

- ナレッジセンター
- 匠コラム
ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは - 後編 -
- 匠コラム
- 監視/分析
- ネットワーク
ビジネス推進本部応用技術部
コアネットワークチーム
井上 勝晴
ハディ ザケル
連載テーマの第2弾は「脚光を浴び始めたTelemetry とは」の後編として、ネットワンシステムズが構築した「Telemetry PoC」を紹介したいと思います。
| 連載インデックス |
|---|
Netone Telemetry PoC概要
弊社ネットワンシステムズは、この Telemetry 技術のキャッチアップと、そこで得られるリアルタイムデータの活用を検討すべく、Telemetry PoC を構築しました。弊社の Telemetry PoC の特徴は以下となります。
Point 1:マルチベンダー対応
現在のネットワーク環境はマルチベンダーで構成されることが多いため、複数ベンダー機器から生成されるTelemetryデータを同一の基盤上で収容出来るよう、マルチベンダー対応型 Telemetry PoC を構築しています。
Point 2:Micro Service 化
ネットワーク機器数や収集するTelemetryデータ量により、必要とされるCollectorの容量は異なるため、scaleアップ・ダウンが容易な作りとすべく、Collectorの各コンポーネントはコンテナにて構築し、Micro Service化を実現しています。
Point 3:Machine Learning
収集したTelemetryデータに機械学習を掛け、ネットワークの異常性を検知する仕組みを設けています。
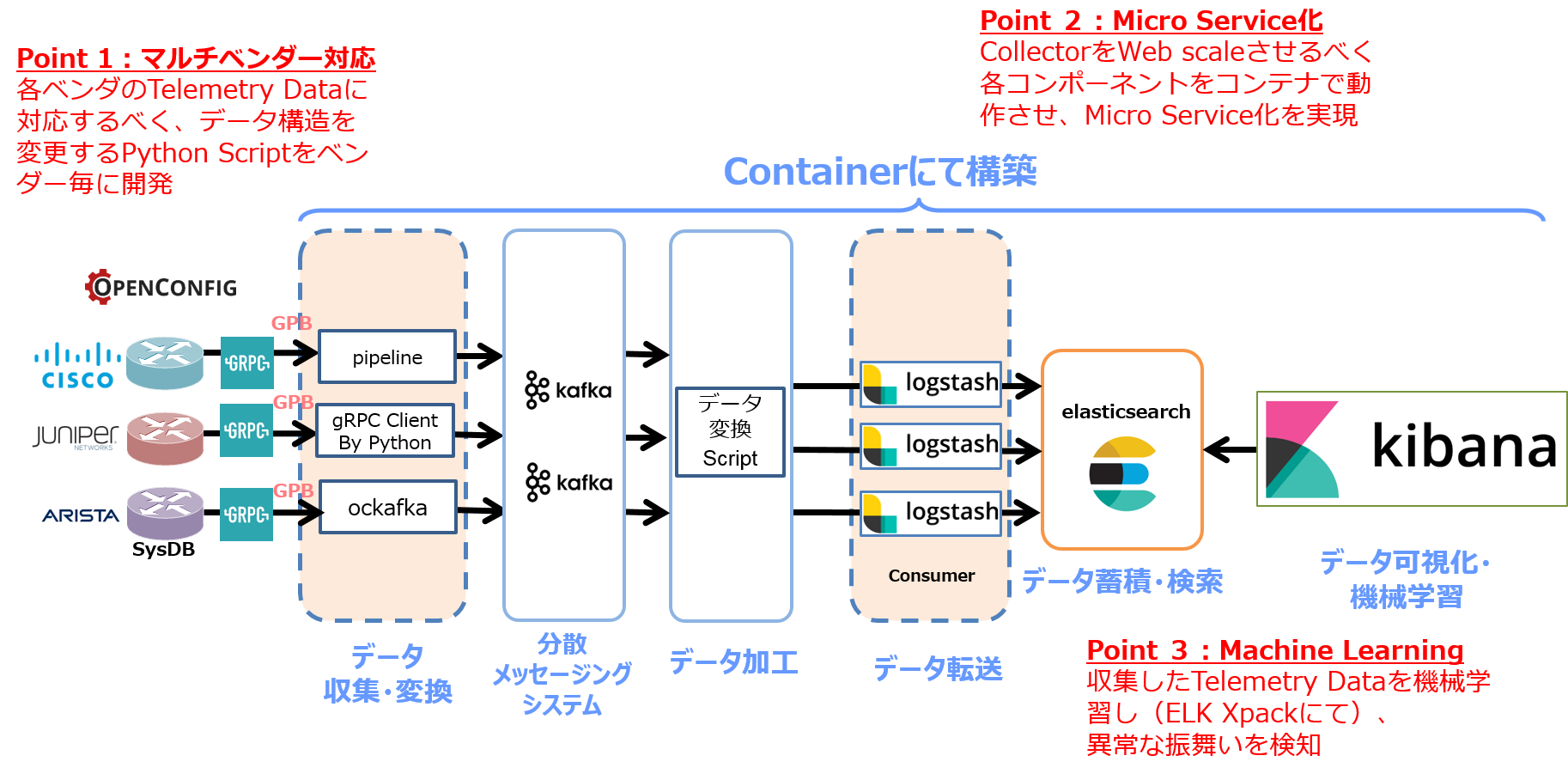
この様な Telemetry Collector により、将来的には、機器より収集したリアルタイムデータを分析し、その分析結果を基にして Work Flow エンジンがネットワークの最適化作業(コンフィグ変更等)を自動的に行う、と言ったサイクルを構築したいと考えています。
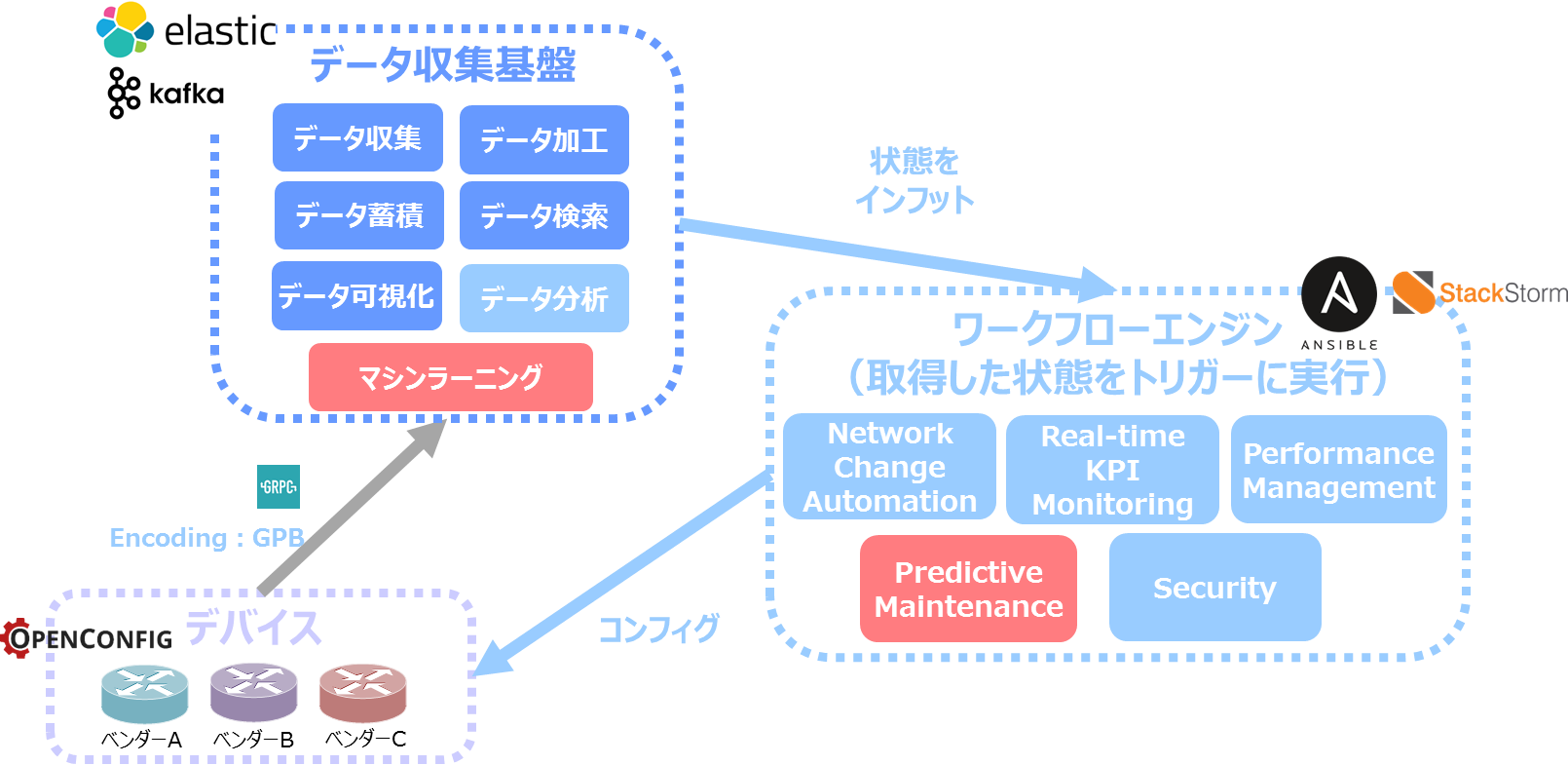
Netone Telemetry PoC 構成要素
それでは、弊社 Telemetry PoC の構成要素を簡単に説明したいと思います。
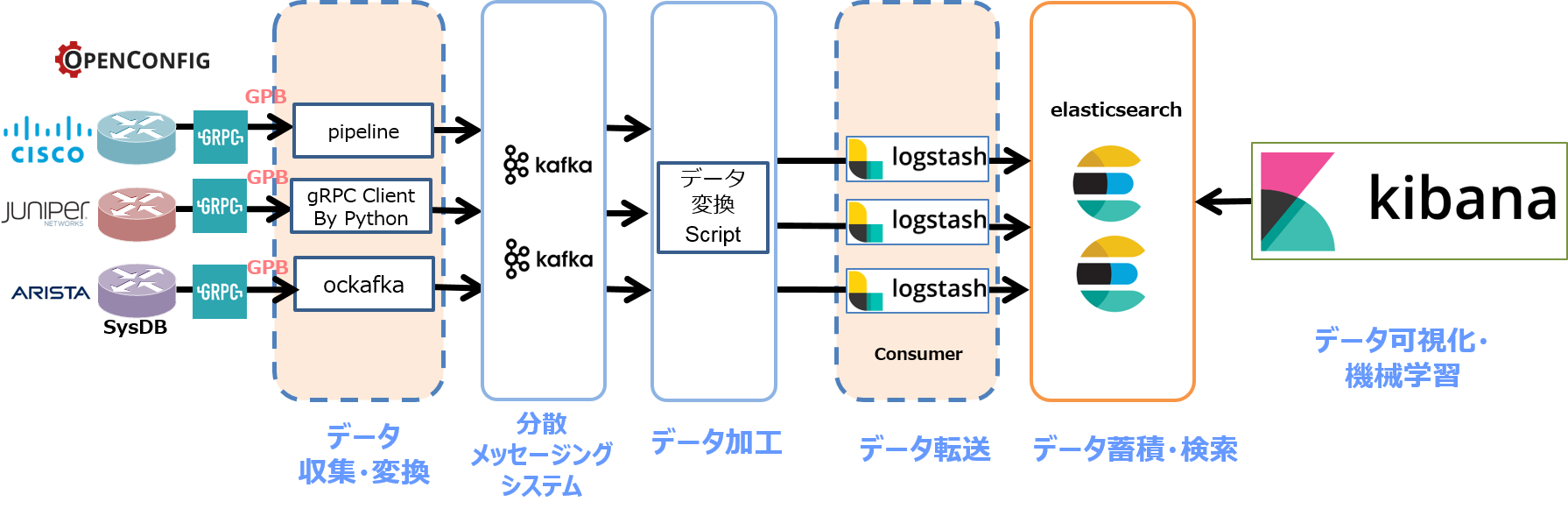
Router
Telemetry データを生成し、指定した Collector へ送信します。
一般的には、機器側でデータモデリング(OpenConfig や Native)、コーディング(GPB や JSON)、Transport(gRPC や TCP/UDP)を其々指定する事が出来ます。
Collector
機器からの Telemetry データを受ける Frontend コンポーネントに相当し、gRPC の終端、GPB デシリアライズとデータの構造化(JSON 化)、外部コンポーネントへの送信等を担います。
弊社 Telemetry PoC では、各ネットワーク機器ベンダーが公開/提供する Collector ツールを利用しています。
Note: Collector tools
goarista(arista機器向け) – リンク
bigmuddy-network-telemetry-pipeline(Cisco機器向け) – リンク
gRPC client by python(Juniper機器向け) – Juniper 社より提供
メッセージングシステム
Collector から送信されるリアルタイム構造データを一時的に受け、外部コンポーネントへと展開します。
弊社 PoC では Kafka を使用しています。
データ加工 Script
Elastic stack にて正確に可視化する為に必要であった、基データへの加工処理を行うコンポーネントとなります。(後述)
データ転送/蓄積・検索/可視化/機械学習
メッセージングシステムに展開されたTelemetryデータを取得・蓄積し、可視化及び機械学習を実行します。
弊社 PoC では、Elastic Stack (Logstash、Elasticsearch、Kibana)を使用しています。
PoC 構築時に気付いた事(データを変換する技術の必要性)
実際に各ネットワーク機器から Telemetry データを取得して気づいた事でありますが、各 Router が送信する Telemetry データは、そのままでは Kibana で取り扱う事が出来ないデータ型となっている事があり、その為適時データ型の変更作業が必要でした。
以下は本 Telemetry PoC で必要となったデータ変換例になります。
- Kibana でデータとして取り扱うことが出来ない「Array Object 型」への処置
- 1つのメッセージに複数 JSON が内包されるケースへの処置
- key 上の変数に対する処置
- Kibana でデータとして認識するよう、Telemetry data の JSON 形式化
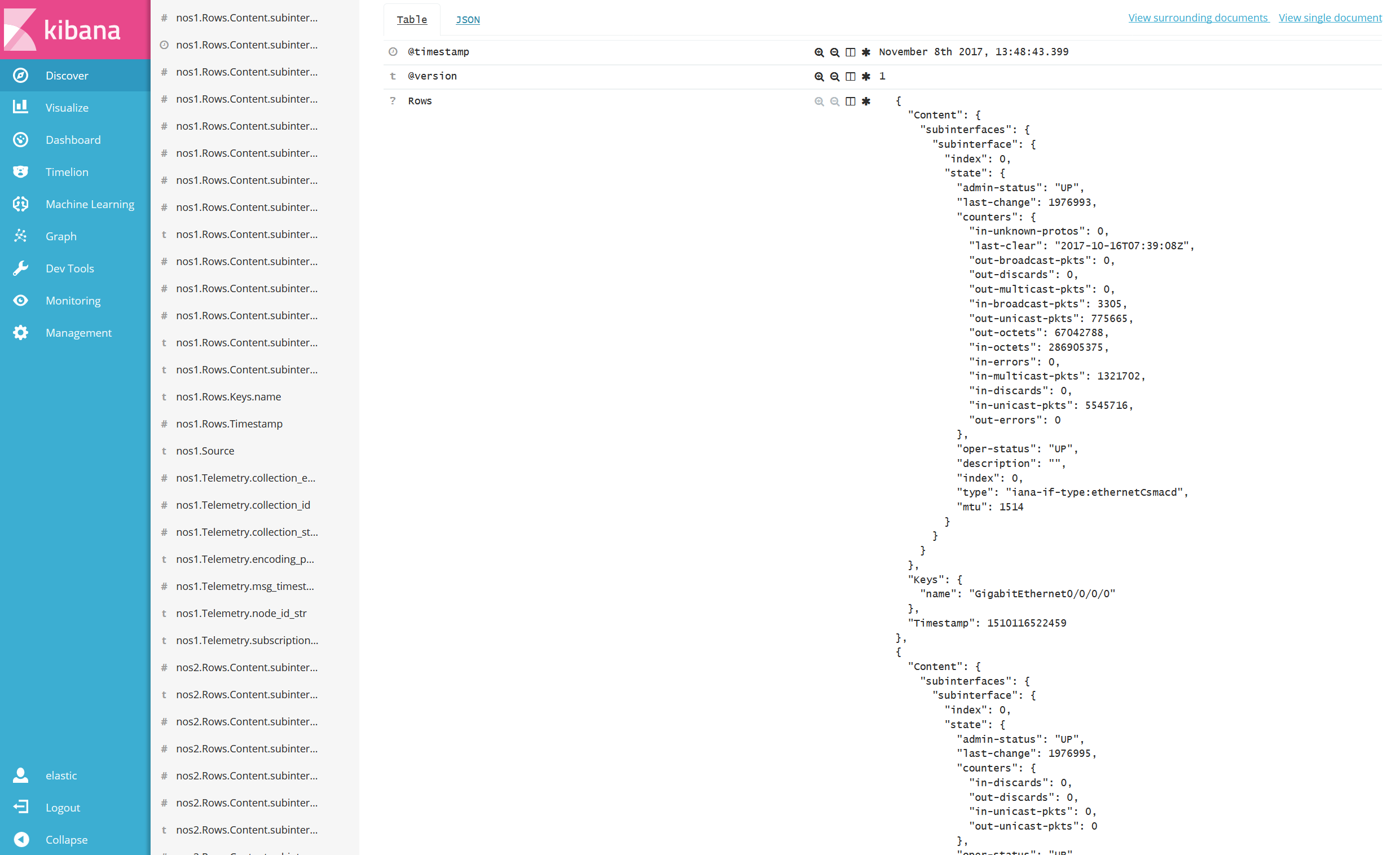
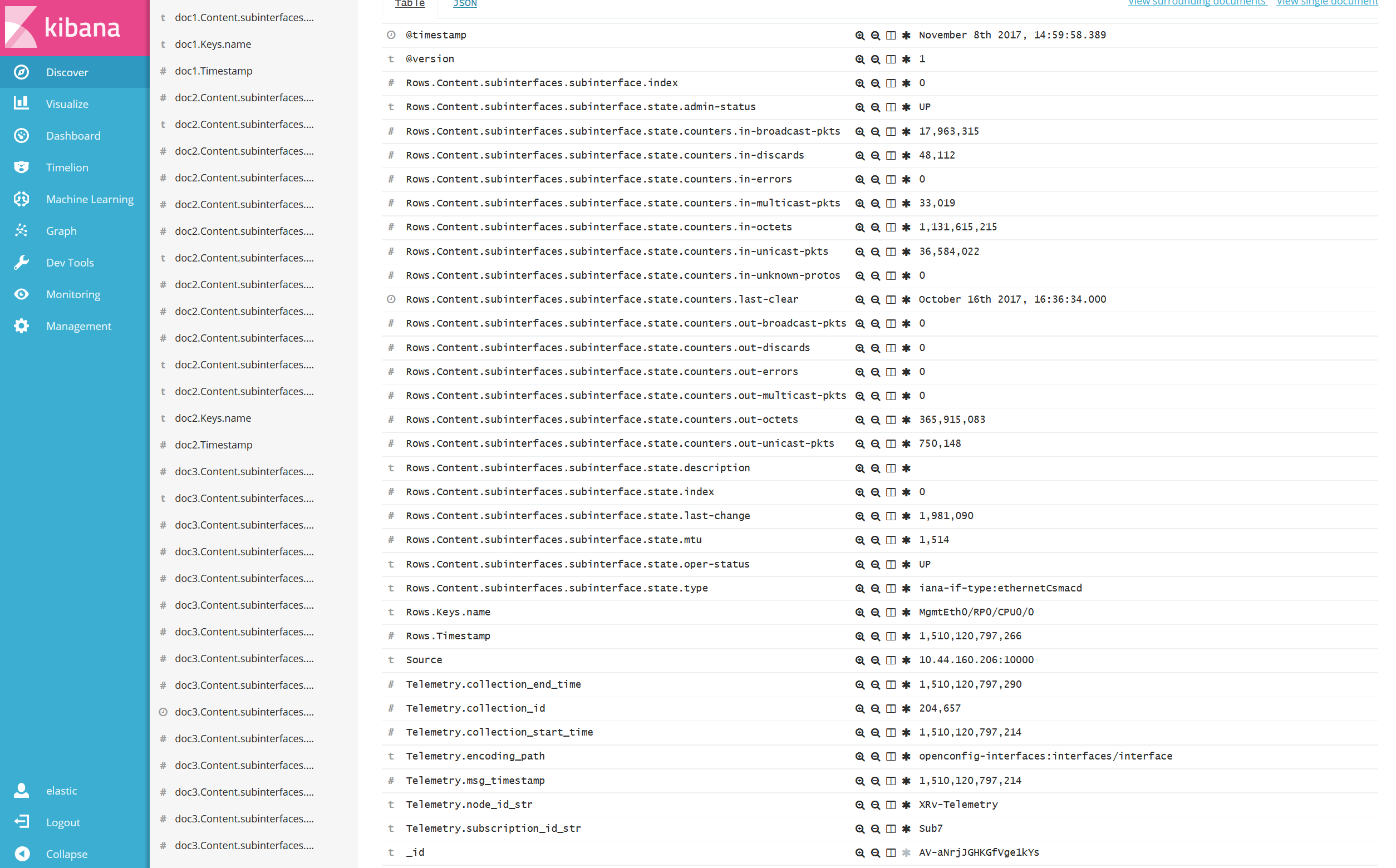
Array Object 型
一部の Collector から送信される Telemetry データは、以下のように1つの Key に対し複数の Value が存在するケースがありました。(図はクリックして拡大できます。)

この例では Rows 以降のデータが Array 型となっており(黄色ハイライト部分)、この様なデータ型に対しては、Elastic stack にて可視化を行ったとしてもデータとして取り扱う事が出来ません。
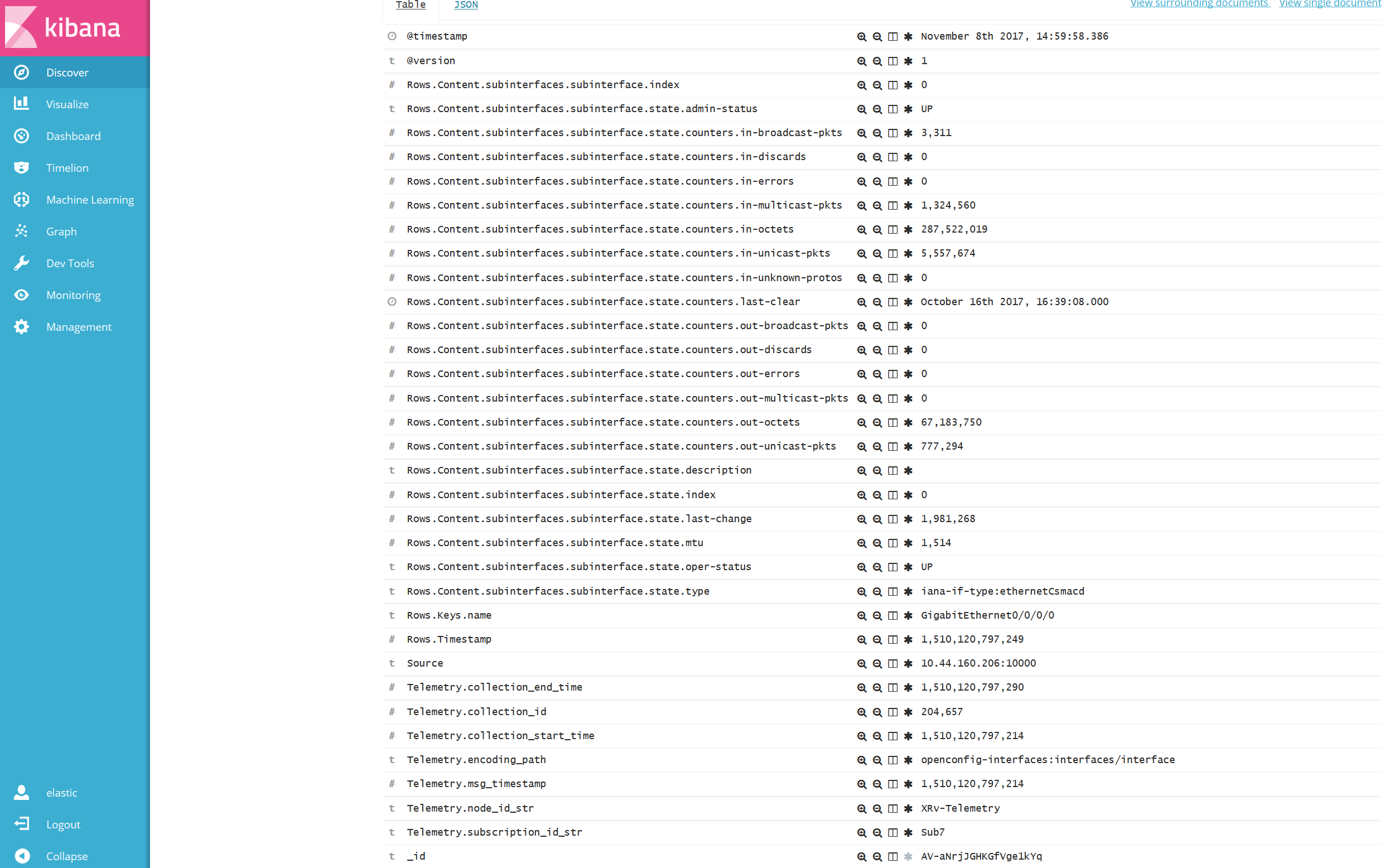
実際に Kibana で可視化した結果を見るとイメージが付きやすいのですが、以下の様に、Rows の Key に複数の Value が含まれています。(図はクリックして拡大できます。)
1つのメッセージに複数 JSON が内包
このケースでは、以下のように1つのメッセージの中に複数の JSON が存在し、それら JSON が[]で括られています。(図はクリックして拡大できます。)

この様なデータ型に対しては、LogstashのJSON Filterが正常に動作する事が出来ません。(JSON parse failure)
データ変換方法論1:Logstash Filter にて
この様なデータ型への対応として、Logstash が機能として持つ各種Filterを駆使して基データを変更する方法があります。
具体的には、grok filter や json filter を用いてデータを加工していく事になります。この Logstash Filter の作成作業は試行錯誤(Try and Error)ではありましたが、① Array 型への対処、②複数 JSON への対処、が其々成功しています。(図はクリックして拡大できます。)

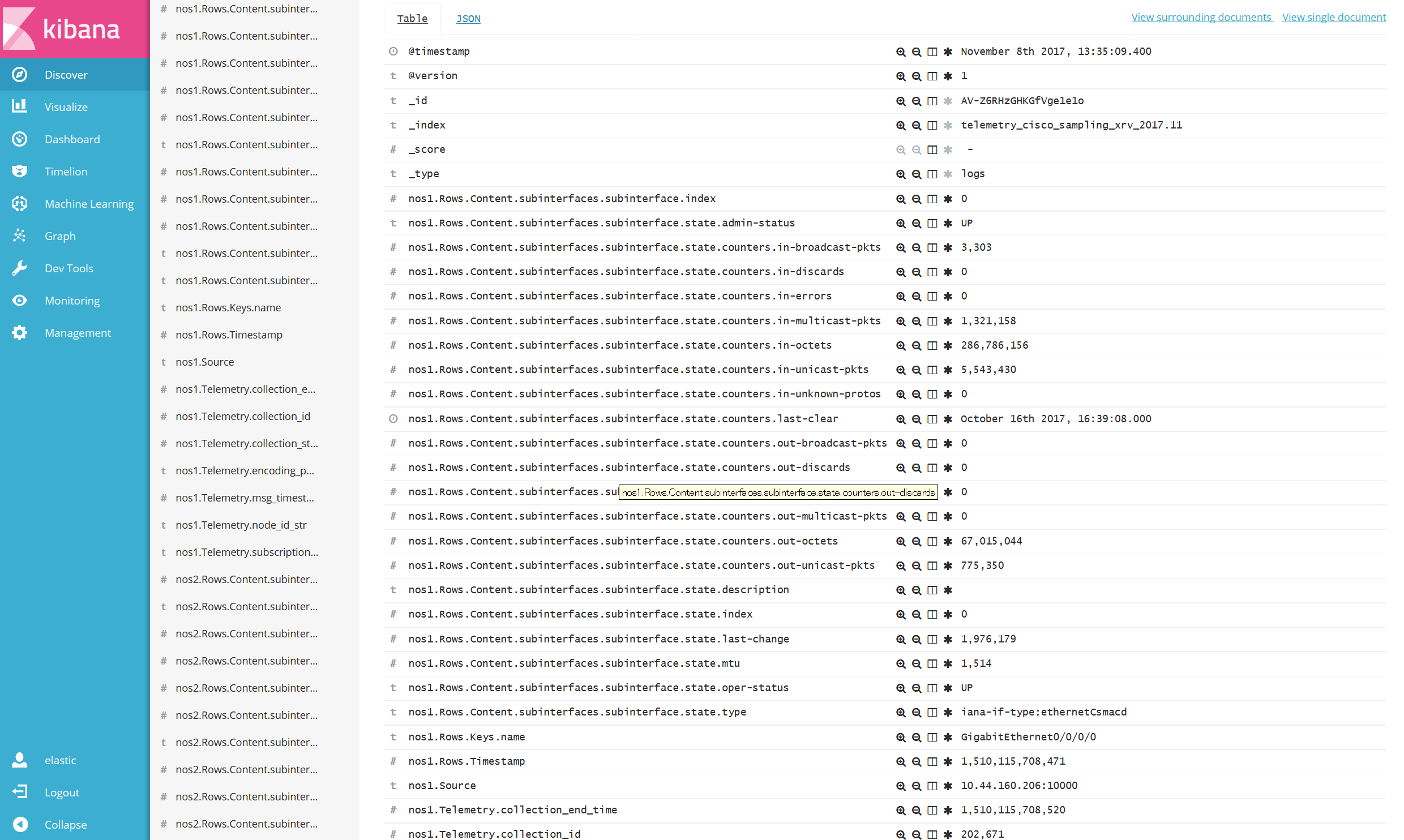
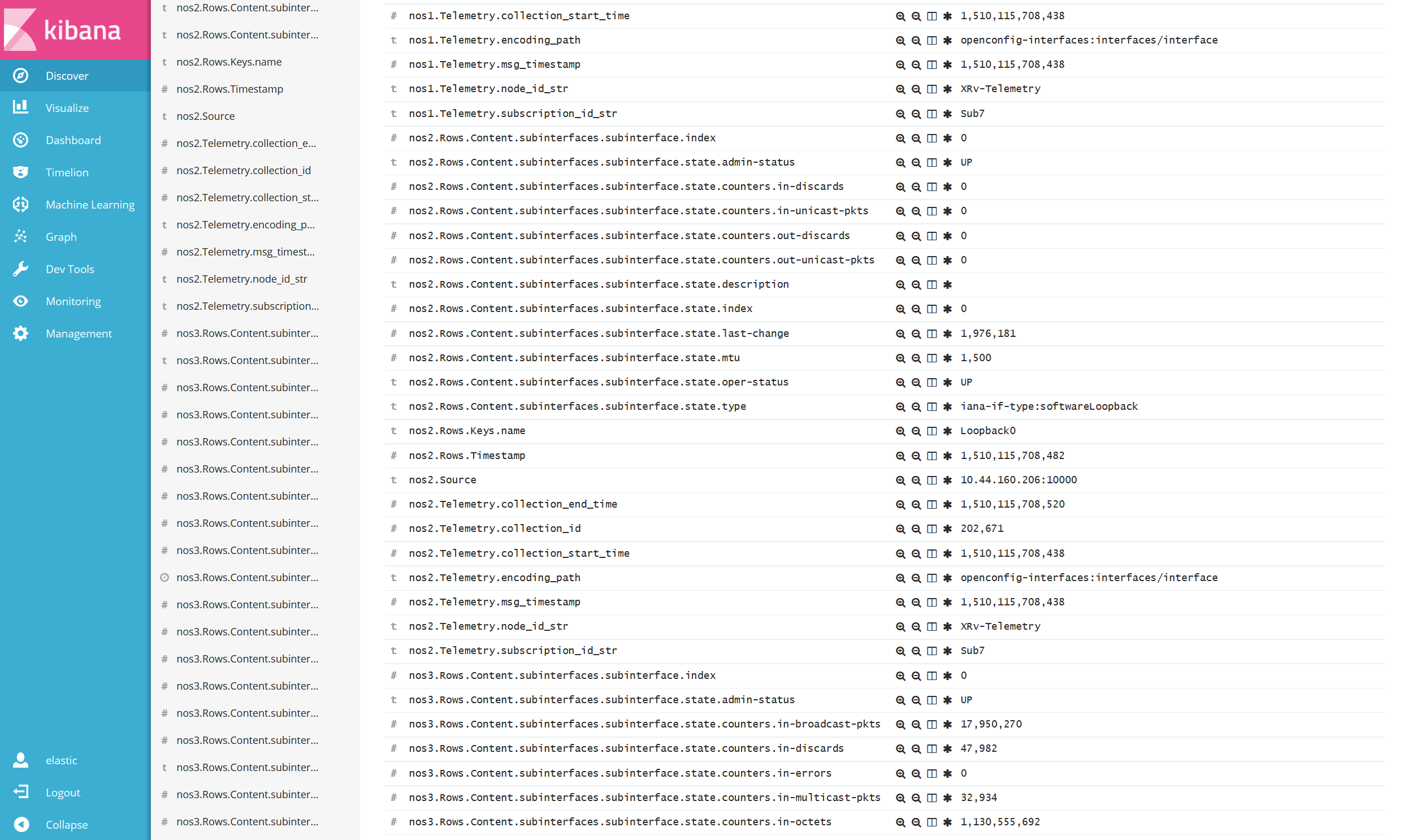
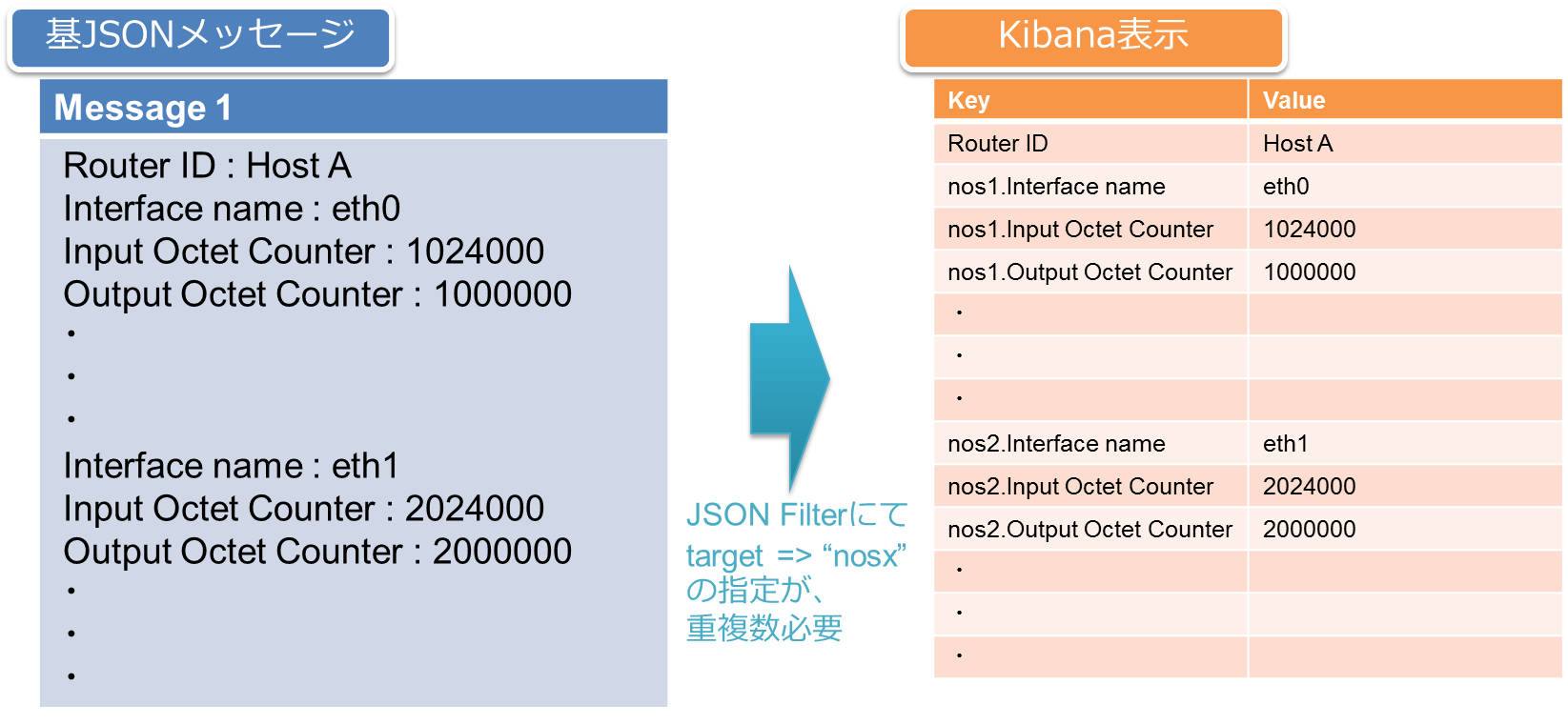
しかしながら、Logstash Filter を用いたデータ変換には課題もありました。上図を見て解るように、基データに複数の同一要素(Key)が存在していたため、各 Key の先頭に識別子(nos1, nos2, nos3)を追加する必要がありました。
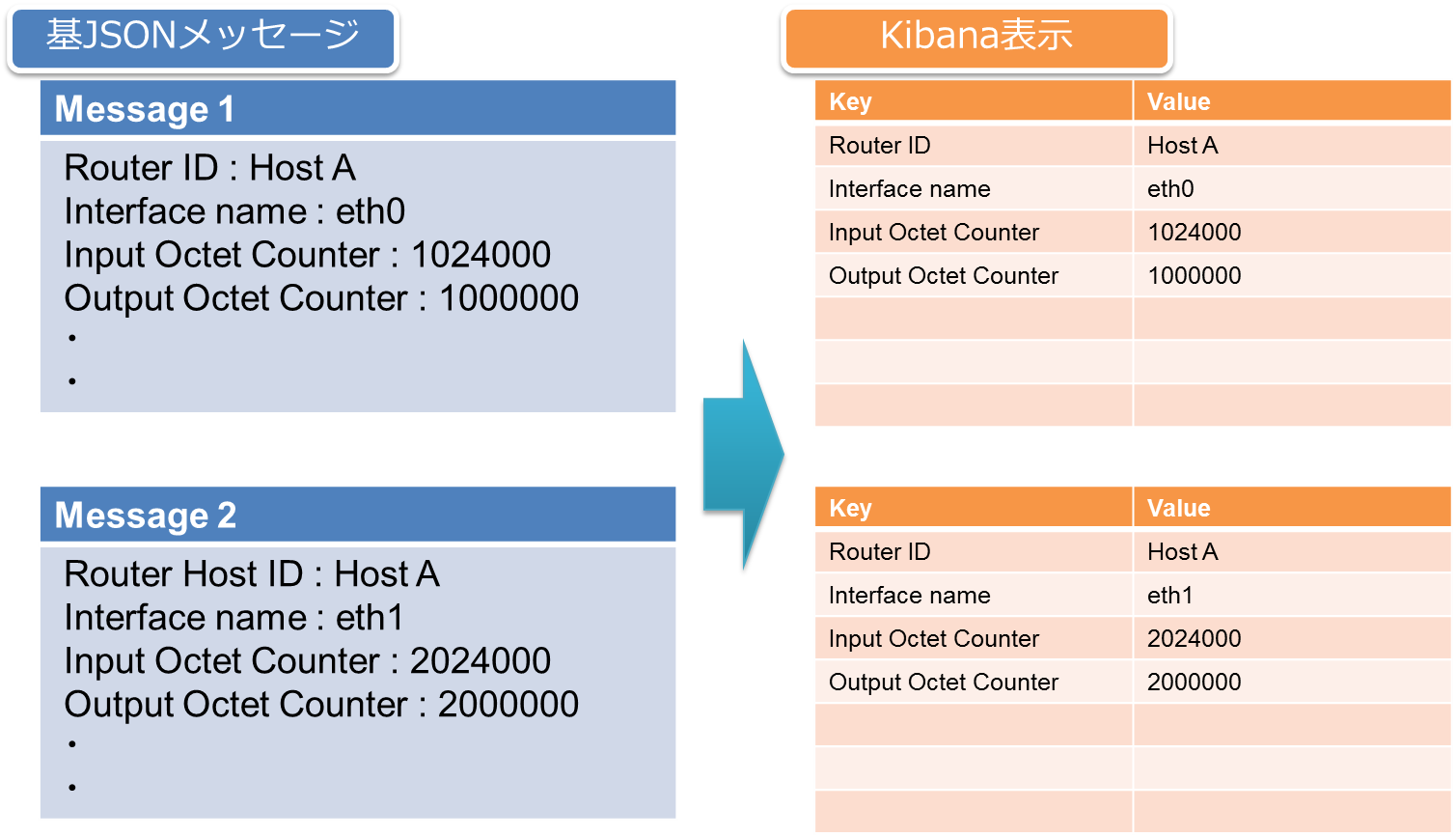
本来1つのデータ、例えば Router A の Interface eth0 の Octet カウンターを参照したい時、「Router ID」と「Interface name」と「Input Octet Counter」を識別子として該当データメッセージを検索する事がシンプルな方法です。この方法論は、1つのメッセージ内に「Interface name」等の識別子が重複しない前提の基で動作します。(図6)
しかし前述の例では、1つのメッセージ内に複数の「Interface name」や「Input Octet Counter」等が同じ Key として存在していました。(図7)(故に、Logstash Filter にて各 Key の先頭に識別子を入れる必要がありました。)その為、同様に Router A の Interface eth0 の Input Octet を参照する際に、①eth0 がどの nosx.interface_name として存在するかを確認し、②nosx.input_octet_counter を参照する、のような煩雑な作業となってしまいます。
データ変換方法論2:Python Script による一括変換
これまで説明したように、Logstash Filter を活用したデータ変換は、受け取る Telemetry データ次第では上手く動作する事もありますが、一方で課題も存在します。その為、弊社の Telemetry PoC では、Python Script を用いた一括データ変換の手法を採用しています。Kafka に展開された基データを Consume(取得)して必要なデータ変換を実施し、別 Index で Produce(格納)する Python Script を作成しました。この方法論にて、可視化に際して必要となった全データ加工作業を実施しています。
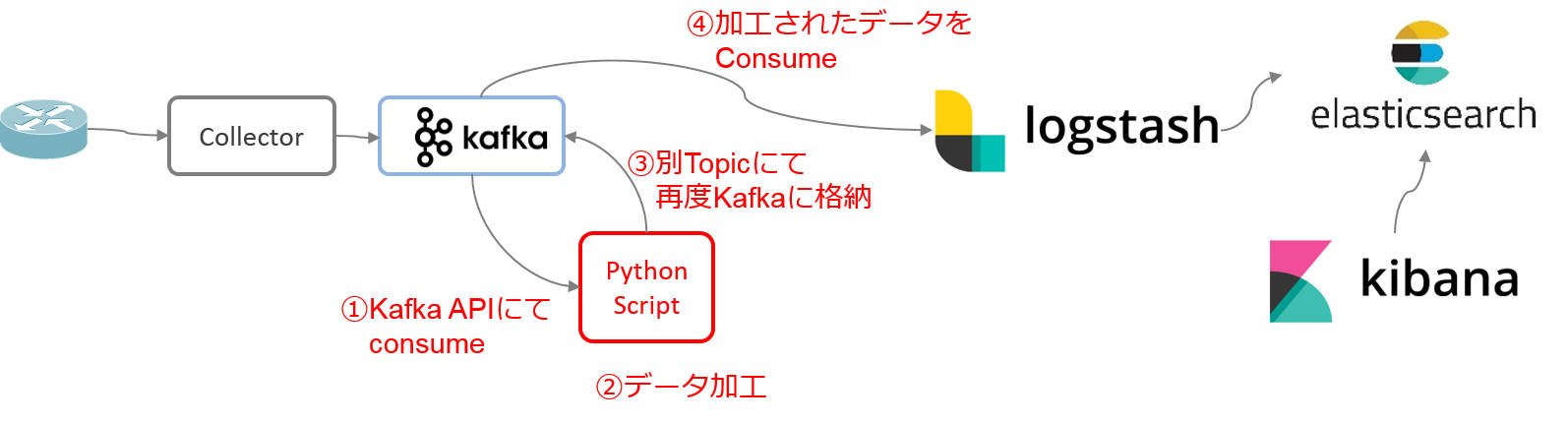


先に紹介した Array 型や複数 JSON への対処の他にも、使用する Collector に応じて上記の様なデータ変換を実施しています。この様な対処により、以下のような理想的な可視化が達成出来ています。
成果・効果のご紹介
それでは、弊社 PoC で実施した「リアルタイム可視化」と「分析」について、紹介したいと思います。
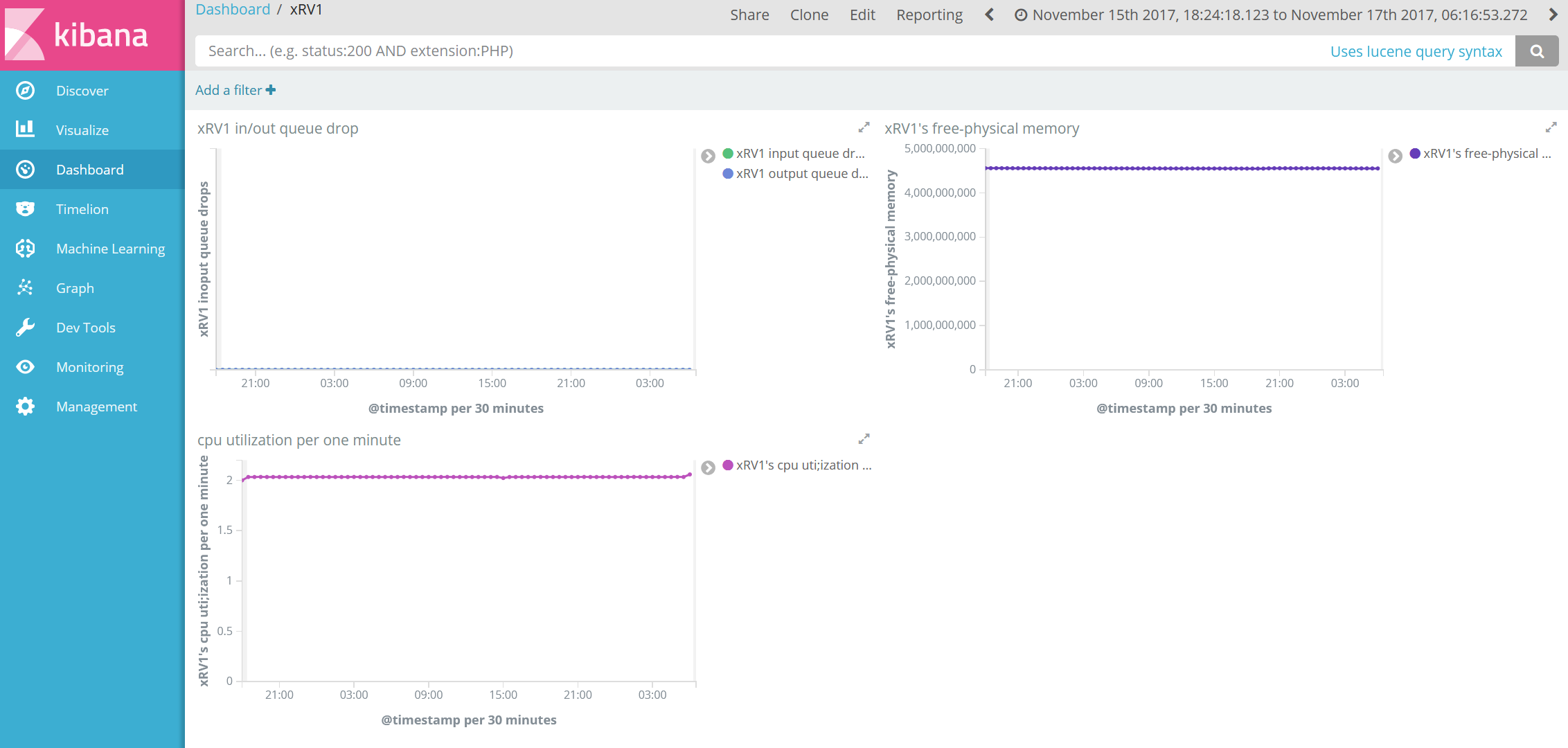
リアルタイム可視化:Interface 使用帯域
Telemetry で取得する Interface Counter(Input / Output octets)データを基に、Kibana Timelion 上で帯域計算を実行してグラフ作成し、各 Interface の帯域を可視化しています。
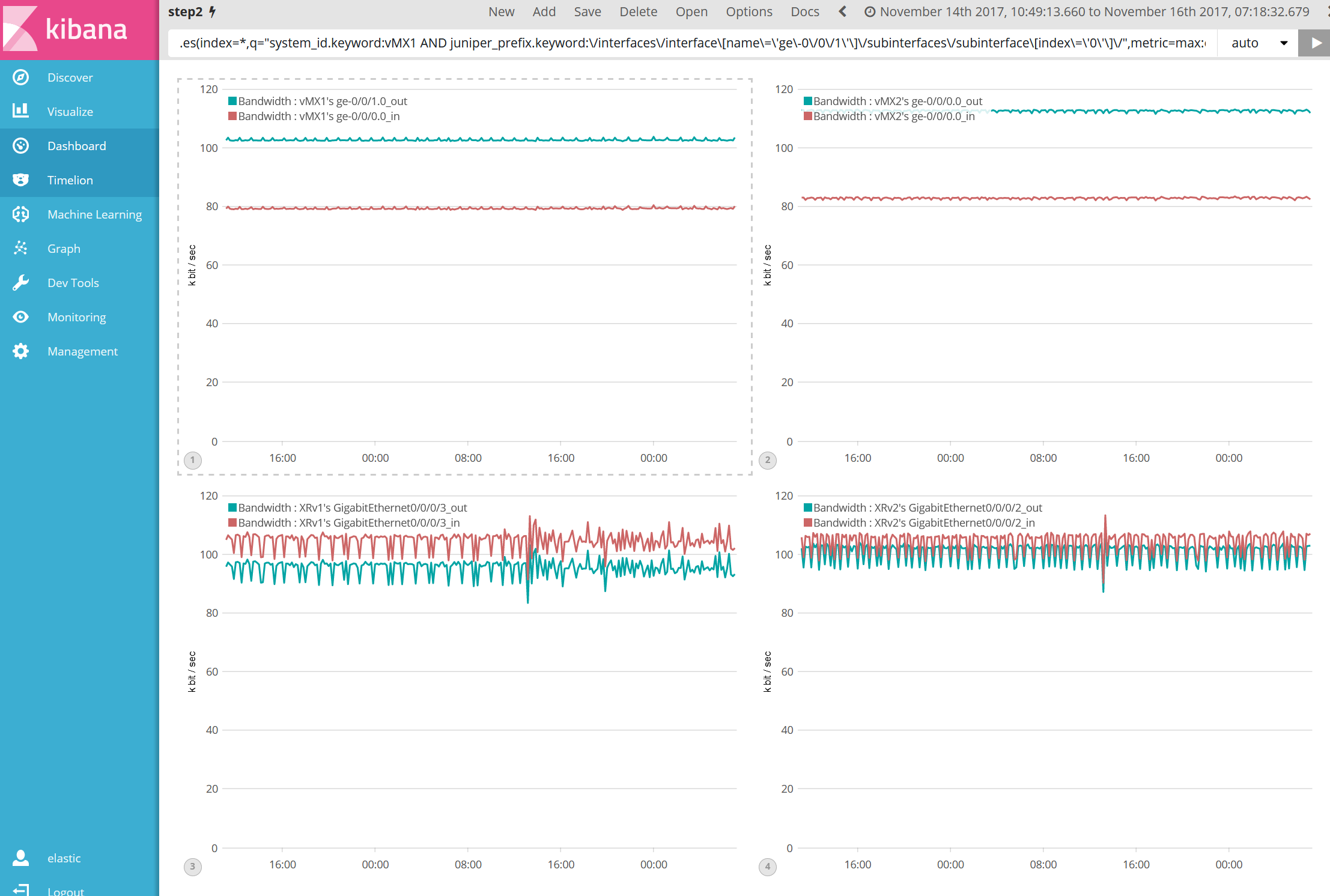
また、Telemetry データ取得の頻度を数秒から数十秒とする事で、Burst traffic をより正確に検知する事が出来ています。(前回コラム)
リアルタイム可視化:その他カウンター
CPU 使用率やメモリ使用率、Interface Queue drop カウンター等、Telemetry データで取得した値は可視化する事が出来ています。
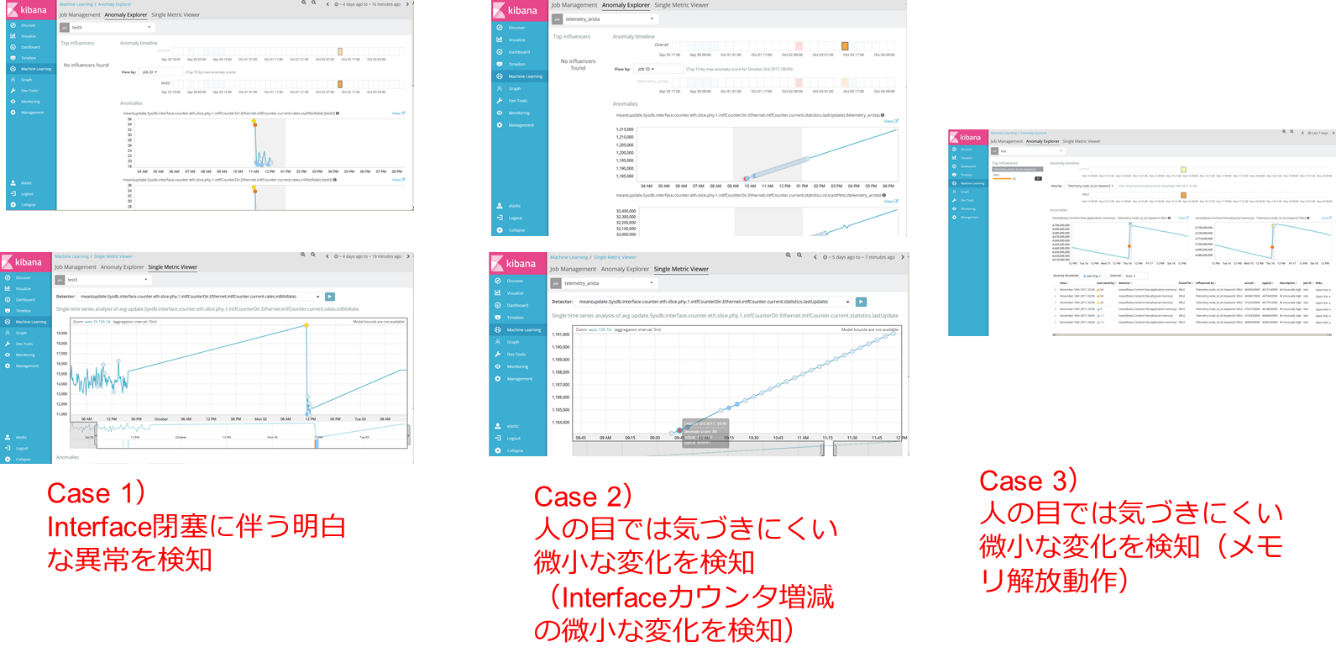
分析:機械学習
Interface カウンター等を Machine Learning に掛け、結果、幾つかのケースにて異常性/特異性の検知に成功しています。
まとめ
本コラムでは、Telemetry 技術の実体解説と弊社ネットワンシステムが構築した Telemetry PoC を紹介させて頂きました。この Telemetry 技術により、ネットワークインフラに対し、これまで把握が難しかった側面を抽出し、様々な角度よりそれらを可視化する事が可能である事が解りました。また、機械学習と連携する事により、人間の目では気付き難い微小な変化を捉える事も可能である事も解りました。今後はより一般的な要素(CPU・メモリ使用率、温度、FAN 回転速度、Buffer 値、等)も Machine Learning に掛けて異常性との相関を抽出し、必要な Action を Workflow エンジンに展開し、ネットワークの自動最適化に繋げられるような取り組みを行う予定です。
弊社の今後の取り組みにもご期待下さい。
関連記事
- ネットワン NFV の全貌と市場への挑戦①
- ネットワン NFV の全貌と市場への挑戦②
- ネットワン NFV の全貌と市場への挑戦③
- NFV動向: NFVとOpenStack①
- NFV動向: NFVとOpenStack②
- NFV動向: NFVとOpenStack③
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 - 前編 –
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 - 後編 –
- ネットワークが創生する価値 再考①:Hyper Scale DC Architectureとその手法
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 前編 –
執筆者プロフィール
井上 勝晴
ネットワンシステムズ株式会社 ビジネス推進本部 応用技術部 コアネットワークチーム所属
エンタープライズ・サービスプロバイダのネットワーク提案・導入を支援する業務に、10年以上にわたり従事
現在はSDN・クラウドのエンジニアになるべく格闘中
- MCPC1級
ハディ ザケル
ネットワンシステムズ株式会社 ビジネス推進本部 応用技術部 コアネットワークチーム所属
主にハイエンドルータ製品の担当として、評価・検証および様々な案件サポートに従事
現在は、SP-SDN分野、コントローラ関連、標準化動向について調査及び連携検証を実施中
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索