
AIやマシンラーニングが急速に進化し、私たちの日常やビジネスに大きな変革をもたらしています。GPUはこの変革を支える大きな役割を果たしており、今日NVIDIAのGPUが多く利用されていますが、価格や流通の観点からNVIDIA GPUに代わる選択肢としてAMDやIntelのアクセラレーターも期待されています。本記事では、Red Hat OpenShift上でAMD GPUを利用する方法をご紹介します。

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
はじめに
本記事ではAMD Instinct MI210を利用しており、OpenShiftクラスターのノードを確認すると、以下のようにPCIデバイスとしてGPUが認識されています。
sh-5.1# lspci | grep -i MI210 e3:00.0 Display controller: Advanced Micro Devices, Inc. [AMD/ATI] Aldebaran/MI200 [Instinct MI210] (rev 02)
AMD GPU Operatorの利用
OpenShiftでAMD GPUを利用するためには、GPUドライバーのインストール、デバイスプラグインの有効化等が必要です。AMDが公開しているGPU Operatorはこれらのデプロイと管理を簡素化します。
AMD GPU Operator利用の前提条件
OpenShiftでAMD GPU Operatorを利用するには、以下の2つのOperatorをインストールしておく必要があります。
- Node Feature Discovery Operator (Red Hat Certified)
- Nodeに搭載されているデバイスを識別して、ラベルを付与する。
- Kernel Module Management Operator (Red Hat Certified)
- Out-of-treeカーネルモジュールとデバイスプラグインの管理、ビルド、署名、デプロイを行う。
Node Feature Discovery Operatorをインストールすると、AMD GPUが搭載されたノードを検出し、feature.node.kubernetes.io/pci-1002.present=true ラベルがノードに付与されました。"1002" はAMDが製造するPCIデバイスに付与されているベンダーコードです。
# oc describe node worker02 | grep 'feature.node.kubernetes.io/pci'
feature.node.kubernetes.io/pci-1002.present=true
feature.node.kubernetes.io/pci-1002.sriov.capable=true
feature.node.kubernetes.io/pci-102b.present=true
feature.node.kubernetes.io/pci-14e4.present=true
Kernel Module Management (KMM) Operatorは、Moduleカスタムリソースによりカーネルバージョンに対応したデバイスドライバをコンテナイメージとしてビルドし、modeprobeコマンドを利用してカーネルモジュールとしてロードします。AMD GPU OperatorはKMMを利用してAMD GPU向けのデバイスドライバコンテナイメージをビルドし、DaemonSetとしてPodを起動してドライバーをカーネルモジュールとしてロードします。
AMD GPU Operatorのインストール
OperatorHubで「amd」で検索すると、以下の様に2種類のamd-gpu-operatorが表示されます。今回はCertified Operatorを利用しました。

Operatorをインストールすると、amd-gpu-operator-controller-manager podが起動し、カスタムリソースとして deviceconfigs.amd.com が利用可能になります。
$ oc get pod -n kube-amd-gpu NAME READY STATUS RESTARTS AGE amd-gpu-operator-controller-manager-79c5b5cdb7-qvrqm 1/1 Running 0 1192 $ oc get crd | grep amd deviceconfigs.amd.com 2024-12-13T03:33:52Z
DeviceConfigリソースとして以下の内容で構成します。
apiVersion: amd.com/v1alpha1
kind: DeviceConfig
metadata:
labels:
app: amd-gpu-operator
name: rocm-deviceconfig
namespace: kube-amd-gpu
spec:
driver:
enable: true
blacklist: true
version: "6.3"
devicePlugin:
devicePluginImage: rocm/k8s-device-plugin:latest
nodeLabellerImage: rocm/k8s-device-plugin:labeller-latest
metricsExporter:
enable: true
image: rocm/device-metrics-exporter:v1.1.0
port: 5000
serviceType: ClusterIP
selector:
feature.node.kubernetes.io/pci-1002.present: "true"
上記のDeviceConfigリソースを作成することで、.spec.selector に基づいてノードに必要なPod(device-plugin、metric-exporter、node-labeller)が起動します。
$ oc get node -L feature.node.kubernetes.io/pci-1002.present NAME STATUS ROLES AGE VERSION PCI-1002.PRESENT controller01 Ready control-plane,master 148d v1.29.9+5865c5b controller02 Ready control-plane,master 148d v1.29.9+5865c5b controller03 Ready control-plane,master 148d v1.29.9+5865c5b worker01 Ready worker 147d v1.29.9+5865c5b worker02 Ready worker 7d21h v1.29.9+5865c5b true $ oc get pod -n kube-amd-gpu -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES amd-gpu-operator-controller-manager-79c5b5cdb7-qvrqm 1/1 Running 0 5d7h 10.129.1.185 controller02 <none> <none> rocm-deviceconfig-device-plugin-2mxxj 1/1 Running 0 19h 10.129.2.16 worker02 <none> <none> rocm-deviceconfig-metrics-exporter-hbmvf 1/1 Running 0 19h 10.129.2.15 worker02 <none> <none> rocm-deviceconfig-node-labeller-kr95f 1/1 Running 0 19h 10.129.2.10 worker02 <none> <none>
GPUワークロードの実行
AMD GPUが搭載されたノードには amd.com/gpu がスケジュール可能なリソースとして公開されています。
apiVersion: v1
kind: Pod
metadata:
name: rocm-smi
spec:
containers:
- image: docker.io/rocm/pytorch:latest
name: rocm-smi
command: ["sleep","infinity"]
resources:
limits:
amd.com/gpu: 1
PodはAMD GPUが搭載されたがノード上で、GPUがアサインされて起動します。起動したPodでrocm-smiを実行すると、GPUの状態確認が可能です。
$ oc get pod
NAME READY STATUS RESTARTS AGE
rocm-smi 1/1 Running 0 12m
$ oc exec -it rocm-smi -- rocm-smi
========================================= ROCm System Management Interface =========================================
=================================================== Concise Info ===================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Edge) (Avg) (Mem, Compute, ID)
====================================================================================================================
0 2 0x740f, 42924 42.0 C 45.0W N/A, N/A, 0 800Mhz 1600Mhz 0% auto 300.0W 0% 0%
====================================================================================================================
=============================================== End of ROCm SMI Log ================================================
Metric Exporterの利用
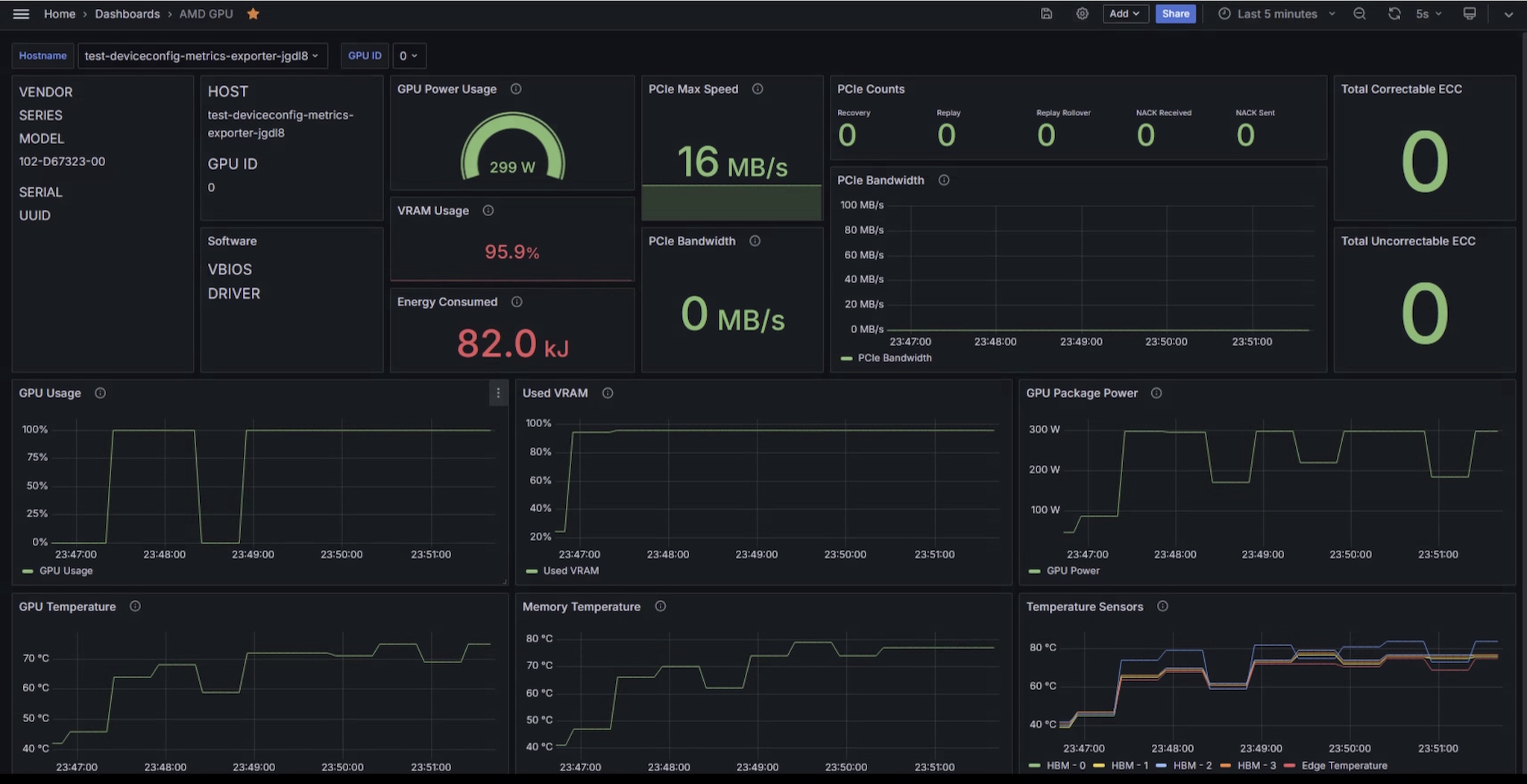
DeviceConfigでMetric Exporterを有効化すると、kube-amd-gpuネームスペースでmetric-exporterが起動し、GPU Power、VRAM Usage、GPU Usage、Memory Templature等のメトリックを出力可能です。Grafana向けのDashboardテンプレートも提供されているため、PrometheusとGrafanaで可視化も容易です。
OpenShift AIのAMD GPUサポート
OpenShift上でAI/MLプラットフォームを実現するOpenShift AIもAMD GPU対応を進めています。OpenShift AI 2.16のリリースノートにはテクノロジープレビュー機能として以下の記載があります。
AMD GPUのサポート
AMD ROCm ワークベンチイメージは、AMD グラフィックスプロセッシングユニット (GPU) Operator のサポートを追加し、コンピュートを集中的に使用するアクティビティーの処理パフォーマンスを大幅に向上させます。この機能により、AI ワークロードと幅広いモデルをサポートするドライバー、開発ツール、API にアクセスできるようになります。さらに、AMD ROCm ワークベンチイメージには、TensorFlow や PyTorch などの AI フレームワークをサポートする機械学習ライブラリーが含まれています。テクノロジープレビューリリースでは、AMD GPU を使用したサービングおよびトレーニング、またはチューニングのユースケースを調査するために使用できるイメージへのアクセスも提供されます。
ROCmはAMDが提供するオープンソースのGPGPUプラットフォームで、HPCやディープラーニングなどに利用されます。CUDAと同様にGPUを活用した並列計算を効率化するAPIやツールを提供します。ROCmはオープンソースで、コードの確認や改変が可能です。PytorchやTensorFlow、vLLM等のフレームワークやライブラリーがROCm対応を進めています。
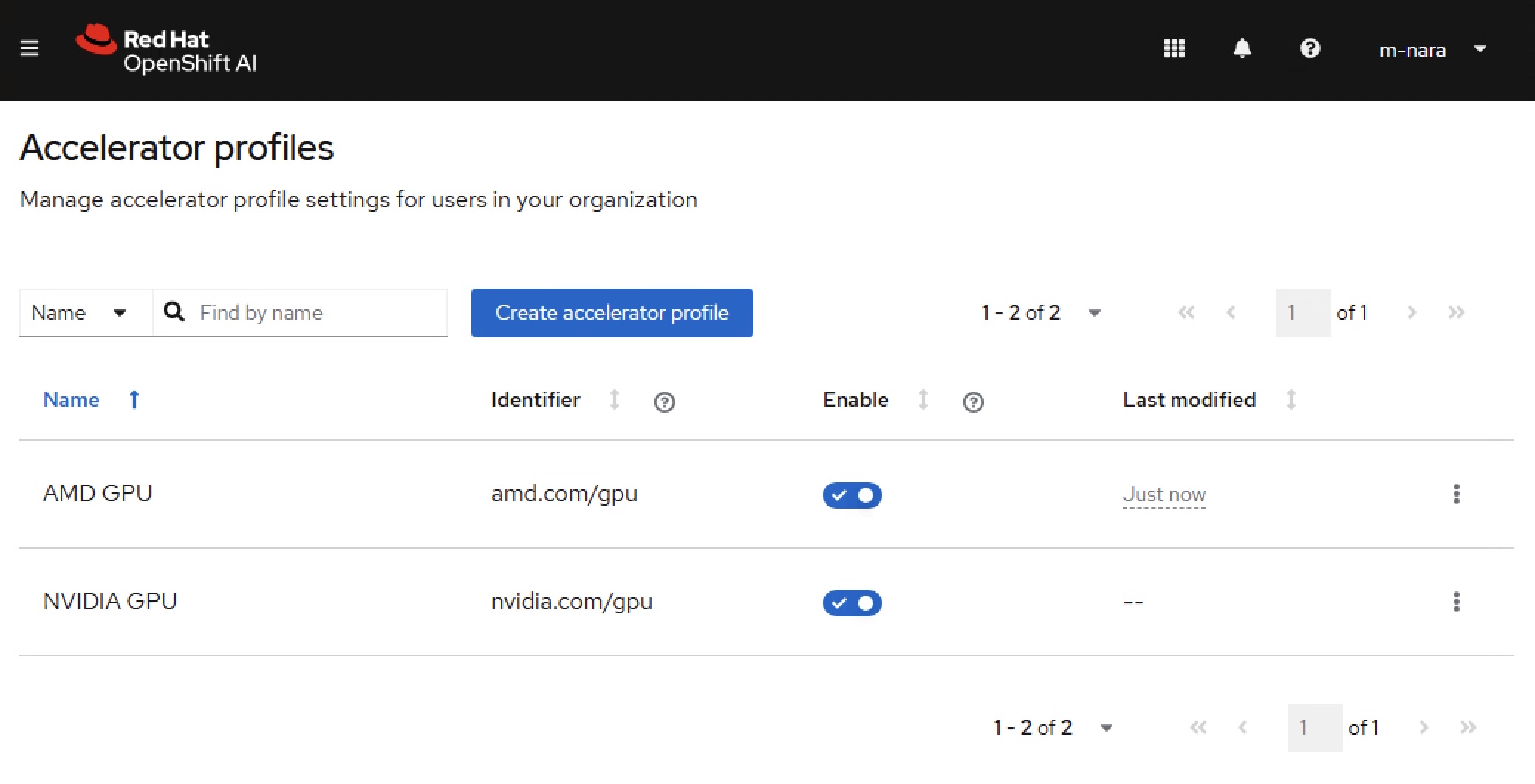
アクセラレータープロファイルの追加
OpenShift AIのアクセラレータープロファイルとしてAMD GPUリソース向けの識別子( amd.com/gpu )追加すると、OpenShift AI GUI上でアクセラレーターとしてAMD GPUの選択が可能になります。
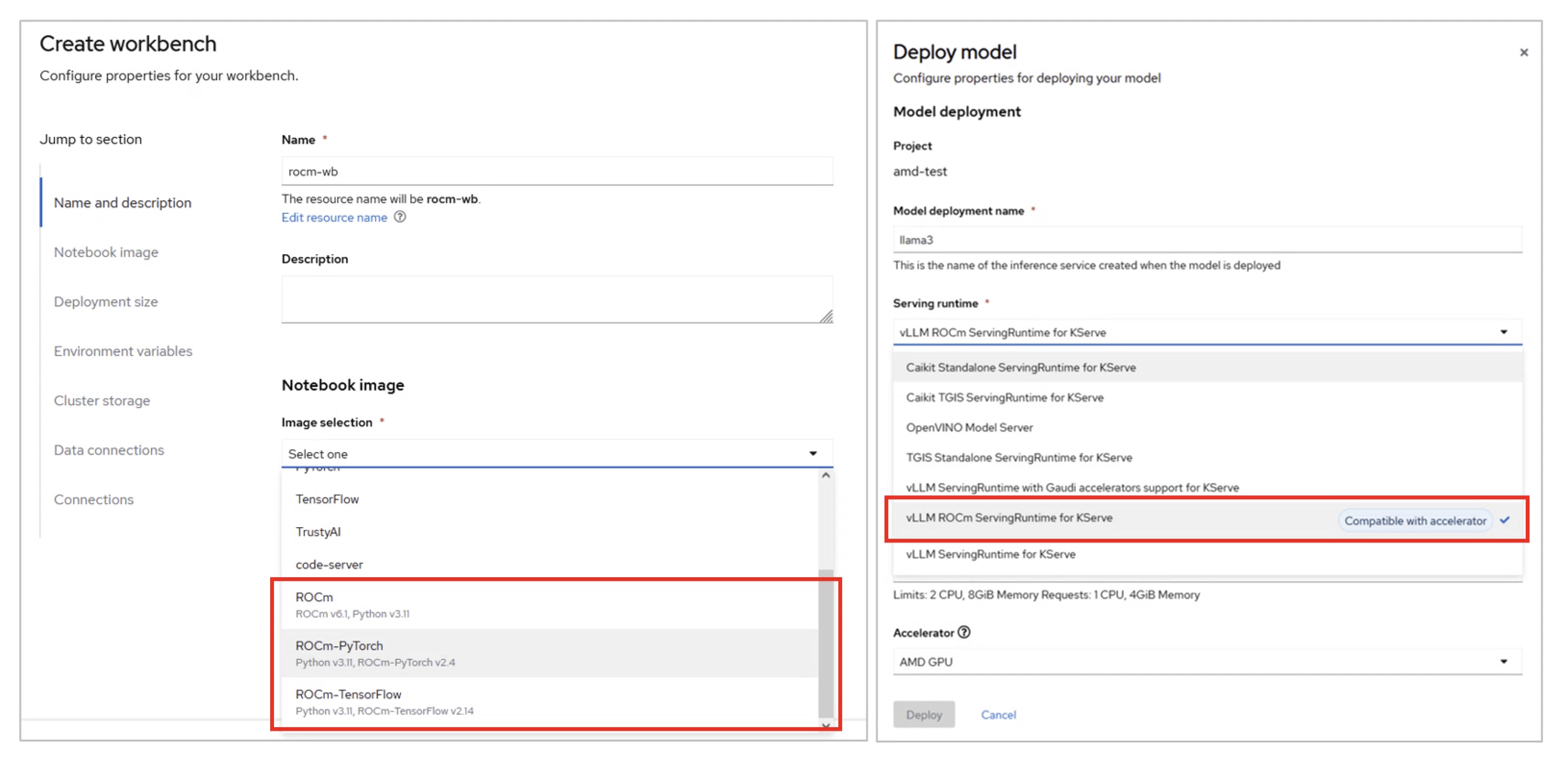
ROCm対応イメージの利用
OpenShift AIのWorkbenchやModel Servingのデプロイ画面を確認すると、以下のようにROCm対応のNotebook ImageやServing Runtimeの選択が可能となっており、上記で登録したアクセラレータープロファイルと組み合わせて利用することで、AMD GPUを利用したWorkbenchやモデルサービングが可能です。
まとめ
AI/MLの活用が進む中でOpenShiftやOpenShift AIはNVIDIA GPU以外のアクセラレーターへの対応を進めており、NVIDIA GPU以外のアクセラレーターを利用することが可能です。PytorchやTensorFlowがROCm対応を進めているため、これらのフレームワークを利用するアプリケーションはアクセラレーターの違いを意識することなくファインチューニングや、モデルサービングを行うことが可能です。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


