
LLMに新たな知識を習得させる方法は3種類あります。LLM全体の再学習、LLM一部の再学習、Promptに情報を埋め込むになります。今回はPromptに情報を埋め込む、RAGについて解説します。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
【更新日】2023/11/8
はじめに
Chat-GPTに代表される、LLMに最新の情報やクローズド情報を返してほしい場合に、取りうる手段が3種類あります。
- LLM全体の再学習
新規データを加えたデータセットでLLMをゼロから再学習します。コストは膨大となります。
- LLMの一部の再学習
Fine Tuningと呼ばれる手法で、LLMの一部を新規データで再学習します。1.のゼロからの全体の学習よりはコストを抑える事が出来ますが、GPU環境は必要となります。
- PromptにContext(参考情報)を付加
Retrieval Augment Generation (RAG)と呼ばれる手法で、PromptにContextを加えてLLMに問い合わせを行います。LLMのモデル自体に影響を与えることなく対応が可能な為、学習用のGPU環境を必要としません。
RAGについて
LLMは質問をした場合に、LLM内部の情報を参照して回答を生成します。LLM学習時の情報が古ければ古い情報を返します。LLM内に情報が無ければ創作して返します。これはハルシネーション(幻覚)と呼ばれています。これを防ぐために、質問に情報検索で得られた、参考情報(Context)を付けてLLMに質問する仕組みがRAGです。RAGは質問タスクをContextの要約タスクに変換しているとも言えます。
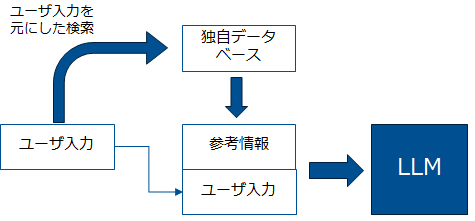
RAGでのデータ検索
RAGでは入力されたPromptに基づいてデータを検索して結果を受け取る必要が出てきます。その為、RAGでは検索サーバを用意する必要があります。通常の文章検索と違って検索結果をシステムが受け取って自動的に添付してLLMに送信する為、以下の点を考慮しておく必要があります。
- 検索結果の1位から5位程度までにPromptに関連した正しい情報が必要
- 複数の検索結果を添付する場合は、内容が相反するような情報を添付しない事が望ましい
- LLM内の知識情報に反する情報が添付されない事が望ましい
検索の方式について
RAGでは単語を元にしたキーワード検索の他に、文章の内容を元にしたセマンティック検索の一部であるVector Searchが使われます。セマンティックサーチは一般的にはキーワード検索に比べて、より良い結果を得られる事が期待されています。しかしながら対象の情報によってキーワード検索や、キーワード検索とセマンティック検索の両方を利用したハイブリッドサーチが良い場合もあります。
Vector Searchについて
Vector Searchは入力されたPromptを数字の羅列であるベクトルに変換して、Promptに関連したデータを検索します。検索対象のデータは事前にベクトル化しておく事が必要です。データをベクトル化する為にはEmbedding用のモデルを利用します。Open AIやAzure Open AIはEmbedding用のモデルとしてtext-embedding-ada-002を提供しており、与えられた文章を1536次元のベクトルに変換します。1536次元のベクトルとは、1536個の数字の羅列を意味します。ベクトル化する場合はOpen AIのEmbedding用のAPIを利用する必要はなく、オープンなEmbeddingモデルを利用して閉じた環境でEmbeddingも可能です。モデルが固有のベクトルを出力する為、ベクトル化するモデルを変える場合は再度、データ上の全文章の再ベクトル化が必要となります。Promptに近いデータを探すためにPromptとデータのベクトルの類似度を計算します。類似度を測る手段は様々な手段がありますが、一般的にはk近傍法や、コサイン類似度が利用されます。
文章の分割とサマリ
LLMにはPromptの文章の長さには制約があります。その為データが長い場合は適度に分割しておく必要があります。また、長い文章をベクトル化してしまうとベクトル内に反映される情報が薄れる恐れがあります。その為、単語、文章、段落ベースでの分割や、文字数ベースでデータを分割しておきます。文字数ベースで分割する場合は、必要に応じて前後の文字を重複しておきます。対象のデータが長文となる場合は、以下サイトによると512トークン毎に分割して、25%重複しておき、検索結果の中から上位から3-5位程度までを選択すれば良い結果が得られると言われています。
Vector DBについて
セマンティック検索の為の検索エンジンは、LLMの利用が広まると共に増えており、いくつかの実装があります。
- オンメモリVector Database: FAISS / Chroma
- Vector Database: Weaviate / Pinecone
- 既存のキーワード検索にセマンティック検索を追加: Elasticsearch / Cognitive Search
- 既存のDBの仕組みにVectorを追加する: pgVector
RAGに対応した検索エンジン
RAGに対応した本番利用可能な検索エンジンとして、今回はCognitive SearchとElasticsearchを取り上げます。
Cognitive Searchを使ったHybrid検索
Cognitive Searchではキーワード検索と、セマンティックサーチを組み合わせたHybrid検索を提供します。セマンティックサーチはtex-embedding-ada-002を利用してベクトル検索をしています。キーワード検索とセマンティックサーチの検索結果は、Reciprocal Rank Fusion(RRF)を用いて一つの結果に統合されて返されます。これをL1と呼んでおり、L1では50の結果を返します。この50の結果を元にSemantic Rankingを使って、ランク付けを行い上位に来るデータの精度を高めていきます。この操作をL2操作と呼んでいます。以下のBlogポストによると、このHybrid検索+Semantic Rankerは、ほとんどの条件で単純なHybrid検索よりは、良い結果が出ていると報告されています。
Elasticsearchを使ったHybrid検索
Elasticsearchは文章検索目的で利用されていますが、最近は時系列のセキュリティやObservabilityでも利用されています。Elasticはベクターサーチの機能等のRAGに対応する為の機能群をElastic Relevance Engine(ESRE)として出しています。通常のワード検索に加えて、セマンティック検索でつかうベクターサーチではOpen AI等の外部サービスに加えて、Elastic上での独自モデル利用も可能となっています。これによりベクトル化やセマンティック検索を外部のAPIに頼ることなく内部で実施が可能となります。ElasticはElastic Learned Sparce Encoder (ELSER)の名前で、セマンティック検索の為のモデルを提供しています。それ以外にもElasticのElandを使って、PyTorchのモデルをHugging Face等からインポートして利用可能です。また、RRFを使ったHybrid検索にも対応しています。現状(2023年9月20日時点)では、セマンティック検索やHybrid検索はElasticから有償のライセンスの購入が必要です。Elasticでは無償の範囲で出来る部分とライセンスが必要となる場合がありますので、都度ライセンスの確認が必要です。
RAGの性能評価
RAGの利用を開始する場合に、RAGが正しい回答を生成してくれるかの客観的な評価が必要となります。人を使って評価も出来ますが、評価は労力も大きく、評価者によるばらつきが多くなります。これを解決する為に、LLMを利用した評価の研究が行われています。RAGに限らず、ChatBotの評価には一般的には強力なLLM(例:GPT-4)を活用した評価が行われています。https://arxiv.org/abs/2306.05685
今回はDatabricksが公開しているRAGの評価に対するベストプラクティスを元に、RAGの評価について考えます。
https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG
RAGの性能評価について
Blog記事を参照すると、RAGの性能評価について以下の事がわかってきます。
- 評価では0-100で評点を付けるより、1-5の範囲の短い範囲で評点を付ける方が良い
- 単純に評価させる場合なら、GPT-4を利用して評価する
- GPT-3.5でもPromptを工夫すれば、GPT-4と同程度の評価を行う事が可能となり、評価の為のコストを削減できる。
RAGの評価の流れ
LLMを活用してRAG評価を行う場合の流れです。以下の手順を元にスコアを生成して、評価を行います。
- 評価シートの作成
質問とContextのペアを作成します。ContextはRAGで使用する文章から質問に対する文章を抜き出したものです。100問程度用意します。検索エンジンの評価では、ここでのContextを正確に自動的に選んでくれるかの評価になります。 - 回答用紙の作成
評価シート中のPromptとContextを元に様々なLLMを使って回答を作成します。 - 評価を行う
回答用紙を元に評価用のLLMに正確性、網羅性、可読性の評価と理由の説明を行ってもらいます。
所感
RAGの議論は結局のところ検索エンジンや検索手法をどうするかの議論に収束します。RAGで利用する検索エンジンも様々な物が出てきており、製品やサービスの選択に迷うところです。今後ともこの分野では様々な製品やサービスが発表されると考えられます。

※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


