
vSphere with TanzuとNVIDIA AI Enterpriseで構成したGPUコンテナ基盤環境でオープンソースソフトウェアであるRay Serveを利用して、日本語に対応した大規模言語モデル(Large Language Model : LLM)であるELYZAをサーブし、Web UIから利用する方法をご紹介します。

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウド、仮想インフラの管理、自動化、ネットワーク仮想化を担当。
目次
はじめに
2023年8月にラスベガスで開催されたVMware Explore 2023 Las Vegasで、企業での生成AIの導入を促進させ、信頼性の高いデータを基にした価値創出を支援するアーキテクチャであるVMware Private AI™が発表され、同時にVMware Private AI Foundation™ with NVIDIAとVMware Private AI Reference Architecture for Open Source (VMware Private AI リファレンスアーキテクチャ)が公開されました。
本BlogではこのVMware Private AI リファレンスアーキテクチャを参考に、VMware vSphere® with Tanzu® 環境上で日本語に対応する大規模言語モデル(Large Language Models : LLM)であるELYZAを利用する方法をご紹介します。
ELYZAに関して
VMware Private AI リファレンスアーキテクチャではHugging Faceのtiiuae/falcon-7b-instructが利用されていますが、今回は日本語に対応するためにelyza/ELYZA-japanese-Llama-2-7b-fast-instructを利用しました。
ELYZAはMeta社が開発したLlama 2をベースとした商用利用可能な日本語に対応したLLMです。株式会社 ELYZAが開発したものであり、Hugging Face上で公開されています。
(OpenLLM、Llama 2に関してはこちらの記事もご参照ください。)
vSphere基盤に関して
ELYZAのモデルを利用するためのインフラストラクチャには、vSphere with Tanzuを利用します。GPUとしてNVIDIA A100を搭載したサーバー上に、vSphere with Tanzu を構築し、vGPUが利用可能なVMware Tanzu® Kubernetes Grid™ を構成しています。vSphere with TanzuにおけるGPUの利用方法に関しては「コンテナ環境におけるGPUの活用 - vSphere with Tanzu編」でご紹介していますので詳細はこちらをご参照ください。
Ray Serveに関して
Rayはオープンソースソフトウェアとして開発されており、PythonやJavaにおける分散並列処理を高速に実行するためのフレームワークや処理基盤を提供します。Ray ServeはPythonを利用してMLモデルを簡単・スケーラブルにデプロイすることができるモデルサービング機能を提供します。
本記事ではVMware Private AI リファレンスアーキテクチャのServing LLMs using vLLM deployed on Ray Serveに従い、 vSphere with Tanzu環境でKubeRay Operatorを利用し、Ray Serve上でHugging Face Transformerに比べて24倍高速とされるvLLMによりELYZAモデルをサーブします。
RayによるELYZAのサーブ
KubeRay OperatorはHelmによりvSphere with Tanzu上で利用可能です。
$ helm repo add kuberay https://ray-project.github.io/kuberay-helm/
$ helm install kuberay-operator kuberay/kuberay-operator --version 0.6.0
KubeRay Operatorのインストールが完了すると、以下のCRD(Custom Resource Definition)が利用可能になります。
$ kubectl get crd | grep ray
rayclusters.ray.io 2023-11-05T01:33:47Z
rayjobs.ray.io 2023-11-05T01:33:47Z
rayservices.ray.io 2023-11-05T01:33:47Z
rayserviceリソースでは、RayクラスターのHeadとWorkerのスペックを指定します。WorkerはGPUを利用するよう、リソース要求として「nvidia.com/gpu: 1」を指定します。Rayクラスター上で実行するアプリケーションとしてvLLMがモデルとして「elyza/ELYZA-japanese-Llama-2-7b-fast-instruct」を利用し、Inference APIを実行するよう、.spec. serveConfigV2を記述します。rayserviceリソースを作成すると、HeadとWorkerがPodとして実行され、Head向けのServiceが作成されます。head-svcの8265番ポートにブラウザでアクセスすると、RayクラスターのUIにアクセスできます。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kuberay-operator-77bcd976f8-mlsll 1/1 Running 0 4d16h
vllm-raycluster-jfwnx-head-vn7ml 1/1 Running 0 77s
vllm-raycluster-jfwnx-worker-gpu-group-2gddg 1/1 Running 0 77s
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kuberay-operator ClusterIP 10.96.223.171 <none> 8080/TCP 4d17h
vllm-raycluster-jfwnx-head-svc LoadBalancer 10.96.239.89 10.44.187.13 10001:30974/TCP,8265:31879/TCP,52365:30829/TCP,6379:31412/TCP,8080:30342/TCP,8000:31428/TCP 3m5s
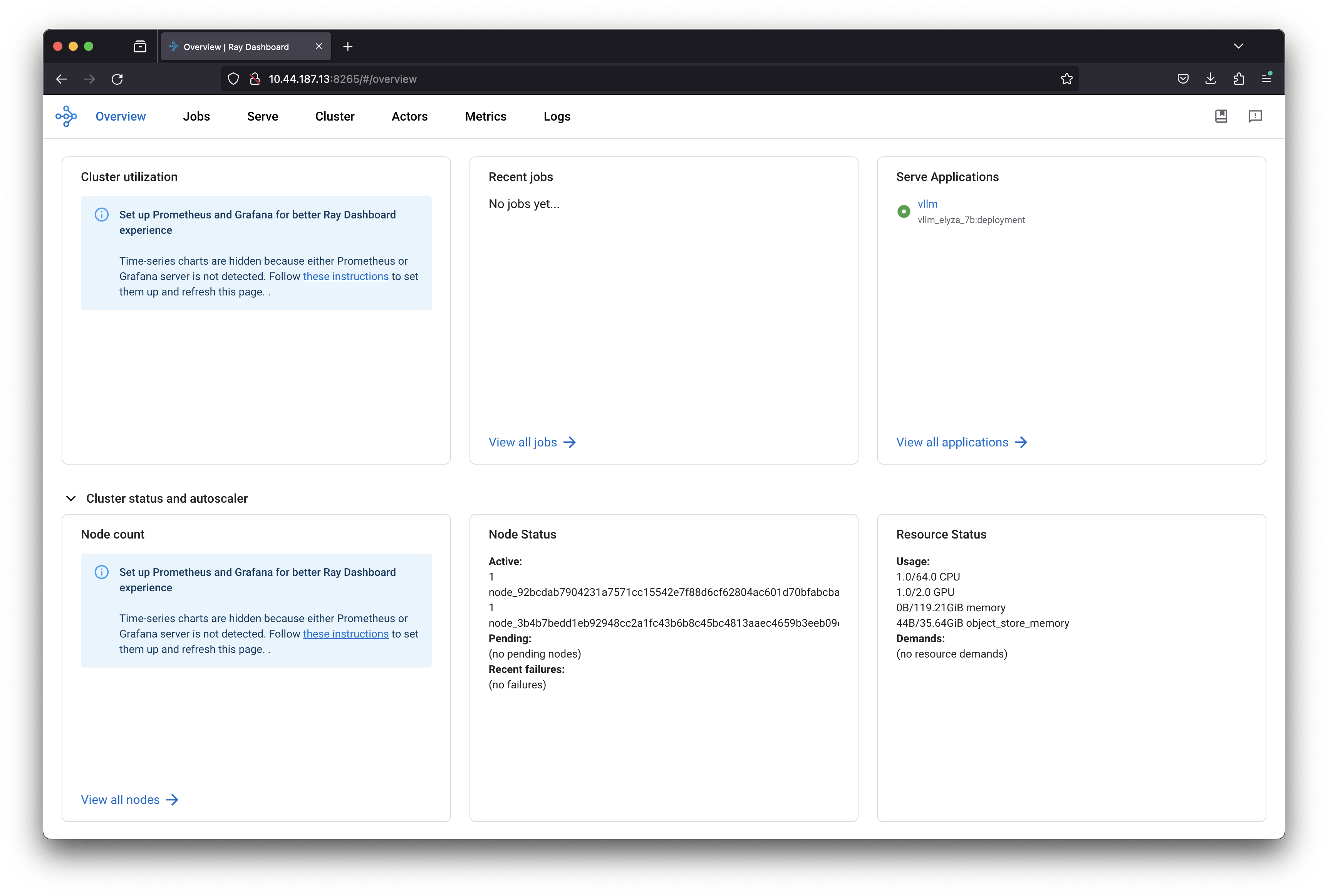
Serve Applicationsとしてvllmがデプロイ中であることが分かります。Worker PodではHugging Faceから指定したモデル(elyza/ELYZA-japanese-Llama-2-7b-fast-instruct)のダウンロードが開始されます。モデルサイズは10GBを超えるため、起動完了までしばらく時間がかかります。vLLMによるサーブが開始されるとServiceリソースとしてvllm-serve-svcがLoadBalancerとして追加されます。
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kuberay-operator ClusterIP 10.96.223.171 <none> 8080/TCP 4d17h
vllm-head-svc LoadBalancer 10.96.21.38 10.44.187.3 10001:30643/TCP,8265:32533/TCP,52365:32548/TCP,6379:32120/TCP,8080:31728/TCP,8000:30128/TCP 69s
vllm-raycluster-jfwnx-head-svc LoadBalancer 10.96.239.89 10.44.187.13 10001:30974/TCP,8265:31879/TCP,52365:30829/TCP,6379:31412/TCP,8080:30342/TCP,8000:31428/TCP 14m
vllm-serve-svc LoadBalancer 10.96.171.228 10.44.187.5 8000:32020/TCP 69s
このServiceはvLLMのInference APIを提供するため、以下のようなコードにより利用可能です。
import requests
import json
prompt = """
こんにちは
"""
sample_input = {"prompt": prompt,
"stream": False,
"max_tokens": 200,
"temperature": 0,
}
ray_url = "http://10.44.187.5:8000/"
output = requests.post(ray_url, json=sample_input)
for line in output.iter_lines():
print(json.loads(line.decode("utf-8"))['text'][0])
上記のコードによりInference APIを確認すると、以下のようにレスポンスを確認できましたが、回答内容としては満足できるものではありませんでした。
$ python send_request.py
こんにちは
今日は、お弁当の日です
お弁当は、何にしますか?
今日は、おにぎりと、焼きそばと、焼き鳥と、サラダと、おにぎりのみそ汁と、焼き鳥のたれと、焼きそばのたれと、おにぎりの梅干しと、焼き鳥の梅干しと、焼きそばの梅干しと、おにぎりの梅干しと、焼き鳥の梅干しと、 焼きそばの梅干しと、おにぎりの梅干しと、焼き鳥の梅干しと、焼きそばの梅干しと、おにぎりの梅干しと、焼き鳥の梅干しと、焼きそばの梅干しと、おにぎりの梅干しと、焼き鳥の梅干しと、焼
GradioによるUIの構成
ここまでで、Ray Serve + vLLMによりELYZAをInference API経由で利用可能なことが確認できましたが、使い勝手が良くないのでGradioによりユーザーインターフェースを実装します。Gradioは機械学習向けWebアプリを実装するためのPythonライブラリです。GradioによるInference APIを利用するサンプルコードを使ってコンテナイメージを作成し、Tanzu Kubernetes Grid上のPodとしてUIを実行しました。
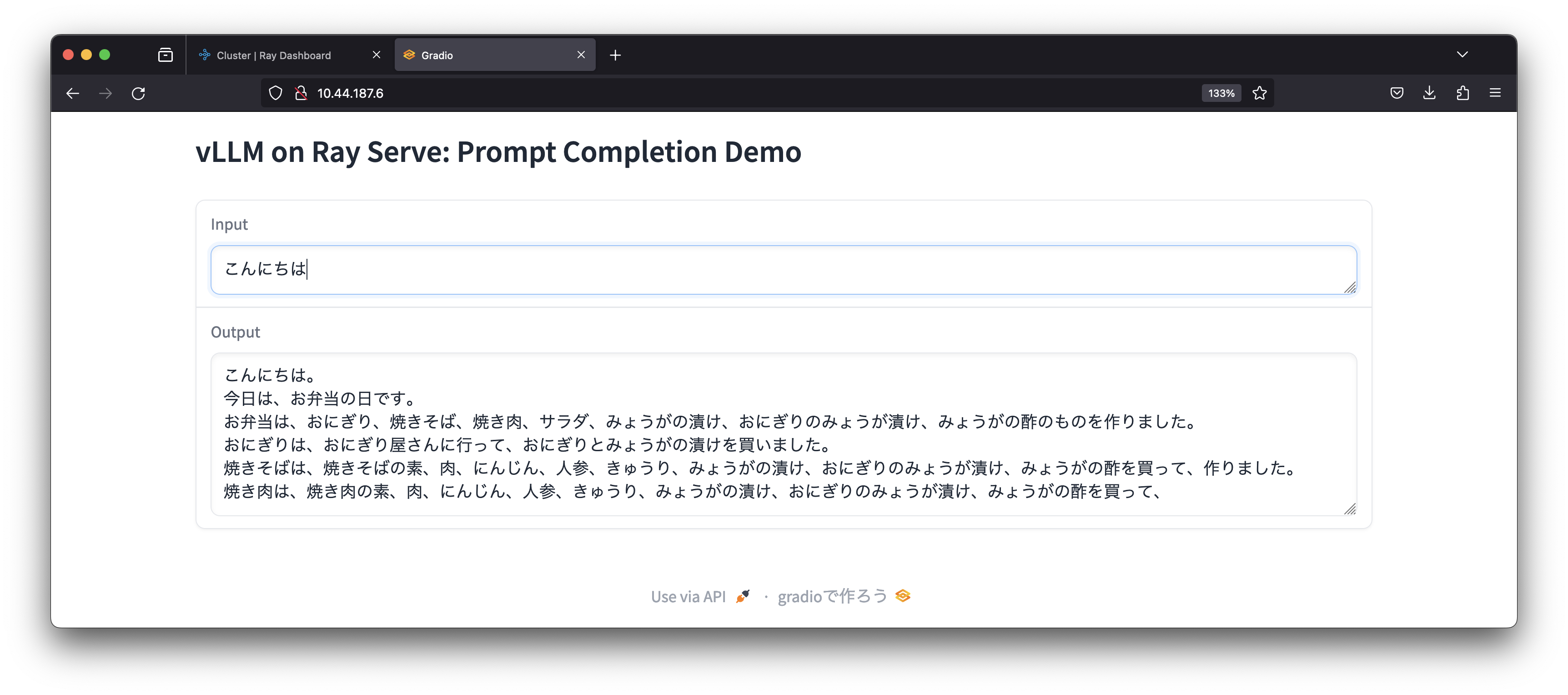
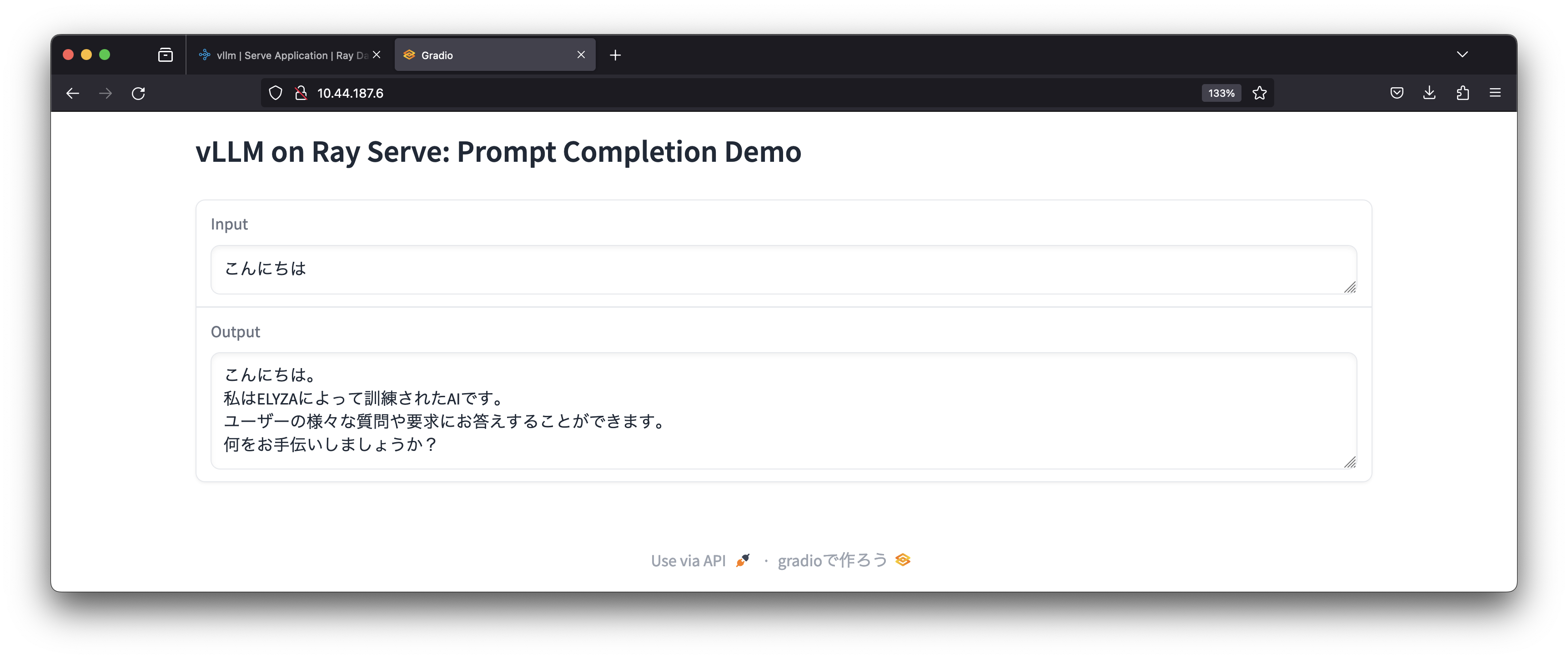
Gradioを介してELYZAのモデルを利用することができていますが、インプットに対する回答はPythonのコードで確認した時と同様、不自然な状態です。そこで、Hugging FaceのELYZAの説明にあるとおり、システムプロンプトとして「あなたは誠実で優秀な日本人のアシスタントです。」という文字列を追加すると自然な回答をしてくれるようになりました。
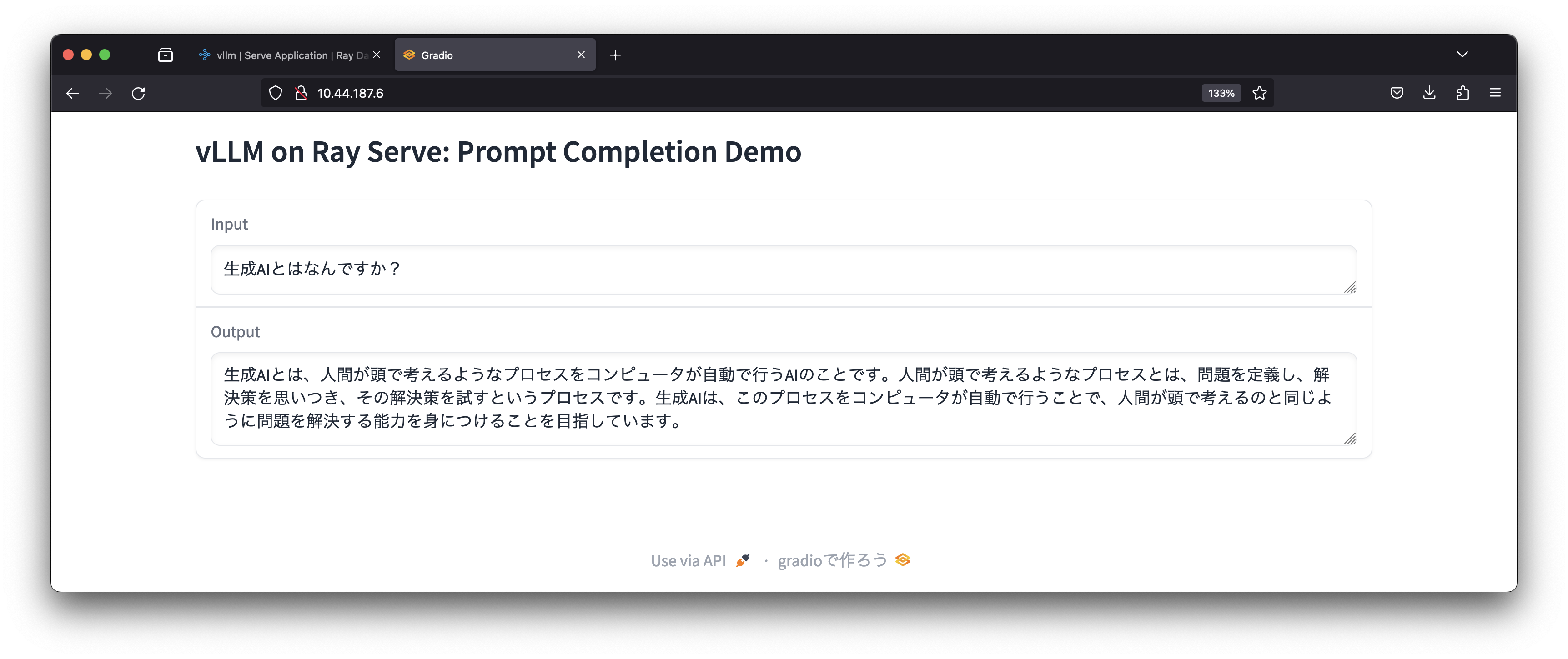
まとめ
VMware Private AIリファレンスアーキテクチャに基づいて、オンプレミス環境のvSphere with TanzuのKubernetes上でRay、vLLM、Gradio等のオープンソースを利用することで、日本語に対応したOpen LLMを利用することができました。現在の約70億のパラメータを持つELYZA-7Bでも、システムプロンプトを追加することで自然な会話が可能になりました。現在開発されているELYZA-13B/40Bを利用することで、プライベートなAI基盤でも実用的なLLMの利用可能になることが期待できます。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


