
はじめに
フィジカルAIとは、センサーで周囲の物理世界を認識し、意思決定を行い、実際の操作や移動によって価値を生み出すAIシステムの総称です。環境の知覚→推論・意思決定→制御というループをリアルタイムに回し、これまで人が担ってきたタスクを自律的に遂行することを目指します。NVIDIAも、現在のGenerative AI、次に来るAgentic AIのさらに先に「Physical AI」の時代が到来すると提唱しています。
従来の生成AIはサイバー空間のデータを中心に学習・推論してきましたが、フィジカルAIでは物理空間のデータを瞬時に取り込み、サイバー空間からフィジカル空間へ遅延なく制御を返す必要があります。そのため、要求されるインフラ(ネットワーク、エッジコンピューティング、時刻同期、セキュリティ・安全設計など)はこれまでと大きく異なります。
本ブログではフィジカルAIの中でも、人間(専門家・熟練者)の行動を観察し、そのパターンを模倣して学習し、自律制御を実現する「模倣学習(Imitation Learning)」に注目します。前編では最新トレンドと弊社の実験環境をご紹介し、後編では実験で洗い出した課題とその解決アーキテクチャ、フィジカルAI時代に求められるインフラ要件を考察します。

- ライター:伊藤 千輝
- ネットワンシステムズに新卒入社し、IoT/AIの技術の検証/ソリューション開発に従事。また、最新のAI技術をウォッチするために産学連携の取り組みを推進。
現在は製造業をターゲットにスマートファクトリーに向けたデータ収集・集約・加工・保存・活用のためのデータハンドリング基盤の提案導入支援。実際の顧客データを用いた分析支援を行う。
休日は弊社がスポンサーとして支援する大分トリニータをサポーターとして応援。
目次
フィジカルAIの実現に向けて
エージェントAI(AgenticAI)の次はフィジカルAI
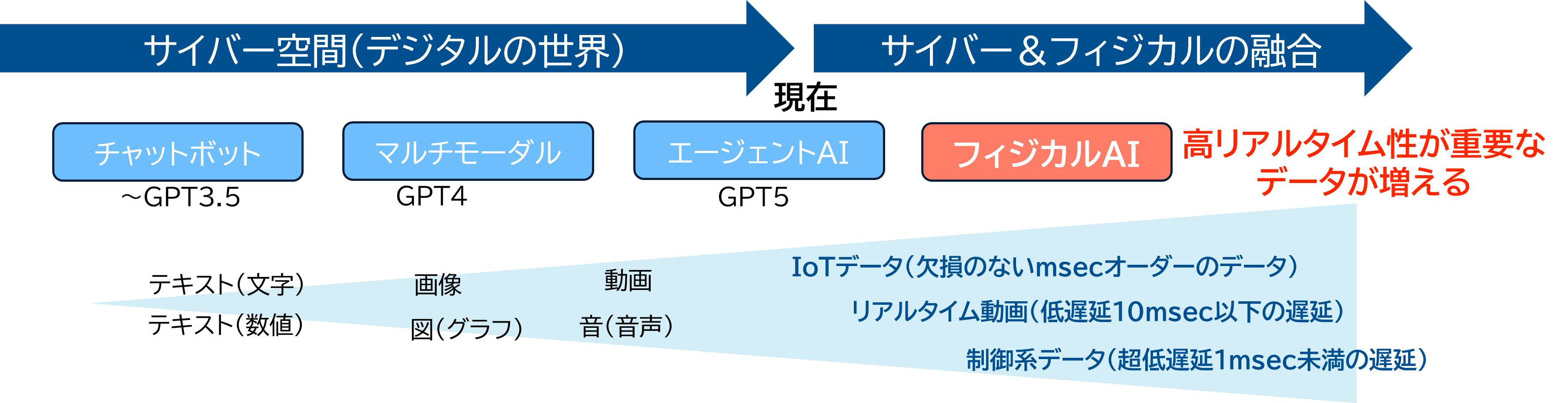
生成AIは登場以降、文章だけでなく、半構造化データ(PDFや表計算)や非構造化データ(画像・動画・音声)まで、幅広いデータを扱えるようになりました。
近年は、人を支援するエージェントAIに注目が集まっています。目標を与えると、自律的に状況を理解し、計画を立て、必要なツールを使い、学習しながら作業を反復してタスクを前進させるタイプのAIです。エージェントAIの概念は広範ですが、RAGやファインチューニングで企業・業種ごとに最適化されたLLMベースのソフトウェアエージェントは、すでに実用段階にあります。
さらに、物理世界で人の動きや意図、環境を自律的に理解して行動する、仮想空間のアバターやロボティック・エージェントに関する実証や事例も登場しています。こうした流れを受け、次のステージとしてフィジカルAIの時代が到来すると見込まれます。
フィジカルAIで扱うデータは高リアルタイム性が重要になる
フィジカルAIが扱うデータは、従来の多品種・大量に加えて、より高いリアルタイム性が求められます。例えば模倣学習では、画像やIoTセンサから環境をリアルタイムに取得・認識し、AIが次の動き(ロボットであれば次の座標やグリッパ位置)を推論して制御するサイクルを数ミリ秒単位で繰り返します。そのため、従来のプロンプト応答型の時のような処理速度では追いつかず、瞬時の推論や遅延のない制御が必須となり、ソフトウェアだけでなくネットワークやコンピューティングなどインフラの影響が非常に大きくなります。
ネットワンシステムズはSIerとして、フィジカルAIの時代を見据え、AI開発者やロボットベンダー間に横たわるインフラ要件を含めた検証やアーキテクチャ設計を推進しています。低遅延ネットワークやエッジコンピューティングなどを含む総合的な設計・検証に取り組み、現場で「止まらず安全に動く」AIシステムの実装を目指しています。
フィジカルAIの自律制御ユースケース

製造
-
部品の把持・挿入・ねじ締め・コネクタ接続などの精密組付け
-
ハーネス配線やケーブル取り回し(柔軟物の扱い)
-
潤滑剤・接着剤の塗布、検査時のカメラ・照明の当て方
-
治具交換・段取り替え、位置ずれのリカバリ動作
-
二腕協調(蓋開閉→取り出し→再閉→整列などの長尺タスク)
-
外観検査の「勘所」(角度・光量調整、対象の持ち替え)
物流
-
多品種ピッキングの把持パターン、仕分け・棚入れ
-
梱包・封緘・テーピング、緩衝材の詰め方
-
パレタイジング/デパレタイジングの段取りと積み方
カスタマーサービス
-
接客ロボの案内・誘導ジェスチャ・会話タイミングの模倣
-
配膳ロボの受け渡し姿勢、混雑時の回避行動
-
清掃ロボの拭き取りパターン、巡回ルート最適化
-
行列整流や発券補助の対話+動作
医療
-
手術支援ロボット
-
看護補助の物品受け渡し
-
施術補助の手元操作
-
リハビリ支援ロボ(セラピストの誘導を模倣)
-
介護支援ロボット
※医療領域は安全・規制・体制の厳守が前提
模倣学習で「教える」AIロボットを現場に
模倣学習とは?
フィジカルAIのユースケースとしての「模倣学習」
模倣学習は、カメラや各種センサで観測した「環境の状態」を入力に、その場でとるべき「アクション(手先位置・姿勢、速度、グリッパ開閉など)」を出力するモデルを、人間の教示データで学習する手法です。人が行った動作(操作ログや軌跡、動画など)をそのまま学習データにし、推論時はモデルが自律的に次の行動を予測し制御します。
これまでロボットのAIによる自律制御は、「試行錯誤と報酬」から最適行動を自律的に学習する手法で試行錯誤してAIが賢くなる強化学習の適応が一般的でした。そこに、生成AIでブレイクスルーを迎えたTransformerモデルを採用したAIによるロボットの自律制御として模倣学習が注目されております。最近では強化学習と模倣学習を組み合わせて、模倣学習で得られた初期の効率的な行動に、強化学習による自律的な最適化を加えることで、両者の長所を活かす手法も開発されてきています。
模倣学習はルールや教示点を固定的に与えるダイレクトティーチングに比べ、ロボット同士の協調や状況依存の段取りといった複雑な動作を身につけさせやすいのが特長です。また、ハンドティーチのように「決め打ちの軌道」に依存しないため、物体位置や背景が少し変わっても、観測から判断して対応できる分、環境の変化に強いという利点があります
世界に衝撃を与えたALOHA
模倣学習の代表例として、米スタンフォード大学のグループが公開した「ALOHA」プロジェクトがあります。ALOHAは、低コストで構築できる二腕ロボットのテレオペレーション環境と、そのためのハード設計・ソフトウェア・データ収集パイプラインをオープンにする取り組みです。人間がコントローラーやハンドトラッキングでロボットを遠隔操作し、その際の画像・センサ・関節角度などの軌跡を記録して学習データに変換、学習後はモデルが環境を見ながら次のアクション(手先位置・姿勢、グリッパ操作など)を自律的に推論・実行します。
ALOHAでは、生成AIでブレイクスルーを迎えた仕組みであるTransformerモデルを活用したAction Chunking with Transformer(ACT)モデルを採用しています。細かい「1ステップごとの動作」、例えば、①ロボットがコップをつかむまでの動作、②コップをつかんだ後の移動する動作、③コップを置く動作などを「塊(Chunk)」として扱い、 Transformerでその順序を学習し、Chunk列を予測・生成する手法で長期依存や長時間タスクを効率よく学習・実行するようにできています。
これを応用して、単純な二腕ロボットのタスクだけではなく、自律移動ロボットに家事(料理や皿洗い)をさせるなど複雑なタスクをロボットにさせる研究やデモ動画が多く公開されております。
Innovation Labでの模倣学習の実装
模倣学習を体験する実験キットDobot X-trainer
模倣学習実験キットとして、DOBOT社の開発する協働ロボットを用いたデータ収集・学習・推論が可能な実験キットを展示しております。
2本のDOBOT社のロボットアームとロボットコントローラー、人間が教示する用のコントローラー、intel社製 Realsenseカメラ3台、それらを固定する台すべてがキットとなっています。
また、実行プログラムも一緒に提供されており、Action Chunking with Transformer (ACT)を採用しております。
X-trainerの模倣学習の仕組み
模倣学習はデータ収集・学習のプロセスと推論動作のプロセスに分かれます。
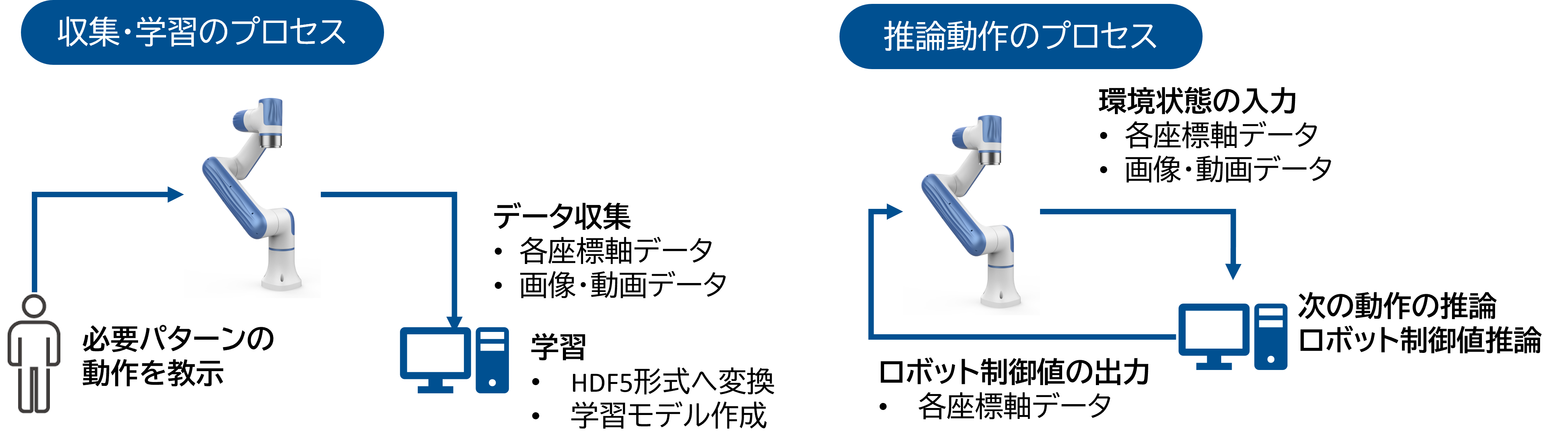
データ収集・学習のプロセス

人が2本の教示用コントローラーを動かすと連動してロボットアームも動く仕組みになっています。
データ収集モードに入ると、ロボットが動いているときの各座標軸のデータ、3つのカメラ(ロボットの手元の右、ロボットの手元の左、上から俯瞰した中央の画角)のデータを取得します。
これを何度か人が繰り返して学習用のデータを取得します。複数回繰り返して取得したデータをHDF5形式へ変換し学習モデルを作成します。
推論動作のプロセス

学習モデルが作成されたら推論モードで推論を行います。現在の環境状態を各座標軸のデータ、3つのカメラのデータをリアルタイムに取得し、その状態における次の動きを推論しロボットに制御値を連続的に返す仕組みになっております。
推論は1秒間に10回から30回連続的に繰り返し、リアルタイムにAIが自律制御する仕組みになっております。
2本のアームが協調してコショウの蓋を開けるタスク
次の動画は、約100回の人間による操作で収集したデータを用いて学習したAIモデルが、実際に推論・動作している様子です。2本のアームが協調して、コショウ瓶の蓋を開けようとします。
従来のティーチングでは、コショウ瓶の初期位置を固定する必要がありましたが、模倣学習では環境を認識できるため、机上の瓶の位置が多少ずれても位置を特定して取りに行くことが可能です。
また、蓋の細かな爪を開けようとして一度失敗しても、まだ開いていない状態をその場で認識し、直ちに再度開けに向かう様子が見られます。さらに、一回では開け切れない場合には、自ら瓶の姿勢を調整して、最終的に蓋を完全に開け切ることができました。これは、データ収集時の人間の動き(やり直し、位置修正、姿勢調整)が学習データに含まれていたため、モデルが状態に応じた回復動作を自律的に実行できていることを示しています。
まとめ
本ブログでは、フィジカルAIが「知覚→推論→制御」をリアルタイムに回して物理世界で価値を生むという本質と、生成AI/エージェントAIの先にある潮流であることを整理しました。なかでも模倣学習は、熟練者のデモから短期間で自律行動を実現でき、ダイレクト/ハンドティーチでは難しい長尺・協調タスクや環境変動への強さを発揮します。
ALOHAやACT(Action Chunking with Transformer)の枠組みは、長期依存を扱いながら現場で再現しやすいデータ収集・学習フローの良いリファレンスです。Innovation Labの二腕ロボによる「コショウ瓶の蓋開け」では、瓶位置のずれに対応し、失敗後のやり直しや姿勢調整まで自律的に実行できることを確認しました。
一方で、現場実装の成否はアルゴリズムだけでなく、低遅延ネットワーク、エッジ推論最適化、時刻同期、セーフティ/セキュリティ、データ品質といったインフラと運用設計に大きく依存します。ここにSIの設計力・運用力が問われます。
後編のブログでは模倣学習の技術的課題と解決策を上げて、フィジカルAI時代に必要なインフラやアーキテクチャをご紹介します。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


