
労働人口減少、品質の担保、企業価値を高める本業への時間確保、様々な理由から業務の効率化が急務になってきており、ITインフラの運用自動化に注目が集まっています。今回はITインフラの運用業務の自動化/自律化を目指してRed Hat社のAnsible Automation PlatformやAIを組み合わせると、どのような運用業務にシフトしていけるのか検証をした結果を共有します。

- ライター:片野 祐
- ネットワンシステムズに新卒入社し、PF, NW, SW, AIといった様々な製品、技術の担当として技術検証、提案導入支援、データ分析等を行ってきた。その後、よりお客様に近い立場でSW開発支援や自動化技術を中心とした案件推進活動を実施。現在は運用高度化を目指し自動化技術の製品担当やソリューション開発に従事。
目次
はじめに
ITインフラの運用業務において、機器に対して手動での設定、コンフィグ投入をしているとヒューマンエラーの発生、作業ミスによる障害や手戻りが発生する可能性をゼロにはできません。これらの発生リスクをできるだけ最小限に留め、作業品質を一定に保ちながら、結果として業務全体の工数を減らす手法として運用業務の自動化が注目されてきました。従来は機器に対して人間が行っていた作業自体を自動化することに焦点が当たっていましたが、インフラ全体の規模が大きくなり複雑化しているため目の前の機器に対する作業のみを自動化しても、関連する業務全体で見たときにそれほど自動化の効果が出ていないように見えてしまう恐れがあります。業務全体を見たときに自動化をより効果的なものにしていくためには、いかに関係者とのコミュニケーションをうまく取っていくか(例:そもそもコミュニケーションがなくて問題ないように実装する、基本的にはAIに一次相談をして重要な部分のみ有識者と会話する、セルフサービス化する、等)を考え、自動化の実装方法やAIによる支援を取り入れていく必要があります。自動化を推進しようと考えたとき、「どこまで自動化をするか」、「どこに人間が介在するか」という新たな検討事項も出てきます。今回は自動化の一歩先として、運用業務の中でより人間の介在する機会を減らした自律化した運用を目指し、AIを活用することでさらに運用を高度化(≒AIOps)できないかということを考えて検証をしてみました。
本検証はRed Hatが公開している「AIOps automation with Ansible - Solution Guide」を参考(※閲覧にはRed Hat IDが必要)にして、弊社内の検証環境向けにカスタマイズして動作検証をしました。
※動くものを作ることを最優先にしたため、各コンポーネントは必ずしも最適化されておりません。
①:検証のイメージと利用したツール
まず今回の検証では、障害発生時のトラブルシュートをできるだけ自律的に行うことに注目しました。以下が今回の検証の最終イメージです。
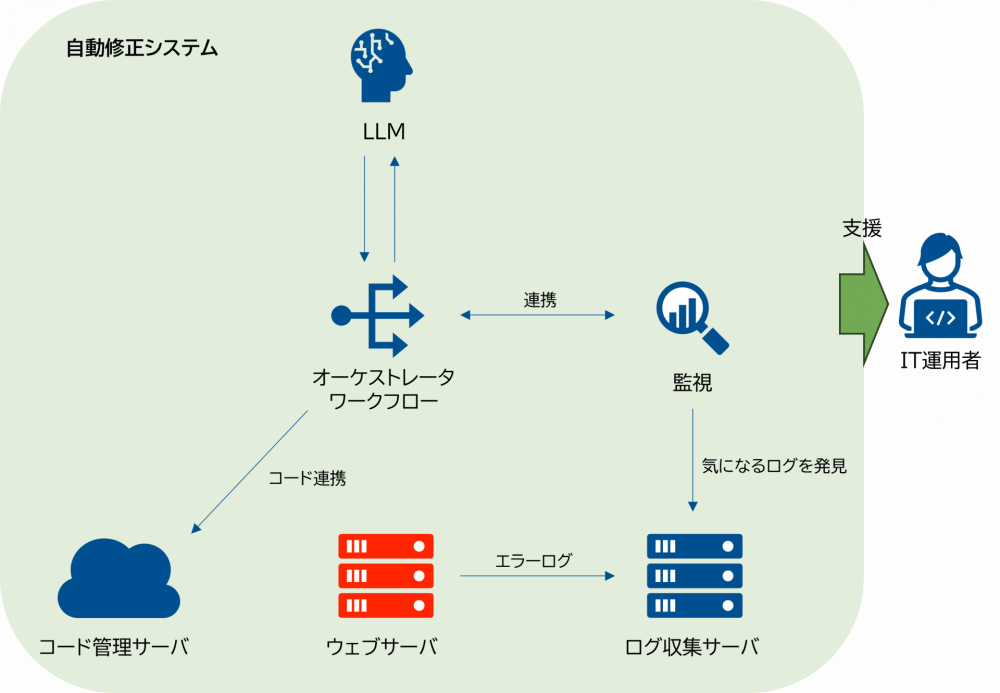
[システムのイメージ]
図の中でもトラブルシュート時に中心となって動くオーケストレータ/ワークフローとしてRed Hat Ansible Automation Platformを使い、ワークフローの中で使うLLMにはRed Hat OpenShift AIを使ってデプロイしたモデルを使うことで環境を作成しました。
Red Hat Ansible Automation Platform
Ansible Automation Platformは自動化のための総合ソリューションです。Ansible Automation Platformにはいくつかのコンポーネントが含まれていますが、今回は以下の2つを利用しました。
Automation Controller
Playbookと呼ばれる自動化のタスクを記述したファイルをジョブテンプレートとして登録し、ワークフロー化して実行制御できるGUIを持ったコンポーネント。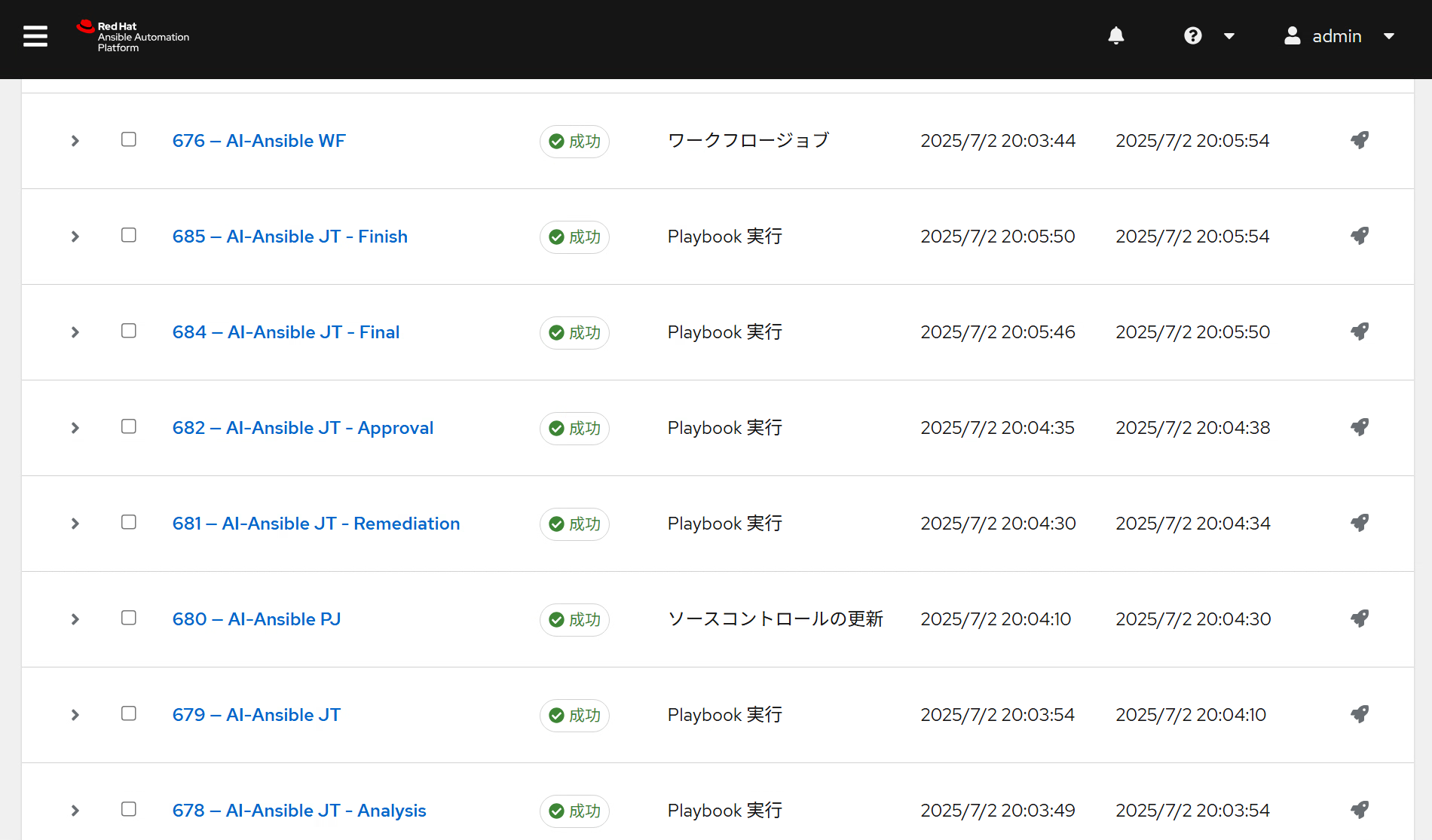
[Automation ControllerのGUI]
Event-Driven Ansible Controller
Automation Controllerのジョブをイベント駆動で実行するためのコントローラー。webhookの待ち受けや、キューのメッセージをポーリングしてRulebookに書かれた処理内容をもとにジョブの開始命令を出すコンポーネント。
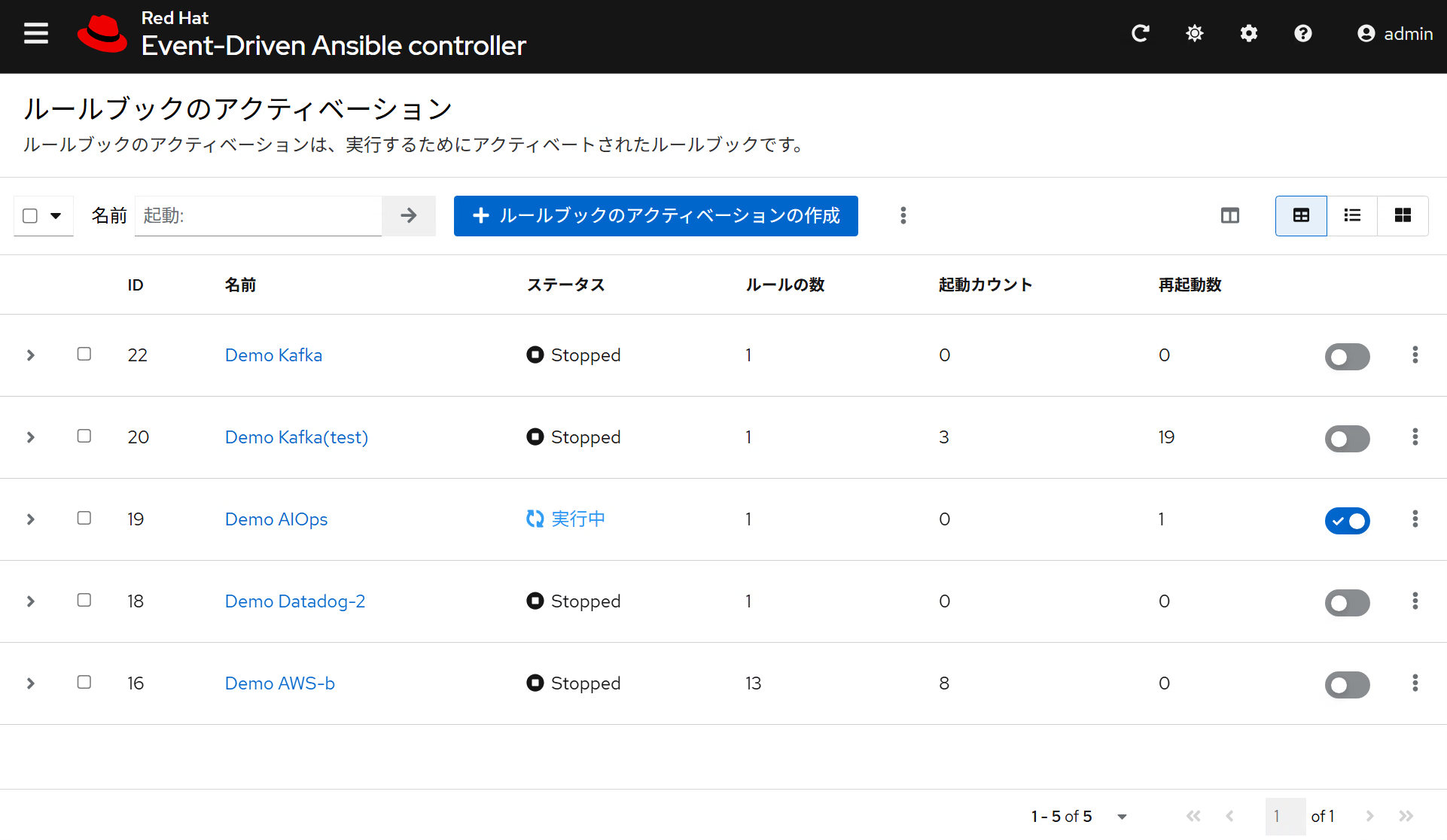
[Event-Driven Ansible ControllerのGUI]
Red Hat OpenShift AI
OpenShift AIはOpenShift上でAI/MLプラットフォームを実現します。今回の検証ではOpenShift AI上にデプロイしたLLMをAutomation Controllerのワークフロー内で活用し運用者を支援します。
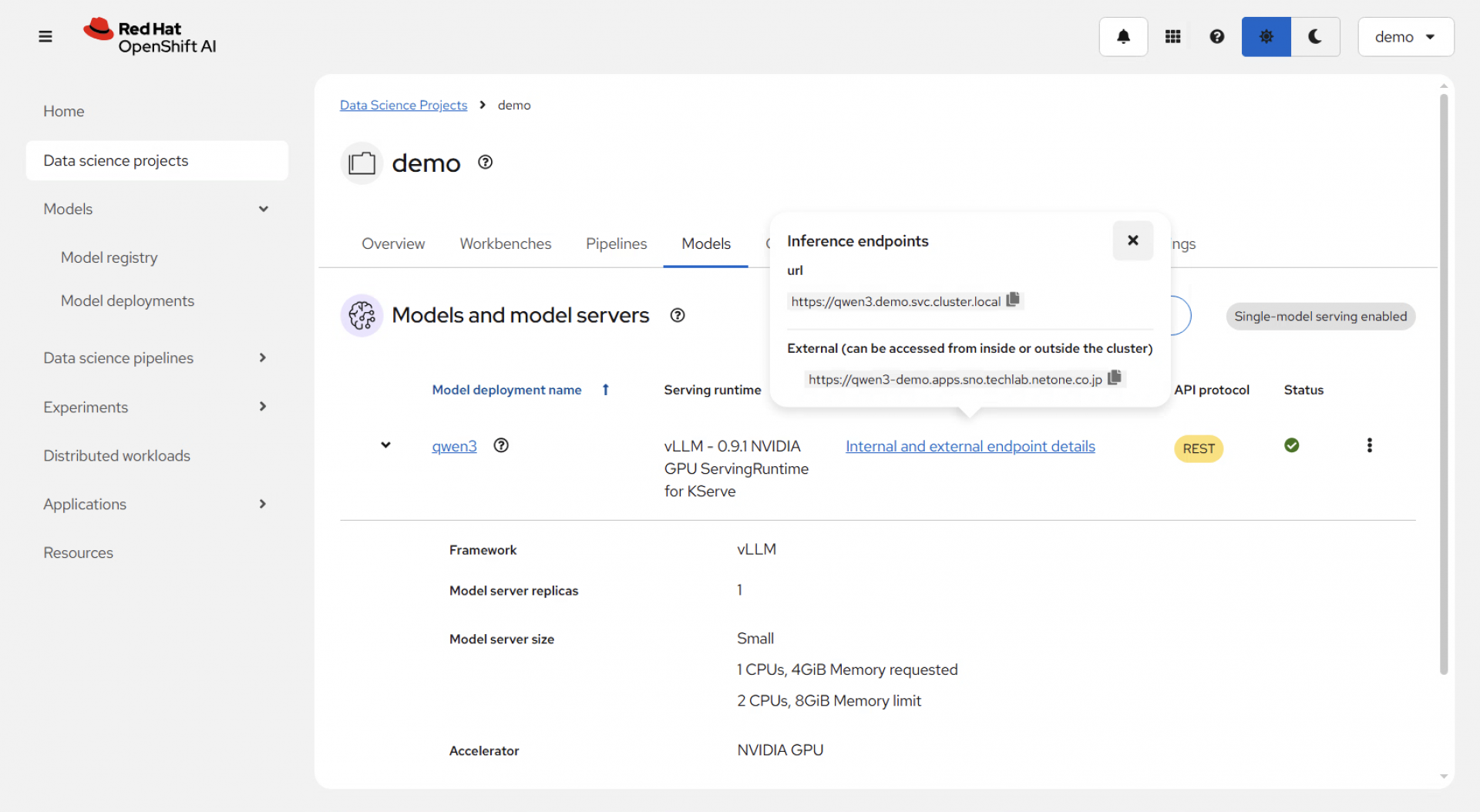
[OpenShift AIのGUI]
②:検証のシナリオ
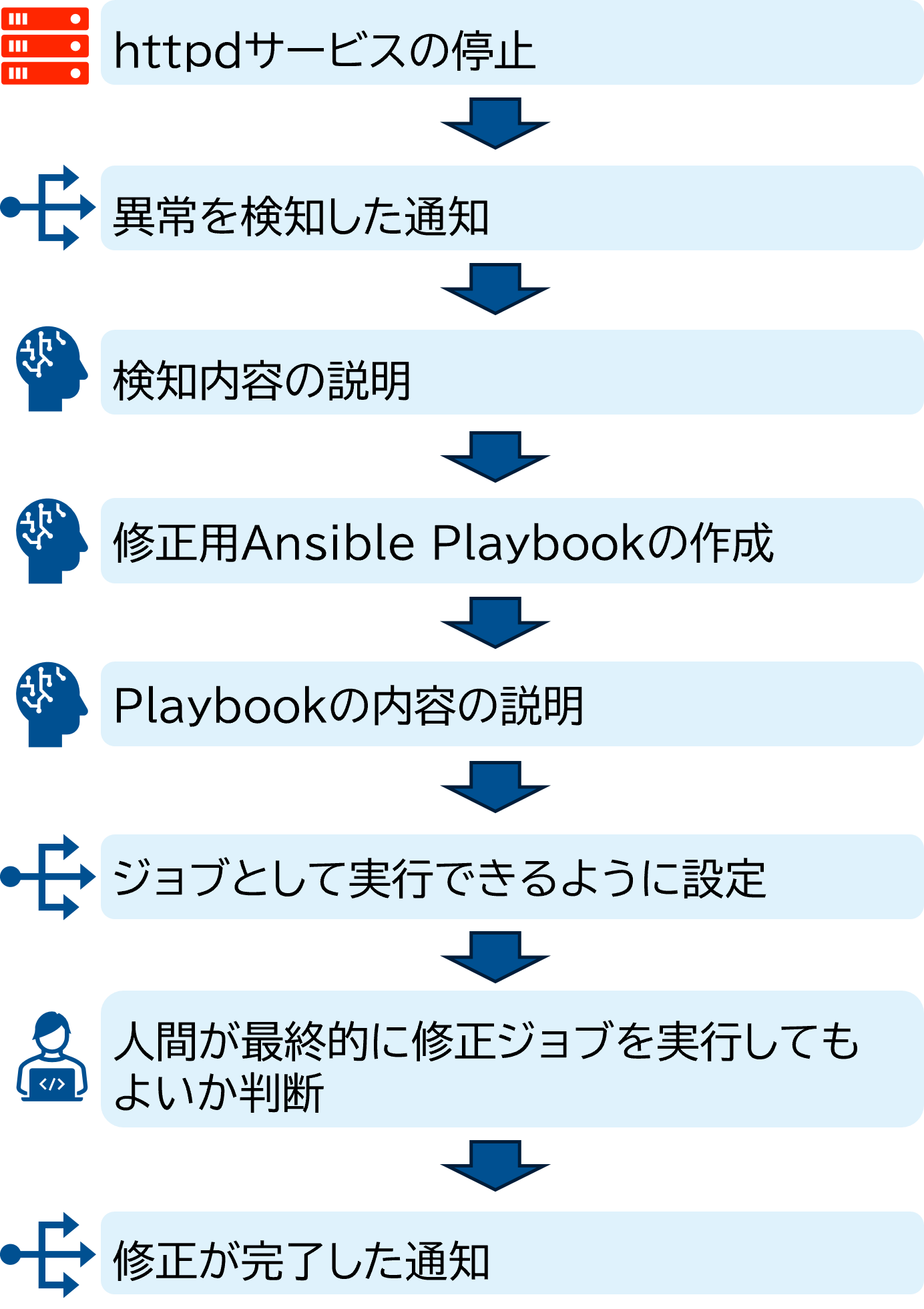
[シナリオ]
以下のようなシナリオを組んで、検証を行いました。
- ウェブサーバが何らかの原因で動作しなくなり、ログを出力する(今回はhttpdのサービスが止まったときに出力される “Stopped The Apache HTTP Server.“ というログを使用する)
- 出力したログをログ収集サーバに送付し、Event-Driven Ansible Controllerがログを検知することでAutomation Controllerで事前設定したワークフローを開始する
- ワークフローの中で以下を実施する
- ログに対して、LLMを用いてログの説明文を生成し、運用者に通知する
- ログに対して、LLMを用いてログの内容を修正するAnsible Playbookを作成する
- ログとAnsible Playbookを照らし合わせ、このPlaybookを実行することで事象が解決しそうか、再度LLMによって検討し運用者に通知する
- 3.(2)で作った修正用Ansible PlaybookをAutomation Controllerで実行できるように設定する
- 作成したAnsible Playbookを実行する設定が完了したことを運用者に通知し、確認を促す。問題がなければ実行を承認(問題があれば否認)する
- 修正用Ansible Playbookを実行する
- 最終的に異常が解決されたことを確認する
今回は単一サーバの単一障害を対象に、シンプルなシナリオで検証を行いました。人間が状況の把握を簡単に行い次のアクションを起こせるよう、今回の検証では通知は普段使っているチャットスペースに送っています。ポイントは、トラブルシュートの一連の流れにおいて運用者は最終的な実行の判断のみを行っており、その他はすべて自動化されているという点です。
③:シナリオを動かしてみた結果、課題と今後の展望
障害を模して、ウェブサーバのhttpdサービスを停止させることでワークフローが動き始めます。ワークフローが進むにつれて、運用者のもとには以下のような通知が届きます。赤枠で囲んだ中で「ログの説明」と「LLMで作ったAnsible Playbookの中身と解説」はワークフロー内でLLMが作成した文章です。
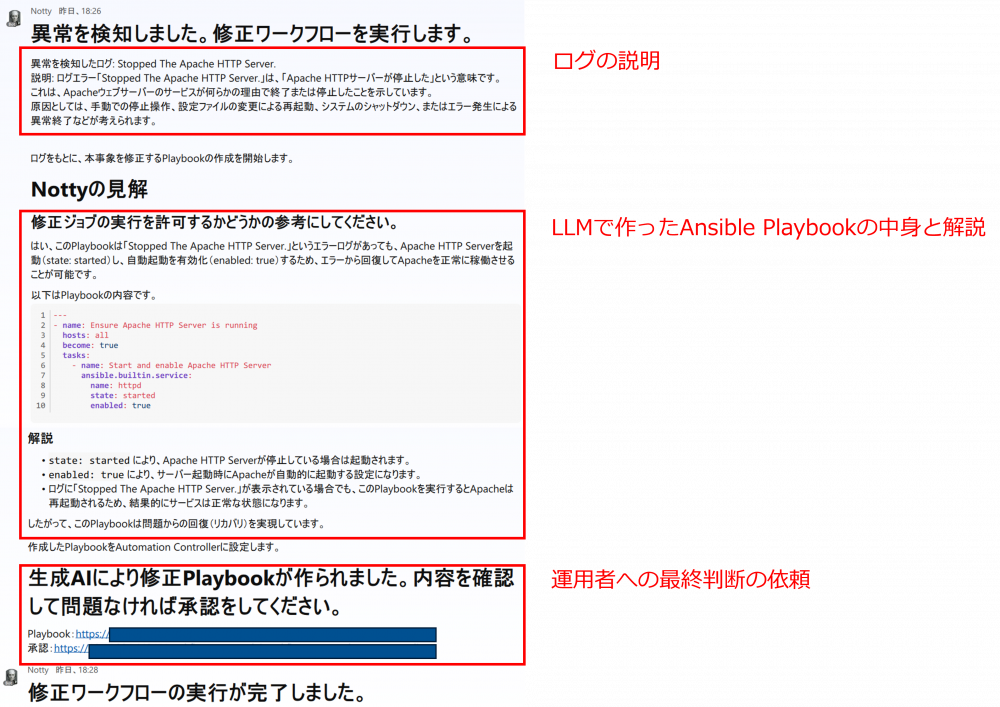
[ワークフローから運用者に送られてくる通知]
運用者は通知が来ることで何か障害が発生したことを認識し、LLMが作った説明文により状況を把握します。その後、障害を復旧させるための準備がワークフロー内で行われるため、その内容を把握して後続の処理の実行可否を判断します。実行を承認した場合、最終的に障害が復旧していることを確認します。
検証の結果を簡潔にまとめると、以下の通りとなりました。
-
最終的にLLMにより作成されたAnsible Playbookを実行することで、ウェブサーバのhttpdサービスを起動することができた。
-
サービスの再開には2-3分の時間を要した(運用者の確認の粒度やインフラのスペックにも依存)。
-
運用者はコマンドや設定ファイルを直接編集することなく、数クリックで障害を解決できた。
今回のシンプルな検証シナリオにおいては、LLMを組み込んだワークフローでウェブサーバの障害を復旧できました。ただし、実際のインフラでは障害の事象も単純なものから複雑なものまであり、さらに単一の機器だけではく複数の機器が絡んだようなものもあるため、より障害の解決が難しいパターンが考えられます。今回の検証ではシンプルなログ、構成で実施したため障害復旧までできましたが、実際にはワークフローの中で周辺機器も含めたログを集め、より深く現状を分析して、その結果をまとめて修正案を考えることをLLMに依頼する方が現実的かもしれません。どこまで実際の障害に耐えうるかはさらに検証をしてみる必要があると感じています。
また、「どこまで自動化をするか」、「どこに人間が介在するか」という観点については、より自律化に近づくほど、やってはいけない変更を事前に防いでおく仕組みの導入も必要になると感じました。今回のようなサービス起動であればその設定変更に対する影響は小さいかもしれませんが、影響度合いはその時々によって異なると思います。ワークフローの中でLLMが作成したAnsible Playbookの説明を運用者に向けて通知をしていますが、運用者のAnsibleに関するスキルやナレッジ、ITインフラ自体のスキルやナレッジによっては、正確にAnsible Playbook実行時の影響を測れない可能性もあります。ここは修正をAnsible以外のツールを使って行うときにも同様のことが言えます。そのため、LLMを絡めた運用になると事前対策はより重要度を増すと考えられます。Ansible Automation Platformの場合、2025年7月の本記事執筆時点の最新版(ver. 2.5.15)ではPolicy enforcementという機能を有効化することができ、必要なコンプライアンス設定を実行する機器やジョブ等に紐づけることで関連するジョブの実行時にポリシー評価を行うことができるようになります。このようなガードレール機能を使って、安全に自動化/自律化を推進していく重要性を再認識しました。他にも実際の運用を考慮していくと、いきなり本番環境への適用ではなく検証環境を使った試験を行う、設定変更前にバックアップを取得する等、ワークフローの中で実行を検討しなければいけないことはありますが、まず簡単なシナリオを動かせたことで多くの気づきを得ることができました。
まとめ
トラブルシュートを例に、AIを取り入れたワークフローを実行する検証を行いましたが、まだまだ修正の余地はありつつも一連の障害対応のワークフローを動かしてみることができました。今回はマルチベンダーのITインフラに対して実行できるようなコンポーネントを選択しましたが、各ITインフラベンダーがそれぞれAIを活用したオーケストレータやマネージャー製品をリリースしてきているため、一概にどれを使うのが最適解かということは環境によって異なると思います。また、ITインフラの構成によって使える製品、実装の難易度も変わってくるため、運用で実現したいことと開発コストとの天秤になることもあると思います。様々な選択肢があり、テクノロジーの進化が速い領域のため、引き続きキャッチアップを続けていこうと思います。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


