
NVIDIA®は2025年のGTCにて、小型AIコンピューター「NVIDIA DGX Spark™」を発表しました。
小型筐体・低消費電力ながら、128GBのユニファイドメモリを搭載し、背面のNVIDIA ConnectX®-7 NICを利用することでマルチノードのGPU間通信が可能です。
この度、DGX Sparkと共通アーキテクチャを採用したDell Technologies版モデル「Dell Pro Max with GB10」を入手しましたので、開封から簡単な推論までさわってみた所感をご紹介します。

- ライター:井戸 康太
- ネットワンシステムズに入社後、サーバ製品をはじめとしたPF領域・VDI関連領域を担当。
同製品の技術検証・案件支援等に従事。
最近はAI基盤をはじめとした領域も担当中。
目次
はじめに
皆さま初めまして!
ネットワンシステムズの井戸と申します。
業務ではサーバー製品やデジタルワークスペース製品を担当しております。
今回のネタであるAI基盤に関しても、サーバー製品の延長上ということで積極的にキャッチアップしております。
NET ONE BLOGへの投稿は初めてですが、よろしくお願いいたします。
Dell Pro Max with GB10とは?
「DellPro Max with GB10」(以下、Pro Max GB10)は、NVIDIAが提供する小型AIコンピューター「NVIDIA DGX Spark」(以下、DGX Spark)と共通アーキテクチャを採用した、Dell Technologies版のモデルです。
 Dell Pro Max GB10
Dell Pro Max GB10
基本的なスペックは互換元となるDGX Sparkに準じています。
以下スペック(一部抜粋)になります。
| プロセッサー | NVIDIA GB10(16 MB L2キャッシュ、20 ARMコア) |
| メモリー |
128 GB、LPDDR5x、273 GB/秒、一貫性のある統合システム メモリー |
| プライマリー ハード ディスク ドライブ |
標準構成: |
| GPU |
NVIDIA Blackwell |
| ポート |
1 x USB 3.2 Gen 2x2 (20 Gbps) Type-C® |
| ワイヤレス |
AzureWave AW-EM637、2x2、802.11be、Bluetooth® |
| パワー |
280W ACアダプター, USB Type-C |
| ネットワーク コントローラー | NVIDIA ConnectX-7(QSFP対応) Realtek RTL8127-CG(10GbE対応) |
128GBのユニファイドメモリを搭載していることで、比較的大規模なモデルをローカルで動かすことができます。
また、ConnectX-7 NICを搭載しており、背面のQSFPポートを利用することで200GbpsでのGPU間通信が可能です。(最大2ノード)
一方で、ネットワーク冗長性がないことやWi-Fi搭載、USB Type-C給電、LPDDR5xメモリといった仕様から、ミッションクリティカルな環境での常時稼働を前提とした設計ではなく、学習用途や少数グループでの開発用途に最適化された機器であることが分かります。
こうした仕様から、本機は“学習・検証用途向けのコンパクトなAIコンピューター”として位置付けられていることが分かります。
開封 ~ セットアップ
開封
早速開封してみました。
筐体を見てみると、前面にメーカーロゴ、背面に各種インターフェースが搭載されていることが確認できます。
 前面・背面の様子
前面・背面の様子
背面は左から
- 電源ボタン
- Type-Cポート x4
- HDMIポート
- RJ45ポート(10GbE)
- QSFPポート(200Gb) x2
となっています。
Type-Cポートのうち給電用は一番左で固定されており、他ポートはDP Altモードに対応しています。
Type-Cで画面出力ができるので、外部機器が軽くなり取り回しがよかったです。
セットアップ
セットアップについて
Pro Max GB10には2つのセットアップ方法があります。
- キーボード・マウス・ディスプレイを接続して直接セットアップ
- 内蔵のWi-Fiを利用し、他PCからアクセスしてセットアップ
今回は環境の都合上、①の方法でセットアップしました。
周辺機器を接続し、背面の電源ボタンを押すと以下画面が表示されました。
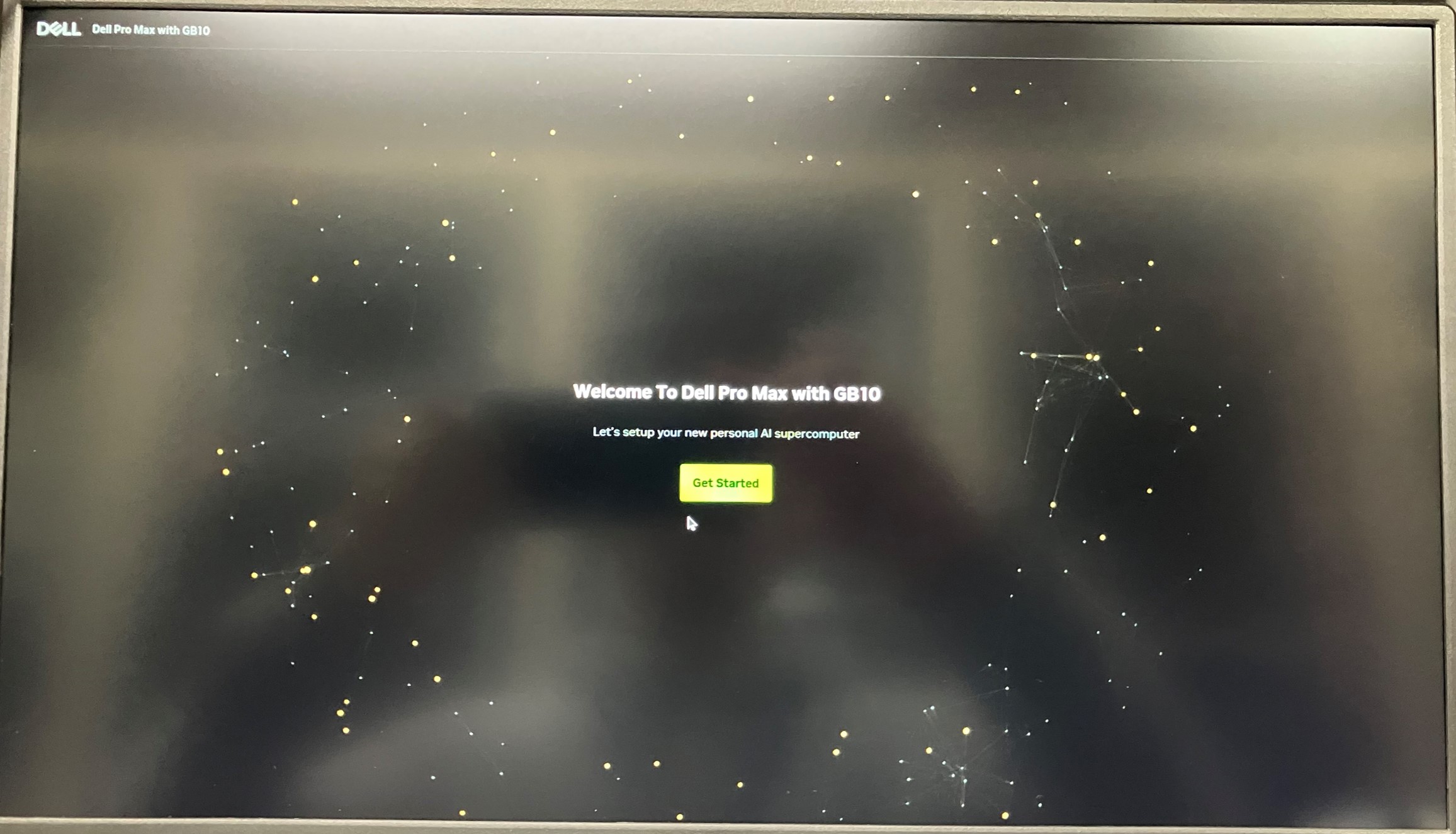
初期画面
搭載OSはNVIDIAのDGX™ OSですが、ちゃんと「Dell Pro Max with GB10」と表示されていますね。
「Get Started」をクリック後、案内に従い言語設定・規約への同意・アカウント作成を実施します。
設定が完了すると、システムアップデートが走ります。
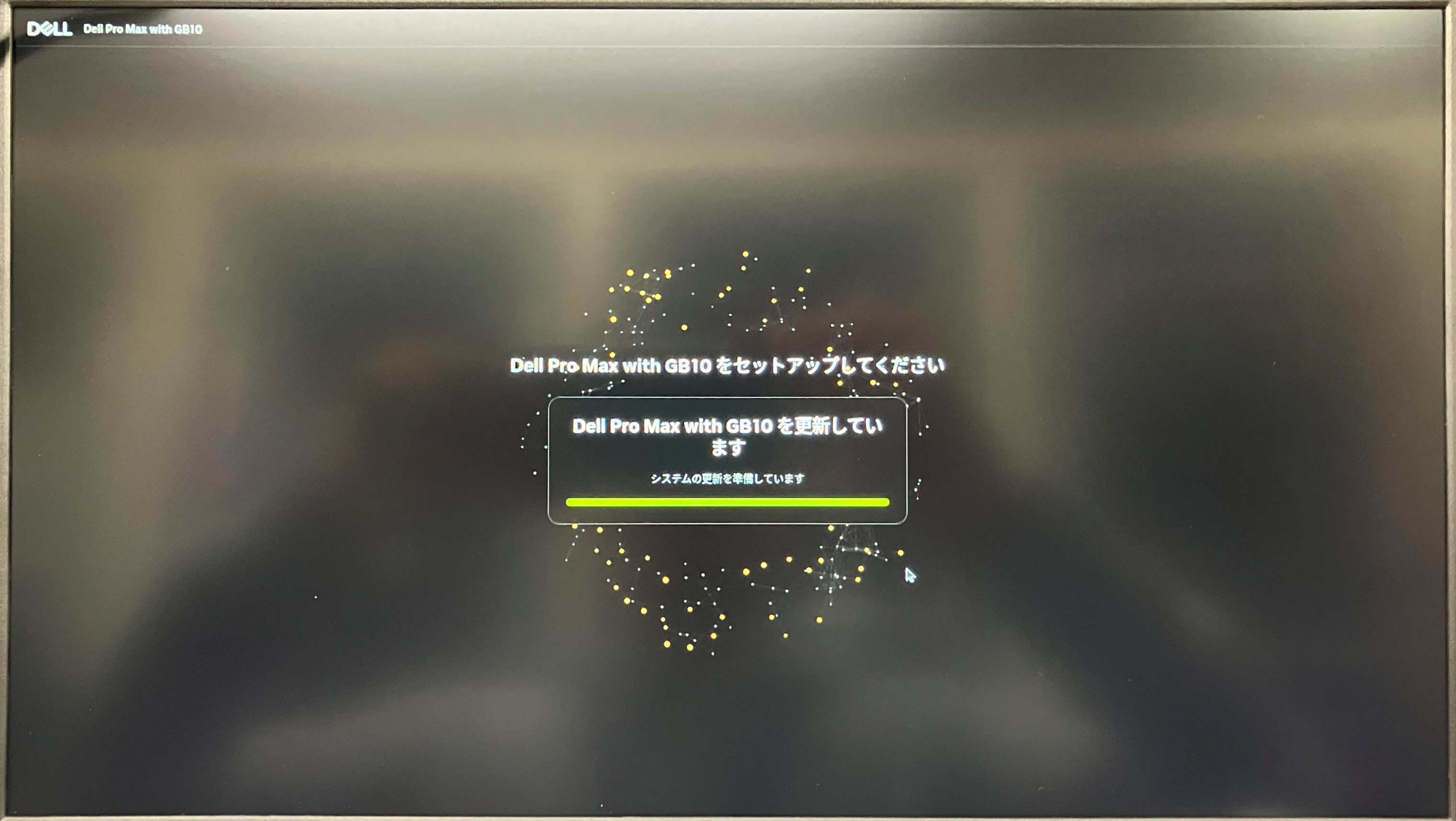 システムアップデート画面
システムアップデート画面
時間がかかるかな…と思いましたが、有線のためか10分かからず完了しました。
アップデート完了後、作成したアカウント情報でログインします。
DGX OSのデスクトップ画面が表示されました!
 DGX OS デスクトップ (初回起動時)
DGX OS デスクトップ (初回起動時)
DGX OSはUbuntuをベースとしているため、あまり使用感も変わらずさわることができます。
初期状態ではDHCP設定になっていますが、リモートアクセスで作業したいため固定IPを振っておきます。
さわってみた
今回は下記内容を試してみました。
- NVIDIA Sync・DGX Dashboardの利用
- DACケーブルを用いたマルチノード接続
- vLLMを用いた推論
また、Pro Max GB10はDGX Sparkと共通アーキテクチャを採用しているため、DGX Spark向けに記述されたドキュメントやPlaybookを、そのままPro Max GB10でも参照して利用できます。
NVIDIAが豊富なドキュメントを用意しており、下記を参考にしています。
DGX Spark User Guide
DGX Spark User Guide — DGX Spark User Guide
システム情報やアップデートについて記載されています。
Start Building on DGX Spark
推論をはじめとした、DGX SparkでできることのPlaybookが記載されています。
NVIDIA Sync・DGX Dashboardの利用
NVIDIA Syncとは?
NVIDIA Syncとは、DGX Sparkに対して簡単にリモートアクセスするために用意されたツールです。
NVIDIA Sync — DGX Sparkユーザーガイド
クライアントにNVIDIA Syncをインストールすることで、IP・アカウント情報のみでDGX SparkへSSHアクセスできます。
つまり簡単な設定でSSHが使えるようになります。
設定すると、以下のような画面が表示されます。
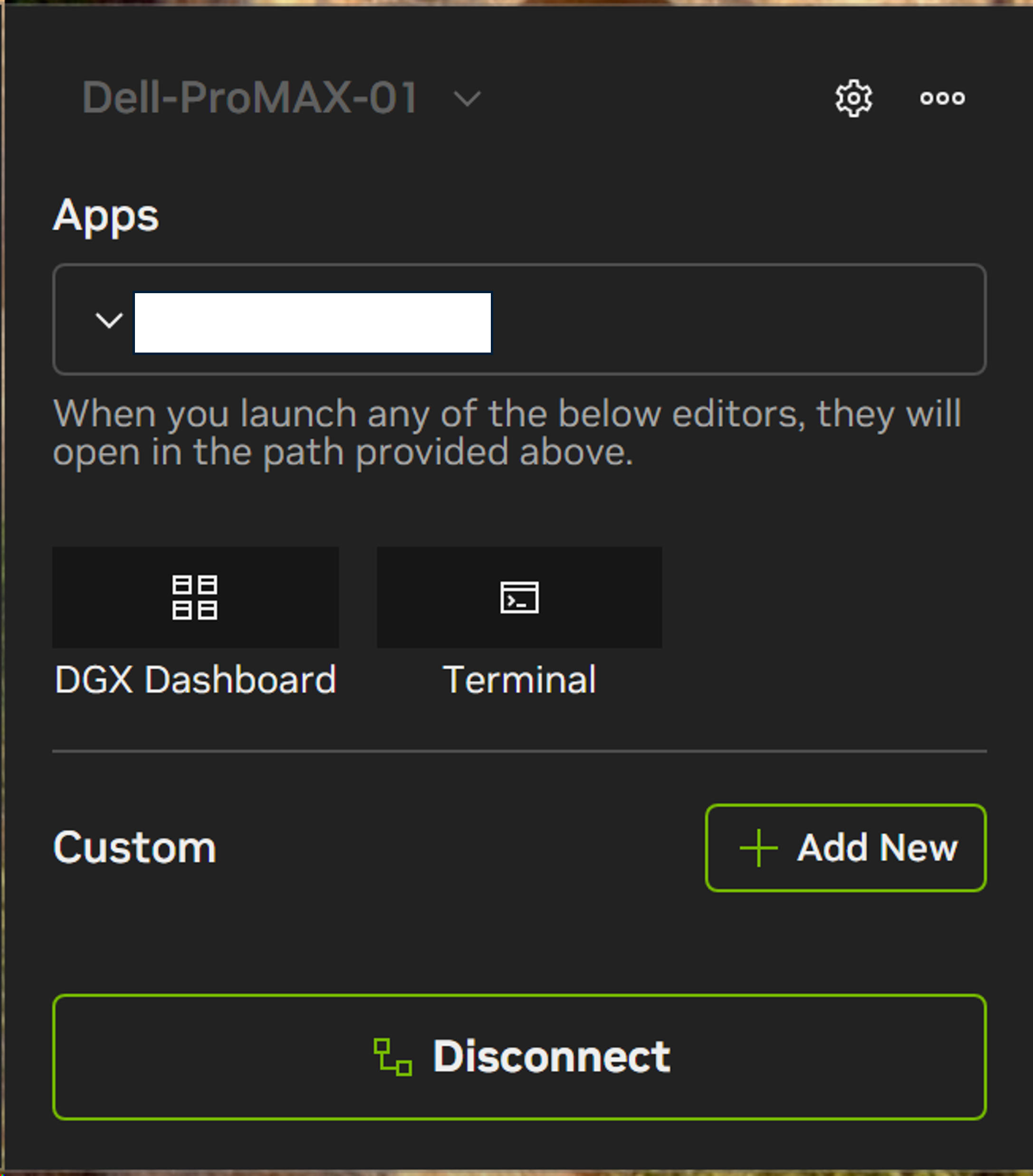
この状態から「DGX Dashboard」「Terminal」「VScode(インストールしていれば表示)」を選択することで、各ツールにSSHでアクセスできます。
また、特定のコンテナ・サービスを起動させるようなカスタムスクリプトを作成することも可能です。
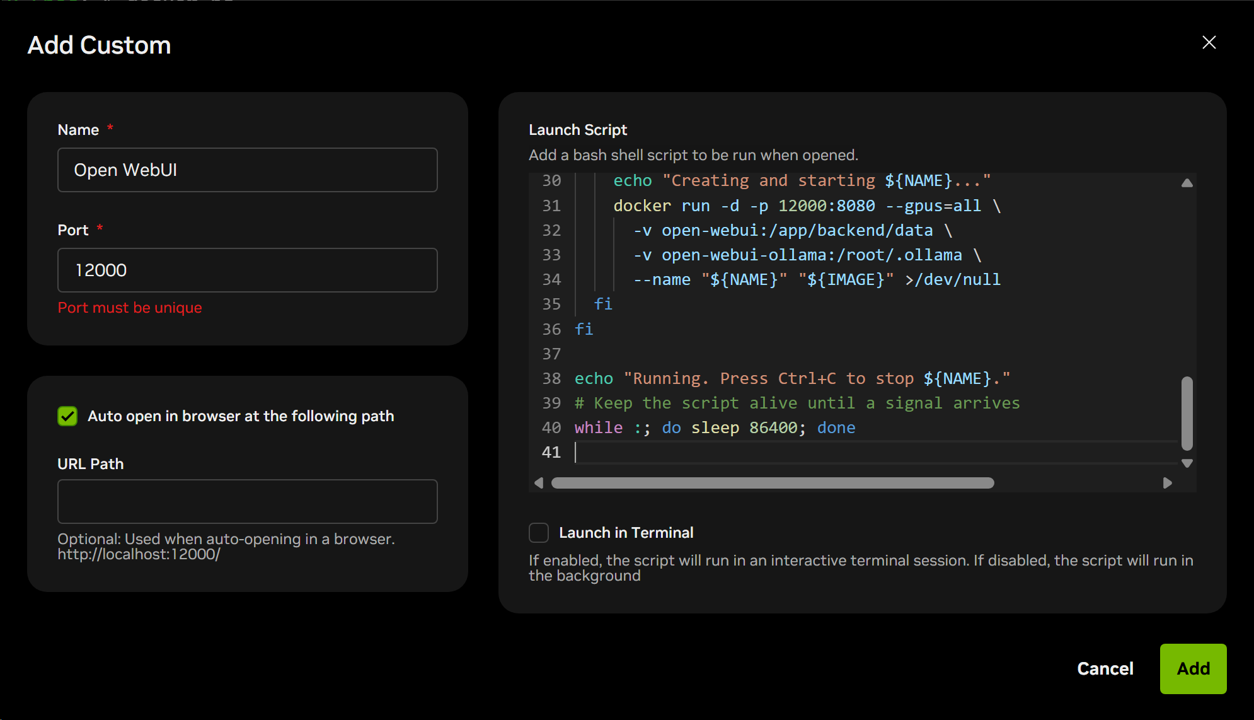 Open WebUI + Ollama起動スクリプトの例
Open WebUI + Ollama起動スクリプトの例
個人的にはファイルの受け渡しが楽だったので、VScodeが非常に良かったです。
DGX Dashboardとは?
メモリやGPUの利用率の確認、システムアップデートの実施を行うページです。
また、JupyterLabの起動もここから行います。
ブラウザからlocalhost:11000へアクセスすることで確認できます。
NVIDIA Syncで接続済みの場合、クライアントのブラウザからでもアクセスが可能です。
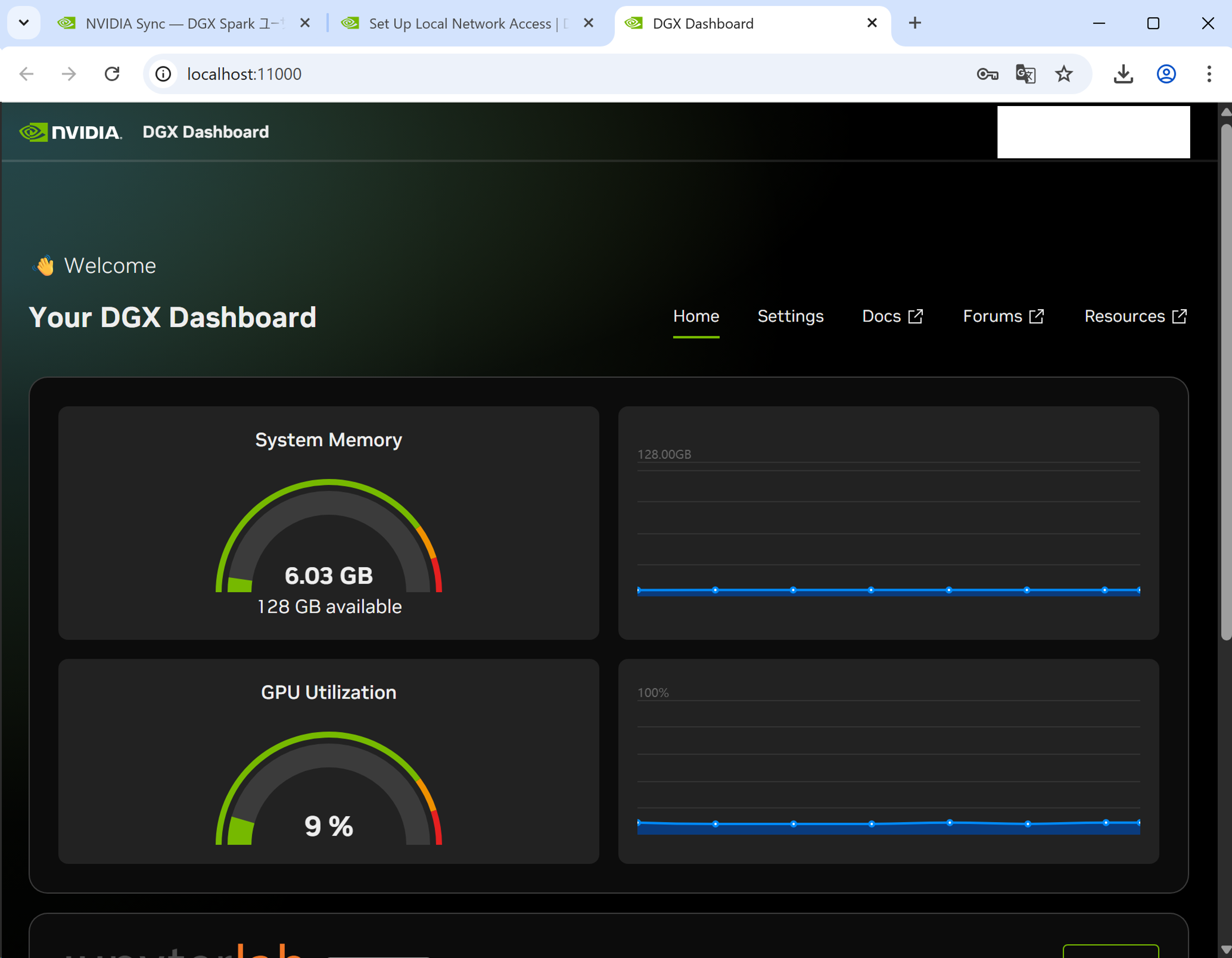 DGX Dashboard (一部)
DGX Dashboard (一部)
DACケーブルを用いたマルチノード接続
前述の通り、Pro Max GB10はQSFPポートを通じてマルチノードのGPU間通信を実現できます。
今回は接続用のDACケーブルも入手できましたので、マルチノード接続を試してみます。
 Dell純正DACケーブル
Dell純正DACケーブル
Start Building on DGX Spark内のConnect Two SparksおよびNCCL for Two Sparksを参考に進めていきます。
事前準備しておくこと
マルチノード接続を実施する前に、以下の状態にしておきます。
- 対応DACケーブルの用意
- 各ノードのユーザ名を一致させておく
- 各ノードがインターネットに接続されている
マルチノード接続してクラスタ化する際、片方を親、もう片方を子として設定していきます。
親が子のリソースを使えるイメージですね。
IPアドレス設定
Connect Two Sparksの範囲では、DACケーブルを2台のPro Max GB10に接続し、各ノードにIPアドレスを設定していきます。
3つ提示されている手順のうち、今回はOption 2のnetplan configure fileを作成しました。
設定が完了すると、以下のようにIPアドレスを確認できます。
※本環境ではDACケーブルが2本刺さっているため、全てのインターフェースにIPが設定されています。
※…が、本記事内では1本しか利用していないため、ご承知おきください。
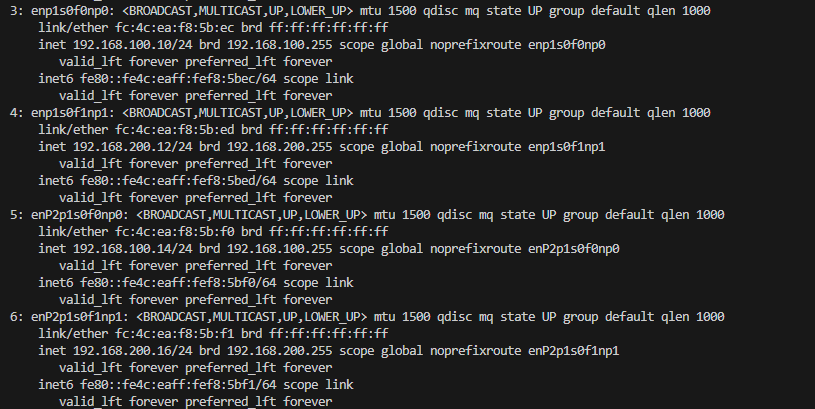 ip addr showの結果(一部、node1)
ip addr showの結果(一部、node1)
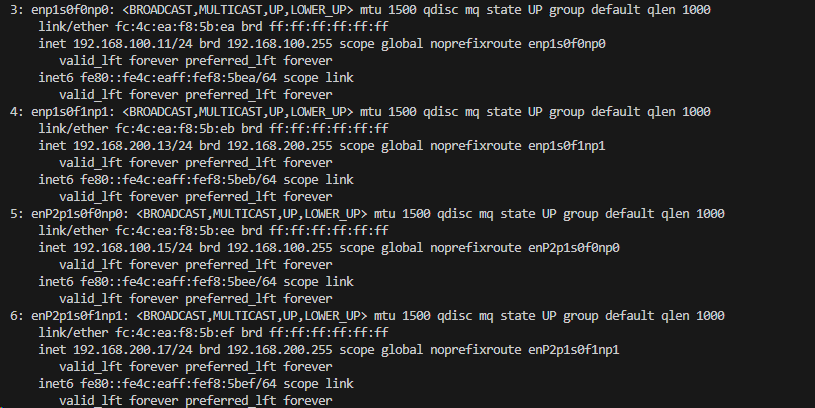 ip addr showの結果(一部、node2)
ip addr showの結果(一部、node2)
NCCLの設定
続いてNCCL for Two Sparksの範囲では、各ノードにNVIDIAのGPU間通信を最適化するライブラリであるNCCLの設定をしていきます。
Playbook内のコマンドを実行していきます。
設定後、Step 5でnccl-testsを実施します。
結果は以下の通りです。
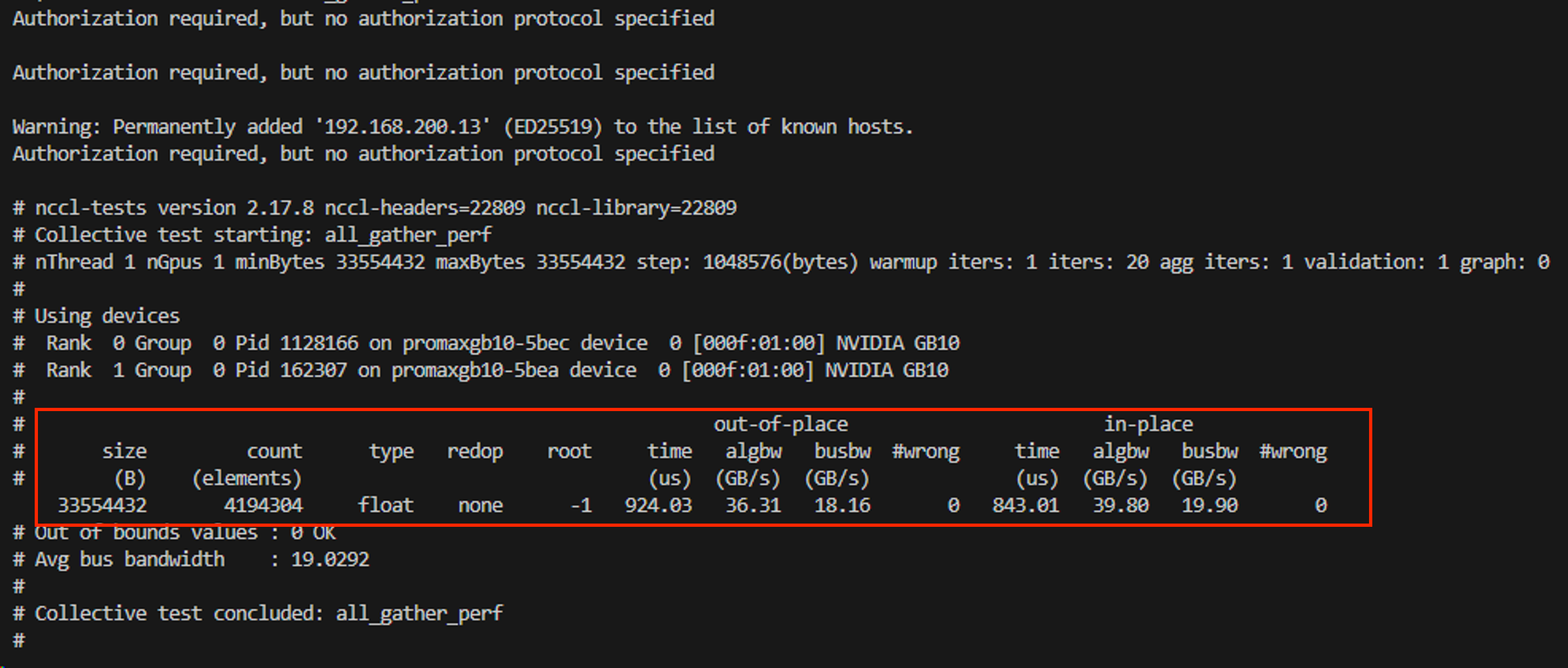
node1 (親)
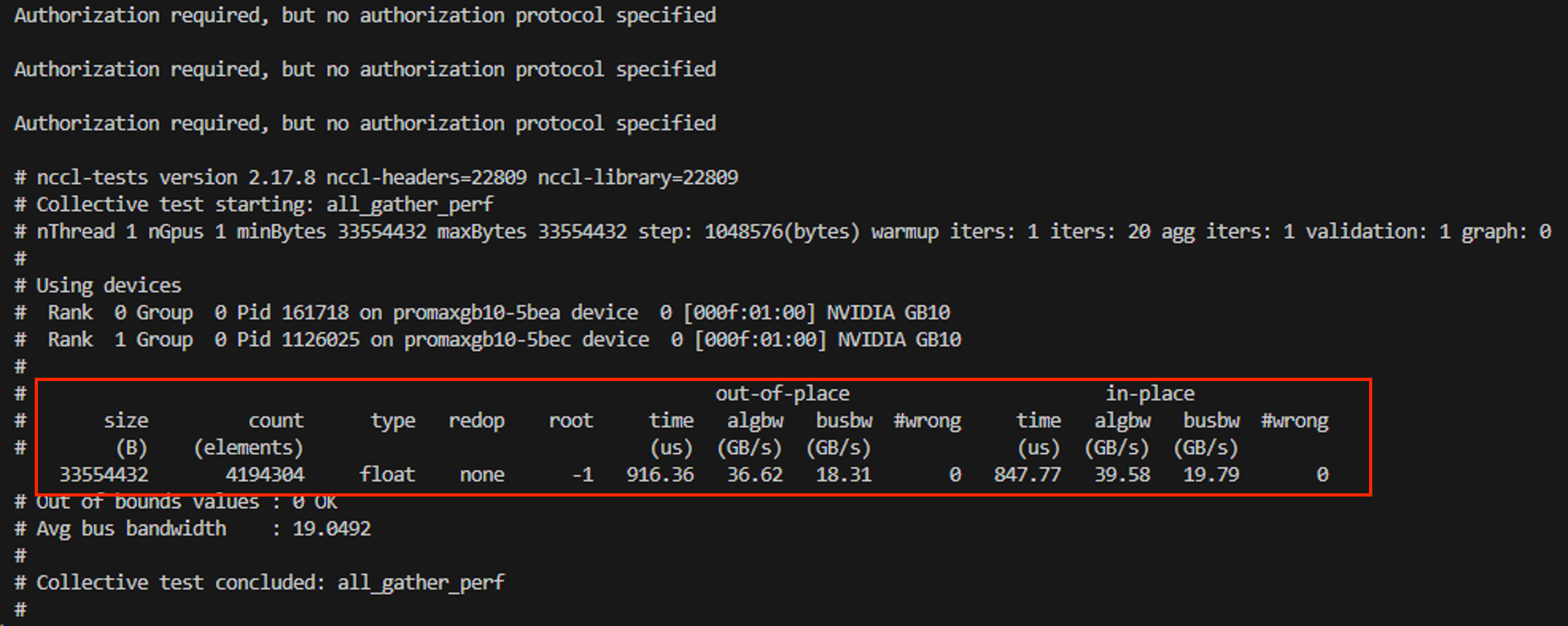
node2 (子)
「algbw」・「busbw」項を見ると、36.31 ~ 39.80 (GB/s)・18.16 ~ 19.90 (GB/s)になっています。
これはそれぞれ290.48 ~ 318.4 (Gbit/s)・145.28 ~ 159.2 (Gbit/s)ですので、正常に通信できているといえるのではないでしょうか。
vLLMを用いた推論
マルチノード間の通信が確認出来たところで、大規模なモデルの推論を試してみました。
NVIDIAの触れ込みでは1ノードで2000億パラメータ(200B/4bit量子化)のモデルを動かせるとのことですので、今回は2ノードでLlama3.1 405B (INT4量子化)を動かしてみたいと思います。
Start Building on DGX Spark内のvLLM for InferenceのPlaybookでも、テスト用途として同モデルを用いた推論が案内されています。
必要メモリについて
Llama3.1 405B (INT4量子化)を動かすには、通常200GB以上のGPUメモリが必要になります。
Pro Max GB10は1ノードあたり128GBのユニファイドメモリ(CPUと共用)を搭載しているため、2ノード利用でギリギリの数値となることが想定されます。
先ほどのvLLM for Inferenceページより、Run on two Sparksタブを選択して進めていきます。
通信可能な2ノードをRayというライブラリを使用し、vLLMクラスタとして設定していきます。
必要なスクリプト・コンテナを取得し、node1をhead node、node2をworker nodeとして起動します。
設定が完了したら、Step 6に従いray statusコマンドでクラスタステータスを確認してみました。
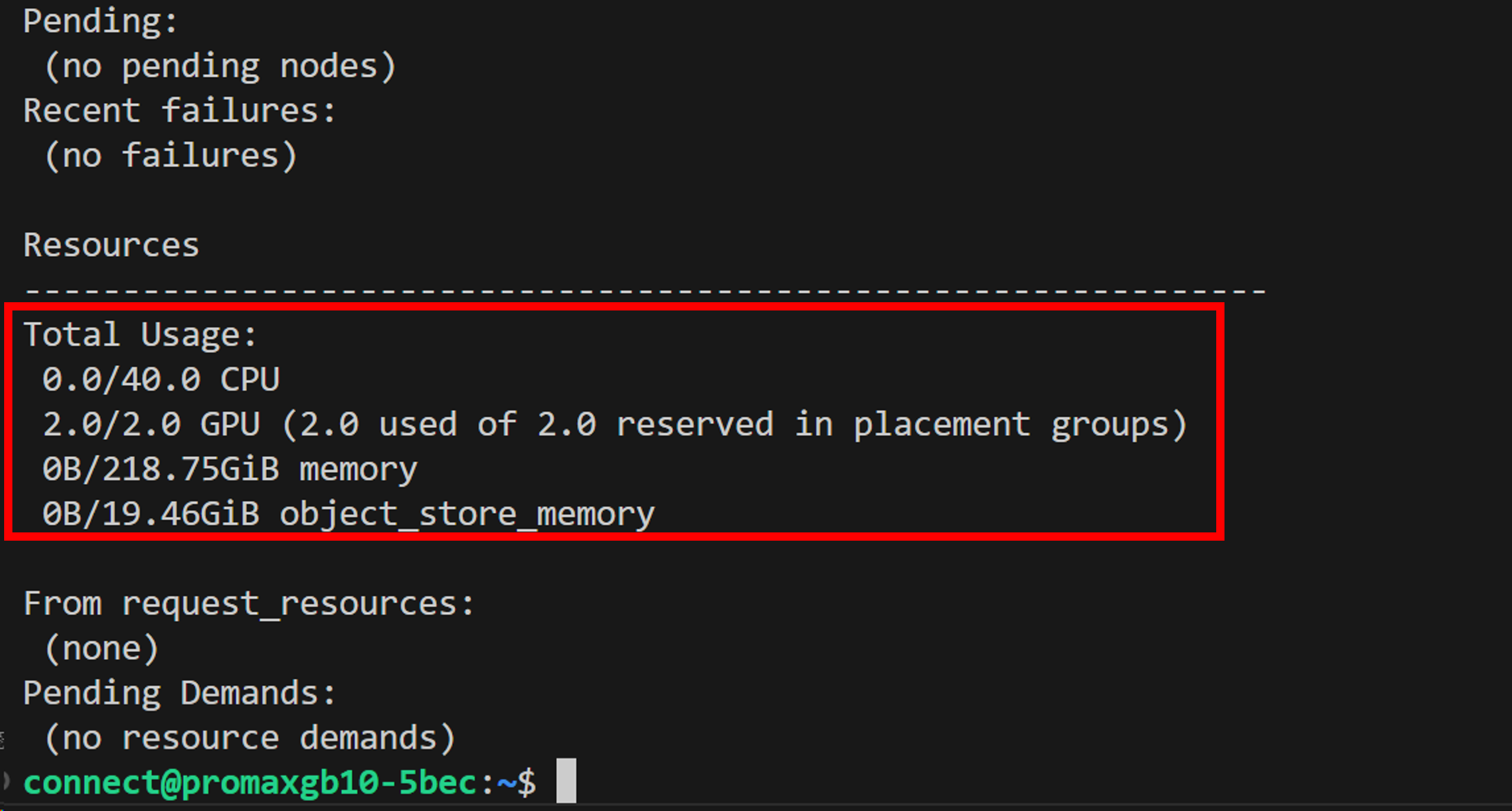 ray statusの結果 (一部)
ray statusの結果 (一部)
GPUが2基、メモリが218.75GiB認識されていることが確認できます。
2ノードのリソースをまとめて利用できる状態になっています。
この状態でvLLM上にモデルを展開していきます。
Step 11のコマンドでvLLMクラスタ上にLlama3.1 405Bを展開できます。
途中で止まってしまいますが、バックグラウンドでモデルをダウンロードしているため気長に待ちましょう。
私は一晩放置しましたが、ログを見るとおよそ1時間半程度かかっていました。
「Application startup complete」というログが表示されると起動完了し、待ち受け状態となっています。
早速推論してみましょう。
新しいTerminalを開き、HTTPリクエストでモデルに話しかけます。
Playbookを参考にしつつ、「GPUについての俳句を詠んでください」と聞いてみました。
結果は以下の通りです。
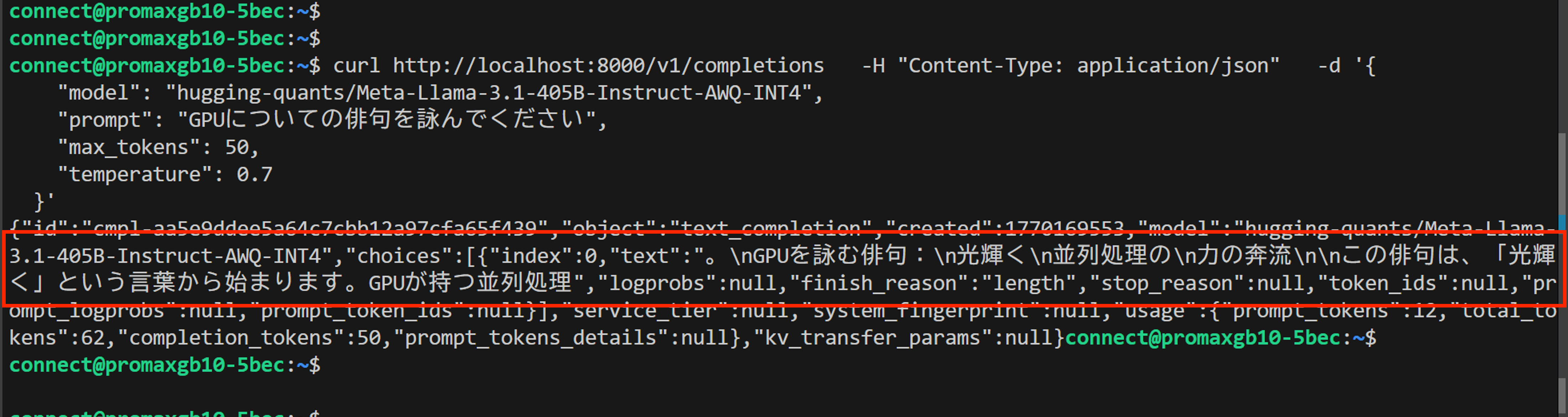
推論結果
WebUI等利用していないため少しわかりにくいですが、「GPUを詠む俳句: 光輝く 並列処理の 力の奔流…」と返答を得られています。
※max_tokensを50に制限しているため、回答が途中で終了しています。
無事、目的としていたマルチノードを活用した大規模モデルの利用までたどり着きました。
大規模モデルですので、回答が得られるまでは多少の待機時間がありました。
また、制限をした状態でもある程度の発熱がありましたので、Playbookにあった「testing purposes only」の文言は正しいかなと思います。
おまけとして、メモリ不足のエラーを取得できないかとシングルノードで同モデルの推論を試してみましたが、性能不足からか途中でハングアップしてしまいました。
所感・今後
今回はNVIDIA DGX SparkのDell Technologies互換機であるDell Pro Max with GB10をさわってみました。
スペックを見てみると、ネットワークの冗長性がないこと・メモリ帯域等、本番環境での利用が想定されている機器ではありませんでした。
しかし、シングルノードでも比較的大きなモデルを試せること・低消費電力であることによる手軽さがあり、何よりNVIDIAが提供するPlaybookを活用することで、マルチノードのクラスタ化や大規模モデルの展開ができることに大きなメリットを感じました。
今回の記事では触れていませんが、本製品にはNVIDIA AI Enterpriseライセンスを適用でき、NVIDIA NIM™をはじめとしたツールを試すことができます。
これらのことから、学習・研究用途として需要はあるのではないでしょうか。
引き続き、本機器は社内でのAI基盤の学習環境として活用していきたいと考えております。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


