

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
はじめに
こちらのBlog記事ではコンテナ環境でGPUを活用するためのNVIDIA AI Enterprise + VMware vSphere® with VMware Tanzu® をご紹介しました。今回は2回の記事に分けて、この環境を利用して自然言語処理モデルであるBERTをチューニングし、開発したAIモデルをTriton Inference ServerによりKubernetes上でコンテナとして実行し、Kubernetesのオートスケール機能によってスケールアウト・スケールインを実現する方法をご紹介します。
- GPUプラットフォームにおけるAIモデルの開発と推論の実現 (前編) : BERTモデルの開発とKubernetesに対する推論サーバーのデプロイ
- GPUプラットフォームにおけるAIモデルの開発と推論の実現 (後編) : Kubernetes上にデプロイした推論サーバーのオートスケール (本記事)
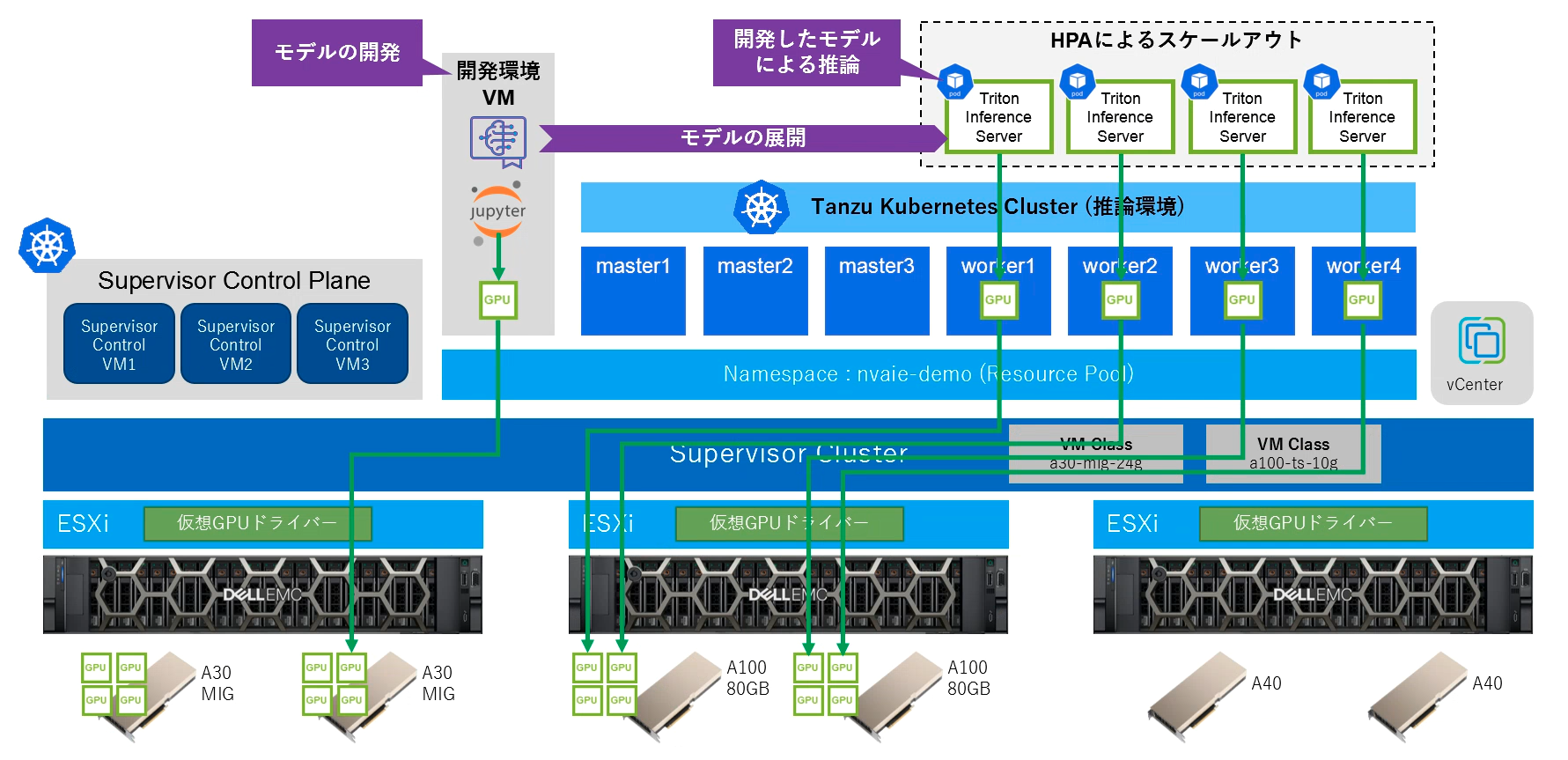
Triton Inference Serverのオートスケール設定
KubernetesのHPAでカスタムメトリクスを利用してオートスケールを実現するために、Prometheusを利用します。Tanzu Kubernetes ClusterをTanzu Mission Controlに登録すると、Tanzu Packageとしてソフトウェアのインストールが可能になります。今回はこのカタログに含まれるPrometheusをインストールします。
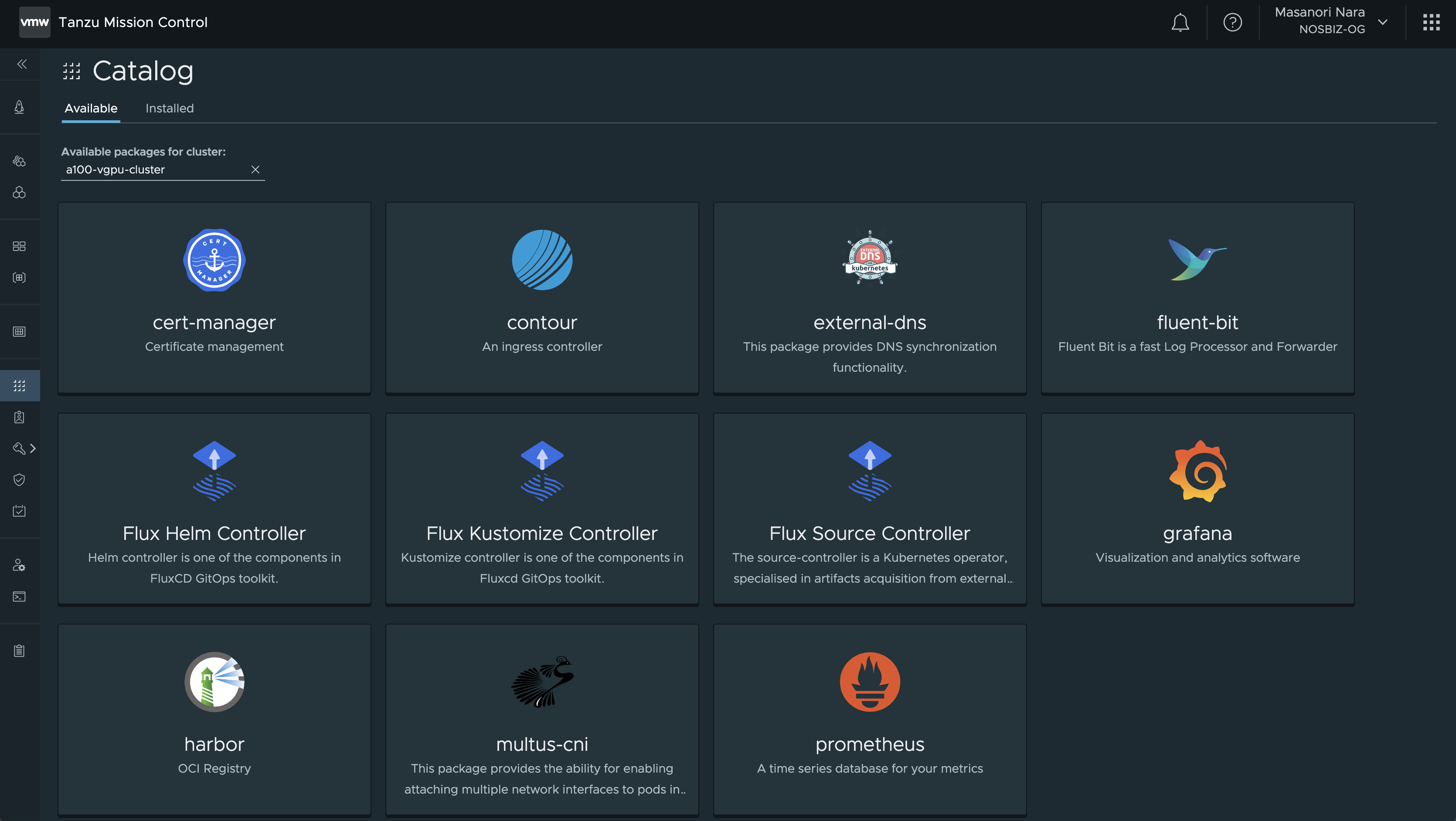
Prometheusをデフォルトの設定でインストールすると、Kubernetesの各種メトリックを格納する構成でPrometheusが構成されますが、今回はDCGM Exporterが出力するNVIDIA GPUのメトリックを格納するよう、Prometheusパッケージのインストール時にprometheus.config.prometheus_ymlを以下の内容で上書きします。尚、Triton Inference Serverもリクエストキュー滞留時間などのメトリックを出力することができ、これらのメトリックを利用してオートスケールすることも可能です。
|
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
尚、クラスター外部からPrometheusのUIにアクセスするには、prometheus.service.typeとしてLoadBalancerを指定するか、monitoring.ingress.enabledと monitoring.ingress.virtual_host_fqdnを設定してIngressを構成します。
Prometheus Adapterのインストール
Prometheus AdapterはクラスターでDeploymentとして実行され、Prometheusに格納されたメトリクスをKubernetesのカスタムメトリクスAPI(custom.metrics.k8s.io)から参照することを可能にします。KubernetesのHorizontalPodAutoscalerはこのカスタムメトリクスを利用してリソースのスケーリングを行います。Prometheus AdapterはPrometheus Community Kubernetes Helm Chartsで公開されているHelm Chartを利用してインストールします。prometheus.urlには、Prometheus向けのServiceリソースの名前を指定します。Tanzu PackageとしてPrometheusをインストールした場合は「prometheus-server.tanzu-system-monitoring.svc.cluster.local」がデフォルトとなります。
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts $ helm install --name-template prometheus-adapter \ --set rbac.create=true,prometheus.url=http://prometheus-server.tanzu-system-monitoring.svc.cluster.local,prometheus.port=80 \ prometheus-community/prometheus-adapter
Prometheus AdapterをインストールするとカスタムメトリクスAPI経由でDCGM Exporterのメトリクスにアクセス可能になります。
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq | grep DCGM_FI_DEV_GPU_UTIL
"name": "namespaces/DCGM_FI_DEV_GPU_UTIL",
"name": "jobs.batch/DCGM_FI_DEV_GPU_UTIL",
"name": "pods/DCGM_FI_DEV_GPU_UTIL",
Horizontal Pod Autoscalerの構成
bert-qa Deploymentに対してHPAリソースを定義し、Podがオートスケールするように構成します。DCGM Exporterが出力し、Prometheusに格納されたDCGM_FI_DEV_GPU_UTILメトリックを指標として、40を超える値が続いた場合に最大で4つまでPodを増やす事が可能になります。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: gpu-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: bert-qa
minReplicas: 1
maxReplicas: 4
metrics:
- type: Pods
pods:
metricName: DCGM_FI_DEV_GPU_UTIL
targetAverageValue: 40
作成されたHPAリソースを確認すると現在のメトリックの状態と、Podの状態が表示されます。
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 0/40 1 4 1 4s
Triton Inference Serverのオートスケールの確認
以下のマニフェストによりクライアント用のPodを作成し、perf_clientスクリプトによりTriton Inference Serverに対して負荷をかけます。接続先はTriton ServerのClusterIPのgRPCポートを指定します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: perf-client
labels:
app: perf-client
spec:
replicas: 1
selector:
matchLabels:
app: perf-client
template:
metadata:
labels:
app: perf-client
spec:
imagePullSecrets:
- name: nvaie-demo-default-image-pull-secret
containers:
- name: serving
image: 10.44.187.8/nvaie-demo/tritonserver-2-0:22.02-nvaie-2.0-py3-sdk
command: ["/bin/sh"]
args: [ "-c", "/workspace/install/bin/perf_client -v --max-threads 10 -m bert -x 1 -p 200000 --input-data zero --concurrency-range 50 -i gRPC -u bert-qa:8001""]
perf-clientがPodとして追加されます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE bert-qa-74dbc5fcbc-7zsh9 1/1 Running 0 111s perf-client-78cb995ddf-6clx4 1/1 Running 0 7s
HPAの状態を確認すると、TARGETSが40を超え、REPLICASが3に変化したことが確認できます。
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 0/40 1 4 1 91s $ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 82/40 1 4 1 119s $ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 41/40 1 4 3 2m
Podの状態を確認すると新たに2つのbert-qaが追加され合計3Pod実行されていことが確認できます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE bert-qa-74dbc5fcbc-7zsh9 1/1 Running 0 3m39s bert-qa-74dbc5fcbc-hphjb 1/1 Running 0 53s bert-qa-74dbc5fcbc-nvbgr 1/1 Running 0 53s perf-client-78cb995ddf-6clx4 1/1 Running 0 115s
HPAを確認すると、DCGM_FI_DEV_GPU_UTILがTarget値を超えたため、Podがスケールアウトしたことを確認できます。
$ kubectl describe hpa gpu-hpa Name: gpu-hpa Namespace: triton-server Labels:Annotations: CreationTimestamp: Fri, 24 Jun 2022 21:16:17 +0900 Reference: Deployment/bert-qa Metrics: ( current / target ) "DCGM_FI_DEV_GPU_UTIL" on pods: 27 / 40 Min replicas: 1 Max replicas: 4 Deployment pods: 3 current / 3 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric DCGM_FI_DEV_GPU_UTIL ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 102s horizontal-pod-autoscaler New size: 3; reason: pods metric DCGM_FI_DEV_GPU_UTIL above target
perf-client podを停止してしばらくすると、TARGETSが0になり更にしばらく待つとPod数はMINPODSとして指定されている1つまで減少します。
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 0/40 1 4 3 6m48s $ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 0/40 1 4 3 11m $ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE gpu-hpa Deployment/bert-qa 0/40 1 4 1 11m $ kubectl get pod NAME READY STATUS RESTARTS AGE bert-qa-74dbc5fcbc-7zsh9 1/1 Running 0 14m
HPAを確認すると、全てのメトリックがTarget値を下回ったため、Pod数が1つに減らされたことが確認できます。
$ kubectl describe hpa gpu-hpa Name: gpu-hpa Namespace: triton-server Labels:Annotations: CreationTimestamp: Fri, 24 Jun 2022 21:16:17 +0900 Reference: Deployment/bert-qa Metrics: ( current / target ) "DCGM_FI_DEV_GPU_UTIL" on pods: 0 / 40 Min replicas: 1 Max replicas: 4 Deployment pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric DCGM_FI_DEV_GPU_UTIL ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 10m horizontal-pod-autoscaler New size: 3; reason: pods metric DCGM_FI_DEV_GPU_UTIL above target Normal SuccessfulRescale 29s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
Tanzu PackageにはPrometheusの他にGrafanaも含まれており今回DCGM Exporterによって出力したメトリックや、Triton Inference Serverのメトリック等をグラフとして可視化することも可能です。
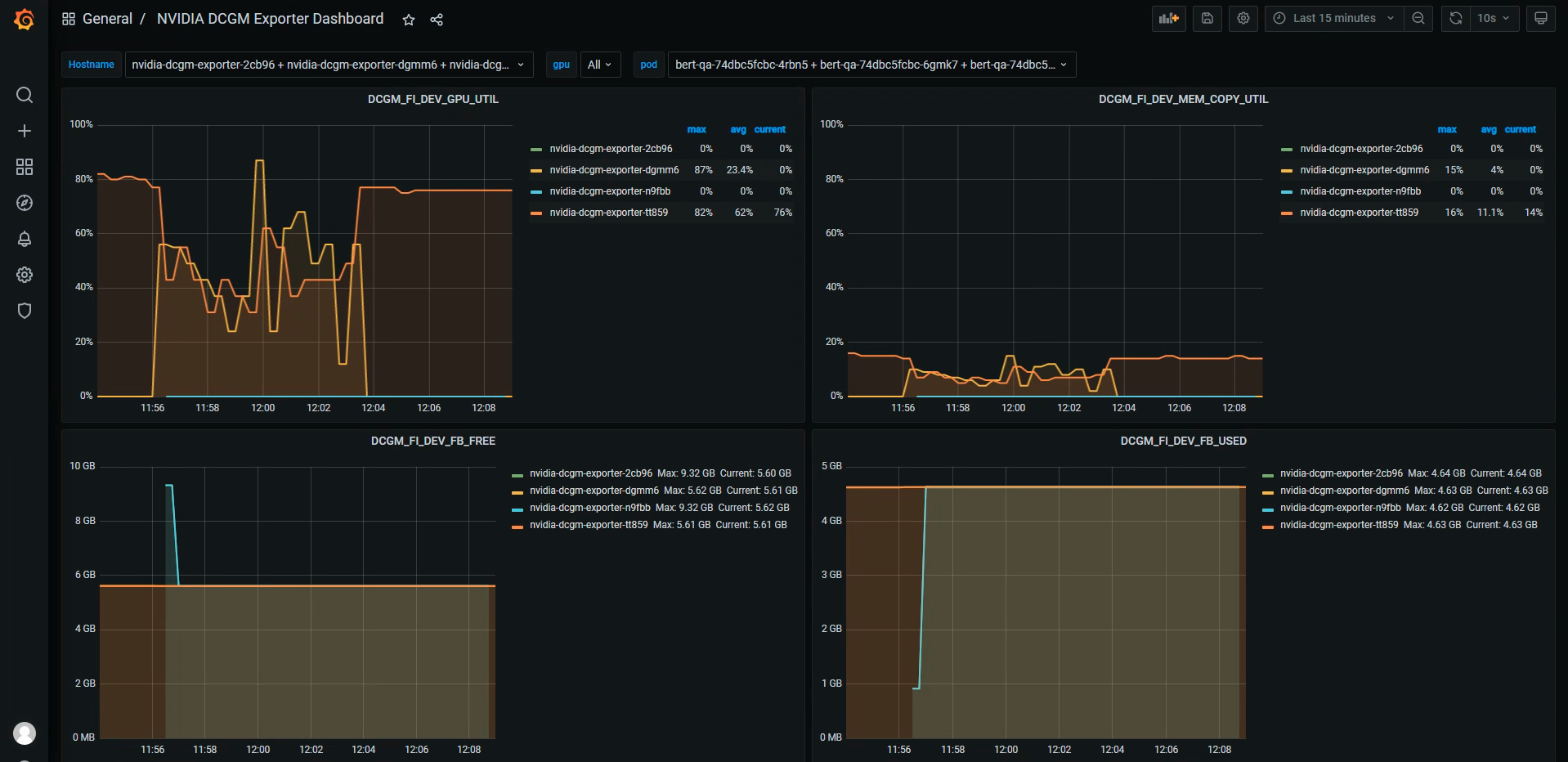
まとめ
2回の記事に渡り、モデル開発と開発したモデルを利用してどのように推論をサービスとして提供するのかをご紹介しました。NVIDIA AI EnterpriseとvSphere with Tanzuの環境であれば、モデルの開発環境や、推論サーバーであるTriton Inference Server、KubernetesのHPAに必要なDCGM Exporter、vSAN File ServiceによるNFSファイル共有、コンテナイメージを格納するHarbor Registry、Tanzu Packageによるアプリケーションのインストール等がサポートされるため、プロダクション向けGPUプラットフォームの実現が可能になります。NVIDIA AI EnterpriseとvSphere with Tanzuの導入に関しては、是非弊社までお問合せください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


