
前回RAGの環境について、お話しました。今回はDatabricksを使ったRAG環境のセットアップと実際のNET ONE BLOGのデータを使って様々な条件での検索の検証と比較検討を行います。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
はじめに
RAGで文章を生成する場合に、まずは参考となる文章をプロンプトを元に検索を用います。この場合は検索前の準備として、参考となるデータをある程度のサイズ(Chunk Size)に区切った後に、Embedding Modelを利用してベクトルに変換します。今回はこのEmbedding Modelの種類やChunk Sizeが検索結果にどのように影響するかの比較を行いたいと思います。検証にはDatabricksを利用しますが、DatabricksはMLFlow等のOSSをベースとしていますので、ご自身のオンプレミスでも同様の検証が可能です。
Embedding Modelを用意する
今回はHugging Face上に公開されている、日本語対応のEmbedding ModelであるMultilingual E5と、Open AIの提供するadaを利用します。また、英語のみ対応とされていますが、DatabricksがFoundation APIで提供しているBGEもテストしてみます。
Multilingual E5でのServingについて
Multilingual E5は日本語を含めて多言語対応のEmbedding Modelです。モデルサイズによって、Small /Base/Largeの3種類が提供されています。Databricksを利用してMultilingual E5をModel Servingします。今回はSmallとBaseを利用しました。
以下でmultilingual-e5-smallをHugging FaceからダウンロードしてDatabricksにモデル登録します。
|
from sentence_transformers import SentenceTransformer sentences = ["NetOne Systemsについて教えてください。"] |
登録されたModelを元にGUIを使ってEndpointを登録します。Modelを動作させるには、CPUのSmallで十分です。
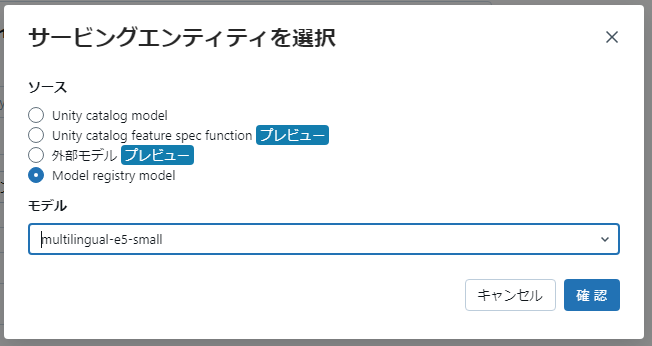
Open AIのAdaのServingについて
Databricksでは、Open AIのEmbedding Modelを外部モデルとして登録が可能です。以下Azure Open AIのada-002を登録する場合のサンプルです。
|
import mlflow.deployments |
Vector DBの作成
NET ONE BLOGを元にしてDatabricks上にデータを作成しておきます。Chunk Sizeは512/1024/2048の3つを用意しました。Vector DBはこのTableを元にGUIを利用して作成します。Embeddingの項目には用意したEmbedding Modelを選択します。
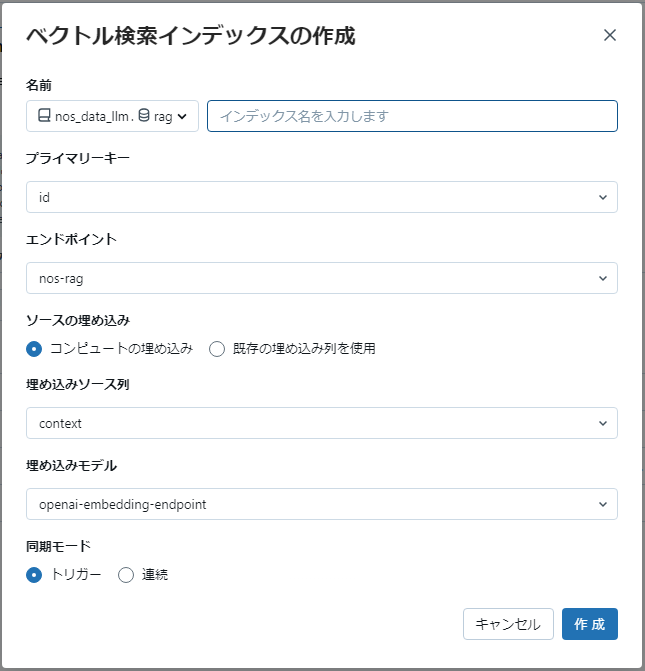
作成後いくつかのVector DBが作成されました。
RAGでのドキュメント検査の性能計測
model_typeをretrieverとするとRAGの為にDocument検索の為に使うprecision@k/recall@k/ndcg@kの計算を行ってくれます。
https://mlflow.org/docs/latest/python_api/mlflow.html#mlflow.evaluate
以下Evaluateを実施する場合のサンプルです。
|
with mlflow.start_run(run_name=run_name) as run: |
結果はエクスペリメントから参照可能で、様々な結果の確認が可能です。
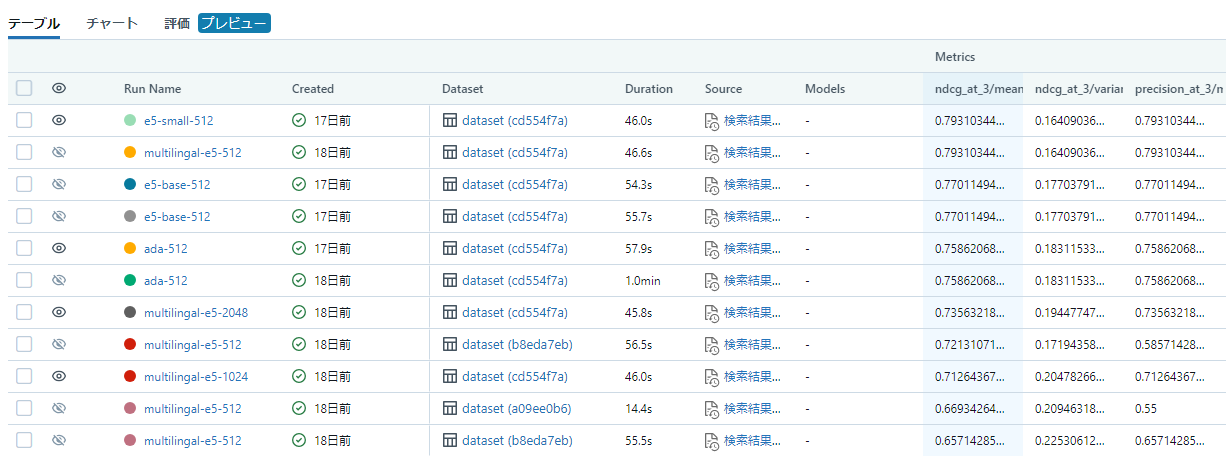
RAG計測結果と比較
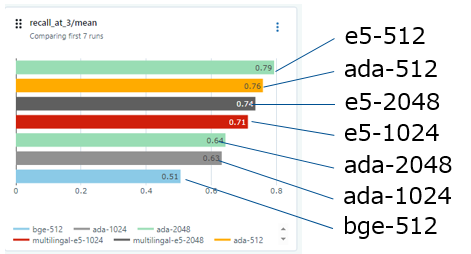
今回のNET ONE BLOGでの結果は以下の結果となりました。Documentの種類や様々な条件によって異なるので参考程度に考えてください。
- Chunk sizeは512の性能が良かった
- Multilingal-e5とada-002は同様の性能
- Chunk Sizeが大きくなるとada-002は性能が落ちた
- Bgeのモデルは日本語対応していないため、スコアは悪かった
考察
今回の結果は当該データに対する参考としてください。条件によっては結果が変わる可能性が高くなります。Chunk Sizeやmultilingual-e5はCPUベースで動作可能な為、adaの利用料と比較して安価な場合は候補に入れる事が出来ます。今回は社員で手分けして回答用紙を作成しましたが、外れている場合も回答用紙のURLと選んだURLの内容を比較した場合に、検索で選んでも問題ないように思える部分もありました。回答用紙の精度を高める作業も必要と、改めて感じました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


