
前回はRAGの検索で、正しい文章を見つけてきているかの評価について書きました。今回は生成される文章に注目して、その評価方法を考えます。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
LLMを活用した評価について
LLMのシステムを構成する場合に、RAGであれば、文章検索の方法、Chunk Size、含めるDocumentの数、使用するLLMの種類等の様々な選択肢があります。質問(Prompt)に対して、理想的な回答を作っておき生成された文章と比較して定量的な評価が出来れば一番良い組み合わせを選択する事が出来ます。自然言語処理の世界では、従来は性能指標としてROUGEやBLUE等が利用されてきましたが2つの文章を比較して指標を出すだけでした。生成文章と回答の関係性や正しさ等の指標を出せないかという事で、新しくLLMを活用したLLM as a Judgeが考えられました。
https://arxiv.org/abs/2306.05685
DatabricksのLLM as a Judgeについて
MLFlowのEvaluateの中に新しくLLM as a Judgeの機能が取り込まれています。様々な実験を行い判断基準と判断例を含めたPromptを作成してLLMに送付して評価してもらいます。結果はエキスペリメントの画面で表示可能で、条件を変えた結果をRunに記録可能です。
RAGの作成と評価LangchainでDatabricksを活用した文章の作成
今回はDatabricksのVector StoreとLangchainを組み合わせてRAGのシステムを作成します。Embeddingは前回作成したAzure Open AIのada-002を利用しました。
|
from langchain.chains import RetrievalQA |
NET ONE BLOGのデータを使ったRAGシステムの評価の実施
Mlflow.evaluateを利用すると生成AIを使った評価を行えます。
今回も、前回Blogと同様にNET ONE BLOGのデータを使い、Correctness / Relevance / Similarityの3つを選択してGPT-4に評価を行ってもらいます。また、指定を行えばROUGEも計算されますので、指標として利用します。比較の条件ですが、Chunk Sizeと参照ドキュメント数を元に比較を行います。Chunk Sizeは512/1024/2048の3つで区切ります。ドキュメント数は2048を最大として、Chunk Size別では512の場合は最大4、1024の時には最大2、2048の時は最大1としました。以下のコードで条件を変えながら、評価を行っています。
|
from mlflow.models import infer_signature |
LLM as a Judgeでの評価結果
条件を変えながら、エキスペリメントに記録された結果は以下になります。
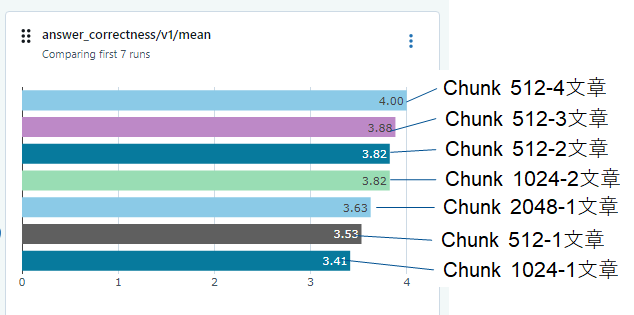
結果を見ると、Correctnessで大きな違いが出ておりChunkが512で、4文章を入れた場合が良いようです。しかしながら、詳細の結果画面を見るとNan(空)が結構入ってしまっているのがわかります。これは、今回利用したAzure Open AIからエラーが返ってきているのですが、GPT-4の一定時間でのAPI Callの上限に達してしまっている為、これ以上の評価が出来ない場合に(空)と記録されていると考えられます。
以下のMLflow中のコード中のdefault値を見るとWorkerが10であることが理由のように思えます。またmax tokenも200となっていますが、回答集は400程度の文字で書かれているのでmax tokenも400としたいところです。
https://github.com/mlflow/mlflow/blob/v2.9.2/mlflow/metrics/genai/genai_metric.py
Custom Metricを作成する
Workerの数とMax Tokenを調整したい為、CustomのMetricsとして作成します。以下の元のPromptを参考にすれば作成可能です。
mlflow/mlflow/metrics/genai/prompts/v1.py at v2.9.2 · mlflow/mlflow · GitHub
以下のようなコードでCustom Metricを作成可能です。Exampleは省略しています。
|
custom_correctness = make_genai_metric( examples=[custom_correctness_example_score_2, custom_correctness_example_score_4], |
改めて見るとLLM as a Judgeの為のPromptは結構長いことがわかります。
Custom Metricを利用した評価
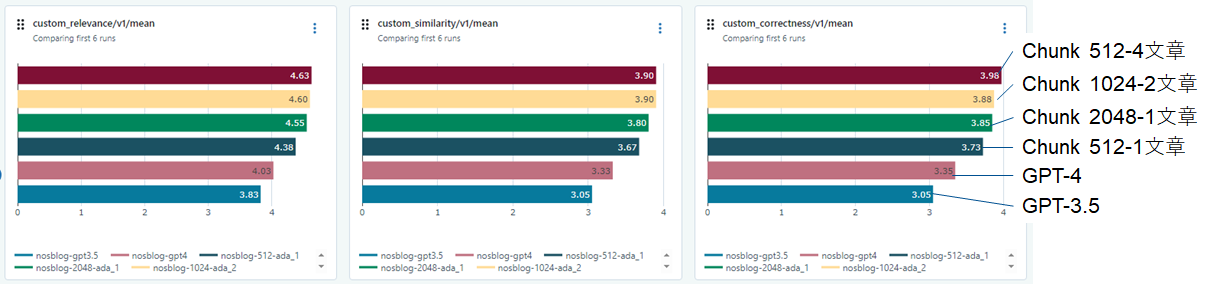
今回はRAGを使わないGPT-3.5/4の結果も含めました。RAGを使えば、GPT-3.5/4より3つの評価の値が改善されていることがわかります。また、512で4文章、1024で2文章が良い値でした。
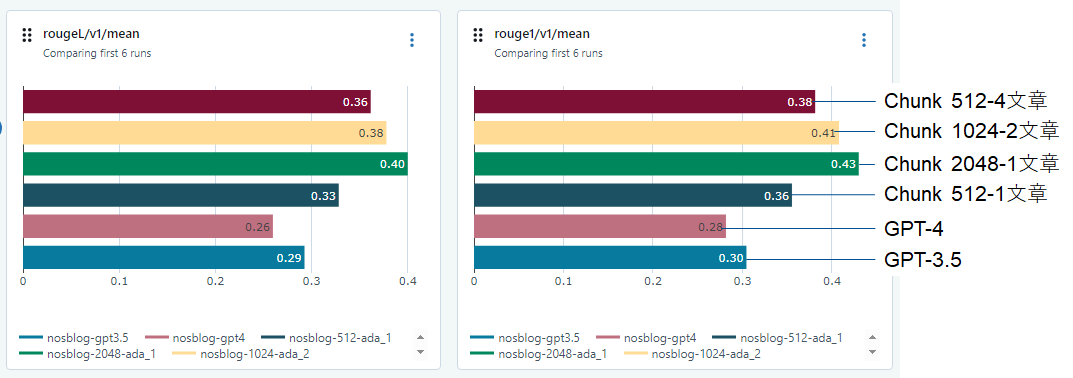
自然言語処理で利用されるROUGE-L/ROUGE-1も計算されるので、結果を見るとChunkが2048の場合が一番良い結果となっていました。上位の3つは評価の指標によって順位が変わる事が確認出来ました。
詳細を見ると、(空)が無くなっています。Workerを2として場合は2-3倍程度の時間がかかるようになってしまいました。
所感
LLM as a Judgeの機能を利用した条件を変えた場合にどのような評価となるかの確認を行いました。RAGのシステムを作る場合は、Chunk Sizeを小さくして複数の文章を添付した方が結果が良くなると言われていますが、今回も同様の結果が確認出来ました。RAGを使って検索対象の中に正しい文章が存在する場合は、GPT-4/3.5より良い文章を生成出来る事も確認出来ました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


