

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
はじめに
こちらのBlog記事ではコンテナ環境でGPUを活用するためのNVIDIA AI Enterprise + VMware vSphere® with VMware Tanzu® をご紹介しました。今回は2回の記事に分けて、この環境を利用して自然言語処理モデルであるBERTをチューニングし、開発したAIモデルをTriton Inference ServerによりKubernetes上でコンテナとして実行し、Kubernetesのオートスケール機能によってスケールアウト・スケールインを実現する方法をご紹介します。
- GPUプラットフォームにおけるAIモデルの開発と推論の実現 (前編) : BERTモデルの開発とKubernetesに対する推論サーバーのデプロイ (本記事)
- GPUプラットフォームにおけるAIモデルの開発と推論の実現 (後編) : Kubernetes上にデプロイした推論サーバーのオートスケール
- BERT (Bidirectional Encoder Representations from Transformers)
BERTはGoogleが開発した深層学習を利用した自然言語処理モデルの1つです。翻訳、文書分類、質問応答等の自然言語処理タスクに対してBERTの学習は大量データによる「事前学習」と少量データによる「ファインチューニング」の2段階でモデルの開発を行います。NVIDIAはNGCを通じて事前学習済みのBERTモデルを公開しており、NVIDIAが公開するBERTはGoogleの公式実装をNVIDIAのGPUに最適化しています。
- SQuAD (The Stanford Question Answering Dataset)
SQuAD(The Stanford Question Answering Dataset)はスタンフォード大学が作った質問応答データセットです。Wikipedia 英語版の記事とその記事内容に対する質問、その回答のテキストのセットで構成されており、500以上の記事と100,000以上の質問と回答のペアが含まれています。 SQuADによりBERTの事前学習モデルをファインチューニングすることで、質疑応答タスク向けのモデルを作成することが可能です。
- NVIDIA Triton Inference Server™
NVIDIA Triton Inference ServerはTensorFlow、TensorRT、PyTorch、OpenVINO、RAPIDS FIL、LightGBM、ONNX Runtime等のメジャーなフレームワークをデプロイすることが可能です。また、C++やPythonで独自の処理を実装し、同様にデプロイすることも可能です。これらのフレームワークで生成したモデルを変換することなくGPUやCPUサーバーにデプロイすることが可能です。データサイエンティストは、フレームワークやネットワークを自由に選択することができ、開発者とIT運用者はこれらのネットワークによって訓練されたモデルを簡単にサポートすることが可能です。
開発環境の構築とモデル開発
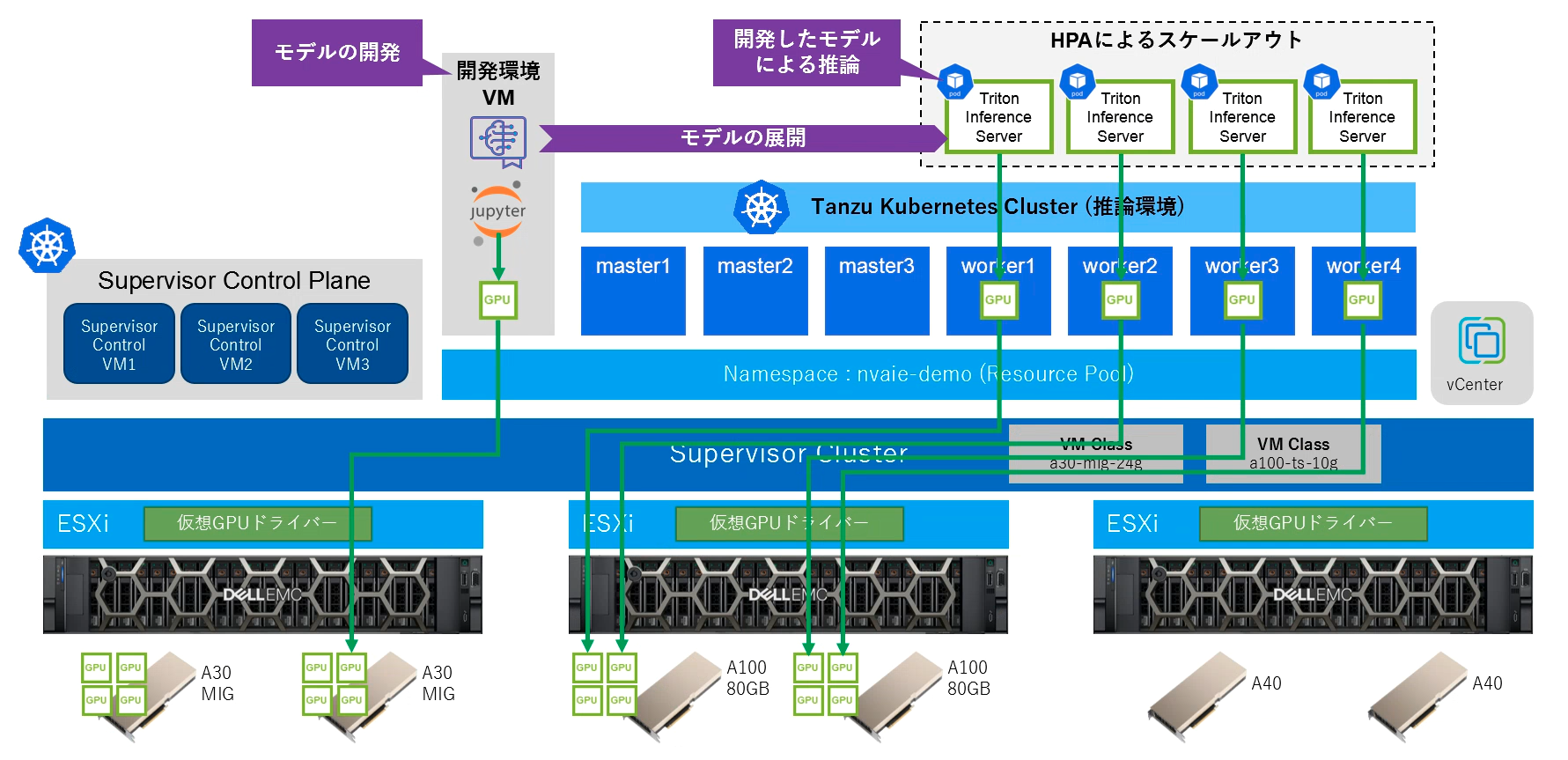
仮想マシンの作成
vSphere with TanzuではSupervisor ClusterのVM Serviceを利用して、Tanzu Kubernetes Cluster 環境に加え、単体の仮想マシンをデプロイすることが可能です。今回は機械学習モデルを開発する環境として Ubuntuベースの仮想マシンを作成します。モデルの開発に利用するコンテナイメージは各種ライブラリが含まれているため、比較的大容量となります。コンテナイメージが格納されるデータ領域(/var/lib/docker)と、モデルを格納するホームディレクトリ領域(/home)に対してPersistent Volume Claimを作成して仮想マシンに接続して、ディスク容量を増やし、データを永続化します。
apiVersion: vmoperator.vmware.com/v1alpha1
kind: VirtualMachine
metadata:
name: gpu-vm1
labels:
app: gpu-vm1
spec:
imageName: ubuntu-20-1633387172196
className: a30-mig-24g
powerState: poweredOn
storageClass: unity-k8s
vmMetadata:
configMapName: vm1-cm
transport: OvfEnv
networkInterfaces:
- networkType: nsx-t
volumes:
- name: gpu-vm1-pvc1
persistentVolumeClaim:
claimName: gpu-vm1-pvc1
- name: gpu-vm1-pvc2
persistentVolumeClaim:
claimName: gpu-vm1-pvc2
.spec.classNameとして指定しているa30-mig-24gはNVIDIA A30のGPUメモリー24GBを共有モードとして「マルチインスタンスGPU共有」(MIG)でvGPUを構成します。
仮想マシンのスペック(.spec.vmMetadata)としてcloud-configのデータを含むConfigMapを指定することで仮想マシンをカスタマイズすることが可能です。ConfigMap内ではユーザーの作成や、接続されたPersistent Volume Claimのマウントポイント等を設定します。作成した仮想マシンのSSHとJupyter Notebookに対して外部から接続できるよう、VirtualMachinesServiceをLoadBalancerとして作成します。
apiVersion: vmoperator.vmware.com/v1alpha1
kind: VirtualMachineService
metadata:
name: gpu-vm1-svc
spec:
selector:
app: gpu-vm1
type: LoadBalancer
ports:
- name: jupyter
port: 8888
protocol: TCP
targetPort: 8888
- name: ssh
port: 22
protocol: TCP
targetPort: 22
VM上のコンテナでvGPUを利用してモデル開発を行うため、仮想マシンにはNVIDIAドライバー、NVIDIA Container Toolkit、Dockerをインストールします。
BERTモデルのファインチューニング
NVIDIAが公開しているDeepLearningExamplesリポジトリを利用して、VM上でTensorflowコンテナを実行し、Jupyter Notebook経由でBERTモデルのファインチューニングを行います。DeepLearningExamplesリポジトリには、モデル開発で利用するための各種スクリプトとNotebook
NGCで公開されているコンテナイメージ(tensorflow-2-0:22.02-tf1-nvaie-2.0-py3)をベースとして、モデル作成用のコンテナイメージをビルドし、launch.shによってコンテナを起動します。launch.shスクリプトの実行により、VMのカレントディレクトリ(DeepLearningExamples/TensorFlow/LanguageModeling/BERT/)が/workspace/bertと/resultsとしてマウントされます。
git clone https://github.com/NVIDIA/DeepLearningExamples.git cd DeepLearningExamples/TensorFlow/LanguageModeling/BERT/ docker build . --rm -t bert --build-arg FROM_IMAGE_NAME=nvcr.io/nvaie/tensorflow-2-0:22.02-tf1-nvaie-2.0-py3 bash scripts/docker/launch.sh
コンテナ内でファインチューニングに利用するSQuaD 1.1データセットをダウンロードします。
python3 /workspace/bert/data/bertPrep.py --action download --dataset squad
コンテナ内でJupyter Notebookを起動します。
jupyter notebook --ip=0.0.0.0 --allow-root
Jupyter Notebookの起動が成功すると、GUIにアクセスするためのTokenが表示されます。ブラウザでVMの8888番ポートにアクセスし、生成されたTokenを利用してJupyter Notebookにログインし、notebooksフォルダ内のbert_squad_tf_finetuning.ipynbを開き、「BERT Question Answering Fine-Tuning with Mixed Precision」を実行します。
このNotebookではNVIDIAが公開しているBERTのTensorFlow事前学習モデルをNGCからダウンロードし、SQuAD v1.1データセットによってファインチューニングしてモデルを再生成します。
BERTモデルのエクスポート
実行中のnotebookをshutdownして、作成したファインチューニングしたモデルをrun_squad.pyスクリプトでコンテナ内の/workspace/bert/tritionディレクトリにTritonで読み込める形式としてエクスポートします。
python run_squad.py --vocab_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/vocab.txt --bert_config_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/bert_config.json --init_checkpoint=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/model.ckpt --max_seq_length=384 --doc_stride=128 --predict_batch_size=8 --output_dir=/workspace/bert/triton --export_triton=True --amp --use_xla
指定したディレクトリ(/workspace/bert/triton)にtriton_models/bertディレクトリが作成され、配下にTriton向けのモデルが格納されます。
$ tree triton
triton
└── triton_models
└── bert
├── 1
│ └── model.savedmodel
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── config.pbtxt
推論環境の構築
Tanzu Kubernetes Clusterのデプロイ
今回は推論サーバーをKubernetes上でコンテナとして実行するため、vGPUノードで構成されるTanzu Kubernetes Clusterを作成します。vGPUを持つノードプールと持たないノードプールで構成されるクラスターを作成します。vGPUを持つノードプールは仮想マシンクラスとして、NVIDIA A100のGPUメモリー10GBを共有モードとして「時間の共有」(Time Sharing)でvGPUを構成します。
2022年6月現在、MIGで構成されるvGPU環境の利用において、DCGM ExporterはUtilizationに関するメトリックを出力することができない等の制約があります。後述のHPAによるオートスケールを実現するには、Time SharingによるvGPUで構成されるTanzu Kubernetes Clusterを作成する必要があります。
GPU Operatorのインストール
作成したTanzu Kubernetes Cluster上でDCGM Exporterを利用することによりNVIDIA GPUの各種メトリックを取得することが可能になります。こちらのBlog記事で紹介した方法でNVIAEのGPU OperatorをインストールするとDCGM Exporterもインストールされます。
$ helm install gpu-operator nvaie/gpu-operator-2-0 -n gpu-operator
インストールを確認します。gpu-operator-2-0-v1.10.1がインストールされていることが確認できます。
$ helm list -n gpu-operator NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION gpu-operator gpu-operator 1 2022-06-22 13:50:33.30332478 +0900 JST deployed gpu-operator-2-0-v1.10.1 v1.10.1
dcgm-exporterはDaemonSetとしてデプロイされ、vGPUを持つノード上でのみ起動します。
$ kubectl get daemonset -n gpu-operator -l app=nvidia-dcgm-exporter NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE nvidia-dcgm-exporter 4 4 4 4 4 nvidia.com/gpu.deploy.dcgm-exporter=true 26m $ kubectl get pod -n gpu-operator -owide -l app=nvidia-dcgm-exporter NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nvidia-dcgm-exporter-52cqg 1/1 Running 0 25m 172.20.24.103 a100-vgpu-cluster-a100-ts-10g-pool-9fwjz-678dc589fc-j48xx <none> <none> nvidia-dcgm-exporter-hz88n 1/1 Running 0 23m 172.20.25.20 a100-vgpu-cluster-a100-ts-10g-pool-9fwjz-678dc589fc-6d4kz <none> <none> nvidia-dcgm-exporter-q6ms7 1/1 Running 0 23m 172.20.22.161 a100-vgpu-cluster-a100-ts-10g-pool-9fwjz-678dc589fc-xvzth <none> <none> nvidia-dcgm-exporter-qxng9 1/1 Running 0 25m 172.20.26.132 a100-vgpu-cluster-a100-ts-10g-pool-9fwjz-678dc589fc-qvzgs <none> <none>
モデルの配置
Triton Inference ServerをKubernetes上にデプロイする場合、NFS共有にTritonモデルリポジトリを配置し、Triton Inference ServerをDeploymentリソースとして実行します。Deploymentリソースとして定義することにより、KubernetesのHorizontal Pod Autoscaler (HPA)によりレプリカ数を制御し、Triton推論サーバーのオートスケールが可能になります。今回はTritonモデルリポジトリとして利用するNFS共有をvSAN File Serviceによって構成します。
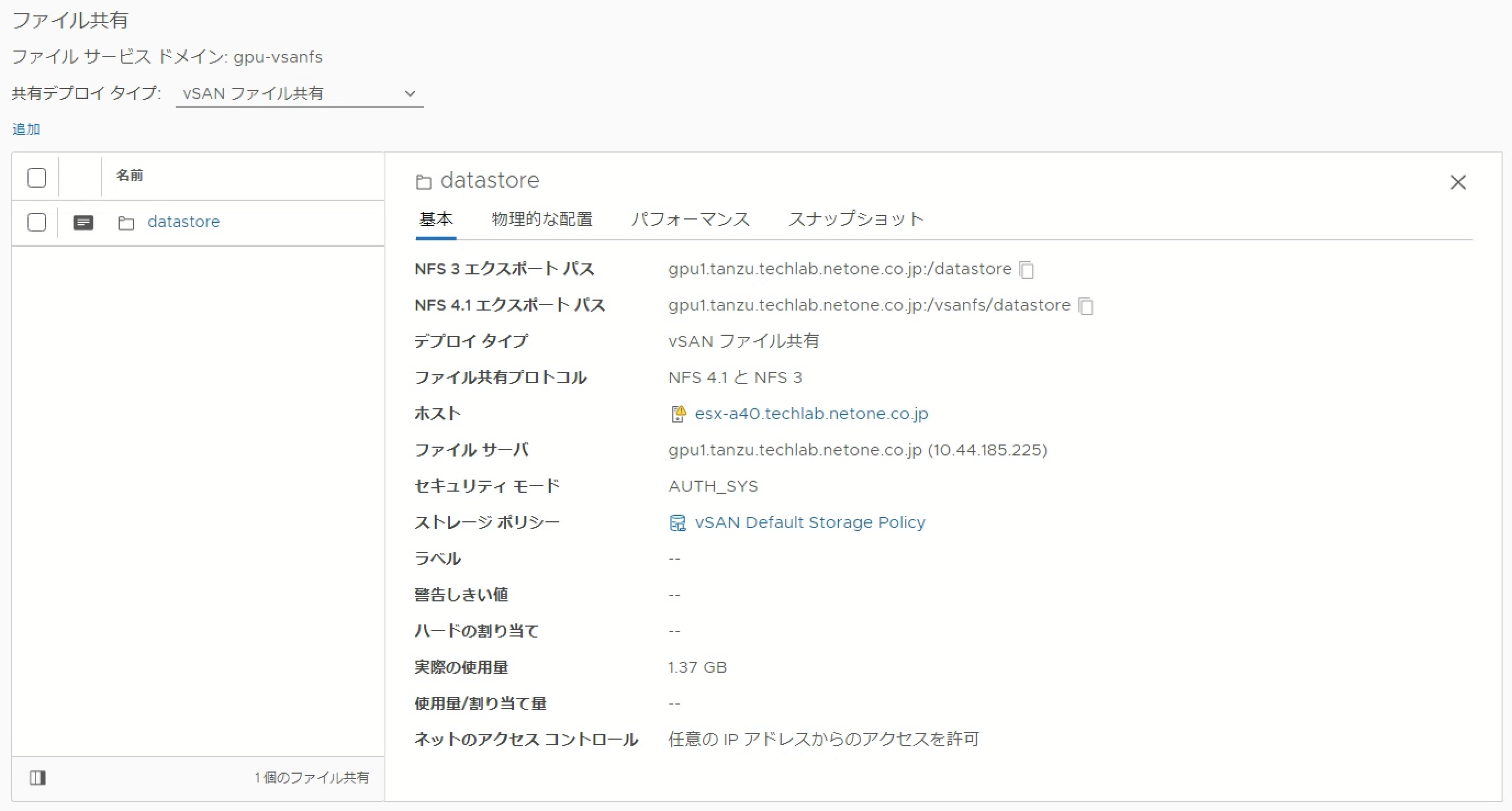
作成したファイル共有を学習環境のVMにマウントし、作成したBERTモデルをコピーします。
$ sudo mkdir /models
$ sudo mount -t nfs gpu1.tanzu.techlab.netone.co.jp:/datastore /models
$ sudo cp -r DeepLearningExamples/TensorFlow/LanguageModeling/BERT/triton/triton_models/bert /models/
$ tree /models
/models
└── bert
├── 1
│ └── model.savedmodel
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── config.pbtxt
4 directories, 4 files
上記ファイル共有をKubernetes上で利用できるよう、PersistentVolumeとPersistent Volume Claimを作成します。
$ kubectl get pv,pvc NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE nfs-pv 500Gi RWX Retain Bound triton-server/nfs-pvc 45s NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE nfs-pvc Bound nfs-pv 500Gi RWX 30s
Triton Inference Serverの起動
Triton Inference Serverを実行するためのDeploymentマニフェストを作成します。Deploymentではモデルを配置したPVCをVolumeとして/modelsにマウントし、Pod内のTriton Inference Serverから参照します。尚、Triton Inference Serverはtritonserver-2-0:22.02-nvaie-2.0-py3としてNGCで公開されているイメージを利用していますが、vSphere with Tanzu環境のレジストリ(Harbor)に再配置し、コンテナイメージのダンロード時間を短縮しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: bert-qa
labels:
app: triton-server
spec:
selector:
matchLabels:
app: triton-server
replicas: 1
template:
metadata:
labels:
app: triton-server
spec:
imagePullSecrets:
- name: nvaie-demo-default-image-pull-secret
volumes:
- name: model-repo
persistentVolumeClaim:
claimName: nfs-pvc
containers:
- name: serving
image: 10.44.187.8/nvaie-demo/tritonserver-2-0:22.02-nvaie-2.0-py3
ports:
- name: grpc
containerPort: 8001
- name: http
containerPort: 8000
- name: metrics
containerPort: 8002
volumeMounts:
- name: model-repo
mountPath: "/models"
resources:
limits:
nvidia.com/gpu: 1
command: ["tritonserver", "--model-store=/models"]
volumes:
- name: model-repo
persistentVolumeClaim:
claimName: nfs-pvc
ClusterIPによりTriton Inference Serverにアクセスできるよう、Serviceリソースを作成します。TCP8000はREST API、TCP8001はgRPC、TCP8002はメトリックを提供します。
apiVersion: v1
kind: Service
metadata:
labels:
app: triton-server
name: bert-qa
spec:
ports:
- name: port-1
port: 8001
protocol: TCP
targetPort: 8001
- name: port-2
port: 8000
protocol: TCP
targetPort: 8000
- name: port-3
port: 8002
protocol: TCP
targetPort: 8002
selector:
app: triton-server
type: LoadBalancer
上記マニフェストによりTriton Inference Serverをデプロイすると、以下のようにPodとServiceが作成されます。
$ kubectl get pod,svc NAME READY STATUS RESTARTS AGE pod/bert-qa-74dbc5fcbc-7zsh9 1/1 Running 0 22s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/bert-qa LoadBalancer 10.96.131.35 10.44.187.5 8001:31971/TCP,8000:32370/TCP,8002:31714/TCP 22s
Podのログを確認すると、PVC上のファインチューニングしたBERTモデルをロードしてTriton Inference Serverが起動していることが確認できます。
I0624 03:58:41.201744 1 server.cc:592] +-------+---------+--------+ | Model | Version | Status | +-------+---------+--------+ | bert | 1 | READY | +-------+---------+--------+ I0624 03:58:41.238073 1 metrics.cc:623] Collecting metrics for GPU 0: GRID A100D-10C
EXTERNAL-IP経由でTriton Inference ServerのREST APIでBERTモデルにアクセスすると応答が確認できます。
$ curl 10.44.187.5:80008000/v2/models/bert/ready HTTP/1.1 200 OK Content-Length: 0 Content-Type: text/plain
以上で、作成したBERTモデルをTriton Inference Serverでホストすることができました。
次回はKubernetes上にデプロイしたTriton Inference ServerをHorizontal Pod Autoscalingによりオートスケールする方法を説明します。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


