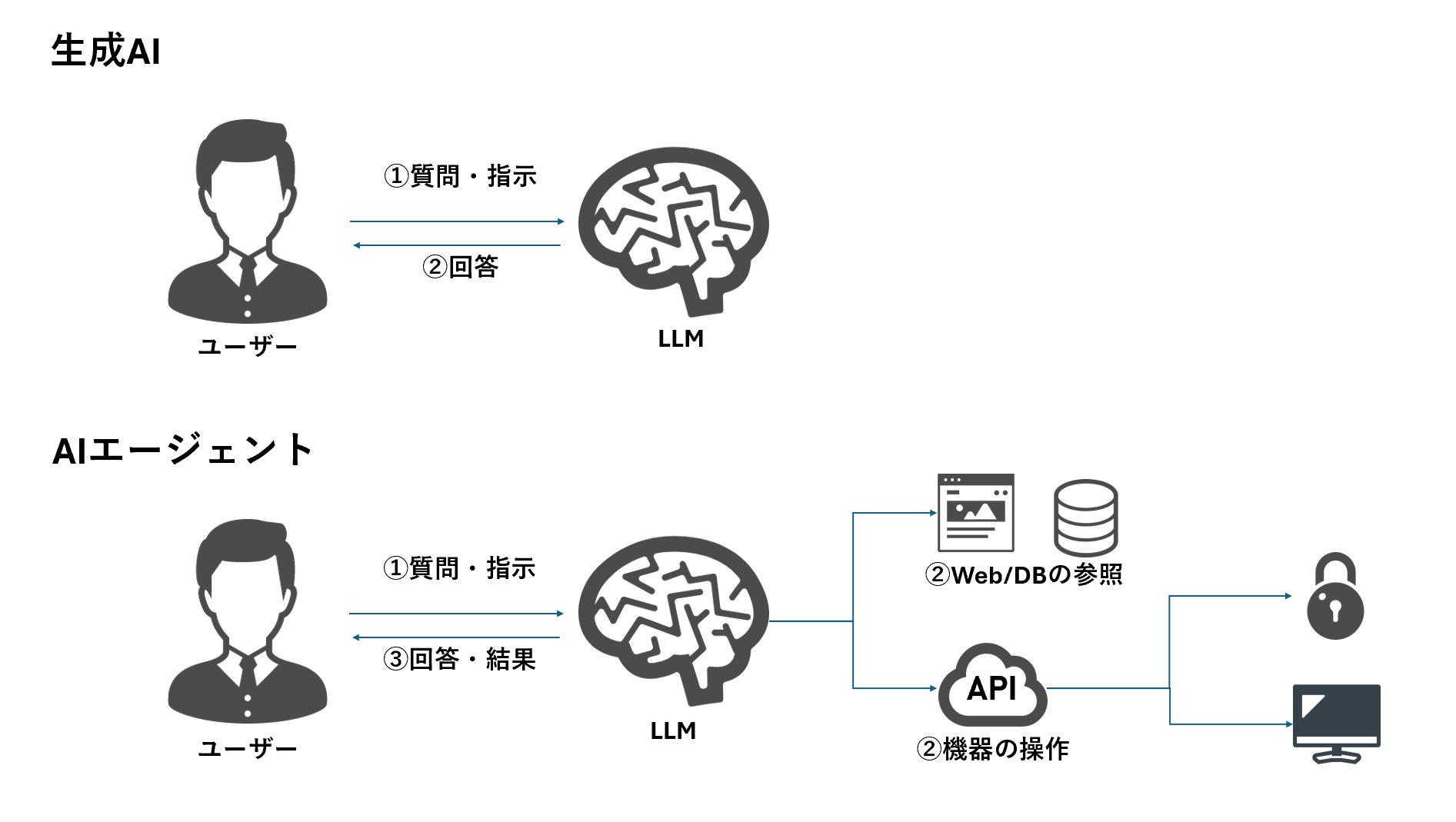
AIエージェントとは、広義には、特定の目標に向かって自律的に行動し、環境やユーザーとのやり取りを通じてタスクを実行するシステム全般を指します。このブログでは特に、生成AIを活用して様々なタスクを自動的に実行するタイプのエージェントについて説明します。
生成AIを基盤としたエージェントは、自然な言葉での指示を理解し、APIの呼び出しやデータ処理などの複雑な操作を自動化することで、ユーザーが求める結果を迅速かつ効率的に提供します。これにより、単純なチャットボットを超えた、柔軟で高度なサポートが可能になります。
AIエージェントは、人的リソースが限られる中でも、複雑な運用タスクを自動化し、予測分析を通じてシステムの安定性を高めることが可能です。これにより、将来のIT運用のスタイルが大きく変革され、日本の技術者不足問題に対しても有効なソリューションとなることが期待されています。
ロボットでAIに物理世界とのインターフェースを
生成AIの登場によって我々の業務は大きく変革したことは間違いありません。
しかし、その業務改善事例の多くは文章要約やAIチャットボットなど、PCやスマートフォンを介した電子データの操作に集中しています。これらのユースケースでは、テキストベースのインターフェースやデータ処理が中心で、生成AIが得意とする自然言語処理やデータ分析の能力が活用されています。
しかし、生成AIとロボットが組み合わさることで、例えばオフィスの受付、倉庫管理、製造ラインの自動化など、物理的な作業の自動化や効率化が今後期待される分野です。これにより、単に電子データ操作にとどまらず、生成AIのユースケースが物理的なインターフェースを介して現実世界に広がっていくことが予想されます。
実装例: ロボットを活用したIT運用向けAIエージェント
それではここから実際にどのように実装するかについて「IT運用向けAIエージェント」を題材にご説明します。
システムの全体像と処理シーケンスのイメージは以下の通りです。

[システム構成イメージ]
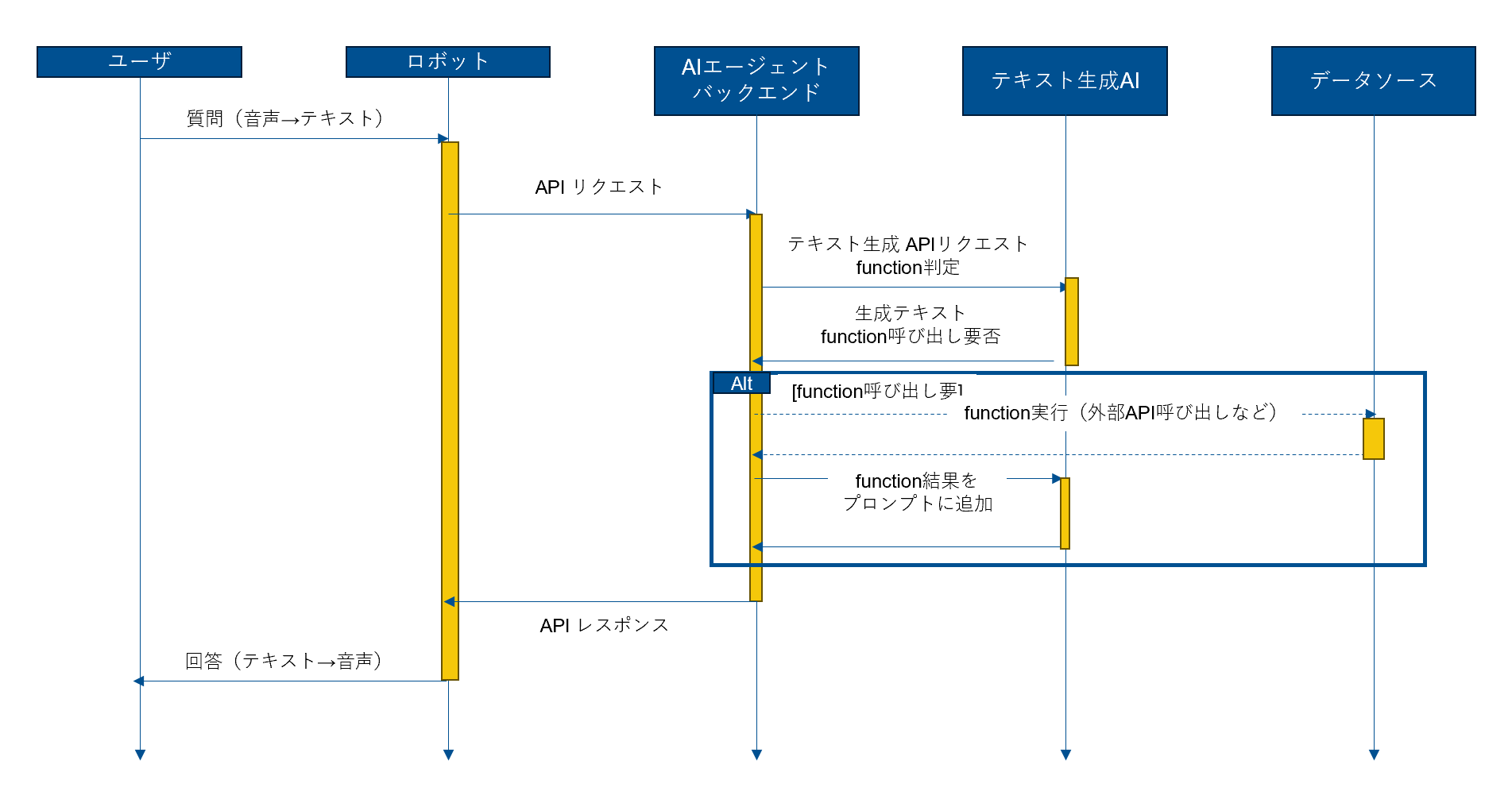
[処理シーケンス]
ステップ1. Open AI Function CallingによるAIエージェントの実装
テキスト生成AIに使われている大規模言語モデル(LLM)は革新的な技術ですが、決して万能ではありません。モデル学習時に含まれていない最新の情報などは回答できませんし、LLM単体ではテキストを生成することしかできません。
生成AIを「AIエージェント」として昇華させるには、Web検索やデータベースの参照、API呼び出しなどの外部タスクの実行というスキルを実装してあげる必要があります。
AIエージェントの実装として使える様々なサービスやOSSが公開されていますが、今回はOpen AI APIの「Function Calling」を使用しました。
Open AI APIのFunction Callingは、テキスト生成と同様にAPIとして提供されているため、他の実装方法と比べて、追加のライブラリや複雑なフレームワークなしで迅速にエージェント機能を実装できるメリットがあります。
Function Calling機能を利用することで、AIエージェントはただのテキスト生成にとどまらず、特定の外部APIを呼び出してタスクを実行できるようになります。
例えば、ユーザーが「最新の在庫状況を教えて」と指示した場合、Function Callingを活用することで、AIは在庫データベースにアクセスし、実際の数値を参照して正確な回答を返すことが可能です。また、天気情報や為替レートの照会、特定のシステムコマンドの実行など、多様なタスクに応用できるため、Function Callingを利用することで、AIエージェントが複数のシステム間をシームレスに連携し、業務を効率化するサポートが可能になります。
「CPU使用率の高いサーバーを教えて?」をDatadogのAPIを使って実現
今回はIT運用者向けのAIエージェントを想定して、DatadogのメトリクスAPIをAIエージェントを使って呼び出す実装を試してみます。
使用するのはPythonスクリプトとWebフレームワークのFlask、そしてOpen AI APIおよびDatadog APIのSDKです。
まずはDatadogのSDKを使ってCPU使用率を取得する関数を作成します。
import datetime
from datadog_api_client import ApiClient, Configuration
from datadog_api_client.v2.api.metrics_api import MetricsApi
from datadog_api_client.v2.model.metrics_data_source import MetricsDataSource
from datadog_api_client.v2.model.formula_limit import FormulaLimit
from datadog_api_client.v2.model.metrics_aggregator import MetricsAggregator
from datadog_api_client.v2.model.metrics_scalar_query import MetricsScalarQuery
from datadog_api_client.v2.model.query_formula import QueryFormula
from datadog_api_client.v2.model.query_sort_order import QuerySortOrder
from datadog_api_client.v2.model.scalar_formula_query_request import ScalarFormulaQueryRequest
from datadog_api_client.v2.model.scalar_formula_request import ScalarFormulaRequest
from datadog_api_client.v2.model.scalar_formula_request_attributes import ScalarFormulaRequestAttributes
from datadog_api_client.v2.model.scalar_formula_request_queries import ScalarFormulaRequestQueries
from datadog_api_client.v2.model.scalar_formula_request_type import ScalarFormulaRequestType
configuration = Configuration()
configuration.unstable_operations["query_scalar_data"] = True
api_client = ApiClient(configuration)
api_instance = MetricsApi(api_client)
def query_cpu_usage_from_datadog():
"""Datadogからメトリクスを取得する"""
# 現在時刻から1時間を範囲とする
to = datetime.datetime.now().astimezone()
_from = to - datetime.timedelta(hours=1)
body = ScalarFormulaQueryRequest(
data=ScalarFormulaRequest(
attributes=ScalarFormulaRequestAttributes(
formulas=[
QueryFormula(
formula="cpu_usage",
limit=FormulaLimit(
count=1000,
order=QuerySortOrder.DESC,
),
),
],
queries=ScalarFormulaRequestQueries(
[
MetricsScalarQuery(
aggregator=MetricsAggregator.SUM,
data_source=MetricsDataSource.METRICS,
query="avg:system.cpu.user{*} by {server}",
name="cpu_usage",
),
]
),
_from=int(_from.timestamp() * 1000),
to=int(to.timestamp() * 1000),
),
type=ScalarFormulaRequestType.SCALAR_REQUEST,
),
)
response = api_instance.query_scalar_data(body=body)
d = response.to_dict()['data']['attributes']['columns']
# dictに変換
result = {s[0]: v for s, v in zip(d[0]['values'], d[1]['values'])}
# 高い順に並べ替え
result = dict(sorted(result.items(), key=lambda x: x[1], reverse=True))
return result
次に、Flaskを使ってAPIサーバーを構築し、リクエストをOpen AI APIに送信するコードを記述します。
import os
import json
from flask import Flask, request, jsonify
from openai import OpenAI
app = Flask(__name__)
functions = {'query_cpu_usage_from_datadog': query_cpu_usage_from_datadog}
tools = [
{
"type": "function",
"function": {
"name": "query_cpu_usage_from_datadog",
"description": "各サーバーのCPU使用率を取得する"
}
}
]
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
OPENAI_BASE_URL = os.environ.get('OPENAI_BASE_URL')
model = "gpt-4o"
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_BASE_URL
)
@app.route('/send_message', methods=['POST'])
def send_message():
# クライアントからのPOSTリクエストのデータを取得
data = request.json
# メッセージのリストを取得(デフォルトは空リスト)
messages = data.get('messages', [])
# クライアントのチャットAPIを使用して最初のレスポンスを生成
response = client.chat.completions.create(
model=model, # 使用するモデルを指定
messages=messages, # メッセージリストを渡す
tools=tools, # ツール(function)を指定
tool_choice="auto", # ツールを自動選択
)
# 生成されたメッセージの中から最初のレスポンスを取得
response_message = response.choices[0].message
# ツール呼び出し(function call)のリストを取得
tool_calls = response_message.tool_calls
if tool_calls:
# ツール呼び出しがある場合、生成されたメッセージをメッセージリストに追加
messages.append(response_message)
for tool_call in tool_calls:
# 各ツール呼び出しを処理
tool_call_id = tool_call.id # ツール呼び出しのID
message = {
"role": "tool",
"tool_call_id": tool_call_id,
"content": "" # 初期コンテンツは空文字列
}
# 呼び出されたツール(function)の名前を取得
tool_function_name = tool_call.function.name
if tool_function_name in functions:
# 定義されたfunctionリストにツール名がある場合
results = functions[tool_function_name]() # 対応する関数を実行
message['content'] = str(results) # 実行結果をメッセージに格納
else:
# ツールが存在しない場合のエラーメッセージ
error_msg = f"Error: function {tool_function_name} does not exist"
message['content'] = error_msg
messages.append(message) # メッセージリストに結果を追加
# 関数実行後のメッセージリストを使い再度APIにリクエストを送信
model_response_with_function_call = client.chat.completions.create(
model=model,
messages=messages,
)
response_message = model_response_with_function_call.choices[0].message # 更新されたレスポンスを取得
# 最終レスポンスメッセージのコンテンツをJSON形式で返す
return jsonify({"message": response_message.content})
ここまでが生成AIを用いた通常のAIエージェントの実装方法になります。
生成AIの優れている点は、構造化されていないデータを扱える点にあります。それは大量のデータから文脈やパターンを学習し、構造がなくても情報を理解できるからです。
コードを見てみると、function(関数)の実行要否判定に際し、生成AIに対しては最初の質問である「CPU利用率の高いサーバーを教えて」という情報、そしてfunctionの名前「query_cpu_usage_from_datadog」と「各サーバーのCPU使用率を取得する」という概要しか送信していないことがわかります。function実行結果も、DatadogからのAPIレスポンスの結果をほぼそのままPython dict形式のまま文字列化したものを末尾に追加して送信しているだけです。
実際に実行してみると分かりますが、この実装だけで、「CPU利用率の高いサーバーを教えて」に対して、「CPU使用率の最も高いサーバーはXXX サーバーで、平均使用率は80%です。」といった回答を返してくれます。
次のステップでは、作成したAIエージェントにロボットを連携していきます。
ステップ2. ロボットをAIエージェントと人間のインターフェースにする
次に、「temi」というロボットを使って、物理世界とのインターフェースを拡張します。
temiは自律走行可能な汎用ロボットで、様々なセンサーや機能を持っています。
- マイク・スピーカーによる自然言語での音声会話
- カメラによる人物検知・顔認証
- 距離センサーによる空間認識・座標検知
- カスタムアプリケーションによる機能拡張
今回はカスタムアプリケーションによって前述のAIエージェントと統合し、音声会話機能を拡張します。

カスタムアプリでユーザーとの会話をAIエージェントに送信する
temiはAndroidベースのOSを搭載しており、Android向けのカスタムアプリケーションがインストール可能です。
今回はKotlinとtemi SDKを使ってAIエージェントとアプリケーションを実装していきます。
MainActivity.kt
override fun onAsrResult(asrResult: String, sttLanguage: SttLanguage) {
robot.finishConversation()
// 音声認識結果(asrResult)を元にエージェントに問い合わせる
viewModel.askAgent(
asrResult // ユーザーの音声入力をテキストとしてエージェントに渡す
) { msg: String ->
// エージェントからの応答メッセージ(msg)を音声として再生
speak(msg, showAnimationOnly = true) // アニメーションのみ表示してメッセージを発話
}
}
MainViewModel.kt
// ユーザーとアシスタント間のメッセージを表現するデータクラス
data class ChatMessage(
val role: String, // "user" または "assistant" など、メッセージの役割を表す
val content: String? = null, // メッセージの内容
val name: String? = null // 名前(オプション)
)
// チャット履歴を管理する変数
private val _chatHistory = MutableLiveData<List>().apply { value = listOf() }
private val chatHistory: LiveData<List> get() = _chatHistory
// チャット履歴に新しいメッセージを追加する関数
private fun addMessage(message: ChatMessage) {
// 現在の履歴リストに新しいメッセージを追加し、更新する
val updatedList = _chatHistory.value.orEmpty() + message
_chatHistory.value = updatedList
}
// ユーザーからの入力を処理し、エージェントに質問する関数
fun askAgent(
userInput: String, // ユーザーからの入力メッセージ
callback: (resultMessage: String) -> Unit = {} // 結果メッセージを返すためのコールバック
) {
// 非同期で処理を開始
job = viewModelScope.launch {
try {
// ユーザーの入力メッセージを作成し、チャット履歴に追加
val userMessage = ChatMessage(role = "user", content = userInput)
addMessage(userMessage)
// チャット履歴をもとにエージェントにリクエストを送信し、結果を取得
val result = ShowcaseAgentUtils.sendRequestToLLM(chatHistory.value!!)
val botOutput = result.getString("message") // レスポンスのメッセージ部分を取得
// エージェントからの応答メッセージをチャット履歴に追加
addMessage(ChatMessage(role = "assistant", content = botOutput))
// コールバック関数を呼び出して結果メッセージを返す
callback(botOutput)
} catch (e: Exception) {
// 例外が発生した場合、エラーメッセージをコールバックで返す
callback("サーバーとの通信に失敗しました。")
}
}
}
これらの実装によって、temiに対して音声で質問した内容がテキスト化され、Webで実装したバックエンドのエージェントに送信されます。
エージェントから返された回答結果は、temiを介して音声に変換されてユーザーに伝えられます。
まとめ
いかがでしたでしょうか。
OpenAIのFunction Calling機能を活用することで、生成AIに外部リソースと連携する力を持たせ、実用的なエージェントとしての役割を果たせるようになります。これにより、AIは単なるテキスト生成ツールから進化し、業務の一部を担うパートナーとして活躍する可能性を秘めています。
また、ロボットとの組み合わせにより、デジタルと物理の領域を超えた幅広いユースケースが期待されています。従来のデータ操作にとどまらず、物理的なインターフェースを持つロボットを通じて、現実空間での業務にもAIエージェントが貢献できる未来が目前に迫っています。
今回は音声会話機能のみしか実装しませんでしたが、例えばAIエージェントのレスポンスに応じてロボットを特定の場所へ移動させたり、カメラから取得した画像・映像データ、さらに顔認識によって得られた人物情報などを併せてAIエージェントに送信することで、リアルタイムな分析をしたり、パーソナライズされた回答結果を出力することなどが可能になります。
弊社のオフィス「netone valley」では、今回ご紹介したロボットとAIエージェントのデモもご覧いただけますので、是非お気軽にお問い合わせください。
※掲載しているソースコードはサンプルのため動作を保証するものではありません。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


