
- ライター:大河原 昂也
- 2021年、ネットワンシステムズに入社。現在は主にクラウド、インフラ管理、自動化を担当。
目次
はじめに
前回の「製造デジタルツインについて」(2025年2月発信)では、弊社が提供する製造デジタルツインのデモをご紹介しました。そのデモでは、ロボットからリアルタイムで取得されるデータをもとにシミュレーション技術を活用し、通常では観測が困難なデータの再現・可視化を行いました。
今回は、このシミュレーションによって得られるデータを活用し、ロボットの異常検知を行う試みについてご紹介します。具体的には、シミュレーションデータを活用しない場合と活用した場合で、異常検知の精度がどのように変化するかを検証しました。本検証は、アルテアエンジニアリング株式会社のサポートのもと実施しました。
検証概要
本検証では、小型4軸ロボット「Dobot Magician」を用いて、鉛筆で紙に指定の記号を書くタスクを実行させ、その際のデータをもとに異常検知の精度を評価しました。具体的には、ロボットの動作データを機械学習モデルに入力し、動作が正常か異常かを予測しました。 その際、入力データとして 「リアルデータのみ」 と 「リアルデータ+シミュレーションデータ」 の2パターンを用意し、シミュレーションデータの追加が異常検知の精度向上につながるかを比較しました。
なお、異常状態は以下の3つのケースを意図的に発生させました。
- ロボットに鉛筆を持たせない → ロボットは動作するが、字を書くことができない。
- ロボットの筆圧が強すぎて紙が動く → ロボットは字を書こうとするが、紙がズレてうまく書けない。
- ロボットに芯が折れた鉛筆を持たせる → ロボットは動作するが、紙に何も書かれない。
このように、ロボットが字を書けない、またはうまく書けない状態を「異常」、正常に字を書けた状態を「正常」と定義し、機械学習モデルを用いた異常検知を実施しました。
今回、異常検知に使用した機械学習モデルは以下の3種類です。
- サポートベクターマシン
- LightGBM
- オートエンコーダ
これらのモデルに対し、シミュレーションデータの有無による検知能力の違いを比較しました。
なお、機械学習に入力するデータは以下のとおりです。
- シミュレーションデータを活用しない場合: 「Dobot Magician」のアームの位置座標、速度、加速度
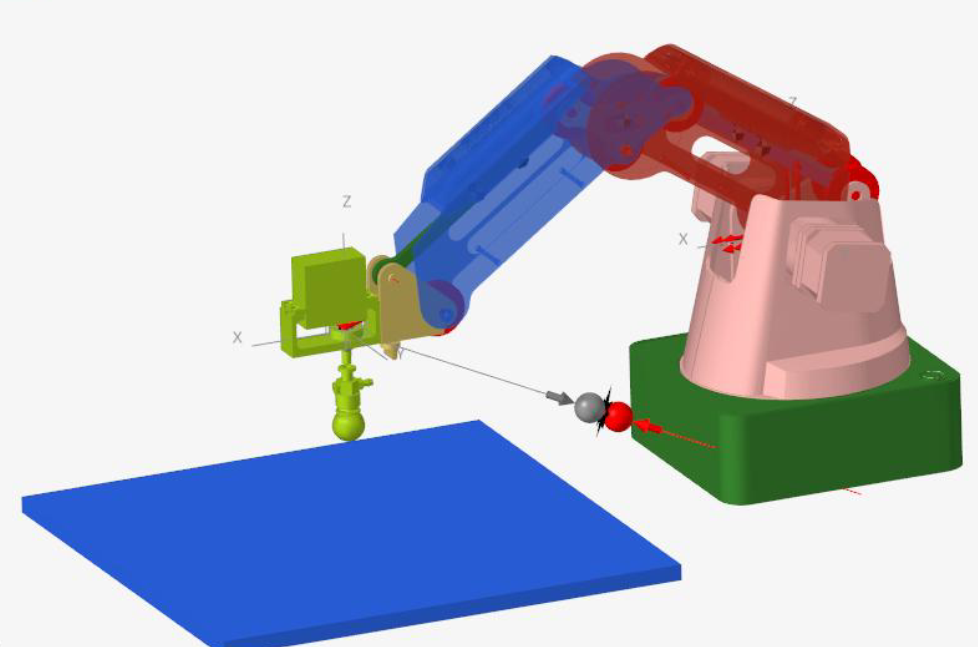
- シミュレーションデータを活用する場合: 上記 + 「Dobot Magician」の各軸の電力。(各軸の電力は、アームの位置座標から算出されるシミュレーションデータです。 シミュレーションに使用する機構モデルは、「製造デジタルツインについて」で紹介したモデルに ペンと紙のモデルを追加し、さらに両者の接触定義を組み込んでいます。)
今回使用した「Dobot Magician」の機構モデル
検証結果
サポートベクターマシン、LightGBM、オートエンコーダの3種類のモデルに対し、シミュレーションデータの有無による正常/異常を区別する能力の違いを比較しました。今回の評価指標には AUC(Area Under the Curve)を使用し、各モデルに対して 5分割交差検証を実施しました。その際の検証用データに対するAUCの平均値と標準誤差を以下の表に示します。

検証結果を示した表
この結果から、シミュレーションデータを導入することで、サポートベクターマシンとLightGBMではAUCが大幅に向上し、オートエンコーダではわずかに向上している ことが確認されました。 ただし、ブートストラップ法を用いてAUCを補足的に統計的検定した結果、サポートベクターマシンとLightGBMでは統計的に有意な差(p < 0.05)が認められた一方、オートエンコーダでは有意な差は確認されませんでした。
まとめと今後の展望
今回の検証により、シミュレーションデータを活用することで、使用するモデルによっては異常検知の精度が大幅に向上することが確認されました。 これにより、デジタルツインの活用が異常検知精度の向上につながる可能性が示唆されました。しかし、その適用範囲や実用化に向けては、以下の課題についてさらなる検討が必要です。
1. シミュレーションデータの適用範囲と制約
本検証では、特定の異常パターンに対する評価のみを行いましたが、異なる環境や異常パターンにおいても同様の効果が得られるかどうかは未検証です。また、シミュレーションデータの有効性がどの条件下で最大化されるのかも明確ではありません。 例えば、
- どの種類の異常に対して効果的なのか
- どの機械学習モデルがシミュレーションデータを最大限活用できるのか
- シミュレーションの精度が異常検知の性能にどの程度影響を与えるのか
これらの点を検証し、シミュレーションデータの適用範囲と制約を明確にすることが重要です。
2. リアルタイム処理の課題
シミュレーションデータを活用する場合、リアルデータの取得 → データのシミュレーション → モデルによる異常検知 という一連のプロセスが必要になります。しかし、リアルタイム性が求められる異常検知システムにおいて、シミュレーション処理の計算コストがボトルネックとなる可能性があります。そのため、処理速度の最適化や、シミュレーションの軽量化 についても検討が必要です。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


