
生成AIの話題が増える中で、インフラエンジニアとしては「AI基盤のネットワークが実際にどうなっているのか」が気になるところです。
GPUやモデルの話はよく見かけますが、実際のAIインフラでは多数のGPUがネットワークを介して連携しながら処理を進めています。そのため、GPU間通信を支えるバックエンドネットワークが性能やスケーラビリティにかなり大きく影響します。
しかも、この世界で求められるネットワークの条件は従来のデータセンターネットワークよりもずっとシビアです。ロスを避けること、輻輳をうまく制御すること、そして複数経路を効率的に使うこと。どれもAIインフラではかなり重要になります。
今回は、その中でも経路分散の仕組みとしてよく出てくる Dynamic Load Balancing(DLB) を取り上げます。
また、実際のスイッチで シングルフローが本当に分散するのか を試してみたのでその結果も簡単に紹介します。

- ライター:菊池 裕次
- ネットワンシステムズに中途入社後、通信キャリア案件を中心にフロントSEとして設計・構築に従事。現在はデータセンターネットワーク、キャンパスネットワーク、光伝送など幅広い分野での製品評価や技術検証に携わる。
目次
AIネットワークでは、まずパケットを落とさないことが重要になる
AIインフラでは、多数のGPUがネットワークを介して連携しながら処理を進めます。
このときGPU同士は同期を取りながら動くため、一部の通信でパケットロスや再送が発生すると、その遅れが全体の足を引っ張りやすくなります。
そのため、AIネットワークでは パケットをできるだけ落とさないこと、つまり ロスレスネットワーク が重要になります。
EthernetベースのAIネットワークでは、RoCEv2 と DCQCN(ECN/PFC) などを使って、こうしたロスを起こしにくいネットワークを実現します。
このあたりの詳細は別記事で紹介しましたが、ここで押さえておきたいのは、AIネットワークでは パケットロスを防ぐために 輻輳をうまく制御すること が重要だということです。
ただ、これだけではまだ足りません。もう一つ大事なのが、トラフィックを偏らせないことです。
複数経路があっても、きれいに使えるとは限らない
スケールアウト型のネットワークでは、Leaf-Spine型のIP Fabric が広く使われています。AIインフラのネットワークも、その代表的なユースケースの一つです。
Leafが複数のSpineにつながることで、ネットワーク全体としては複数経路を持てる構成になります。こうしたネットワークでは通常、ECMP を使って経路分散を行います。
ECMPは、IPアドレスやポート番号などを元にハッシュを計算し、フロー単位で経路を決める仕組みです。普通のデータセンターネットワークでは、これで十分なことが多いですが、AIネットワークでは少し事情が違います。
GPU間通信は、
-
フロー数が少ない
-
1フローあたりの帯域が大きい
-
バースト性がある
といった特徴を持っているからです。
そのため、ECMPの結果次第では一部の経路にフローが偏ってしまい、輻輳が起きることがあります。Fabricとしては複数経路を持っているのに、実際には一部のリンクだけが詰まり、他はまだ余裕があるというちょっともったいない状態になるわけです。
そこで効いてくるのが Dynamic Load Balancing(DLB)です。
DLBは、もっと細かい単位でトラフィックを見る
Dynamic Load Balancing(DLB) は、フローベースで固定的に経路を決めるのではなく、ポート状況(データ量など)を見ながら複数経路にうまく負荷分散するための仕組みです。
通常のECMPでは「1フローは基本的に1経路」となりやすいのに対して、DLBでは「1本の重いフローでも複数経路に分けて流す」ことができます。
DLBのモード
DLBにはいくつかの動作モードがありますが、代表的なのが Flowlet SwitchingとPacket Spraying です。
Flowlet Switching は、フロー中の短い gap を境に経路を切り替える方式です。フローがずっと途切れず流れているように見えても、実際にはごく短い隙間が入ることがあります。その隙間を境目として後続の通信を別経路へ流す、というのが基本的な考え方です。通信のまとまりごとに切り替えるので、順序入れ替わり(Out-of-order)を抑えやすいのが特徴です。
一方の Packet Spraying は、パケット単位で経路を振り分ける方式です。帯域を均等に使いやすい反面、パケットの順序入れ替わり(Out-of-order)が発生しやすいという特徴があります。こうした順序入れ替わりが起きると、受信側でパケットを正しい順番に扱いにくくなり、通信性能に悪影響が出ることがあります。
実際にスイッチで試してみた
では実際にスイッチでDLBの挙動を確認してみます。今回のポイントは、シングルフローでも分散が起きるのかどうかです。
送信条件としては、シングルフローにて9000Byteのジャンボフレームを連続送信し続けます。スイッチのDLBはFlowlet Switchingで動作させました。
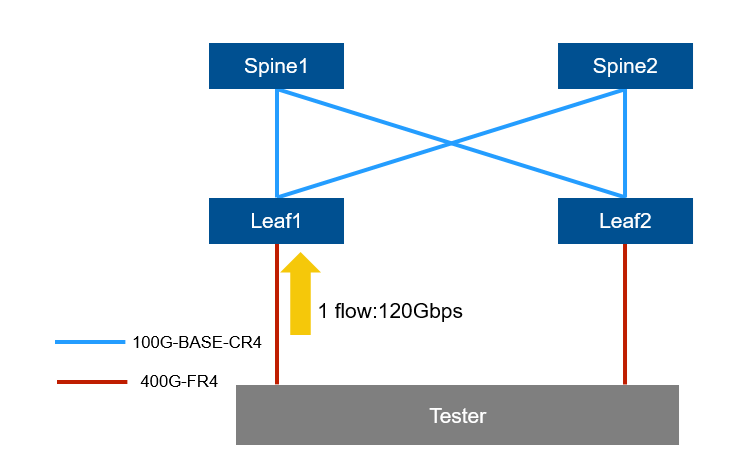
DLBを無効の場合
DLBを無効時は当然ですがECMPベースの挙動になります。
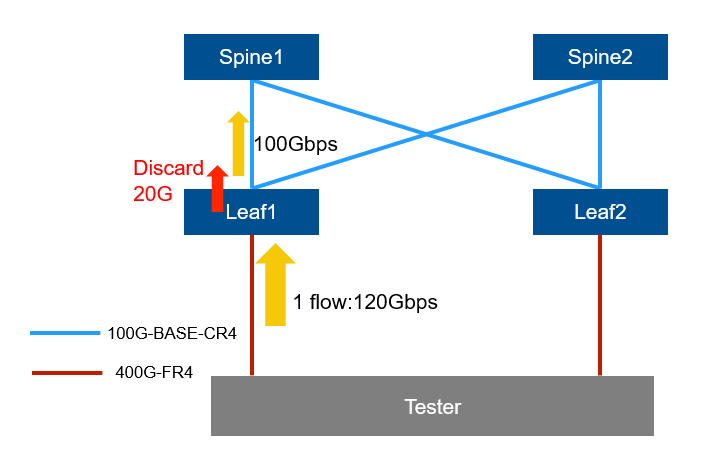
シングルフローは片側の経路に寄り、もう片方のリンクは空いたままになります。1本の経路に対して egress 帯域以上のトラフィックが押し寄せると、あふれたパケットはそのポートで破棄(Discard)されました。ここがまさにECMPの弱点です。
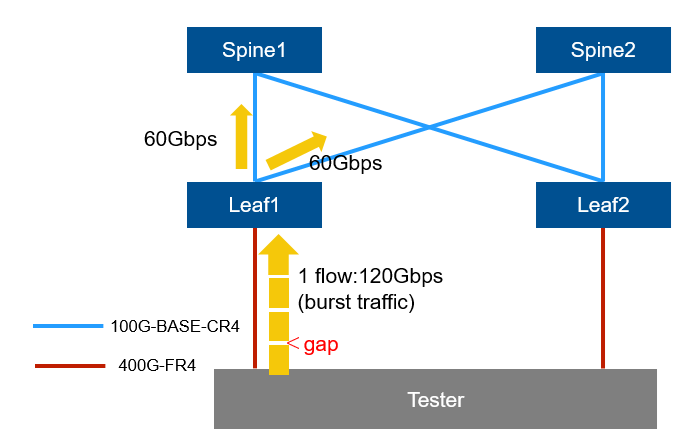
DLBを有効にした場合
次に DLBを有効 にして試しました。
ここは少し面白いところで、単純に同じパターンのトラフィックを連続して流すだけでは分散しませんでした。
先ほどの Flowlet Switching の説明の通り、DLBはフロー中の gap を経路切り替えのタイミングとして使います。つまり、ただ連続データを流しているだけでは、flowletの切れ目が作れず経路も切り替わりません。
そこで、フローの途中に gap が入るように、トラフィックをバースト的に流してみました。具体的には、9000Byteのジャンボフレームを100パケット連続で送り、μsレベル の gap を入れる形です。(今回はスイッチ側のDLB仕様に合わせ50μsとしました)
この条件にすると、期待通りトラフィックが2本の経路に分散することを確認できました。
この結果から見えてくること
DLBはgapがあるときに経路を切り替え、gapがないと切り替わらない という、Flowlet Switchingの動きを見ることができました。
GPU通信はワークロードによってバースト傾向を持つため、DLBの切替トリガーとなるμsレベルのgapが生じるケースはあると考えられます。ただし、そのgapがどの程度現れるかは通信パターン次第であり、常にきれいに分散されるとは限りません。
それでも、フローベースで経路が固定されるECMPだけで動かす場合に比べれば、偏りによる輻輳やパケット破棄を避けるうえで有効な手段といえそうです。
まとめ
今回の検証では、スイッチでDLBを有効にすることで、シングルフローでも分散される挙動を確認できました。
ただし、こうした経路切替が起きるにはμsレベルのgapがフロー内で発生している必要があります。万能な仕組みではありませんが、少なくともECMPだけでは吸収しにくい重いフローの偏りに対して有効な手段であることを確認できました。
AIインフラでは、どうしてもGPUやモデルの話に目が向きがちです。ただ、その性能を支えているのはこうしたネットワーク側の細かな仕組みでもあります。DLBも、その一つとして押さえておきたい技術です。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


