

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウド、仮想インフラの管理、自動化、ネットワーク仮想化を担当。
目次
はじめに
「コンテナ環境におけるGPUの活用 vSphere with Tanzu編」ではコンテナを活用した大規模なGPU基盤を構築するソリューションとして、NVIDIA AI EnterpriseとvSphere with Tanzuの組み合わせをご紹介しましたが、2022年3月に公開されたNVIDIA AI Enterprise 2.0でRed Hat OpenShiftのサポートが追加されました。今回のブログではRed Hat OpenShift環境でNVIDIA AI Enterpriseを利用し、コンテナワークロードからGPUを活用する方法をご紹介します。
NVIDIA AI Enterprise
NVIDIA AI Enterpriseは、エンタープライズ環境におけるAI/機械学習を実現するためのインフラ向けのドライバソフトウェア、AI/機械学習に必要となるツールやフレームワークなどのソフトウェア、コンテナ・Kubernetes環境でこれらを活用するためのソフトウェア等のパッケージで構成されています。機械学習環境を作る上で必要となるライブラリやフレームワークをコンテナイメージとしてパッケージ化したものをNGC Catalogで公開しています。NVIDIA AI Enterpriseはこれらのソフトウェアに対するサポートを提供し、Red Hat OpenShift環境での実行をサポートします。
Red Hat OpenShift
Red Hat OpenShiftはRed Hatが提供するエンタープライズ向けKubernetesコンテナプラットフォームです。オープンソースとして開発されたKubernetesをコアとして様々な拡張機能が追加されており、これら全ての機能に対してRed Hatがサポートを提供します。OpenShiftはRed Hat Enterprise Linux CoreOS (RHCOS)と呼ばれるLinuxディストリビューションによりマスター、ノードが構成され、ベアメタル、仮想環境、パブリッククラウド等様々な環境で実行することが可能です。
NVIDIA AI Enterprise / Red Hat OpenShiftの利用方法
ここからは、実際にNVIDIA AI EnterpriseとRed Hat OpenShiftを利用して、コンテナワークロードでGPUを利用する方法をご紹介します。
サポートされるOpenShiftの実行環境
NVIDIA AI Enterpriseは以下の環境で実行されるOpenShiftをサポートします。いずれのOpenShiftもNVIDIA GPU Operatorにより、クラスターにGPU Driver、Container Toolkitをインストールして、クラスター上のワークロードからGPUの利用を可能にします。
- ベアメタル環境
- VMware vSphere環境の仮想マシン - PCIパススルーによりGPUデバイスを仮想マシンに接続
- VMware vSphere環境の仮想マシン - GPU仮想化機能が実現するvGPUを仮想マシンに接続
- パブリッククラウド (NVIDIA AI Enterprise 2.1〜)
今回は、VMware vSphere上の仮想マシンであるOpenShiftノードに、PCIパススルーによりGPUデバイスを接続する方式でNVIDIA AI Enterpriseを利用してみます。仮想マシンでは以下のようにDirectPath I/OデバイスとしてGPUを指定します。

仮想マシンの起動オプション > ファームウェアとして「EFI」を指定し、セキュアブートを無効に設定し、仮想マシンの詳細オプションとして以下のパラメータを追加します。(仮想マシンがパススルーするPCIデバイスのメモリーに適切にアクセスできるよう、use64bitMMIOにより64bitのMemory Mapped I/Oを有効化し、64bitMMIOSizeGBでMMIO領域のサイズを指定します。)
- use64bitMMIO : TRUE
- 64bitMMIOSizeGB : 256 (A100-80GB 1枚の場合)
Node Feature Discovery Operatorのインストール
GPU Operatorをインストールする前にNode Feature Discovery(NFD) Operatorをインストールし、ノードの構成状態をクラスター内で参照できるようにします。NFD OperatorはOpenShift ConsoleのOperatorHubからインストールすることが可能です。OperatorHubにはCommunity版とRed HatがサポートするNFD Operatorが存在しますが、Red HatがサポートするNFD Operatorを利用します。
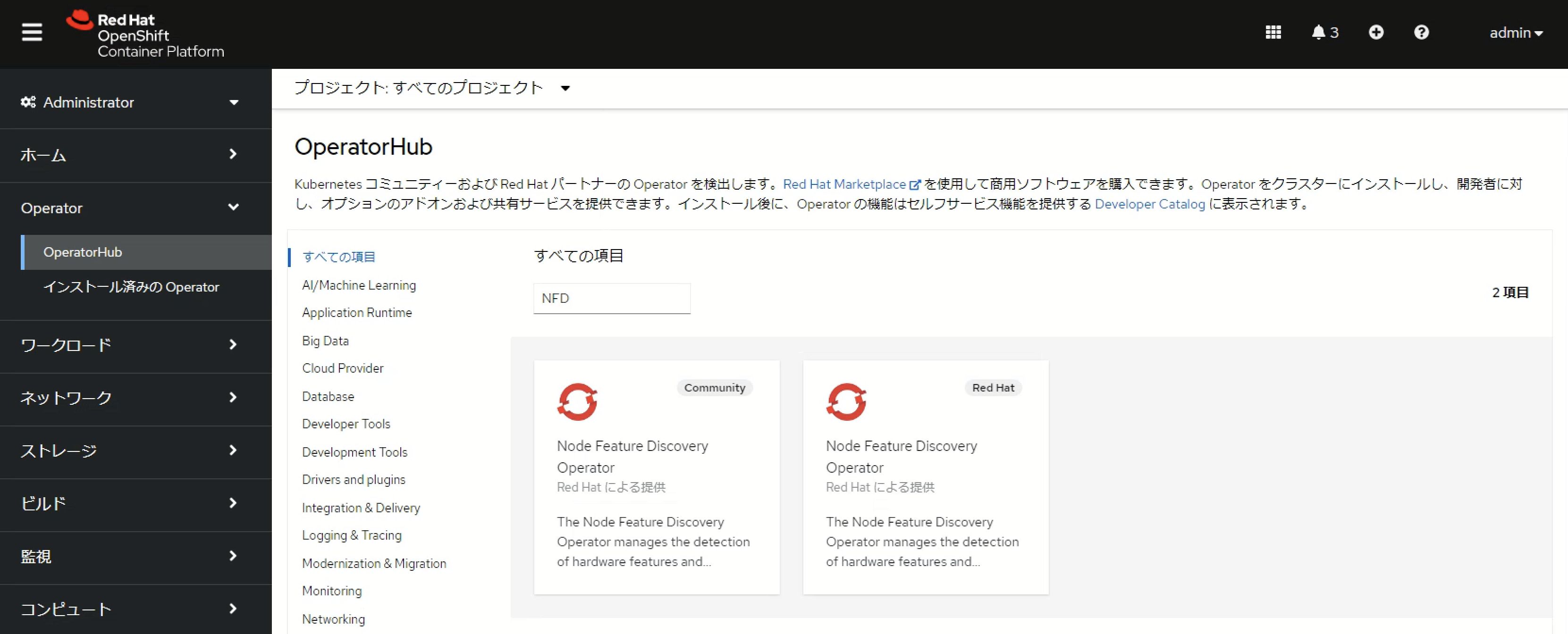
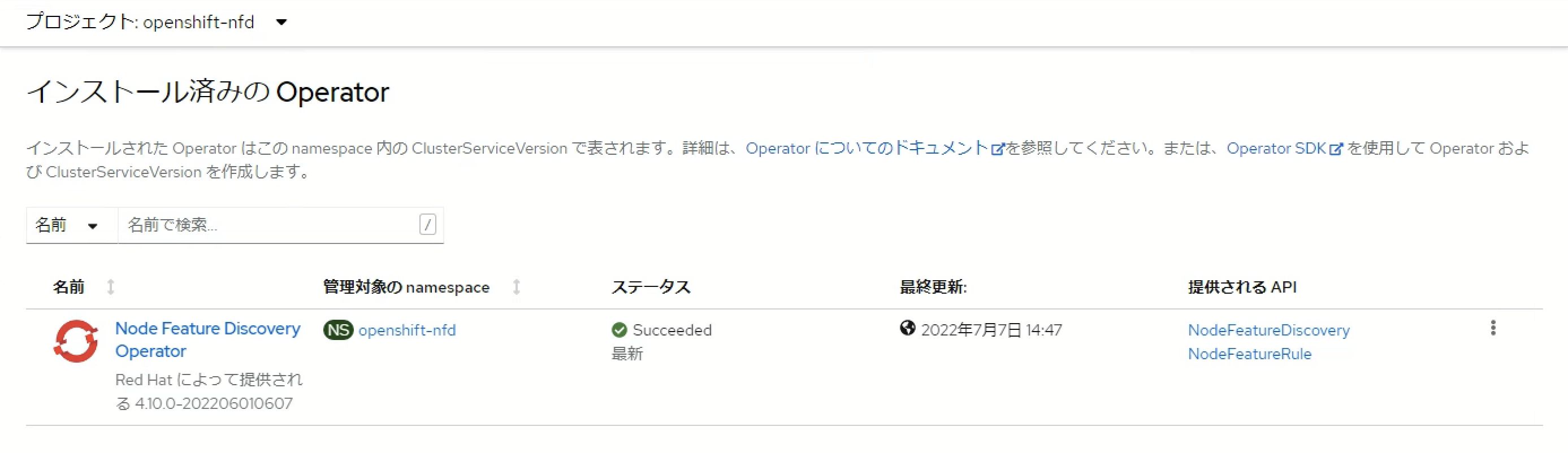
NFD Operatorのインストールが完了した後、「NodeFeatureDiscoveryの作成」をクリックしてNodeFeatureDiscoveryを作成するとクラスター内の各ノード上でNFD podが起動します。
$ oc get pod -n openshift-nfd NAME READY STATUS RESTARTS AGE nfd-controller-manager-5bd96f6f78-sl87r 2/2 Running 0 9m15s nfd-master-56l64 1/1 Running 0 4m12s nfd-master-m244t 1/1 Running 0 4m12s nfd-master-wp9wq 1/1 Running 0 4m12s nfd-worker-kscws 1/1 Running 0 4m12s nfd-worker-n97cz 1/1 Running 0 4m12s nfd-worker-qxn49 1/1 Running 0 4m12s
NFD podはNVIDIA GPUを搭載しているノードを認識し、ノードのラベルとしてfeature.node.kubernetes.io/pci-10de.present=trueを付与します。本環境はnvaie-bfpbb-worker-p225pとnvaie-bfpbb-worker-gzk58のみGPUを搭載しているため、これらのノードにのみラベルが付与されています。(10deはNVIDIA固有のPCI IDです)
$ oc get node -L feature.node.kubernetes.io/pci-10de.present NAME STATUS ROLES AGE VERSION PCI-10DE.PRESENT nvaie-bfpbb-master-0 Ready master 13d v1.23.5+3afdacb nvaie-bfpbb-master-1 Ready master 13d v1.23.5+3afdacb nvaie-bfpbb-master-2 Ready master 13d v1.23.5+3afdacb nvaie-bfpbb-worker-bjblv Ready worker 6d23h v1.23.5+3afdacb nvaie-bfpbb-worker-gzk58 Ready worker 6d22h v1.23.5+3afdacb true nvaie-bfpbb-worker-p225p Ready worker 6d23h v1.23.5+3afdacb true
NVIDIA GPU Operatorのインストール
NFDによりGPU搭載ノードを認識できたら、NVIDIA GPU Operatorをインストールします。GPU OperatorもOperatorHubからインストールすることが可能です。
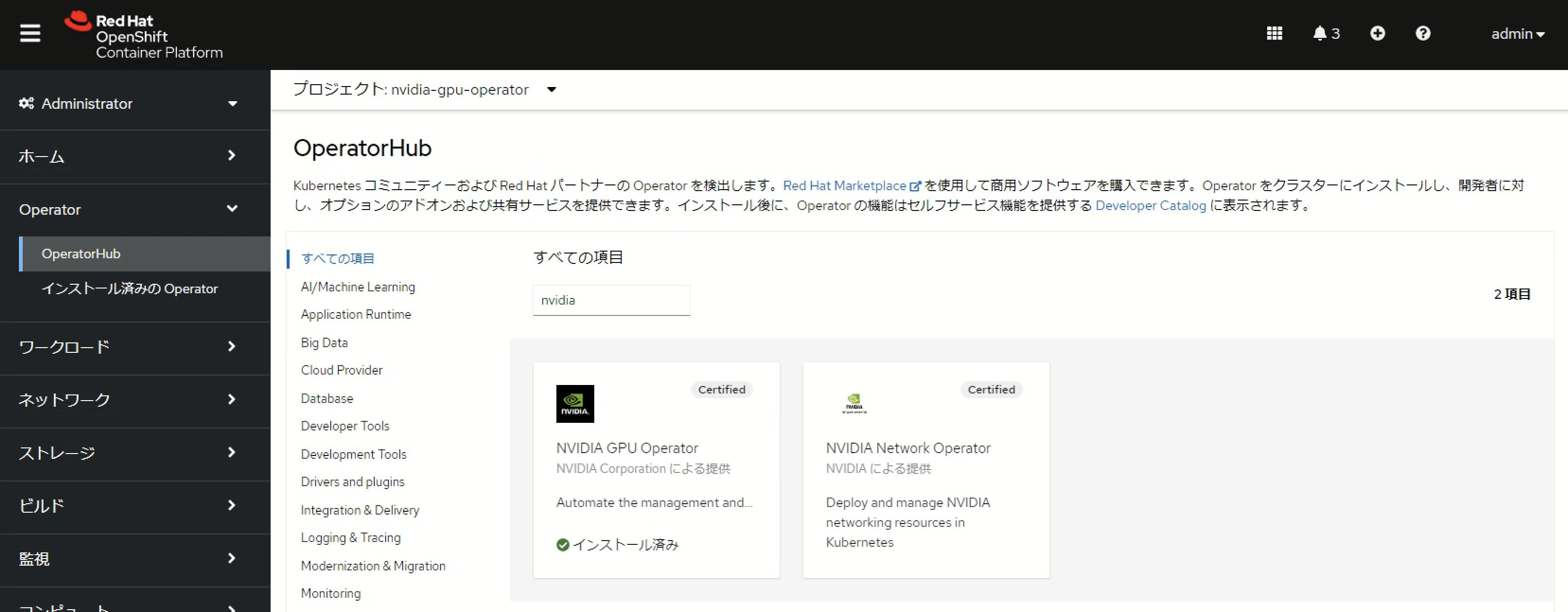
NVDIA GPU Operatorのインストール後、ClusterPolicyを作成します。
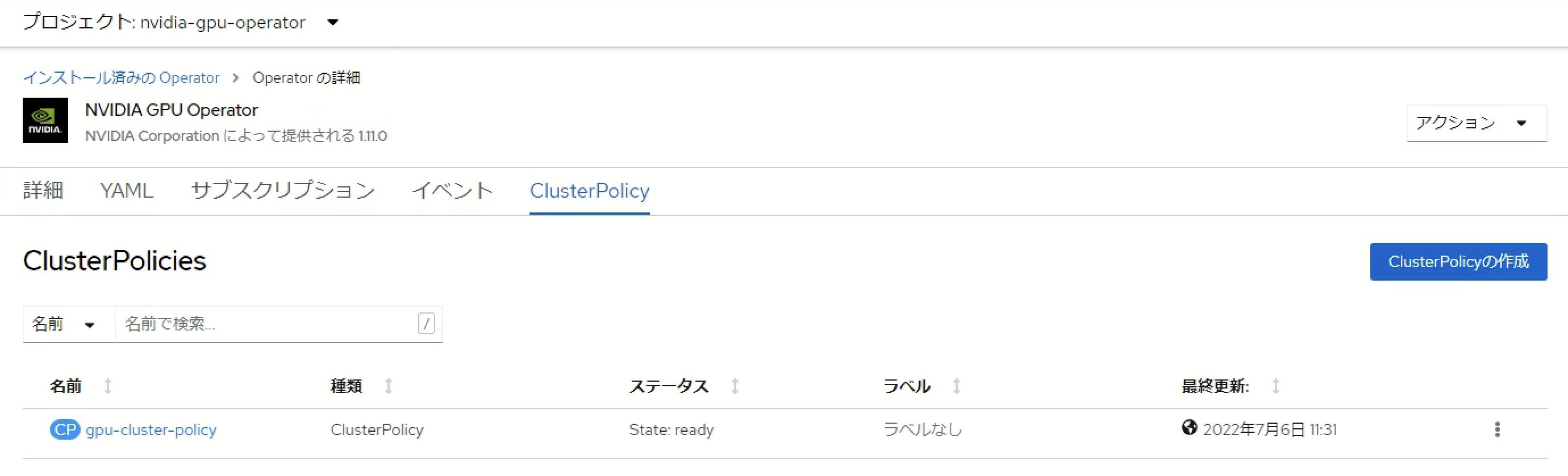
OpenShiftクラスターのGPU利用方法によってClusterPolicyの構成内容が異なります。
- vSphereによりGPUをパススルーする場合 : デフォルトのフォームビューのままClusterPolicyを作成
- NVIDIA vGPUを利用する場合 : ClusterPolicy内でvGPUドライバーを指定し、Delegated License Service (DLS)に関する情報をConfigMapとしてを設定
ClusterPolicyを構成することにより、GPUを搭載したノードでnvidia-driver-daemonset、nvidia-container-toolkit-daemonset等GPUを利用するためのコンポーネントがpodとして起動し、GPU搭載ノードにはnvidia.com/gpu.countラベルが付与され、ラベルの値としてGPU数が構成されます。
$ oc get pod NAME READY STATUS RESTARTS AGE gpu-feature-discovery-pkrgj 1/1 Running 0 85m gpu-feature-discovery-rv7gp 1/1 Running 0 86m gpu-operator-5d8cb7dd5f-qpvcd 1/1 Running 0 5h50m nvidia-container-toolkit-daemonset-rfbj9 1/1 Running 0 85m nvidia-container-toolkit-daemonset-zk6cc 1/1 Running 0 86m nvidia-cuda-validator-jw6md 0/1 Completed 0 83m nvidia-cuda-validator-vcd45 0/1 Completed 0 83m nvidia-dcgm-exporter-m8hxf 1/1 Running 0 86m nvidia-dcgm-exporter-vbp9n 1/1 Running 0 85m nvidia-dcgm-nfqnr 1/1 Running 0 85m nvidia-dcgm-txt7l 1/1 Running 0 86m nvidia-device-plugin-daemonset-27w5p 1/1 Running 0 86m nvidia-device-plugin-daemonset-5bnd8 1/1 Running 0 85m nvidia-device-plugin-validator-8zdn7 0/1 Completed 0 82m nvidia-device-plugin-validator-z5d5b 0/1 Completed 0 83m nvidia-driver-daemonset-410.84.202206080346-0-csbcr 2/2 Running 0 86m nvidia-driver-daemonset-410.84.202206080346-0-jgj4b 2/2 Running 0 86m nvidia-mig-manager-585bk 1/1 Running 0 85m nvidia-mig-manager-9przx 1/1 Running 0 86m nvidia-node-status-exporter-chtc9 1/1 Running 0 86m nvidia-node-status-exporter-hzm59 1/1 Running 0 86m nvidia-operator-validator-slrc6 1/1 Running 0 86m nvidia-operator-validator-z4wss 1/1 Running 0 85m $ oc get node -L nvidia.com/gpu.count NAME STATUS ROLES AGE VERSION GPU.COUNT nvaie-bfpbb-master-0 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-master-1 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-master-2 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-worker-bjblv Ready worker 7d18h v1.23.5+3afdacb nvaie-bfpbb-worker-gzk58 Ready worker 7d18h v1.23.5+3afdacb 1 nvaie-bfpbb-worker-p225p Ready worker 7d18h v1.23.5+3afdacb 1
以下のマニフェストによりDeploymentを作成すると、GPUノード上でPodが起動します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda
labels:
app: cuda
spec:
selector:
matchLabels:
app: cuda
replicas: 1
template:
metadata:
labels:
app: cuda
spec:
containers:
- name: cuda
image: nvcr.io/nvidia/cuda:10.0-base-centos7
resources:
limits:
nvidia.com/gpu: 1
command: ["sleep", "90000000"]
GPUデバイスをパススルー構成としているためPod内でnvidia-smiを実行すると、A100-80GBがすべて割り当てられています。
$ oc get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cuda-c7c9459d-7c56m 1/1 Running 0 42s 10.130.2.103 nvaie-bfpbb-worker-gzk58$ oc exec -it cuda-c7c9459d-7c56m -- nvidia-smi Thu Jul 14 23:03:28 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA A100 80G... On | 00000000:13:00.0 Off | 0 | | N/A 38C P0 46W / 300W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+
GPU Driver Pod内からGPUのMIGを有効化します。
MIG (Multi-Instance GPU)
A100/A30やH100等のMIGに対応したGPUでは、MIGを有効化することにより単一のGPUを複数のインスタンスに分割して並列に実行することが可能です。それぞれのインスタンスに独立したメモリ、キャッシュ、コンピューティングコアが割り当てられるため、各インスタンスのQoSを保証することが可能です。
$ oc get pod -l openshift.driver-toolkit=true NAME READY STATUS RESTARTS AGE nvidia-driver-daemonset-410.84.202206080346-0-csbcr 2/2 Running 0 18h nvidia-driver-daemonset-410.84.202206080346-0-jgj4b 2/2 Running 0 18h $ oc exec -it nvidia-driver-daemonset-410.84.202206080346-0-csbcr -- nvidia-smi -i 0 -mig 1 Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, openshift-driver-toolkit-ctr, k8s-driver-manager (init) Warning: MIG mode is in pending enable state for GPU 00000000:13:00.0:In use by another client 00000000:13:00.0 is currently being used by one or more other processes (e.g. CUDA application or a monitoring application such as another instance of nvidia-smi). Please first kill all processes using the device and retry the command or reboot the system to make MIG mode effective. All done.
GPUノードを再起動するとMIG MがEnabledとなり、MIGが利用可能な状態になります。
$ oc exec -it nvidia-driver-daemonset-410.84.202206080346-0-csbcr -- nvidia-smi Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, openshift-driver-toolkit-ctr, k8s-driver-manager (init) Thu Jul 14 23:24:53 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA A100 80G... On | 00000000:13:00.0 Off | On | | N/A 42C P0 66W / 300W | 0MiB / 81920MiB | N/A Default | | | | Enabled | +-------------------------------+----------------------+----------------------+
GPUのMIGを有効化した後、MIGの分割方法を指定するためのラベルをノードに適用します。今回はA100-80GBを10GBメモリーのインスタンス7個に分割して利用するため、all-1g.10gbを指定します。他のラベルを付与することで分割方法を変更することが可能です。(参考 : MIG Support in OpenShift Container Platform)
$ oc label node/nvaie-bfpbb-worker-gzk58 nvidia.com/mig.config=all-1g.10gb node/nvaie-bfpbb-worker-gzk58 labeled $ oc label node/nvaie-bfpbb-worker-p225p nvidia.com/mig.config=all-1g.10gb node/nvaie-bfpbb-worker-p225p labeled
ラベル付与後、しばらくするとgpu-operatorがnvidia.com/gpu.countを7に修正し、1ノードで7つのGPUの利用が可能になります。
$ oc get node -L nvidia.com/gpu.count NAME STATUS ROLES AGE VERSION GPU.COUNT nvaie-bfpbb-master-0 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-master-1 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-master-2 Ready master 14d v1.23.5+3afdacb nvaie-bfpbb-worker-bjblv Ready worker 7d19h v1.23.5+3afdacb nvaie-bfpbb-worker-gzk58 Ready worker 7d19h v1.23.5+3afdacb 7 nvaie-bfpbb-worker-p225p Ready worker 7d19h v1.23.5+3afdacb 7
まとめ
NVIDIA AI EnterpriseとRed Hat OpenShiftを利用することにより、コンテナを活用したGPU基盤の構築と運用を実現し、GPUリソースの利用効率を向上することが可能です。また、開発者やデータサイエンティストはこのGPU基盤を利用してNGC上で公開されている各種ソフトウェア・コンテナイメージを利用し速やかに開発や機械学習を行うことが可能となります。NVIDIA AI EnterpriseとRed Hat OpenShiftの導入に関しては、是非弊社までお問合せください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


