
生成AIを活用した環境を独自で構築する場合に、まずはLLMモデルを元にAPI Serviceを提供するModel Servingの環境が必要になります。一般的にModel ServingではOpen AIが提供しているAPIと互換のREST APIの機能を提供します。Model Servingは様々なアプリケーションが提供されていますが、今回はTensorRT-LLMとvLLMという2種類を利用して比較を行いました。今回はLLMを動作させる為にNVDIAのL40Sを4枚使った環境で検証を行いました。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
Model Serving環境の構築
まずは、TensorRT-LLMとvLLMを使ってModel Serving環境を構築します。
検証環境
今回はNVIDIAのL40Sが4枚Dell PowerEdgeに搭載されており、VMwareの仮想化環境を利用しています。

TensorRT-LLMについて
TensorRT-LLMはNVIDIAが開発しているNVIDIA GPU上での推論性能を高速化するライブラリです。TensorRT-LLM使ってLLMモデルの高速動作が可能となります。TensorRT-LLMはHugging Faceにあるようなオープンモデルや、独自モデルをコンパイルする事で高速動作を実現します。TensorRT-LLMにて作成されたモデルはTriton Inference Serverを使ってAPI EndpointとしてServingが可能となります。
TensorRT-LLMでのモデルコンパイル
今回はLlama3-8Bを利用してモデルの配信を行います。以下のNVIDIAのDocumentを参考にしながら動作確認をしています。一部今回の環境に合わせる為に最新のCUDAを利用したり、オプション指定を増やしています。
TensorRT-LLMでのモデルのコンパイルを行います。事前にHuggingFace上でLlama3へのアクセス権取得とTokenを取得しておきます。
|
# Llama3-8Bを取得する為にHugging Faceにログインします。 # TensorRT-LLMを取得します。 # Llama3-8Bを取得します。 #コンパイル作業用のコンテナを起動します。 #以降コンテナ内での作業 # TensorRT-LLMのインストール #1-gpu,BF16でllamaのexampleを使ってチェックポイントの作成 #作成されたチェックポイントから作成 #コマンドでモデルのテスト |
Check Point作成時のオプション等は以下を参照します。2-GPUをTensor parallelで利用する時はチェックポイント作成から変更します。
TensorRT-LLM/examples/llama at main · NVIDIA/TensorRT-LLM · GitHub
|
#2-gpu,BF16でllamaのexampleを使ってチェックポイントの作成.tp_sizeで利用するGPUの数を指定。 #作成元と作成先のフォルダだけ変えています。 |
Triton Inference Serverでのモデル配信
作成したモデルをTriton Inference Serverで配信します。
|
# 先ほどのDockerコンテナを抜けた後、Triton Inference Serverを取得します。 #先ほど作成したモデルをコピーします。 #Tritonの設定を作成します。 #Tritonを起動します。 # Install python dependencies # サーバを起動します。2 GPU利用する場合はworld_sizeを2とします。 #curlコマンドでテストを行います。 |
vLLMについて
vLLMはTensorRT-LLMとは違いNVIDIA以外のGPUでも環境の構築が可能です。vLLMは独自の仕組みを使って高速にHugging Face上にあるモデルや独自モデルのServingが出来ます。vLLMは比較的簡単に環境の構築とModel Servingが行えるようになっています。
vLLMの構築
基本的にpipコマンドでvLLMが利用できる。今回は最新のCUDAを利用したい為コンテナからコンパイルを行う。
|
#Dockerを起動する #コンテナ内でvLLMのレポジトリをCopyしてbuild #vLLMをBuild #vLLMを起動する。起動時のメモリ確保を失敗する事があるので90%確保としています。tensor-parallel-sizeで利用するGPUを指定 # curlコマンドで確認 |
TensorRT-LLMとvLLMの性能比較
TensorRT-LLMとvLLMの性能比較を行います。今回はモデルが秒間で生成するトークン数: TPS(Token per sec)で比較を行います。大きいほど時間単位での多くのトークンを生成できています。GPT 3.5 Turboで53 TPS程度と言われていますので、一般的には50-60TPS程度で生成出来れば十分だと考える事が出来ます。
Llama3-8Bを利用した場合
Meta社が最近リリースしたLLMモデルのLlama3の中で80億パラメータのLlama3-8Bを利用した比較を行います。Llama3-8BはL40Sの場合は1つのGPUでも動作可能です。今回は文章生成処理を主に行うGPUを1,2,4個利用した場合の比較を行いました。複数GPUを利用する場合は今回は1つのモデルを分割して複数GPUで動作させるTensor Parallelを利用しました。
|
Serving形式 |
1-GPU |
2-GPU |
4-GPU |
|
TensorRT-LLM |
47 TPS |
100 TPS |
150 TPS |
|
vLLM |
45 TPS |
71 TPS |
90 TPS |
TensorRT-LLMとvLLMでのTPSを比較すると、マルチGPUで性能差が出ました。TensorRT-LLMの方が1秒間辺り多くのトークンを生成できています。この違いは、TensorRT-LLMはGPUを99%利用していましたが、vLLMはGPUを増えると使用率が60%程度まで低下しており、その差が文章生成の能力差になったと考えられます。
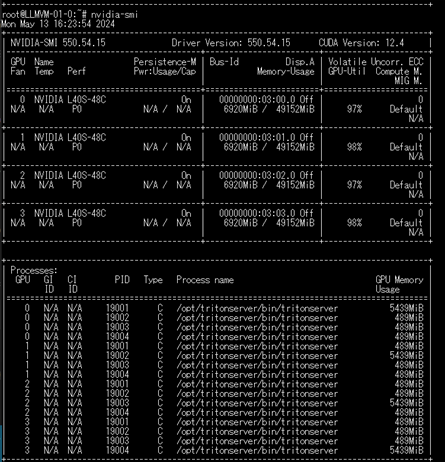
TensorRT-LLM利用時のGPUの様子
Mixtral-8x7B(karakuri-ai/karakuri-lm-70b-v0.1)を利用した場合
MoEの構成でMixtral-8x7Bを元にした日本語LLMを利用してみました。vLLMはモデルを指定すれば動作しました。TensorRTはMixtralのexampleを参考にしましたがllamaと同一との事でモデル名以外の手順は同一で動作します。
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/mixtral
| Serving形式 |
4-GPU |
|
TensorRT-LLM |
90 TPS |
|
vLLM |
60 TPS |
Llama3-8Bと同様にTensorRT-LLMとvLLMでは差が出ました。
所感
GPUのメモリよりGPUの利用率でTensor Parallelでモデルを複数のGPUに配置するとLLMの文章生成速度の恩恵を受ける事が出来る事が確認出来ました。GPU間はPCIEで接続されている為複数GPUを利用した場合に影響が出るかと考えましたが、GPUの利用率を見る限りは今回の条件に於いては問題にならないようです。TensorRTはモデル生成時のGPUを極限まで利用できることが確認出来ましたが、動作させる為の手順が多くかかってしまいます。vLLMはコマンド一行で手軽に利用を開始する事が出来ます。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


