
Databricksを使って生成AI Agentの作成と、モニタリング。SambaNovaを活用したAgentの高速化を行います。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
生成AI Agentとは
Databricksのドキュメントによると生成AI Agentとは、目標を達成するために環境を自律的に認識し、決定し、行動する事が出来るAI駆動型システムとされています。また、エンタープライズでのAI利用に必要とされる複雑なワークフローや、複雑な機能提供に対応する為に、ほとんどのユースケースでDatabricksは固定的なフローに代わって、Agentシステムを推奨しています。
https://docs.databricks.com/aws/ja/generative-ai/guide/introduction-generative-ai-apps
Databricksでの生成AI Agentの作成と管理
Databricksは生成AI Agentの作成から管理、運用までをサポートする様々な機能を提供しています。今回はツールの作成と、Agentの作成、登録、利用、モニタリングの一連の流れをITベンダーのドキュメントを検索するAgentを例に解説します。
DatabricksのAgentツールについて
Agentはユーザの様々な要求に対して、ツールを駆使してデータの読み込みや、タスク実行を行います。Agentが使うツールの登録は、DatabricksではUnity Catalog関数と、Agentコードツールがあります。Unity Catalog関数は、Unity Catalog内に関数としてツールを登録しておき様々なAgentからの利用を可能とします。ツールに対して、アクセス権の設定も出来る為適切な人が、適切なツールを利用出来ます。今回はツールとしてUnity Catalog関数を利用します。Databricksで作成出来るツールは以下のようなものがあります。
- コードインタプリターツール: Python等で記述された、任意のコードをサンドボックス内で動作させます。
- 構造化データ取得ツール: 構造化されたテーブルデータに対して事前にSQL文を定義してデータを取得します。
- 非構造化データ取得ツール: ドキュメントのような非構造化データを取得します。Vector DB等からデータを取得します。
- 外部接続ツール: 外部サービスのAPIに接続して、データ取得とタスク実行します。
Agentツールの登録
今回はVector DBからデータを取得するUnity Catalog関数を登録します。以下のSQL文を実行すると指定のUnity Catalogのスキーマ以下に関数が登録されます。AgentはCOMMENT欄に書かれた内容を元にツールを使うべきかの判断を行います。
|
CREATE OR REPLACE FUNCTION main.default.cisco_docs_vector_search ( |
Unityカタログを参照すると関数が登録されているのがわかります。
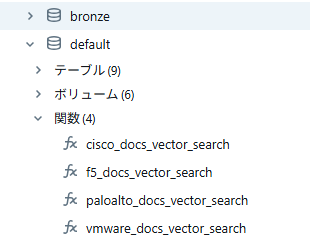
コードでのAgentの作成
今回は以下のLangGraphを使ったAgent作成の手順を参考にしています。コードを実行すると、事前に定義して置いたツールを利用するAgentが作成され、AgentがモデルとしてUnity Catalogに登録されます。
https://docs.databricks.com/aws/ja/notebooks/source/generative-ai/langgraph-tool-calling-agent.html
コードの中のツール登録の部分に、先ほど作成したツールを追記しておきます。
|
uc_tool_names = ["main.default.vmware_docs_vector_search","main.default.paloalto_docs_vector_search","main.default.cisco_docs_vector_search"] |
Servingの登録
前出のコードを最後まで実行すると、Mosaic AI Model ServingにAgentがデプロイされています。Agentがデプロイされると、クライアントからクエリーを受けるAPI Endpointと、エキスパートがAgentのFeed Backを行うWeb UIが自動的に構築されます。
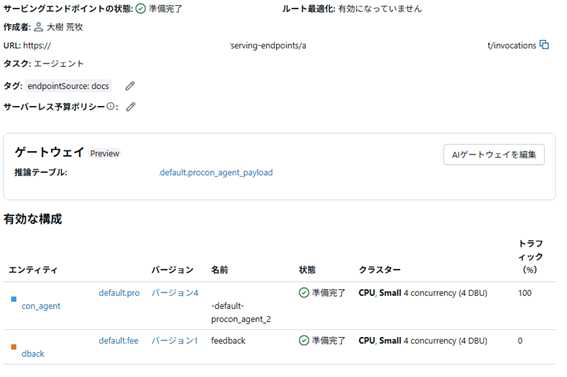
Feed Back用のUIは以下のようになっており、エキスパートが入力して返答を確認して、Feed Backをレポートできるようになっています。ここでのエキスパートはドメイン知識の専門家を想定しており、Ciscoに関するAgentであればCisco Systemsの製品に詳しい専門家がFeed Backの画面を通じてAgentの動作の確認を行います。その後、Feed Backを元にAgentの管理者はAgentの改善プランを立てます。
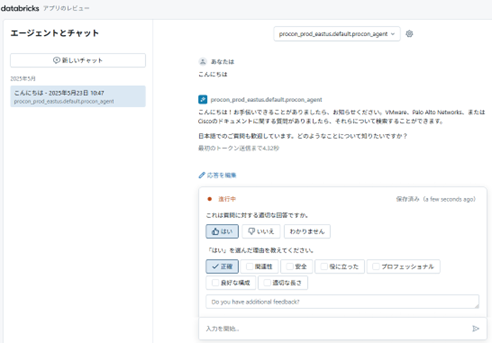
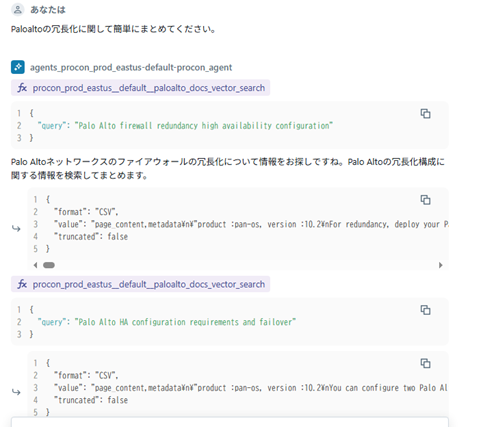
PlaygroundでAgentをテストする
DatabricksのPlaygroundで作成したAgentを選ぶと、簡単にAgentをテストする事が出来ます。先ほどのFeed Backと違い、あくまで簡単にテストする環境となっています。Playgroundの画面では、以下のように、Agentの途中思考も見えるようになっており、Agentが質問に対して、複数回Queryを投げて全体を把握しようとしている様子が見て取れます。
Agentのモニタリング
Agentへの問い合わせと、返信と動作過程は自動的にDatabricks上に推論テーブルとして保存されます。さらに、推論テーブル上のデータを元にモニタリング用のテーブルも作成され、定期実行Jobによってモニタリングデータが更新されます。Job自体は自動的に登録され15分毎に実行されますが、実行間隔等は設定可能となっています。
Jobの画面から確認すると、request_logsを読み込んで、evaluated_tracesに書き込んでいる事がわかります。
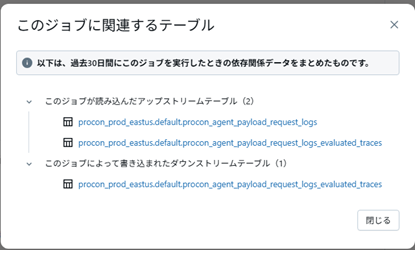
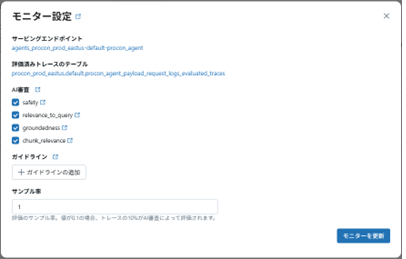
どの程度サンプリングするかや、LLM as a Judgeを使って返答の状況をモニタリングする項目はモニタリングの設定画面で変更可能です。
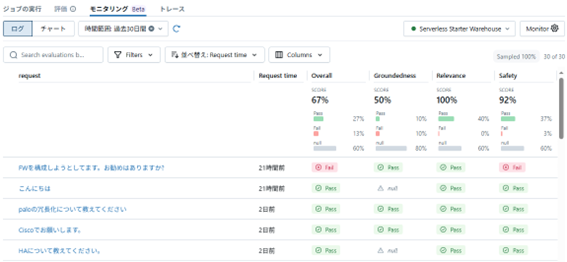
モニタリングで作成されたテーブルはエクスペリメントのモニタリングのページで表示可能です。Agentが問い合わせに対して行った最終的な返信に対して、Groundedness/Relevance/Safetyが評価されています。管理者は、この内容を定期的にモニタリングする事でAgentの質が保たれているか確認が可能となります。
SambaNovaを使ったAgentの高速化
前回の以下の記事で紹介した高速推論を使う事でAgentの高速化を考えます。
SambaNovaを使った生成AIの高速推論とDatabricks連携 | ネットワンシステムズ
SambaNovaの記事によると2025/5/22現在Tool Callingに対応しているモデルから、Deep Seek v3-03-22を選択します。
https://docs.sambanova.ai/cloud/docs/capabilities/function-calling
このモデルをDatabricks上で外部モデルとして登録します。
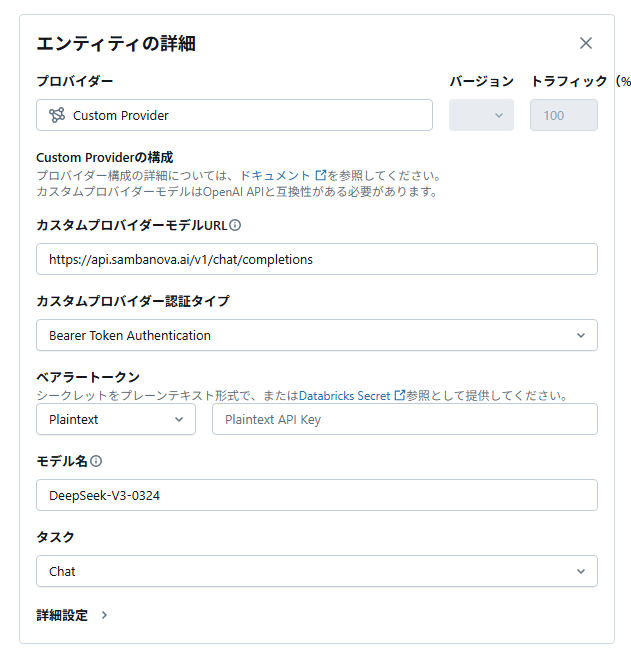
先ほどのAgentを作成した、コードの中でSambaNovaの外部モデルを指定するだけでAgentを簡単に作成出来ます。
| LLM_ENDPOINT_NAME = "deepseek-v3" |
結果の計測
Playground上で2つのPromptを入力して回答が生成されるまでの時間を計測しました。Databricks上のClaude-3.7-Sonnetを使った場合と比べてSambaNovaのDeepSeek v3を使うと、2-4倍程度Agentとしての動作が高速化されています。
|
Databricks |
SambaNova |
|
|
Paloaltoの冗長化に |
9.96秒+50.30秒 |
5.63秒+8秒 |
|
CiscoとPaloaltoで |
8.85秒+68.44秒 |
20.94+8.75秒 |
注意点として、ClaudeとDeepSeekでは最初の回答を受け取った後の動作が異なっており、Claudeでは複数回問い合わせを行って回答の精度を高めようとしているように見えました。LLMの推論速度の差だけでなく、LLMのふるまいでAgentの推論速度の差が大きく出ている可能性はあります。
所感
Databricksを利用するとAgentの作成から、その後のモニタリングや運用までを簡単に行う事が出来ます。Agentは動作の検討や回答の評価等で、複数回LLMを呼び出す為、SambaNovaの高速推論の効果が認められました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


