
前回はNET ONE BLOGのデータを元にした生成AIの評価について、主にOpen AIのGPT-3.5をLLMのモデルとして利用していましたが、今回はOpen LLMのモデルを利用した場合の比較をしたいと思います。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
Databricks上でのOpen LLMの利用について
Databricksでは基盤モデル(Foundation Model)の利用方法として、単純にGPU Modelを使ったModel Servingの外にFoundation Model APIを用意しています。今回はFoundation Model APIsを使ってOpen LLMを利用し前回と同様RAGでの文章生成を行った文章を定量的に評価して、各モデルの比較を行います。
DatabricksのFoundation Model APIsについて
Databricks Foundation Model APIsを利用すると、LLM等の基盤モデルを簡単にDatabricks上で利用出来ます。3つのタイプのモデルをFoundation Model APIで利用可能となっています。
- 従量課金モデル
Llama 2 70B Chat等のModelが事前にDeployされており、Token数での従量課金となっています。特に設定や起動等の操作は必要無く直ぐにOpen LLMを利用できるのがメリットです。登録済みモデルの対応言語は英語のモデルばかりであり、日本語利用は今の時点では想定されていません。
- Databricks Market Placeモデル
Databricks Market Place内にいくつか代表的なモデルが登録されており、利用はスループット課金となります。モデルカタログの中から必要なモデルをワークスペースに追加します。追加した後にServing Endpointとして登録すれば利用を開始出来ます。選択したスループットとモデルサイズに応じてDBUが決められ、起動時間に応じて課金が行われます。Endpointの作成から始まる為、起動までに10分から40分程度必要です。
- Fine-tunedモデル
代表的なモデルをFine Tuneしたモデルを利用出来ます。使い方はMarket Placeのモデルとほぼ一緒ですが、モデルカタログへのモデル追加作業が必要となります。対応しているのはLlama2のFine Tunedモデル等なので日本語対応であればLlama2をFine Tuneした、Elyzaのモデル等が利用可能です。
Foundation Model APIsでのモデルの登録の方法
以下のコードで日本語モデルをFoundation Model APIsで利用する為の登録が可能です。基本的には、モデルの利用方法をChat/Completions/Embeddingから選んで、Metadataを一行追加するだけです。
|
import mlflow |
コードは以下のBlogを参考にさせていただきました。
"LLM-jp-13B" をDatabricks上でサービングする (zenn.dev)
モデルサービング
Marketplaceのモデルや、Metadataを追記したモデルを追加します。追加時にFoundation Model APIのモデルでは通常CPU/GPUのサイズを選ぶ場面で、スループットとして1秒間で処理出来るToken数を選ぶ画面になります。設定したスループットに応じてGPUのサイズ等は自動的に決定されます。また、最小スループットに応じた構成で起動し、トラフィック量が大きくなると最大スループットのインスタンスまで自動的にスケールアウトして設定したスループットを確保します。
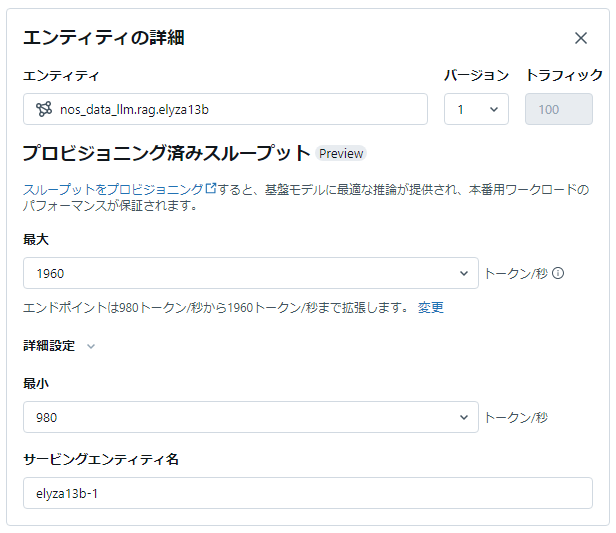
作成されたエンドポイントのモデルがFoundation Model APIsを利用している場合は稲妻のマークが追加されます。
Open LLMの評価結果
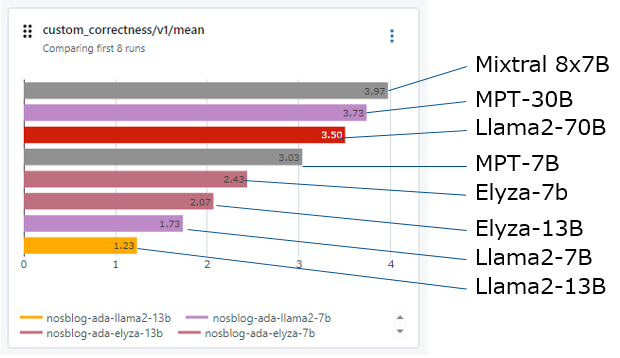
今回は前回と同様にRAGのアーキテクチャで、512のチャンクのドキュメントを4つ添付する形で文章を生成しました。前回は文章生成はAzure Open AIのGPT-3.5を利用していましたが、今回はオープンLLMのモデルを利用しています。今回はLlama2、Elyza、MPT、Mixtral-8x7Bを利用しています。各種モデルで計測してみた結果が以下になります。

大きなモデルほど結果が良いといったMixtral-8x7B Instructは良い結果を出しています。また回答内容も一応確認してみます。
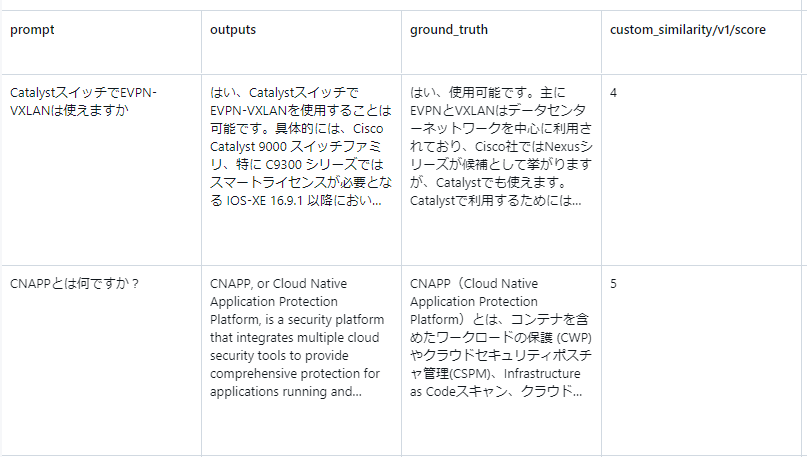
簡潔な回答や英語でも回答も散見されます。LLM as a Judgeでの評価は英語の意味を解釈できるので英語で答えても大きなスコアダウンにはなりません。しかしながら、ROUGE等の従来の手法は英語・日本語の違いは厳密さを見たり、答えが簡潔過ぎないかの確認も行う為別の観点でのスコアが出ています。以下先ほどと並びは同じですが、小規模モデルの方が評価は良いようです。
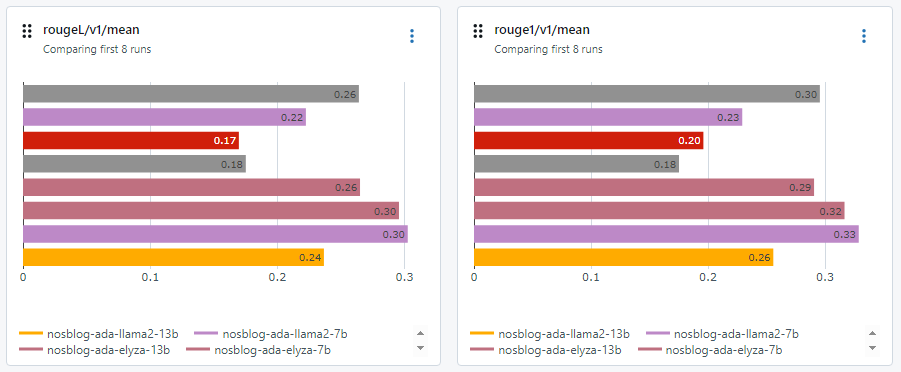
文章生成の遅延について
文章を生成する場合の遅延がどの程度か確認します。以下の状況をみると、従量課金モデルは比較的高速に応答を返しています。個別にデプロイされたモデルは最適化されているとはいえ、かなり遅延が生じてしまっています。同じタスクをGPT-3.5で実行すると3秒、GPT-4では30秒ほどでした。結果はGPT-4ほど極端に遅くは無いですが、速くもないようです。
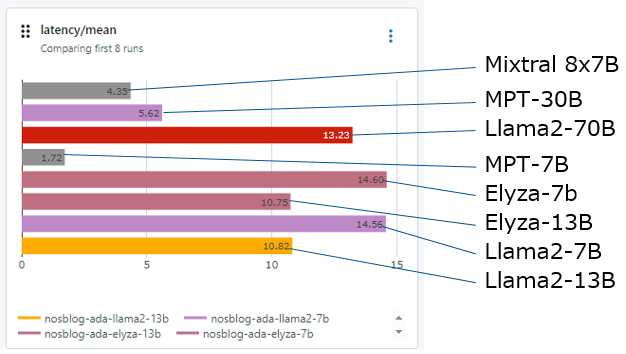
GPTとの比較
前回Azure Open AIのGPT-3.5を利用したRAGの結果でしたが、今回のOpen LLMの結果(上)とGPTを使った結果(下)を比較するとOpen LLMの上位のモデルであればGPT-3.5と同等の性能が出せる事が確認出来ます。
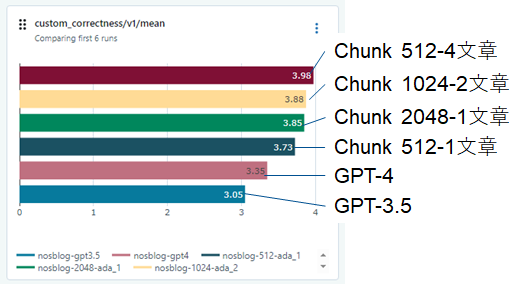
所感
DatabricksのFoundation Model APIsを利用するとOpen LLMを簡単にDeployして利用できることがわかりました。また、今回の結果から30B以上のモデルであれば、GPT-3.5向けのプロンプトで十分性能が発揮できていることがわかりました。しかしながら、元々日本語には正式に対応していないモデルの場合は、日本語で答えてくれるかの保証はありません。13Bや7Bのモデルの場合は日本語対応モデルでもRAGで大量の参考情報を渡してもうまく反映できていないように見えます。小規模モデルの場合は、更なるPromptの工夫やFine Tuningの実施の検討が必要なのかもしれません。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


