
- ライター:篠岡 祐太
- 2018年入社。マルチベンダー環境でのネットワーク保守・障害解析に4年間従事。 2022年より放送IP化プロジェクトやGitLabを活用したDevSecOpsの推進を経験。 現在は、AIデータ利活用の効率化を目指し、Kubernetesを利用したデータ分析基盤の開発に注力。 現場での運用経験に基づいた、実践的なインフラ技術の活用を得意としています。
目次
はじめに
週報は、多くの開発・運用現場で「重要だと分かっていながら、毎週確実に時間を取られる作業」になりがちです。担当者ごとに内容や粒度がばらつき、後から読み返しても判断材料として使いにくい、という課題を感じている方も多いのではないでしょうか。
私たちの現場でも同様でした。プロジェクト管理などのシステムに活動データが蓄積されている一方で、それらを横断的に整理し、「今週何が起きたのか」を文章としてまとめる作業は、どうしても人手に依存していました。
そこで私たちは、週報作成を完全に自動化するのではなく、人が判断する前段階の整理を自動化することを目的に、AIを活用した週報自動化の取り組みを始めました。また、社内業務のAI化は汎用AIがもつ知識だけでは対応することができないため、ネットワンシステムズでは、社内の業務データを利活用できるシステムをAIDEEと称し、開発を進めています。
本記事で紹介するのは、AIDEEに蓄積されたデータを活用し、LLM を使って週報の下書きを生成する POC(概念実証)です。
本記事では、週報自動化に取り組む背景と課題、そして現時点で構築した POC の概要を紹介します。まだ改善途中ではありますが、実際に作ってみて見えてきた点を共有できればと思います。
週報作成の課題と背景
週報作成における最大の課題は、「情報そのものが存在しないこと」ではなく、「情報が分散して存在していること」にあります。日々の活動データはプロジェクト管理ツールやログ基盤に蓄積されていますが、それらを横断的に確認し、文脈を理解したうえで整理する作業は、人手に頼らざるを得ません。
また、週報には単なる事実の列挙ではなく、「何が重要だったのか」「どこにリスクや課題があるのか」といった判断が含まれます。この判断基準は担当者の経験や立場に依存することが多く、結果として週報の内容や粒度にばらつきが生じます。
さらに、週報作成にかかる工数は、実際に文章を書く時間よりも、「情報を探し、整理する時間」が大半を占めます。どの対応が今週の成果と言えるのかを確認する作業が積み重なり、結果として週報作成が後回しになったり、形式的な内容に留まってしまうこともあります。
こうした背景から、週報作成は「やるべきだが負担の大きい業務」になりやすく、改善の余地が大きい領域だと考えていました。
週報自動化における前提と制約
今回の週報自動化の検討にあたっては、いくつかの前提条件と制約があります。
私たちは GitLab をプロジェクト管理ツールとして利用しており、Self-managed のオンプレミス環境で構成されています。
そのため、業務データを外部SaaSへ送信する前提の仕組みは利用できません。
社内に蓄積されているデータをどのように活用するかが重要なポイントになります。
GitLab には Issue や Merge Request などの活動データが存在しており、Advanced Search 機能を通じて Elasticsearch にインデックスされています。
今回の取り組みでは、この Elasticsearch に蓄積されたデータを主な入力情報として利用しました。
また、週報作成を「完全に自動化する」ことは当初から目的としていません。週報には最終的な判断や責任が伴うため、AIが自動生成した内容をそのまま公開することにはリスクがあります。
そこで本取り組みでは、「人が判断する前段階の整理や下書きを支援すること」にフォーカスしました。
今回構築した週報自動化POCの全体像
今回構築したPOCの目的は、既に社内に蓄積されている活動データを、週報という形式に再構成することです。
新たな入力作業を増やすのではなく、既存の業務ログを活用し、週次レポートの「下書き」を自動生成する仕組みを構築しました。
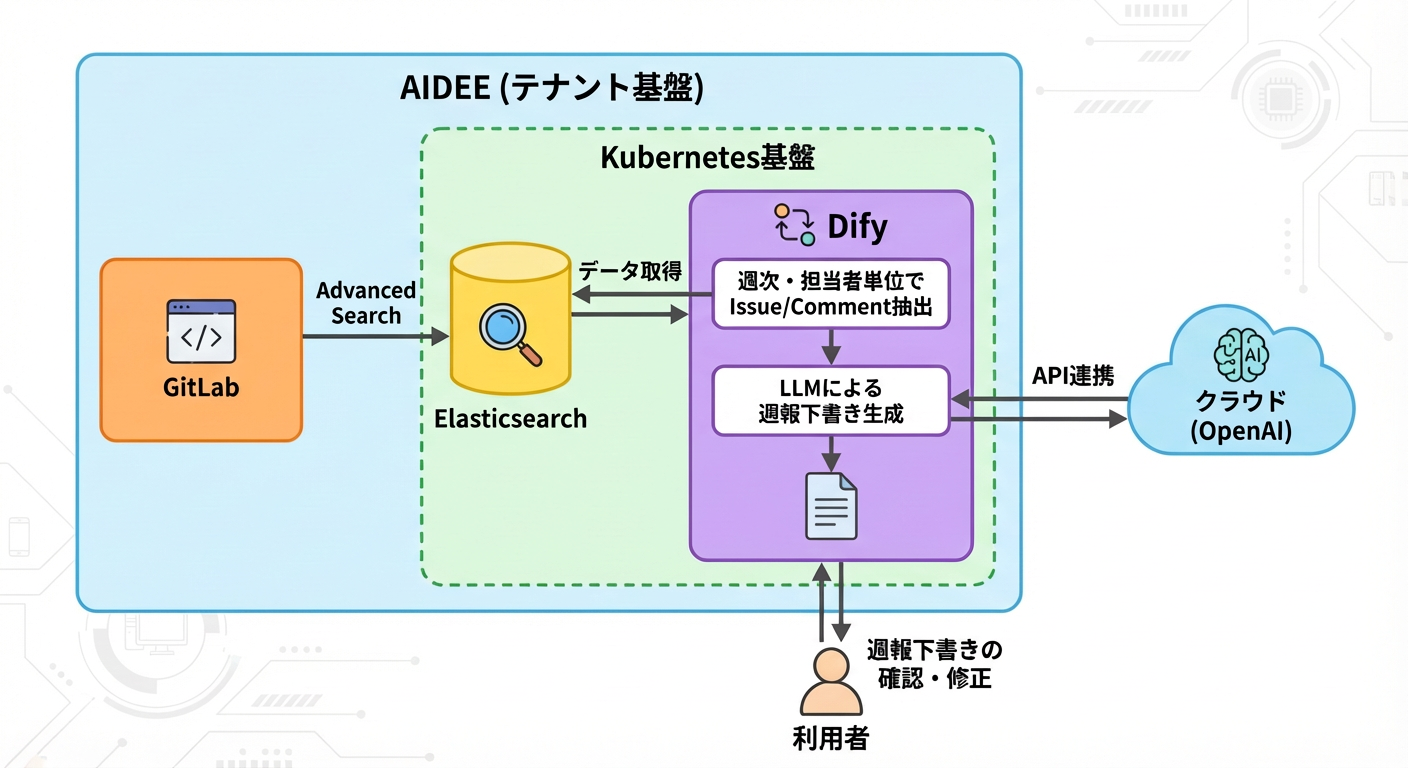
全体構成は以下の通りです。
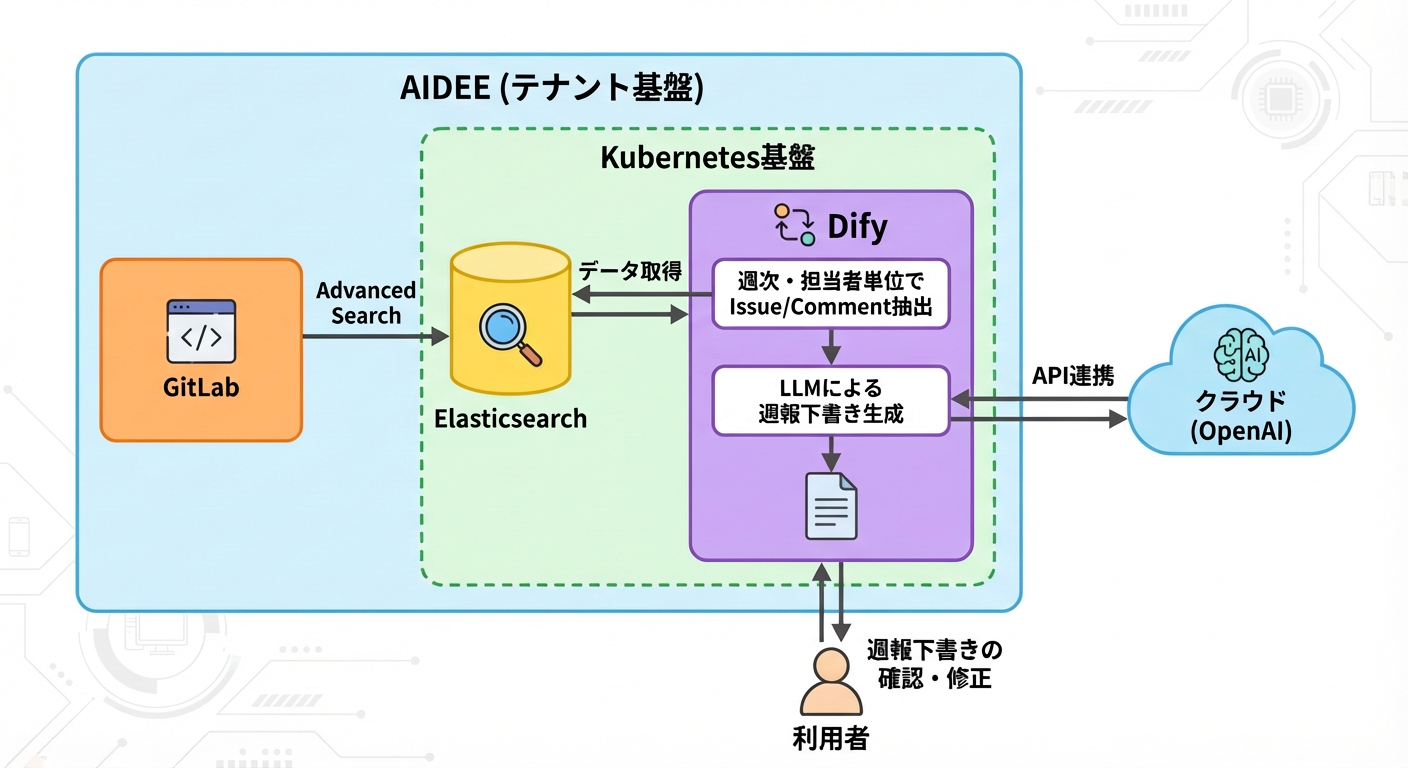
GitLabに蓄積されたIssueやコメントデータは、Advanced Search機能を通じてElasticsearchにインデックスされています。
Difyのワークフローでは、
-
対象期間(週次)
-
担当者
-
対象プロジェクト
といった条件でデータを抽出し、その結果をLLMへ入力しています。
本POCでは、週報フォーマットをあらかじめプロンプト内で定義し、その構造に沿って生成するようLLMに指示しています。
つまり、
-
データ抽出はワークフローで制御
-
文章化・整理・構造反映はLLMに委ねる
という構成です。
以下は今回定義した週報フォーマットです。
|
週報(Week Report) - YYYY/MM/DD 週 1. 現在の業務状況・タスク管理(Status) (テーブル) 課題 (テーブル) 遅延に対するリカバリープラン 進めるうえで必要な支援 / 相談事項 |
このように出力フォーマットを固定することで、
-
情報の網羅性を担保する
-
出力内容のばらつきを抑制する
-
人によるレビューを容易にする
ことを狙いました。
一方で、構造の解釈や分類ロジックの適用はLLMに依存している部分も多く、その点が後述する課題につながっています。
本POCは、完全自律型の仕組みではありません。
あくまで「人が判断する前段階の整理を支援する」ことを目的とした、現実的な自動化の第一歩です。
週報自動化POCの検証結果
今回のPOCでは、実際のプロジェクトデータを用いて週報の自動生成を行い、その出力結果を評価しました。検証の観点は主に以下の3点です。
-
出力フォーマットの安定性
-
タスク/課題の分類精度
-
実運用に耐えうる品質かどうか
本記事では、実際にAIが生成した週報のサンプルを2例掲載しています。
1つ目のサンプルは、比較的うまく生成できた例です。
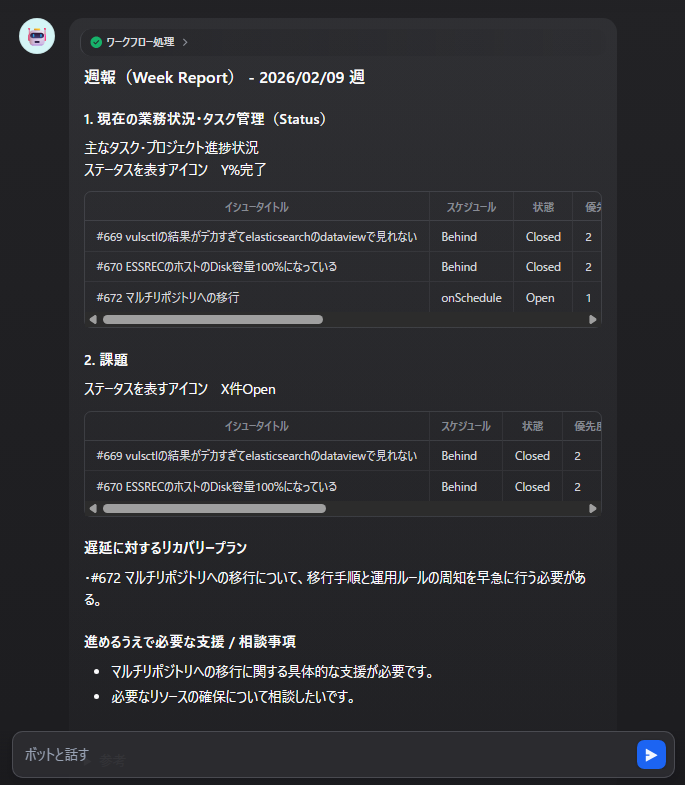
フォーマットは概ね維持されており、Issue情報も網羅的に整理されています。
情報収集の自動化という観点では、一定の効果が確認できました。
一方で、このサンプルでは明確な課題も見られました。
本来「課題」に分類されるべきIssueが「タスク」に出力されており、その逆も発生していました。
Elasticsearchのレスポンスには label_ids フィールドが含まれており、ラベルによってタスクと課題を区別できる設計になっています。
しかし、その情報をLLMに明示的に渡しても、必ずしも意図通りに分類されるとは限りませんでした。
つまり、LLMは文章生成としては自然でも、「構造的な意味の理解」や「業務上の分類ロジックの厳密な適用」には揺らぎがあることが分かりました。
2つ目のサンプルでは、フォーマットの崩れが確認されました。
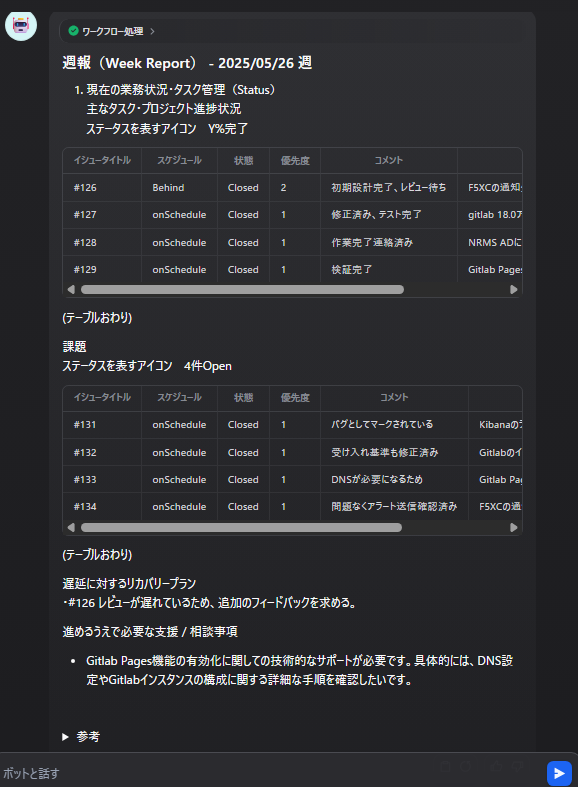
具体的には、本来「イシュータイトル」が入るべき箇所にイシューIDが出力されており、テーブル構造も一部不安定になっています。
これは、プロンプトでフォーマットを指定しているにもかかわらず、出力の再現性が完全には担保できていないことを示しています。
特に、テーブル形式やカラム指定の厳密性を求める場合、LLM単体では安定しないケースがあることが明らかになりました。
これらの検証結果から、週報自動化は「情報収集と文章生成の支援」としては有効である一方で、「構造の厳密性」や「業務ロジックの完全再現」については追加の設計が必要であることが分かりました。
現時点での課題と今後の改善ポイント
今回の検証を通じて、改善すべきポイントが明確になりました。
特に重要なのは、「LLMの特性を前提とした設計になっているか」という観点です。
タスク/課題分類の精度向上
原因(LLMの特性)
LLMは、与えられた情報をもとに「もっともらしい文章」を生成することは得意ですが、業務ロジックを厳密に適用し続けることは得意ではありません。
今回の検証では、Elasticsearch の label_ids をそのままLLMに渡し、タスク/課題の分類を反映させようとしました。
しかし、LLMにとって label_ids は単なる数値情報であり、その意味を常に一貫して解釈する保証はありません。
その結果、本来「課題」に分類すべきIssueが「タスク」に出力されるなどの揺らぎが発生しました。
つまり、LLMに“分類判断”まで任せてしまったことが、構造の不安定さにつながったと整理できます。
対応策(設計の見直し)
今後は、LLMに判断させる範囲を限定します。
-
前処理段階でタスク/課題を機械的に分類する
-
label_idsを人間可読な分類情報(task / problem など)へ変換する -
意味が確定した構造化データ(JSON)としてLLMに渡す
これにより、「分類」という構造的判断はロジック側で保証し、LLMは文章化・要約に専念という役割分離を実現します。
LLMの強みである自然言語生成を活かしつつ、弱みであるロジックの厳密適用を補完する設計へと見直します。
フォーマット安定性の向上
原因(LLMの特性)
LLMは本質的に確率的な生成モデルです。
プロンプトでフォーマットを指定しても、常に同一の構造を再現できるとは限りません。
今回の検証では、
-
テーブル構造の崩れ
-
タイトル欄にIDが入る
-
カラムの順序が揺らぐ
といった現象が確認されました。
これは、構造の生成までLLMに任せていることによる自由度の高さが原因と考えられます。
対応策(設計の見直し)
フォーマットの安定性を高めるため、LLMの自由度を意図的に下げる設計へ移行します。
具体的には、
-
週報をセクション単位で分割して生成させる
-
まずJSON形式で出力させ、その後アプリケーション側でMarkdownへ整形する
といった方法を検討しています。
これにより、LLMは「内容生成」に集中し、フォーマット整形はロジックで保証という分業が可能になります。
実運用においては「自然さ」よりも「再現性」が重要です。
生成AIを業務に組み込む際は、この優先順位の整理が不可欠です。
LLMの役割の再定義
今回の検証を通じて明確になったのは、
LLMは“万能な業務エンジン”ではなく、“高度な文章生成エンジン”である
という点です。
LLMは、下記のような処理に強みを持ちます。
-
要約
-
文脈整理
-
自然な文章生成
一方で、下記のような「決定的な処理」には向いていません。
-
業務ルールの厳密な適用
-
分類ロジックの保証
-
フォーマットの完全再現
したがって、業務ロジックは従来のプログラムで担保し、LLMは最終的な要約・自然言語化に特化させるという役割分担が、実運用における安定性を高める鍵になります。
まとめ
今回のPOCは、週報自動化の可能性と同時に、AI活用における設計思想の重要性を示す結果となりました。
今後は、
- タスク/課題分類のロジック側での確定
- 構造化データ(JSON)を活用した安定した入力設計
- 出力フォーマットの分割生成による再現性向上
を進め、実運用レベルへと昇華させていきます。
週報自動化は単なる効率化ではなく、組織に蓄積された活動データを構造化し、再利用可能な知識へと変換する取り組みです。
本POCはその第一歩に過ぎません。
AIに任せる部分と、ロジックで担保する部分を明確に切り分けながら、今後も継続的に改善を進めていきます。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


