
Databricksが新しいオープンLLMのDBRXをリリースしました。Databricksのページでは各種オープンLLMの性能を超えているとの主張をしています。今回は日本語でRAGを行う場合のDBRXの性能を検証しました。RAGは何度か説明していますが、LLMに文章生成をお願いする時に参考情報を添付して文章生成の精度を高めるテクニックです。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
DBRXについて
DBRXはDatabricksが提供しているオープンLLMで、Llama2等の既存のオープンLLMより文章生成について高度な機能を提供できると主張しています。DBRXは132B(1320億)パラメータのモデルとなっており、文章生成時には36B(360億)パラメータを利用して文章生成を行います。オープンモデルとしてHugging FaceやGitHub上にも公開されており、一定の条件下であれば自由に利用が可能となっています。DBRXは複数のモデルが連合して動作するMoE(Mixture of Expert)の仕組みを取り入れており、内部には16のExpert(モデル)を含み、文章生成時に4つのExpertが自動的に選択されて文章生成を行います。これによって文章生成を高速化しています。学習には日本語のWikipedia等の少量の日本語も含まれており、日本語もある程度は出力可能となっています。DBRXは12Tトークンのデータを用いて学習しており、32Kのトークン長をサポートしています。
「DBRX」を発表: オープンソース大規模言語モデルのスタンダードとして | Databricks Blog
DBRXをDatabricksのFoundation Model APIで利用する
DBRXはDatabricksのFoundation Model APIで利用可能となっています。Databricksのワークスペース内で、スループットベースとトークン毎課金での利用が可能となっています。今回は利用が簡単なトークン毎課金で利用します。DBRXはDatabricks環境からは対応しているリージョンでは特別な操作なしに利用可能です。入力は最大32K、出力は4Kまでとなっています。また、回答精度を高めるために事前に設定されているSystem Promptが自動的に適用されます。Foundation Model API上のDBRXは他の基盤モデルと同様にLangChain等から簡単に利用可能となっています。
https://docs.databricks.com/en/machine-learning/foundation-models/supported-models.html
DBRXの価格について
トークン毎課金を利用した場合のDBRXと、Azure Open AIで利用するGPT-3.5-Turboの2024年4/7の時点での価格を比較します。DBRXは1M Input Token辺り$2.25。1M Output Token辺り$6.75。Azure Open AIのGPT-3.5-Turbo-1106の場合は1M Input Token辺り$1、1M Output Token辺り$2となります。Token辺りで比べると現時点で、DBRXとGPT-3.5は2-3倍程度の価格差があります。
https://www.databricks.com/jp/product/pricing/foundation-model-serving
https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/openai-service/
DBRXと他のLLMと比較
今回も前回と同様にRAGのアーキテクチャを利用する為、NETONE BLOGの文章を512トークン毎に切って保存して、プロンプトに合わせて参考文章を4つ見つけて添付してLLMに回答を生成してもらいます。文章出力の最大は1,000トークンに設定してあります。スコア付けは前回同様NETONE BLOGを元にした理想回答を用意し、LLM-as-a-Judge、ROUGEでスコア付けを行い各種LLMと比較しています。また、回答の生成時間(遅延)も測っています。
DBRXと他のOpen LLMとの比較
オープンLLMのモデルとであるLlama2、Elyza、MPT、Mixtral-8x7BとLLM as a Judgeの仕組みでGPT-4にスコアを付けてもらい平均点を比較しています。DBRXとMixtral-8x7Bはほぼ同様のスコアが付いている為DBRXの能力の高さがうかがえます。
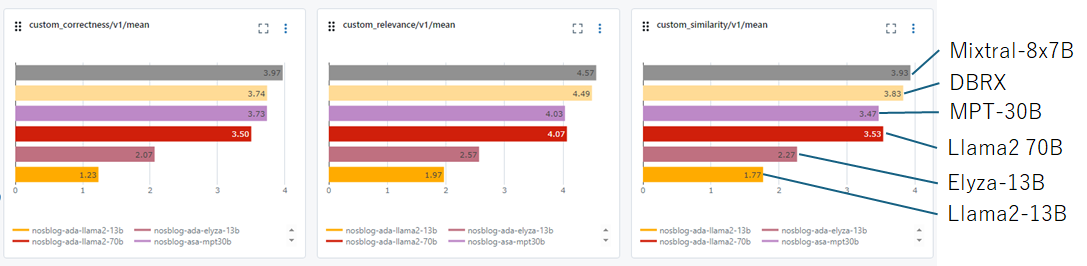
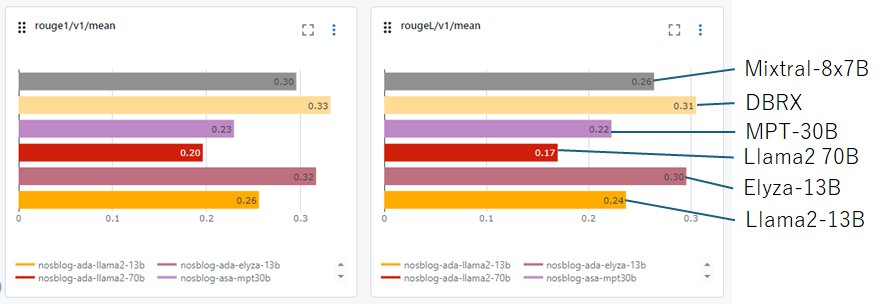
次に理想回答と比較したROUGEのスコアの比較を行います。DBRXはMixtralと違って、日本語でしっかり生成出来ている為ROUGEのスコアも高くなっています。日本語対応LLMであるElyzaと同等のスコアとなっている為日本語生成の能力も問題ないと考えられます。
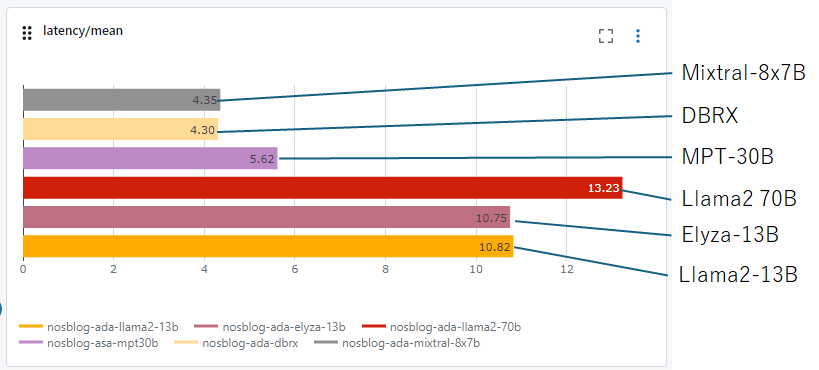
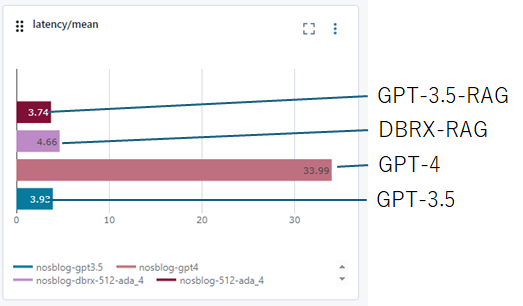
最後に遅延の比較を行います。遅延はMixtralと同等で、Llama2と比較するとかなり高速です。実用に耐えうる時間で文章生成を行えています。
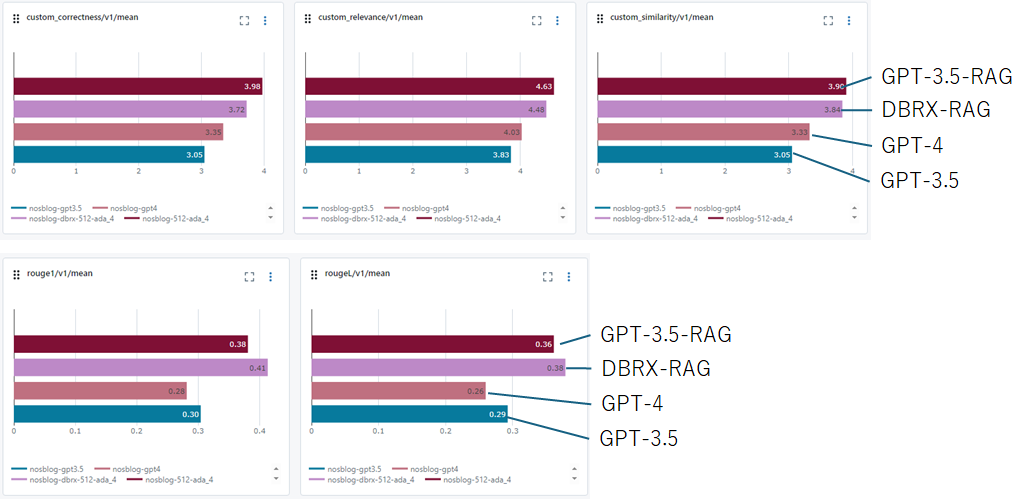
RAGでのGPT-3.5とDBRXの比較
DBRXは他のOpen LLMと比較しても十分な性能がある事がわかりました。次は先ほどと同一条件で、GPT-3.5と比較を行います。今回もLLM-as-a-Judge/ROUGE/遅延の3つの指標の比較を行います。以下各指標をみると、DBRXはGPT-3.5とほぼ同様の性能を実現出来ており、遅延もGPT-3.5の1.2-1.3倍程度だとわかります。
RAGで添付する文章を増やす
以下のDatabricksのDBRXのテクニカルレポートの中で、RAG部分を見るとDBRXは添付する文章(Context)が増えると良いスコアを出しています。
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
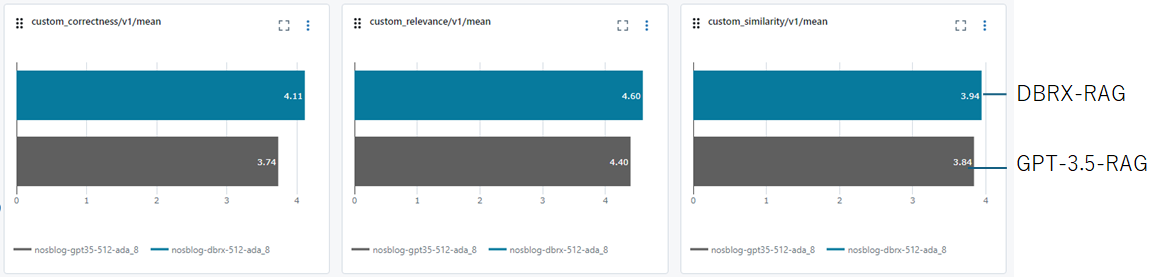
そこで添付文章(Context)を2,048トークンから4,096トークンの2倍に増やしてみてGPT-3.5とDBRXの比較を行います。LLM-as-a-Judgeでスコア付けを行った結果を見ると、DBRXがGPT-3.5よりスコアで上回っており、RAGで多くの文章を添付すればDBRXはGPT-3.5を超える良い精度の文章が生成可能な事がわかります。
所感
DBRXのレポートは英語でのRAGについて記述されていますが、日本語RAGでも同じ性能や傾向が出る事が確認出来ました。また、RAGの仕組みで参考文章としてコンテキストを増やしたい場合はGPT-3.5よりDBRXが良い選択肢になると思います。価格面に関してはGPT-3.5の価格が元々安価な為、支払い総額を考えると大きな問題にはならないと考えています。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


