
AIを活用したアプリケーションやサービスは日々増加し、これらを裏側で支えているのが生成AIの推論(Inference)サービスです。AIがビジネスや社会のあらゆる分野に浸透し始めた現在、推論基盤の重要性は更に高まると予想されています。2025年11月に開催された KubeCon + CloudNativeCon North America 2025 のキーノートでも、この推論基盤が大きなテーマの一つとして取り上げられました。本記事では推論機能を強化する、llm-dについてご紹介します。

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
llm-d とは
LLM(大規模言語モデル)に対する同時アクセスが増えると、LLMのパフォーマンス指標である、最初のトークンが生成されるまでの時間(TTFT : Time to First Token)や、1秒間に生成されるトークンの数(TPOT : Time Per Output Token)が低下するおそれがあります。これは、GPUの処理性能が限られているためです。これらの指標を維持するためには、GPU数を増やしてLLMの推論を分散処理する必要があります。従来のウェブアプリケーションではラウンドロビンやリーストコネクション等の方式を利用して負荷分散対象を選択しますが、LLMを分散処理する場合これらの方式ではGPUリソースを効率よく利用することができません。そこで求められるのがスケールアウト可能な推論プラットフォームであり、llm-dはKubernetes上で推論機能のスケールアウトを可能にします。
llm-dは Red Hat、Google、NVIDIA等が主導して開発を進めている、Kubernetesネイティブな大規模言語モデル(LLM)の分散推論フレームワークのオープンソースプロジェクトであり、特にエンタープライズ環境での「大規模かつ効率的なAI運用」のため、近年、急速に注目を集めています。LLMの推論機能を提供するライブラリであるvLLMベースの推論ワークロードをKubernetes上で管理し、Inference Schedulerと呼ばれる機能により、複数の推論インスタンスに対してリクエストを適切に振り分けられるよう設計されています。推論インスタンスに対する負荷分散には、次世代の Kubernetes Ingress である Gateway API を拡張した、Gateway API Inference Extension (GIE) の実装である Inference Gateway を利用します。推論インスタンスであるvLLMはPodとして実行され、vLLM間でKVキャッシュを共有するためにNIXL(NVIDIA Inference Xfer Library)等が利用されます。また、KVキャッシュを効率的に利用するためにLMCacheを利用することも可能です。
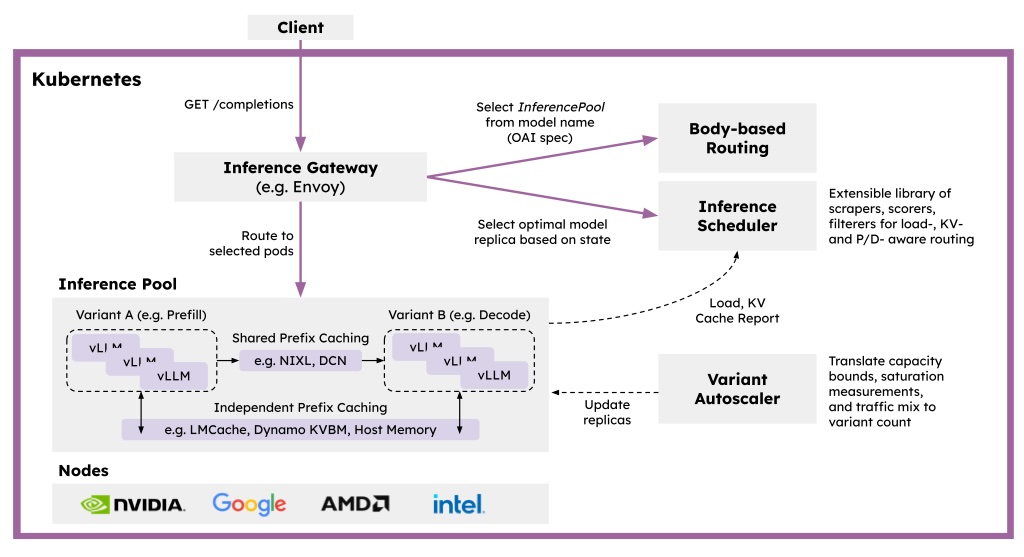
(出典 : https://llm-d.ai/docs/architecture)
llm-dコミュニティが提供するWell-Lit Paths
Well-Lit Paths は直訳すると「よく照らされた道」を意味し、llm-d において推奨される利用方法や、本番運用を想定して検証済みの構成パターンをまとめたものです。現在、4 種類の Well-Lit Paths が提供されています。(High performance distributed inference on Kubernetes with llm-d)
Intelligent Inference Scheduling
Inference Gatewayの背後にvLLM Podを配置します。Inference Schedulerは入力トークンの先頭部分のKVキャッシュ(プリフィックスキャッシュ)を持つvLLM Podにリクエストを転送します。Inference SchedulerはvLLMのKV-Eventsデータに基づいて転送先を決定します。過去のリクエストにより生成されたKVキャッシュを利用することが可能となるため、応答遅延を削減し、スループットを向上させます。また、スケジューリングポリシーは柔軟に設定することが可能です。
Prefill/Decode Disaggregation
LLMの推論実行時は一般的にはPrefillとDecodeと呼ばれる処理が同一のGPUで実行されます。Prefillは入力トークンに対して大規模な行列演算を行いKVキャッシュを生成する処理であり、GPU処理性能に大きく依存します。一方、Decodeは生成済みのKVキャッシュを参照して、トークンを逐次生成する処理であり、計算量自体は小さいもののKVキャッシュへの高速なアクセスが求められます。これら特性の異なる処理をそれぞれ別々のGPUに分離して実行することで、それぞれに最適化されたGPUリソースを割り当て、推論全体の効率化を図ることが可能です。
Prefill向けPodとDecode向けPodはvLLMワークロードとして実行され、KVキャッシュを転送する必要があるためNIXLが利用され、複数ノードで構成する場合、ノード間はRoCEv2やInfiniBandのような低レイテンシ・高帯域なネットワークで接続する構成が一般的です。
Wide Expert-Parallelism
DeepSeek-R1のような非常に大規模なMixture-of-Expert (MoE)モデルを複数のGPUに分散配置し、Data ParallelismとExpert Parallelismによりスケールアウトすることで、エンドツーエンドのレスポンスを高速化します。
Tiered Prefix Cache
通常GPUメモリー上で処理されるプリフィックスキャッシュをCPUメモリーやローカルディスク、共有ディスク等にオフロードして再利用することで、プリフィックスキャッシュの再利用を増やし、TTFTを短縮します。上記の3つのPathと併用可能です。
Red Hat OpenShift AI 3.0 での実装
Red Hat OpenShift AIは、Red Hat OpenShift Container Platform上でAI/MLの開発・利用を推進するための機能を提供し、MLOpsプラットフォームの構築を可能にするソフトウェアです。従来からvLLMを利用した推論機能を利用することは可能でしたが、OpenShift AI 3.0 からllm-dアーキテクチャを用いた分散推論がサポートされました。
Serving runtimeによるllm-dの利用
Red Hat OpenShift AI 3.0では、モデルデプロイ時に選択可能なServing runtimeとして「Distributed inference Server with llm-d」が追加されており、このServing runtimeを利用することで、 KServe のカスタムリソースである LLMInferenceService によるモデルのデプロイが可能となっています。
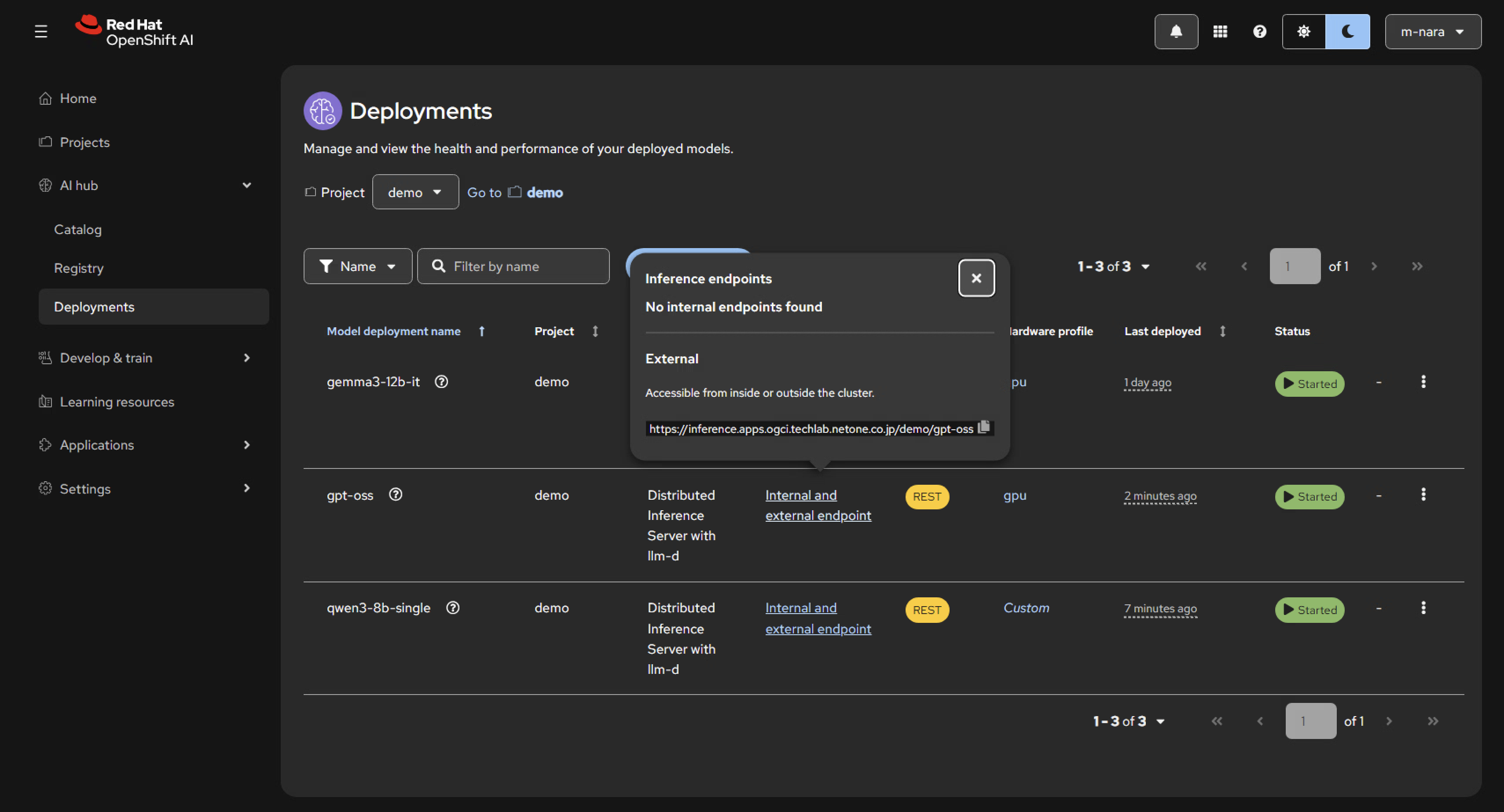
デプロイが完了すると、External endpointとしてURLが利用可能になります。このURLの実体はInference Gatewayであり、URLに対するリクエスト処理はopenshift-ingressネームスペースに存在するEnvoyベースのrouter podによって行われます。
llm-d Serving Runtimeの実体
作成したDeploymentはOpenShift上ではLLMInferenceServiceとして確認することができます。LLMInferenceServiceによって管理されるリソースを確認すると、vLLM Podを起動するためのDeployment(gpt-oss-kserve)や、Endpoint Picker (EPP)として機能する gpt-oss-kserve-router-scheduler Deploymentが作成されています。また、GIEに対する設定としてHTTPRoute、InferencePool、DestinationRule等のリソースが作成されています。
$ oc get llminferenceservices.serving.kserve.io NAME URL READY REASON AGE gemma3-12b-it https://inference.apps.ogci.techlab.netone.co.jp/demo/gemma3-12b-it True 26h gpt-oss https://inference.apps.ogci.techlab.netone.co.jp/demo/gpt-oss True 3m44s qwen3-8b-single https://inference.apps.ogci.techlab.netone.co.jp/demo/qwen3-8b-single True 9m38s $ oc tree llminferenceservices.serving.kserve.io gpt-oss NAMESPACE NAME READY REASON STATUS AGE demo LLMInferenceService/gpt-oss True Current 4m40s demo ├AuthPolicy/gpt-oss-kserve-route-authn - - 4m38s demo ├Deployment/gpt-oss-kserve - - 4m38s demo │ ReplicaSet/gpt-oss-kserve-94547cf4f - - 4m38s demo │ Pod/gpt-oss-kserve-94547cf4f-7fqcx True Current 4m38s demo │ Pod/gpt-oss-kserve-94547cf4f-bt5fs True Current 4m38s demo ├Deployment/gpt-oss-kserve-router-scheduler - - 4m38s demo │ ReplicaSet/gpt-oss-kserve-router-scheduler-7d4fdf9bcd - - 4m38s demo │ Pod/gpt-oss-kserve-router-scheduler-7d4fdf9bcd-6hrrf True Current 4m38s demo ├DestinationRule/gpt-oss-kserve-scheduler - - 4m38s demo ├DestinationRule/gpt-oss-kserve-workload - - 4m38s demo ├DestinationRule/gpt-oss-kserve-workload-svc - - 4m38s demo ├HTTPRoute/gpt-oss-kserve-route - - 4m38s demo ├InferenceModel/gpt-oss-inference-model - - 4m38s demo ├InferencePool/gpt-oss-inference-pool - - 4m38s demo │ Service/gpt-oss-inference-pool-ip-19a8eb77 - - 4m38s demo │ EndpointSlice/gpt-oss-inference-pool-ip-19a8eb77-8px8k - - 4m38s demo ├Role/gpt-oss-epp-role - - 4m38s demo ├RoleBinding/gpt-oss-epp-rb - - 4m38s demo ├Secret/gpt-oss-kserve-self-signed-certs - - 4m38s demo ├Service/gpt-oss-epp-service - - 4m38s demo │ EndpointSlice/gpt-oss-epp-service-zsq7s - - 4m38s demo ├Service/gpt-oss-kserve-workload-svc - - 4m38s demo │ EndpointSlice/gpt-oss-kserve-workload-svc-zmxbf - - 4m38s demo └ServiceAccount/gpt-oss-epp-sa - - 4m38s
Inference Gateway (Envoy)が受信した推論リクエストは、HTTPRouteの定義に基づいて評価され、InferencePoolが選択されます。Inference GatewayはExternal Processingを利用して、InferencePoolで指定されているEPPに転送先を問い合わせます。EPPはvLLM Podのメトリックを参照し、プリフィックスキャッシュ情報等を基にスコアリングを行い、推論リクエストを処理すべきvLLM PodをEnvoyに回答します。Envoyが指示されたvLLM Podに推論リクエストを転送することで、推論ワークロードに適した負荷分散を実現します。
$ oc get pod -l app.kubernetes.io/name=gpt-oss NAME READY STATUS RESTARTS AGE gpt-oss-kserve-94547cf4f-7fqcx 2/2 Running 0 5m4s gpt-oss-kserve-94547cf4f-bt5fs 2/2 Running 0 5m4s gpt-oss-kserve-router-scheduler-7d4fdf9bcd-6hrrf 1/1 Running 0 5m4s
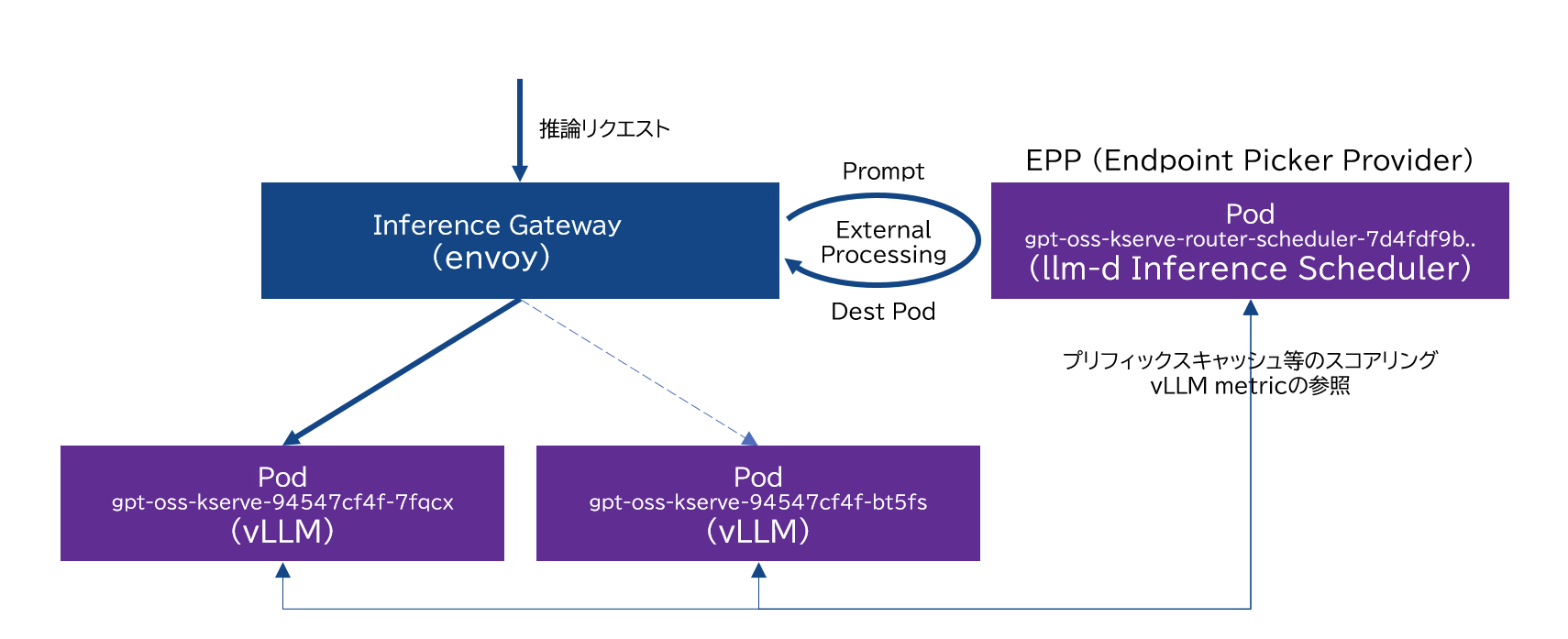
EPPとして機能する gpt-oss-kserve-router-scheduler Podの起動時の引数には、デフォルトで以下のようなEndpointPickerConfigが挿入されています。このEndpointPickerConfigは様々なカスタマイズにより、vLLM Podを決定する方法を柔軟に設定することが可能です。
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: single-profile-handler
- type: prefix-cache-scorer
- type: load-aware-scorer
- type: max-score-picker
schedulingProfiles:
- name: default
plugins:
- pluginRef: prefix-cache-scorer
weight: 2.0
- pluginRef: load-aware-scorer
weight: 1.0
- pluginRef: max-score-picker
llm-dによる効果の測定
弊社ラボ環境でNVIDIA AIPerfをベンチマークツールとして利用してllm-dの有無による効果を測定しました。測定環境はNVIDIA RTX PRO 6000が利用可能なサーバーにOpenShift 4.20.8とOpenShift AI 3.0をインストールし、vLLM Podを8個作成し、OpenShiftのServiceリソースにより分散した場合と、llm-dを利用した場合のTTFT(Time to First Token)とITL(Inter Token Latency)の99パーセンタイル(p99)と90パーセンタイル(p90)をそれぞれ3回測定し、各パーセンタイル値について3回分の平均を比較しました。
|
|
TTFT (ms) [p99] |
TTFT (ms) [p90] |
ITL (ms) [p99] |
ITL (ms) [p90] |
|---|---|---|---|---|
|
llm-d |
181.09 |
73.24333333 |
35.50666667 |
34.97333333 |
|
Service |
693.4166667 |
124.7466667 |
32.22333333 |
31.38333333 |
TTFTの値に関しては、99パーセンタイル、90パーセンタイルどちらを見ても、Serviceに比べてllm-dを利用した場合のほうが短時間で最初のトークンを返せていることがわかります。この結果はllm-dがリクエストの特性やバックエンドのvLLMの状態を考慮してルーティングしたことでTTFTの短縮につながったと考えられます。特に、プリフィックスキャッシュを利用できる場合、キャッシュヒット率の向上がTTFTの改善に寄与した可能性が高いと考えられます。
まとめ
AIアプリケーションの増加に伴い推論機能のニーズは高まり、データ主権や地政学的リスクの軽減を目的としてローカル環境における推論基盤の必要性も高まっています。このような背景から、推論に適した新たなハードウェア、ソフトウェアが登場しています。今回はその中で推論機能を強化するllm-dをご紹介しました。llm-dの動作を含め、AIアプリケーションのためのソフトウェア、オンプレのサーバーやネットワーク、ストレージについてラボでのデモンストレーションも可能ですので、気になる方は、ぜひ、弊社担当にご連絡ください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


