
【セキュリティ文明開化シリーズ】
情報セキュリティ専門家として30年以上の経験を持つ山崎文明が、セキュリティ分野における世界での出来事を新たな視点や切り口でお届けします。
-------------------------------------------------------------
米国では人工知能(AI)テクノロジーの急速な普及と導入が進んでいることを「AIの津波」と呼んでいます。これは国土安全保障省税関国境警備局(CBP)部門の副最高データ責任者兼 AI ディレクターであるTrang Tran 氏が、12 月 13 日にワシントンD.C.で開催された ATARC(Advanced Technology Academic Research Center) の CIO サミット イベントで述べた言葉です。AIに飛びつく前に教育と訓練を通じてAIを理解することが重要だということについて学習データセットという側面から考えてみたいと思います。

- ライター:山崎 文明
- 情報セキュリティ専門家として30年以上の経験を活かし、安全保障危機管理室はじめ、政府専門員を数多く勤めている。講演や寄稿などの啓発活動を通じて、政府への提言や我が国の情報セキュリティ水準の向上に寄与している
目次
AIの本当のリスク
ChatGPTが2022年に公開されて満1年がたちました。SNSなどで大きな話題となり、業務にChatGPTが活かせないか、社員に「試しに使ってみよう」と号令をかけている企業も少なくありません。一方で、今年3月には有料版「ChatGPT Plus」で、一部のユーザーに別のユーザーのチャット履歴(他の人のプロンプト)が表示されてしまうなど、生成型AIの使用が新たな情報漏えいにつながるとの指摘もあります。
そんなセキュリティリスクも確かにありますが、AIを使用する本当のリスクはAIが、事実に基づかない情報を生成する、ハルシネーションと呼ばれる結果に気づかないで、そのままその結果を使用することではないでしょうか。AIはインターネット上に存在する大量のデータを学習していますが、インターネット上にはさまざまな誤った情報も多く存在しているため、それらを学習してしまうことで虚偽の情報を生成してしまうのです。
大阪府が高齢者向けにChatGPTをベースに開発された柴イヌの「大ちゃん」が、大阪万博について質問すると「2025年まで延期になった。」、「残念やけど大阪万博は中止になっちゃったみたい。」と誤った回答をしたり、開催期間を答えられなかったりする現象はSNSで話題になりました。大阪万博についての質問は誰もがその回答を知っていますので、AIの間違いだと気づきますが、そうでない場合は、大変なことになりかねないのです。
学習データが秘密
AIの優劣は「事前の学習」で決まります。試しにChatGPTに「ChatGPTのAI学習用データセットについて具体的な名前を教えて下さい。」と入力するとChatGPTは「私は具体的な学習用データセットの名前を知りません。OpenAIはGPT-3およびその他の言語モデルの学習に広範なデータを使用しています。このデータは、インターネット上の多様なウェブページ、書籍、ウィキペディア、ニュース記事などから収集されました。具体的なデータセットの内部の詳細や名前については公開されていません。」と答えました。
AIの信頼性や安全性を確保するためには学習用データに何を使用しているのかを明らかにすることはとても大切なことですが、ChatGPTは使用している学習用データセットは、今のところ秘密ということです。
学習に使用されるデータセット
AIの事前学習に使用されるデータセットは、「MNIST(エムニスト)」、「MegaFace(メガフェイス)」、「Common Crawl(コモン・クロール)」などがあります。
ChatGPTは、事前学習にコモン・クロールなどのテキストデータをデータベース化したものが使用されています。AIの世界的専門家として知られているアラン D.トンプソン博士(人口の上位2%の知能指数(IQ)を有する者の交流団体であるメンサインターナショナルの元会長)が、ChatGPTの学習用データセットについて明らかにしています。彼の分析では、OpenAI GPT-3モデルの場合は、コモン・クロールが60%、WebTex2が20%、Books1とBooks2が15%、Wikipediaが5%の割合で、学習用データセットとして主に使用されているようです。
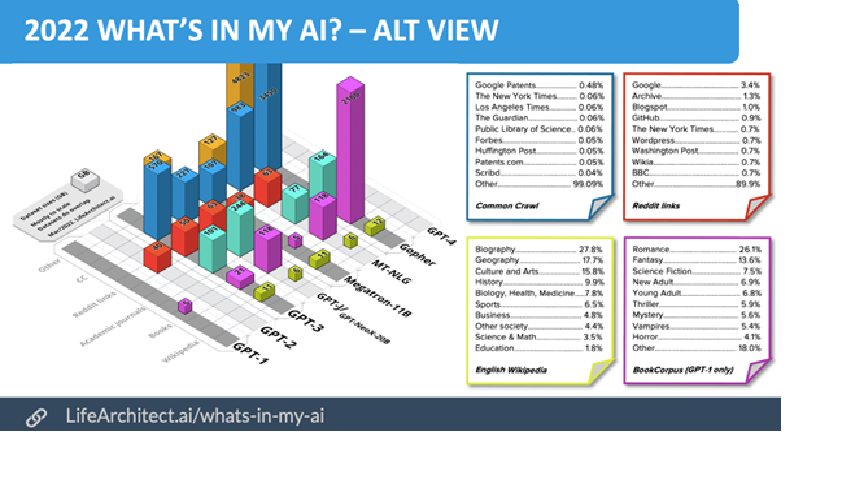 出典:https://lifearchitect.ai/whats-in-my-ai/
出典:https://lifearchitect.ai/whats-in-my-ai/
学習データセットの問題点
コモン・クロール社は非営利の団体で、2012年から世界中のインターネット上にあるウェブサーバーを手当たり次第にアクセスし、Webのページデータ(HTMLドキュメント)をデータベース化して、誰でもが自由に使えるようにしています。「知識のタイムカプセル」あるいは「公共の図書館」としての役割を果たすコモン・クロールは、毎月、インターネット全体をスキャンして記録しています。全世界には13億以上のドメインがありますが、ドメイン名とIPアドレスが紐つけされているドメインは3億程度といわれており、コモン・クロールは、その内の、およそ10%程度にアクセスしているに過ぎません。インターネット全体をカバーしているとは言い難いのが本当のところです。
WebTex2
WebTex2は、米国で人気があるレディット(Reddit)の投稿をデータベース化したものです。レディットは、投稿型ソーシャルサイトで、日本でかつて賛否が分かれた「2チャンネル」のようなもので、2チャンネルでいうところの「板」に当たるのが「サブレディット」、うろ覚えの映画のタイトルやテレビゲームの名前などを投稿すると、その投稿を手がかりに大勢の人が答えを探してくれるサブレディットや、歴史についてわからない時に簡単に要約した解説をしてくれるサブレディットなどがあります。ChatGPTは、このWebTex2のデータセットが大変気に入っているようで、ChatGPTのニューラルネットワークへの入力値として、5倍もの重み付けをしています。なぜ5倍もの重み付けをしているのかについて説明することは、学習用データセットに何を使用しているのかを開示する必要性と同様に、AIの透明性を確保する上で重要なことですが、これらの情報についても部分的にしか明らかになっておりません。
Books1とBooks2
Books1とBooks2は、オンラインで入手可能な無料電子書籍をデータベース化したもので、およそ11,000冊の書籍の全文が含まれていますが、約100,000冊もの電子書籍を毎日無料で閲覧可能としているスマッシュワード(SmashWord : https://www.smashwords.com/)で入手可能な書籍全体の2%に過ぎないともいわれています。また、選択された本のかなりの部分が重複もしくは三重に選択されていることもわかっています。したがって、固有の書籍の総数は、わずか7,200冊だととの分析もあります。こうした調査結果から、学習用データセットに使用されている書籍の数は、これまでに出版された全書籍の0.1%未満ではないかと推測されています。また、ジャンルもロマンスとファンタジーに偏っているようです。
言語の問題
インテリジェンスの歴史研究で有名な学者の一人は、ChatGPTを使用する人間を米国人と同じ思考に変えてしまうことを目的とした、米国が開発した新兵器だという主張をしています。世界最大の統計データを提供しているスタティスタ社の「ウェブサイトで利用されている言語割合」によると1位は、英語58.8%、2位ロシア語5.3%、3位スペイン語4.3%、4位フランス語・ドイツ語3.7%、6位日本語3.0%となっています。結果、学習用データセットのほとんどは、英語文化を反映したものであり、ChatGPTが出す答えも、多分に西洋的な考え方を表現しているのです。
また、宗教表現も特定の宗教に偏っているとの分析もあるようです。
出展:https://jp.statista.com/statistics/1357363/most-common-languages-on-the-
現状を知った上で使いこなす
ChatGPTが米国の新兵器かどうかはさておき、世間の批判を浴びぬようChatGPTが成長していくためには、ポルノや人種差別、憎悪にみちた言葉などを排除していくことが不可欠ですが、そうした行為は、検閲につながることも忘れてはなりません。また、ChatGPTの発話は、誰かが不快に感じる可能性を徹底して排除しなければなりませんが、子供が聞き、話し、議論し、変化しながら成長していくのと同様に、ChatGPTが物議を醸す見解を示したとしても、まだいくつかの懸念事項が存在することを理解しつつ、成長過程の子供を見守るような気持ちで接することが肝心です。
新しい技術を取り入れる際は、情報漏洩などの表面的なセキュリティリスクを意識するだけでなく、その技術の現在地を知る事がセキュリティの一丁目一番地と言えるでしょう。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


