
現代のビジネス環境において、データ分析は必須の取り組みとなりつつあります。
社内外の情報含めビジネスのあらゆる側面がデータ化されています。このデータから価値ある情報を導き、ビジネスに有効となる意思決定につなげることが企業の競争優位性を左右します。 AIの進化とともにますます重要となるデータをどう活用するか、が求められています。
しかし、データ分析はどのような製品を用いるのがよいのか?効果的な進め方は?など、多くの悩みがあります。
本ブログでは、市場を取り巻くデータ分析のトレンドやデータ活用によるビジネス変化の解説、データ分析の進め方とIT技術の紹介、当社の取り組み内容をご紹介します。

- ライター:西嶋 孝夫
- 営業部門にてサービスプロバイダー・金融業界のアカウントを担当した後に現イノベーション推進部に異動。
事業拡大に向け新たなビジネス領域の開拓、GXビジネスの企画、イノベーションセンターを活用した他社/大学院との共創ビジネス、イントレプレナーシップを推進。
テクノロジー視点とビジネス視点を融合させた企画を担当。
保有資格:中小企業診断士 ITコーディネータ
目次
はじめに
近年、AI技術が注目を浴びるなか、AI活用の前段階のデータ処理が重要視されています。AI技術による業務の効率化、高度化、さらには新商品、新サービスの実現に向けデータは切っても切り離せない要素です。企業がDXを推進する中、組織の意思決定や戦略立案などにさまざまなデータを活用し、客観的な根拠に基づいた判断を行いたい(データドリブン経営の実現)という声は多くのお客様から寄せられています。
しかし、データドリブン経営をどのように実現するのか?となると、問題・課題が多いことが実情です。データの専門家を配置し、専用ツールを導入しても実現は難しいのが、この分野の特徴です。
ネットワークインテグレータの当社では、データ分析基盤は当然のことながら、ネットワーク上を流れるデータそのものを重要な「ICTインフラ」として捉え、活用することがビジネス成長の鍵を握っていると考えています。本ブログでは、データの流れから価値を生み出すためのアプローチを解説。単なる技術紹介に留まらず、最新トレンド、データ分析の進め方、実際のユースケース、そして具体的な支援内容まで、実践的な情報をお届けします。
データ分析の最新トレンドとビジネスにもたらす変化
トレンド
近年のデータ分析は、生成AIや大規模言語モデルとの連携が大きなトレンドになっています。例えば「分析の8割は前処理」という言葉は、データ分析に携わったことがある方なら一度は聞いたことがあるでしょう。従来は前処理に多くの時間と労力を割いてきましたが、ツールやAIの進化により、その負担は徐々に軽減されつつあります。
更に、自然言語やGUI操作でデータの変換処理を自動生成したり、データ統合を自動化する仕組みが急速に進化しています。 これにより、「どう分析するか」「どんな仮説を立てるか」といった本来の業務により多くの時間を割けるようになりました。
データ活用がもたらす変化
こうした技術進化は様々な業界に大きな変化をもたらしています。
例えば製造業の現場では、IoTセンサーや生産ラインから取得したデータ、品質管理データを統合し、不良品率の分析や製品品質の改善に取り組む事例があります。食品メーカーでは、在庫管理や需要予測にデータ分析が活用されているケースが増えています。
また、AIの登場により、分析結果はダッシュボードだけでなく自然言語での対話形式でも出力できるようになりつつあり、従来に比べ意思決定スピードが加速しています。今後は「データ整備に追われる分析」から「誰でも使えるデータ活用」へのシフトが加速し、「データ分析の目的はなにか?」がますます重要になる時代が訪れると考えられます。
データ分析の進め方
データを分析するとはどういうことでしょうか?
データとは、事実や事象を数値や文字などで記録したものです。そしてそれらのデータを収集・選別・蓄積して加工することで情報となります。情報を適切に分析することで、その結果からビジネスに役立つ知識を得ることがデータ分析の目的となります。 つまり、データ分析の目的はなにか?これがデータ分析の初めの入り口となります。データ分析がビジネス戦略と密接に関わると言われる所以です。
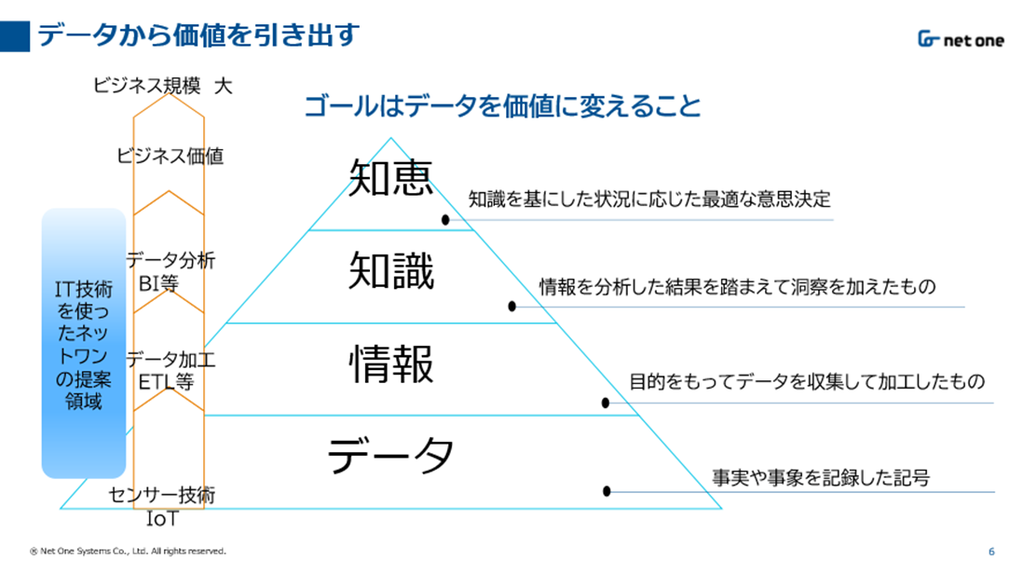
データから価値を導き出す「DIKWモデル」
データから価値を導き出すモデルとして有名なフレームワークとして「DIKW(Data → Information → Knowledge → Wisdom)モデル」があります。DIKWモデルでは、データの価値を「データ」「情報」「知識」「知恵」の4つ階層で表現しています。
-
目的:情報の階層構造を理解し、データを知識・知恵に昇華させるための概念モデル。
-
主な利用分野:ナレッジマネジメント、情報科学、教育、DX推進など。
-
特徴:抽象的で汎用性が高く、業界を問わず使える。「知識とは何か?」を考える際の思考の枠組みとして有用。
-
日本では:DXやデータドリブン経営の文脈で注目されている
データ分析を実現するIT技術
効率的なデータの加工や高度な分析にはIT技術が欠かせません。ツールは課題解決手段ですが、ここではデータ分析で利用される主なツールをいくつかご紹介します。
・ETLツール
データの抽出・変換・格納のプロセスを効率的に行うためのツールです。ETLツールの目的は大量かつ 多様なデータを効率的に扱い、データの品質や一貫性を確保することで分析結果の精度を向上させます。
Extract(抽出) ⇒ Transform(変換) ⇒ Load(格納)
大量かつ多様なデータ データの変換/加工 保存
・BIツール
データの可視化、レポート作成といった機能を備え、データに基づいた意思決定を支援するツールです。BIツールを使うことでデータの可視化(グラフ・レポート・ダッシュボード)、データの一元管理(短時間での集計・分析)ができることで、専門的な知識がなくても現場レベルでデータ分析ができるようになります。
・AutoML
機械学習後に生成する予測や分類のための仕組み(モデル)の構築や最適化のためのプロセスを自動化してくれるツールです。これにより専門知識がないエンジニアでも高度なモデルの作成が可能となり、高精度な分析が可能となります。
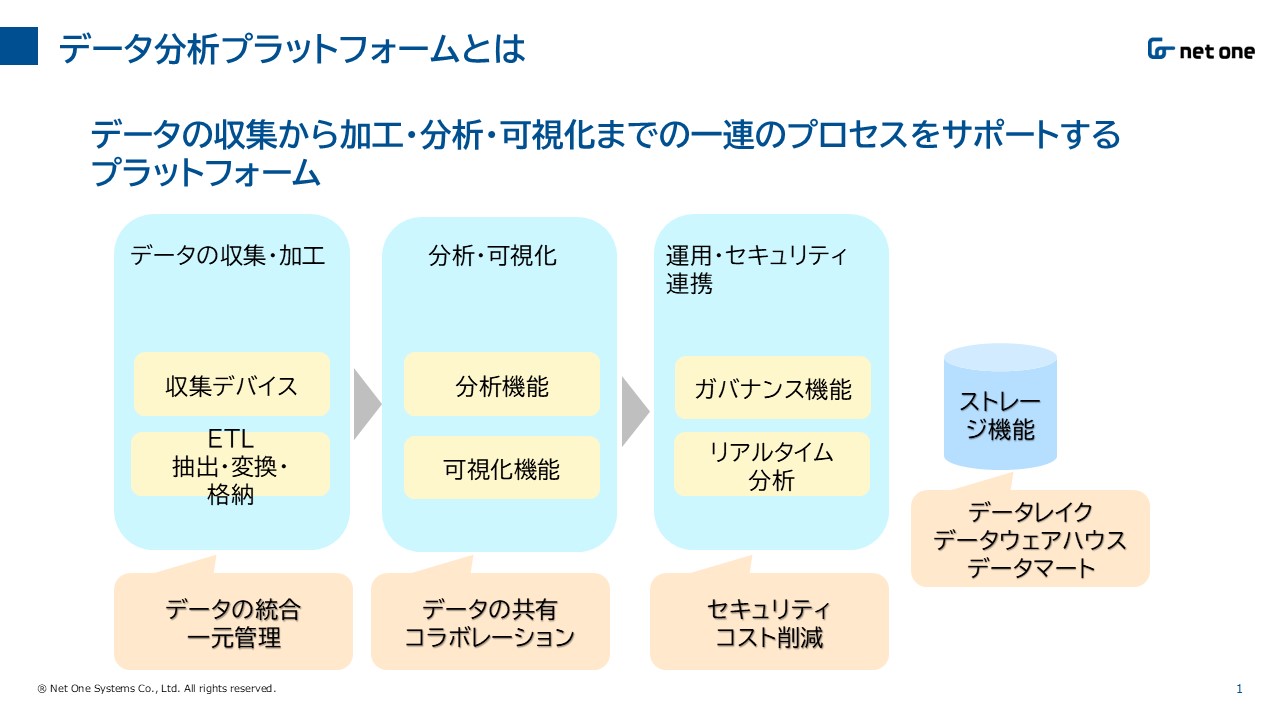
データ分析プラットフォーム
ここまでデータ分析を支援するツールを紹介してきましたが、近年これらのツールを一つのプラットフォームと見立て、データの収集・加工・分析・可視化を統合的にサポートする考え方が出てきました。これが「データ分析プラットフォーム」と呼ばれるものです。
データ分析のプロジェクトは成功率が低いと言われています。その原因はデータの品質の問題が挙げられます。データ収集段階での品質管理、データクレンジングの徹底、データ標準化・正規化、メタデータ管理とガバナンスが重要となります。データ品質の向上は、AIに学習されるデータ品質としても影響を及ぼします。
データ分析で用いる代表的な製品
データ分析で用いる代表的な製品として、リアルタイムなデータ連携を担うConfluent Cloudと、統合的な分析基盤であるDatabricksをご紹介します。
・Confluent Cloud
Confluent CloudはApache Kafkaベースのクラウドサービスで、ストリーミングデータの収集・加工・配信を担うデータストリーミングプラットフォームです。GUIによるパイプライン設計やデータ流れの可視化(Lineage)など、運用負荷を大きく下げる仕組みが整っています。
・Databricks
Databricksは、従来のETLツール・BIツール・AutoMLツールを個別に組み合わせていた時代から一歩進み、「データの収集・蓄積・分析・AI活用」までワンストップで実現できるプラットフォームです。従来は、OracleDBや別々のETL/BIツールを使い、データ連携や権限管理、AIモデルの構築・運用まで多くの専門知識と工数が必要でしたが、Databricksを導入することで、Unity Catalogによる一元管理、ノーコードでの分析やAIモデル作成、API化まで一気通貫で対応可能となり、開発・運用コストの大幅な削減が期待されます。
当社の取り組み内容をご紹介
社内のデータ分析プラットフォームについて
当社では、先にご紹介したConfluent CloudとDatabricksを組み合わせてデータ分析プラットフォームを構成し、「分析基盤」と「生成AI基盤」の両面で活用しています。従来、データ分析やAI活用は一部の専門部門やエンジニアに限られていましたが、現在は現場部門の担当者でも直感的にデータ分析やAIによる業務支援ができる環境を目指しています。
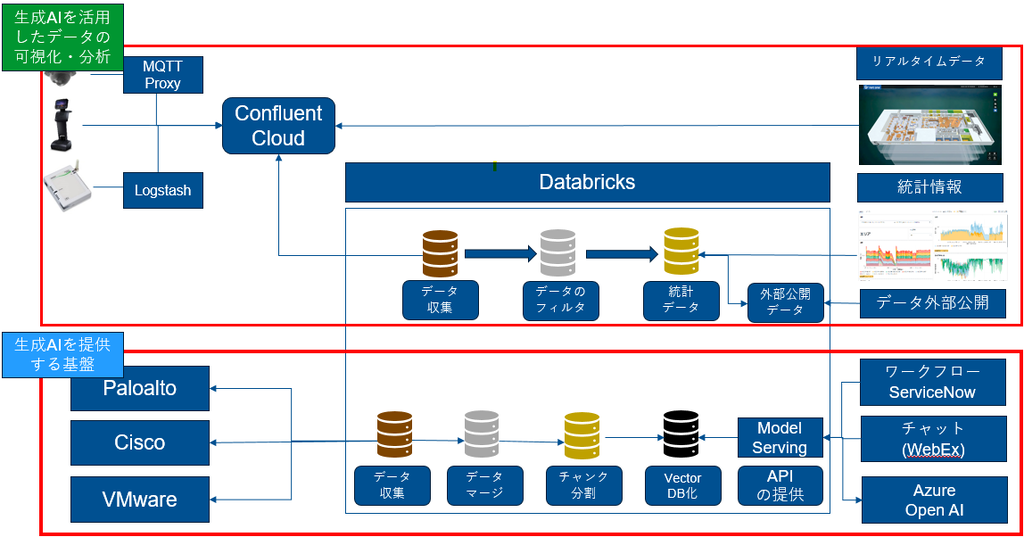
「分析基盤」としてのデータ分析プラットフォーム
netone valley内には多種多様なセンサーが設置されており、これらのセンサーからはミリ秒(ms)単位で高頻度のデータが生成されています。これらの大量データはConfluent Cloudのトピックにリアルタイムでストリーミング配信されており、kSQLを用いた簡易的なデータ加工や、アプリケーションによるリアルタイムデータ取得も可能です。
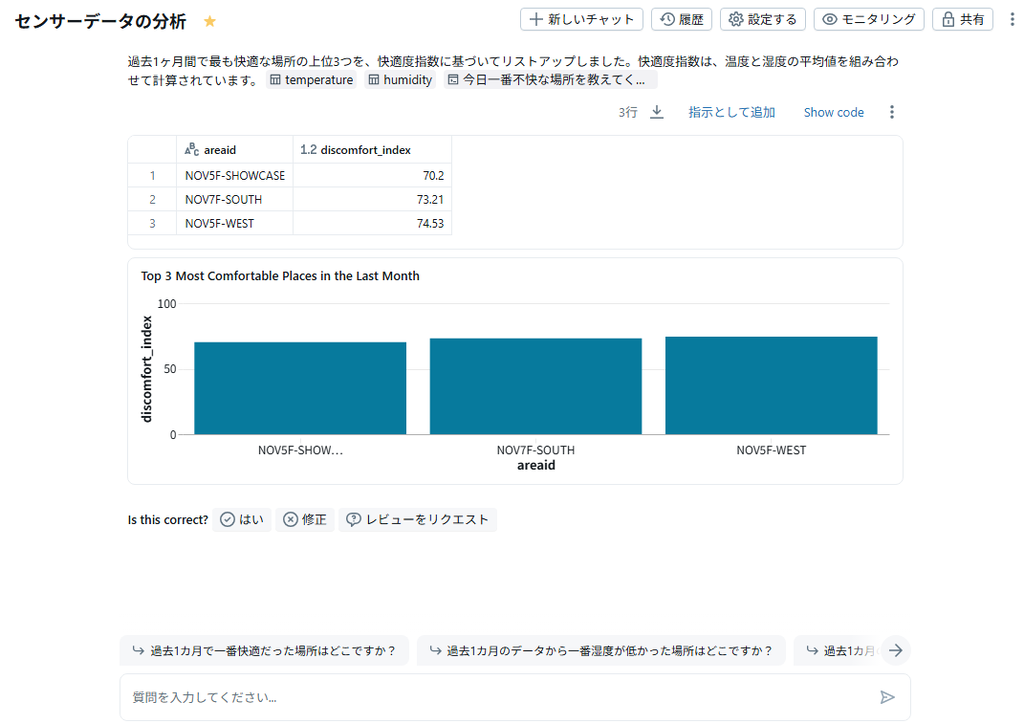
DatabricksはConfluent Cloudから定期的に数千万件にも及ぶ大量のセンサーデータを取り込み、ストレスなく高速に処理・分析を行っています。特に、Databricksの強力な分散処理基盤により、膨大な時系列データの長期的な統計分析やBIによる可視化がスムーズに実現できています。さらに、DatabricksのAI/BI Genie機能を活用することで、現場担当者がノーコード・ローコードで対話的にデータ分析を実施できるようになりました。例えば、設備異常の予兆検知や、センサー値の異常値自動抽出といった分析も、専門知識がなくても実現可能です。
【具体的な分析支援ユースケース】
- 異常の予兆検知
センサー値の時系列データをDatabricksで自動解析し、異常傾向をAIが検出。担当者がGenieに「最近異常値が増えている箇所は?」と質問するだけで、該当箇所とその傾向を可視化できます。
- エネルギー消費の最適化
設備ごとの消費電力を自動集計し、ピーク時の要因分析や省エネ施策の効果測定をAI/BIで実施。
「生成AI基盤」としてのデータ分析プラットフォーム
生成AIの分析支援として、Databricksを活用したRAG(Retrieval Augmented Generation)型のAIアシスタントを社内外の問い合わせ対応に導入しています。具体的には、Paloalto Networks製品の技術問い合わせに対し、事前に蓄積したナレッジベースや過去の対応履歴をAIが検索・要約し、最適な回答を自動生成します。
【生成AIによる分析支援ユースケース】
- 問い合わせ内容の傾向分析
AIが問い合わせ内容を自動で分類・集計し、「今月多い質問カテゴリ」や「対応に時間がかかっているテーマ」を可視化。これにより、FAQの充実や教育コンテンツの改善に役立てています。
- 業務プロセスのボトルネック抽出
ServiceNowやWebEx経由で蓄積された問い合わせ履歴をAIで分析し、業務フローのどこで遅延や手戻りが発生しているかを特定。改善アクションの立案に活用しています。
導入時の課題と工夫
当初はDatabricksでストリーミングデータを直接取り込む仕組みを構築していましたが、リアルタイム性やコスト面で大きな課題が発生しました。Databricksではデータを一旦取り込んでからUnity Catalogに反映されるまでにラグが生じ、リアルタイムでデータを必要とするアプリケーションにはタイムリーにデータを供給できなかったのです。また、ストリーミングデータの直接取り込みはコスト高となりがちでした。
そこで、Confluent Cloudをデータパイプラインの前段に挟む構成に切り替えました。これにより、リアルタイム性が求められる場合はConfluent Cloudから直接データを取得し、長期的な統計分析やAI活用が必要な場合はDatabricksのUnity Catalogからデータを取得するという役割分担が可能になりました。この構成によって、データを利用する側から見ると「リアルタイムデータも統計データも、用途に応じて一貫した環境でアクセスできる」仕組みを実現できたと考えています。
以前は「データ分析=データサイエンティストの仕事」というイメージが強く、現場部門からは「難しそう」「自分たちには無理」と敬遠されがちでした。しかし、データ分析プラットフォーム導入後は、現場担当者が自分でデータを可視化し、AIに質問して業務改善のヒントを得る、といった“データ活用の民主化”が進みました。
今後は経営データの分析や、顧客問い合わせ履歴を活用した生成AIによる高度な業務支援にも取り組む予定です。データ分析・AI活用の裾野をさらに広げ、全社的なデータドリブン経営を推進していきます。
おわりに
本ブログでは、データ分析トレンドと、当社における社内活用事例をご紹介いたしました。近年、データ分析プラットフォームは生成AIとの統合が進み、より多様な分析手法やデータ活用が可能になっています。しかし、ツールが分析を担ってくれるからこそ、「データ分析の目的はなにか?」という目的設定がますます重要になっています。
当社では、お客様と伴走しながら最適なデータ分析をご支援する「データマネジメントワークショップ」を提供しています。まずは、分析対象の範囲と目的を定め、スモールスタート(段階的な導入)でデータ分析を始めてみませんか?「データマネジメントワークショップ」の詳細は下記ブログをご参照ください。当社とともに、着実なステップで成果につなげていきましょう。
本ブログをお読みいただき、データ分析にご興味をお持ちいただけましたら、ぜひ「Innovation Showcase」へお越しください。 Innovation Showcaseではデータ分析基盤のご紹介や、実際のデータ活用デモをご覧いただけます。
お問い合わせやPoC(概念実証)のご相談は、下記問い合わせフォームまたは担当営業までお寄せください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


