
前回の「HashiCorp Vaultでgeminiのキー管理をためしてみた」ではHashiCorp Vaultで開発者がLLMを使用するためのキーを取得できる仕組みを説明しました。今回はLiteLLM Proxyを使ってキーを配布する仕組みを設定手順や検証を交えて整理します。

- ライター:田村 勝
- 2010年にネットワンシステムズに入社。
データセンターネットワークの製品担当として、技術検証や技術サポートに従事。
その後クラウド接続サービスの立ち上げを経て、現在は社内向けのAI活用サービスの開発運用を行っている。
目次
はじめに
前回の「HashiCorp Vaultでgeminiのキー管理をためしてみた」では、開発者個々に単一の長期的なAPIキーを配布することのリスクと、それを回避するために各開発者にユニークなキーを払い出す仕組み構築の必要性について説明しました。そして、Vaultを活用してプロバイダ固有のキーを作成し、配布する方法を実際に試してみました。
今回は、もう一つの選択肢として、LiteLLM Proxyを用いて仮想キーを払い出す方法を検証していきます。
| 説明 | 特徴 | |
|---|---|---|
| A)実キーを払い出す |
プロバイダ(OpenAI/GCP/Azure等)の実際の認証情報(APIキーやサービスアカウントキー)をユーザーに渡す方式。 実現方法(例) |
・既存クライアントやライブラリと互換性が高く、アプリケーションに変更を加える必要がない。 ・LLMプロバイダにキーを登録する必要があるため、キー追加の権限が必要になる。 |
| B)仮想キーを払い出す |
プロキシとLLMとの間の通信のみで実キーが使われ、利用者とプロキシ間は仮想キーが使用される方式。 実現方法(例) |
・実キーをユーザーに渡す必要がないため、漏洩リスクが低い。 ・通信が必ずプロキシを通るためボトルネックになる可能性がある。 |
LiteLLM Proxyとは
LiteLLM Proxyは、多種多様なLLM APIを一つのインターフェースに集約する軽量なプロキシサーバーです。
最大の特徴は、AnthropicやGoogle Vertex AI、Azure OpenAIといった異なるプロバイダーのAPIを、すべてOpenAI形式のAPIとして呼び出せる点にあります。これを利用することで、アプリ側のコードを書き換えることなく、接続先のモデルを柔軟に切り替えられるようになります。
3つの主要な機能
- APIの統合: 100以上のモデルに対し、OpenAI SDKと同じ書き方でアクセス可能。
- 一元的なキー管理: 各サービスのAPIキーをサーバー側に隠蔽し、利用者には制限付きの「バーチャルキー」を発行・配布できます。
- コストと権限の制御: ユーザーやチームごとに予算上限(Budget)やレートリミットを設定し、利用状況をトラッキングできます。
ためしてみた
LiteLLM Proxyを活用し、LLMアプリケーションにはLLMプロバイダのキーを渡すことなく、LLMモデルを使用できることを確認します。
前提条件
- LiteLLM Proxyが動作していること。
本検証では公式サイトに記載のdocker composeを使用する方法で起動しました。また、今回の検証ではhttp://<dockerのホスト>:4000/uiからWEB UIにアクセスして操作をしています。
$ curl -O https://raw.githubusercontent.com/BerriAI/litellm/main/docker-compose.yml
$ echo 'LITELLM_MASTER_KEY="*****"' > .env
$ echo 'LITELLM_SALT_KEY="sk-*******"' >> .env
$ touch prometheus.yml
$ docker compose up- Geminiを使用するためのSAを作成し、jsonキーを取得していること。
- dockerを使用できる環境にあること。
仮想キーのテストとして、本検証ではNextChatをコンテナで起動して動作確認に使用します。
設定手順
まずはLiteLLM Proxyが、用意しているLLMプロバイダのモデル(今回はgemini2.0 flash)を使うためにモデルを登録します。
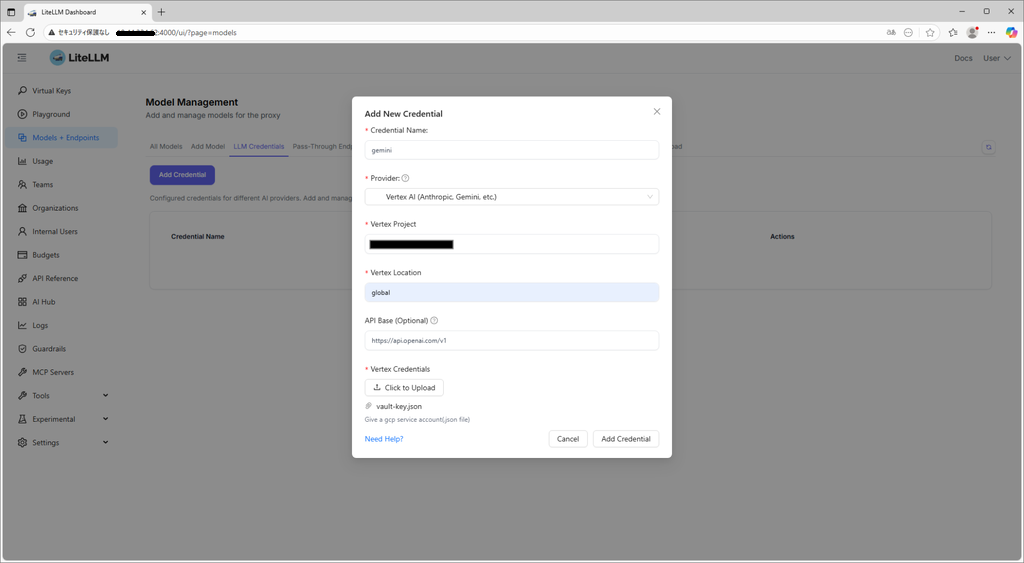
1. クレデンシャルの作成
Models + EndpointsからLLM Credentialsを選択し、Add Credentialを実行し、gcpのSAのjsonファイルを登録します。
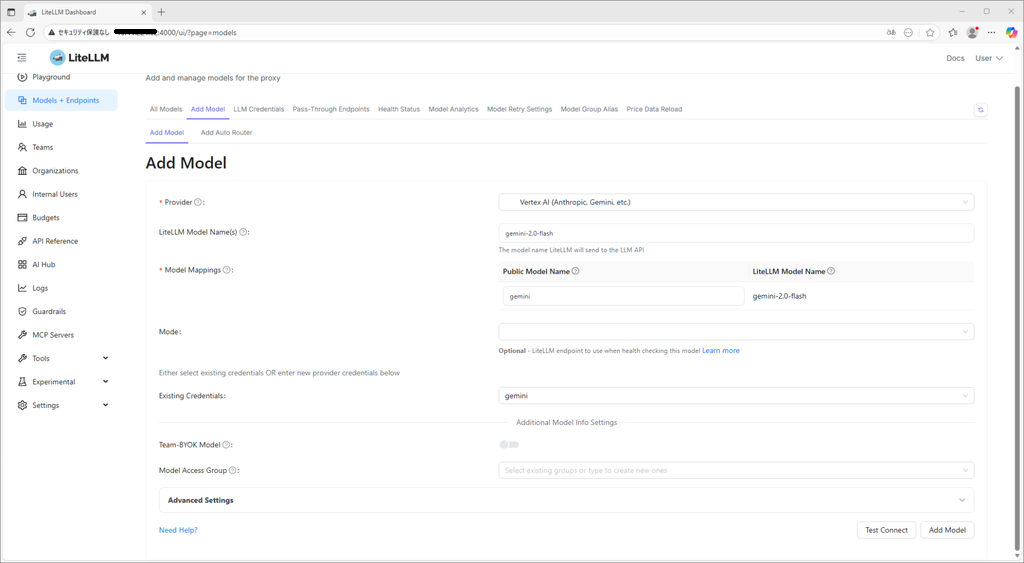
2. モデルの設定
Models + EndpointsからAdd Modelを選択し、先ほど作成したcredentialを使用してgeminiを登録します。
動作テスト
仮想キー(バーチャルキー)を払い出して、実際のLLMアプリケーションに設定し、プロバイダのキーを使用せずにモデルが使用できるかを確認します。
1. バーチャルキーの払い出し
まずはバーチャルキーを払い出します。LiteLLMでは組織やユーザーを作成し、それらにバーチャルキーを払い出すことができます。
今回はチームを作成し、そのチームで使用するバーチャルキーを払い出します。
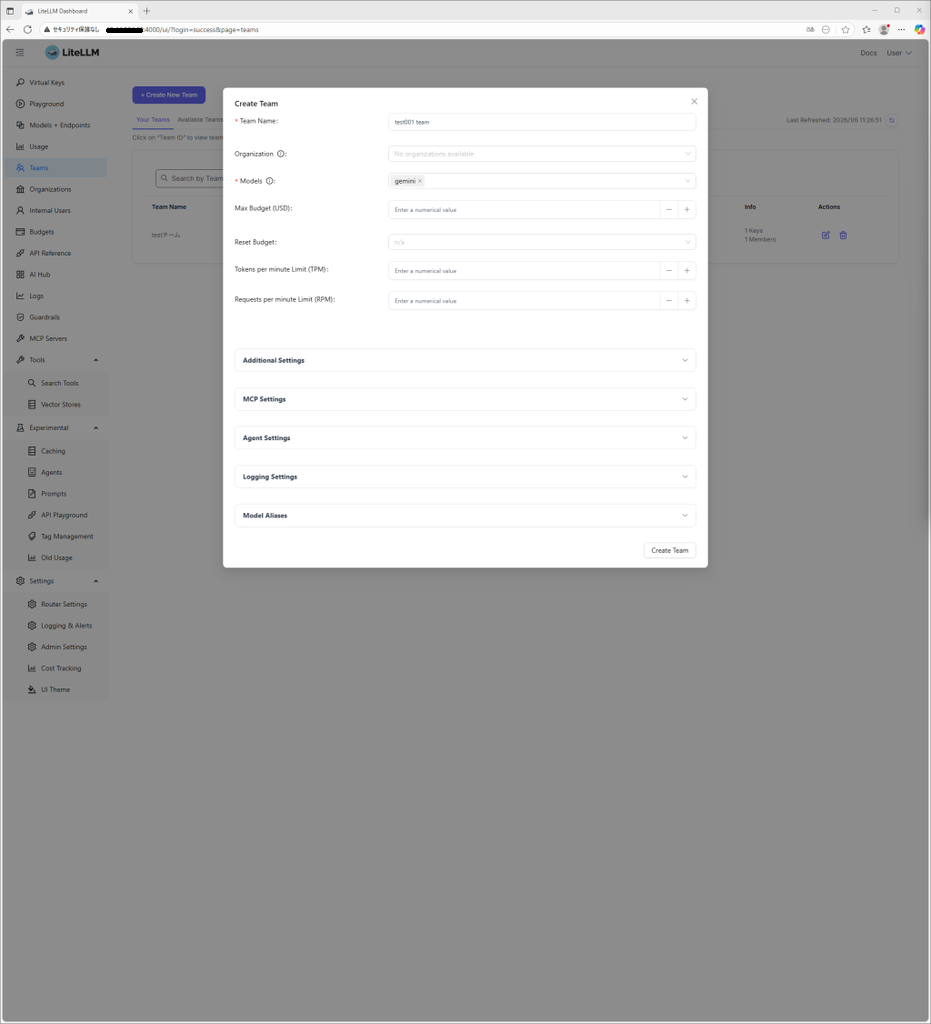
- チームの作成
Teams → Create New Teamからチーム名と使用を許可するモデル名を選択してチームを作成します。
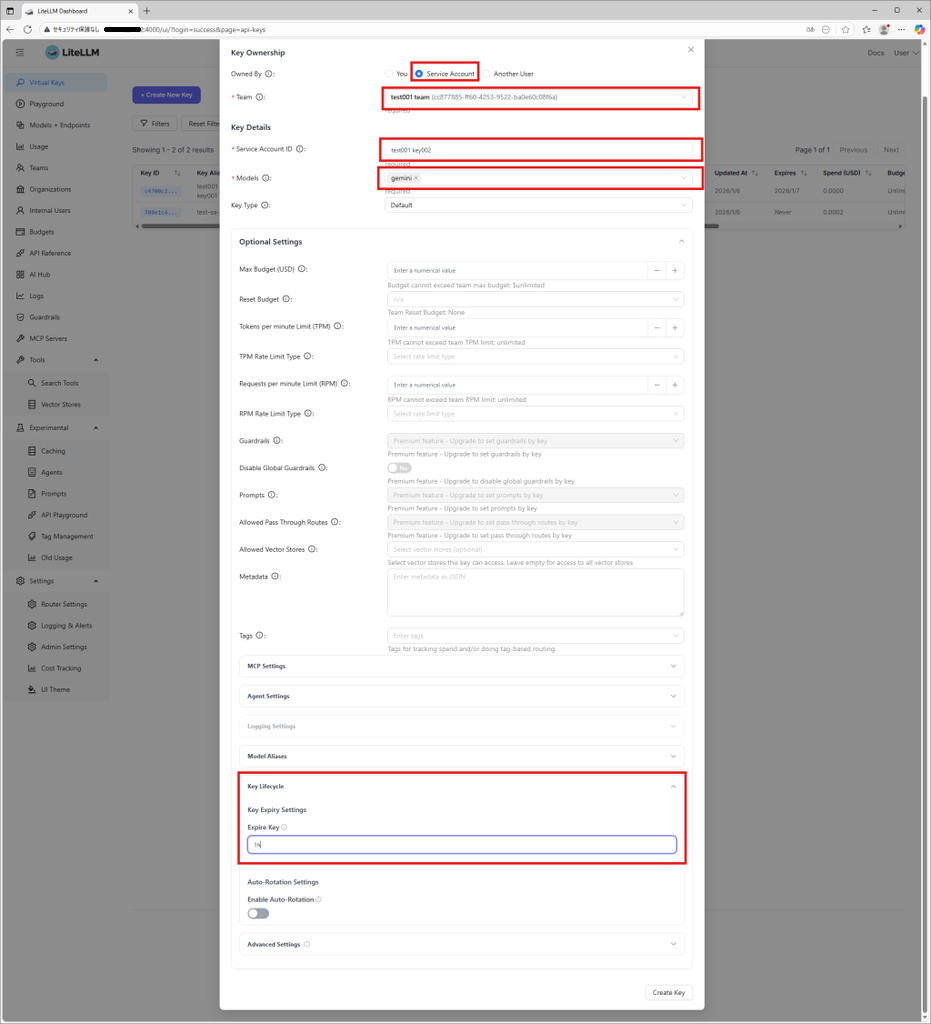
- キーの払い出し
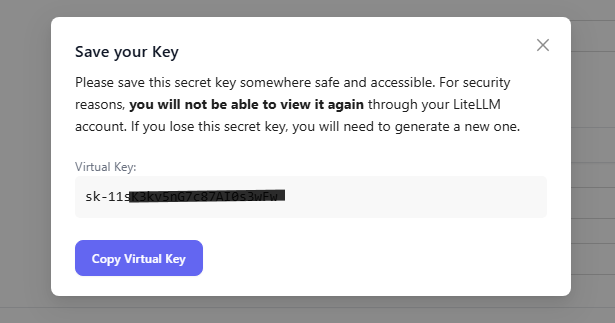
Virtual Keys -> Create New Keyから上記で作成したチームに紐づくバーチャルキーを作成します。Service Account IDは任意の名前を設定します。また、検証のため、Key lifecycleは1時間を指定しました。ほかにも利用量の制限や、TPM(Token per minute)の制限なども設定することが可能ですが、今回は使用しません。また一部機能は有償のライセンスが必要になることがあります。
Create Keyを押下すると、Virtual Keyが表示されます。このキーは再度表示できないので注意してください。コピー後に右上の×で閉じて問題ありません。
2. NextChatを用いたテスト
作成されたバーチャルキーの動作確認としてNextChatに設定します。
下記コマンドでNextChatを起動します。
$ docker run -d -p 3000:3000 -e OPENAI_API_KEY="<作成したバーチャルキー>" -e CUSTOM_MODELS="+gemini" -e DEFAULT_MODEL="gemini" -e BASE_URL="http://<litellm proxyのIPアドレス>:4000" yidadaa/chatgpt-next-webhttp://<dockerのホスト>:3000/にアクセスし、LLMが応答することを確認出来ました。
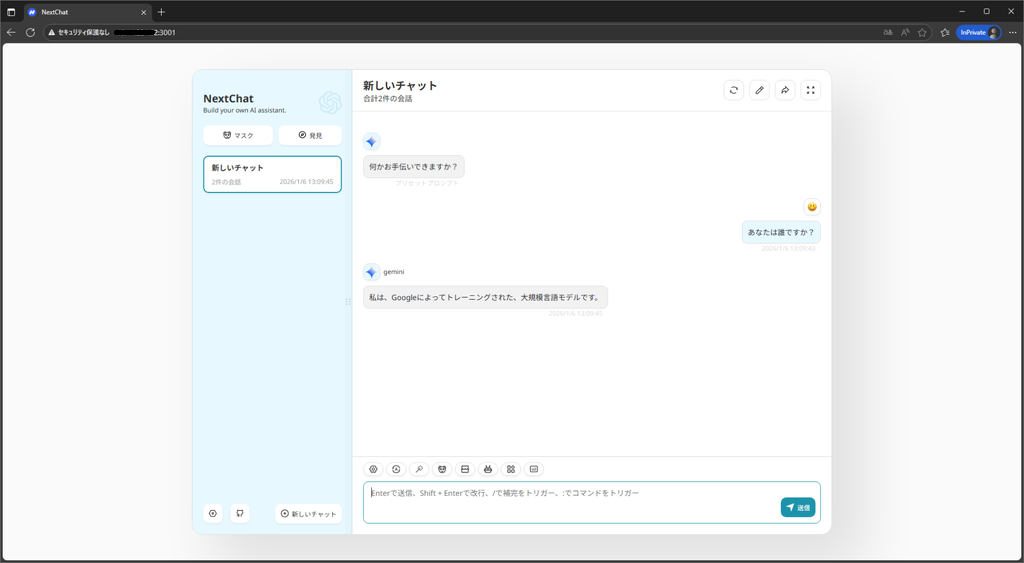
お気づきかと思いますが、geminiをOpenAIのAPI呼び出しと同様の方法で利用することができています。
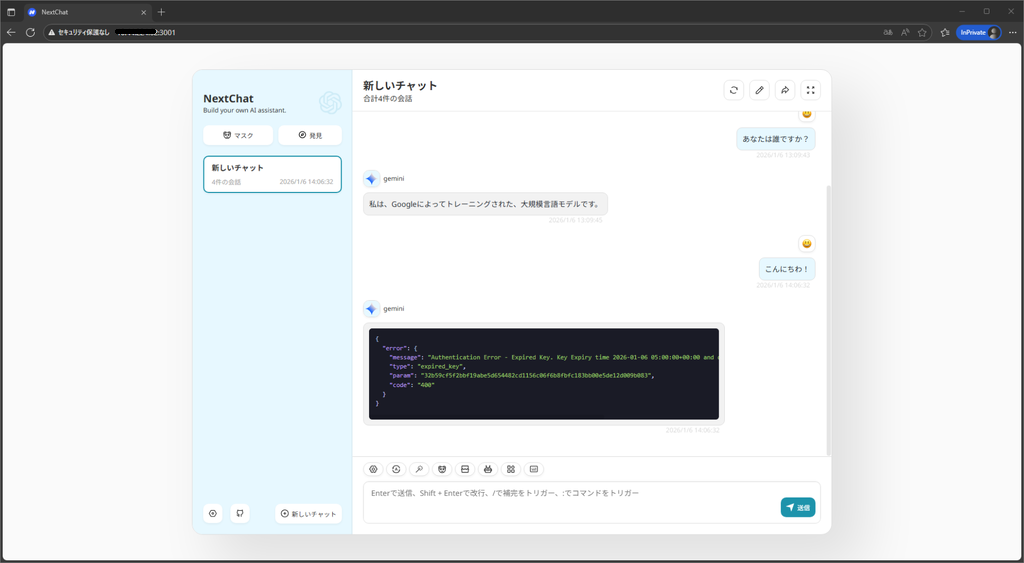
また、1時間後に再度確認すると、キーが無効化されていることを確認できます。
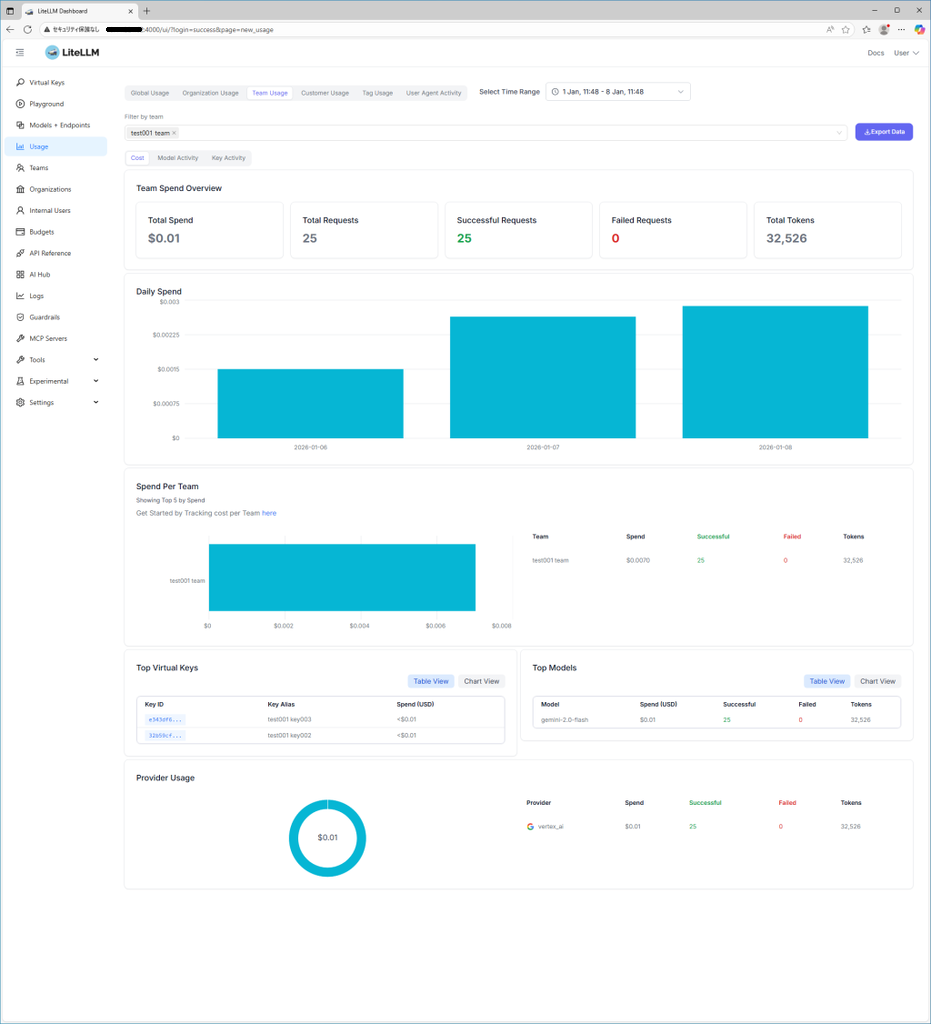
3. LiteLLMの可視化機能
LiteLLMではチームごとやバーチャルキーごとの使用状況を可視化することができます。また、今回は取り上げませんが、Langfuseと連携させることで、使用したチャットメッセージの解析や出力結果の評価、詳細なトレースによるデバッグなども可能になります。
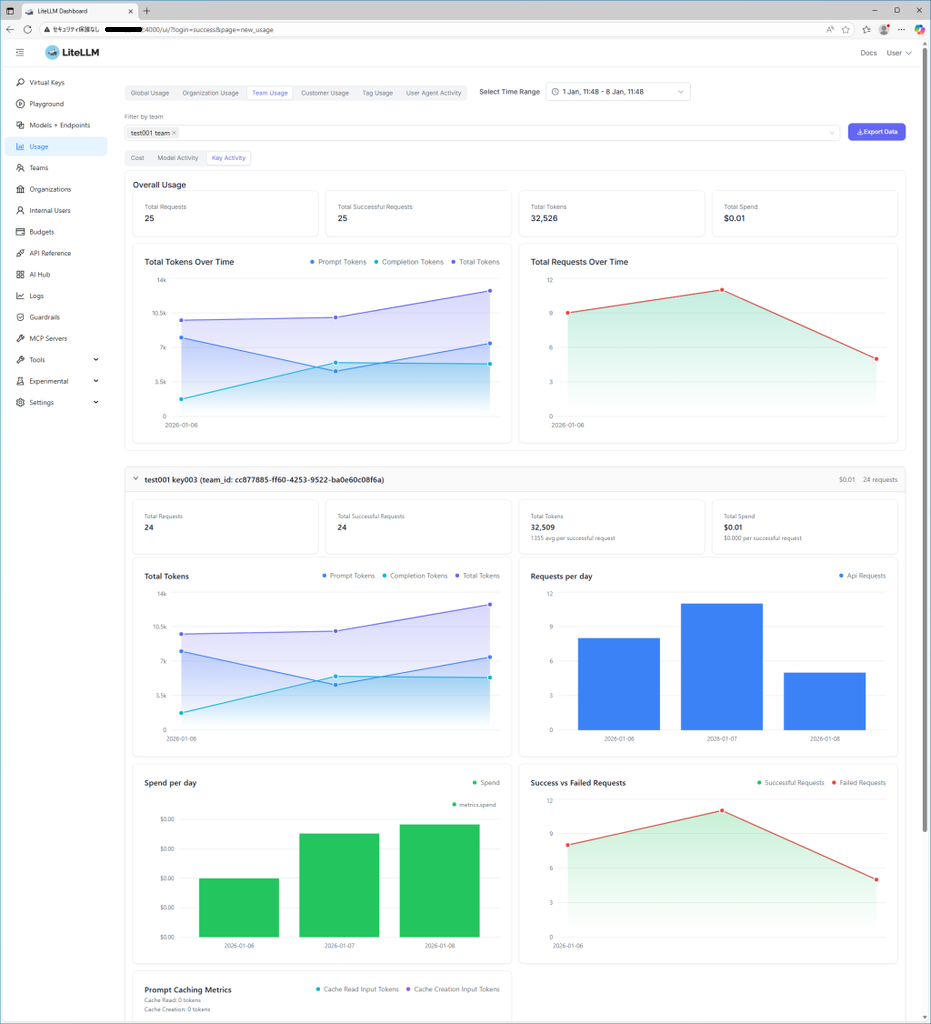
結果
仮想キーを用いることで、LLMを安全に利用できることを確認しました。APIエンドポイントをLiteLLM Proxyに集約することで、キーが漏洩した場合でも、サーバーへのアクセス制限によって被害を局所化できます。ただし、LiteLLM Proxyの可用性が、そのままAIアプリケーション全体のサービスレベルに影響するという点は、Vaultを用いた場合との重要な相違点です。
また、アプリケーションからのAPI呼び出しはOpenAI互換となるため、Gemini固有の高度な機能は利用できません。一方で、LLMプロバイダに依存しないキー管理が可能になるため、Vertex AIやOpenAIなど、複数のプロバイダのAPIキーを一元的に管理できるというメリットがあります。
まとめ
社内向け開発環境の構築にあたり、LLMのAPIキーを安全に提供する方法を比較検討した結果をまとめました。
弊社では、最新機能を常に活用することを重視し、Vaultを利用してプロバイダ固有のキーを直接払い出す方式を採用することに決定しました。
しかし、必ずしも最新機能が必要ではないケースでは、仮想キーを用いることで、ユーザーごとの利用状況を容易に可視化できるため、適材適所での使い分けを検討する余地はあります。
弊社ではInnovation Showcaseにて生成AIをテーマとした展示やデモを実施しています。ぜひ直接ご体験いただき、より具体的なお話ができればと存じます。
また、公開可能なデータを利用して、お客様が直接体験することができるデモ環境もご用意していますので、一緒に試すことから始めませんか?
お問い合わせやご相談は、下記問い合わせフォームまたは担当営業までお寄せください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


