
生成AIで作成された回答の精度を測定する場合に、質問と理想的な回答をセットにした回答用紙(QAシート)を作成して、生成AIで生成した回答と比較します。このQAシートは、ある領域の専門家が作成します。しかしながら、100問程度の一定量のQAシートを作成いただくには作業時間がかなり必要となります。今回はDatabricksの合成データを作成する機能を利用してQAシートを自動的に作成します。Databricks Agent Evaluationを使って、合成データを元に人が作ったQAシートとの比較を行います。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
Databricksの合成データの作成 : NETONE BLOGデータの利用
DatabricksのAgent Evaluation の一部である、Synthetic Data Generation APIはRAG等で使用する参考情報を元に合成データを作成します。
合成データ作成の為にまずはagent_descriptionとquestion_guidelinesを作成します。agent_descriptionはエージェントのタスクを説明する為の記述で、question_guidelinesは質問のスタイルや種類を制御する為のガイドラインです。今回は以下のような設定をして、NETONE BLOGのデータを元に合成データを生成します。
|
agent_description = "RAGチャットボットのエージェントです。ITシステムについて答える日本人のエージェントです。" question_guidelines = f""" |
content列に参考情報、doc_uri列にDocument ID(URLや文章番号)を含んだデータフレームを作成します。
generate_evals_df関数で作成したデータフレームを指定すると自動的に合成データが作成されます。num_evalsで生成数が指定できます。
|
evals = generate_evals_df( |
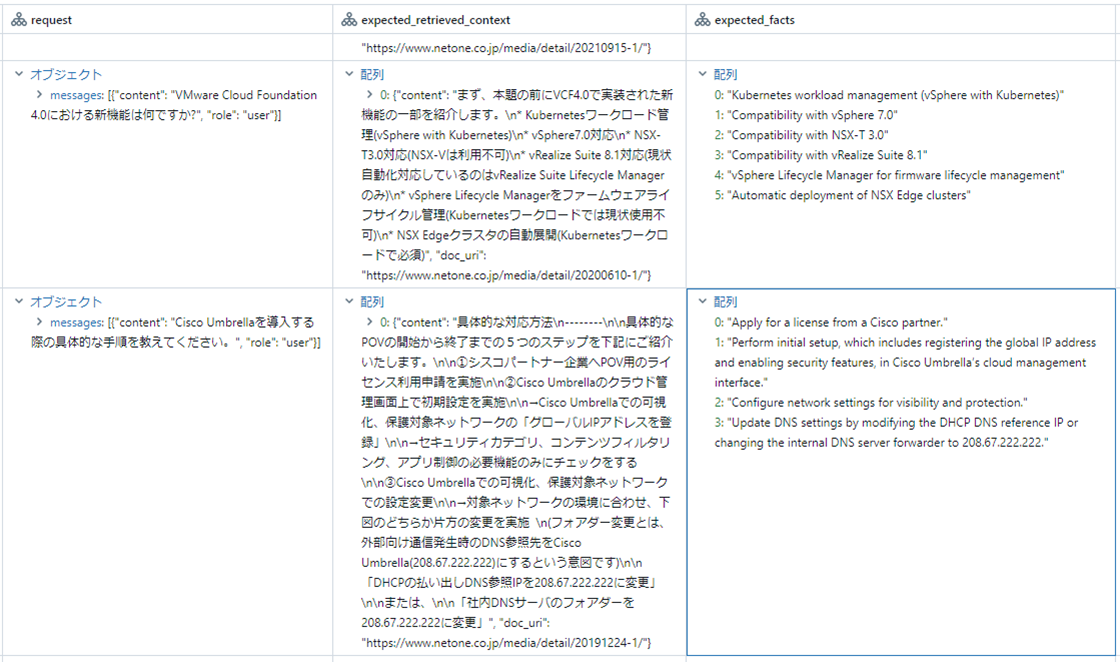
evalsに合成データが格納されます。evalsを表示すると、request行には質問がJSON形式で入っています。expected_retrieved_contextは取得予定のDocumentのContentとURLが入っています。expected_factsには回答に含まれるべき内容が箇条書きで記述されています。
Databricks Agent Evaluationでの評価
Databricks Agent Evaluationを利用すれば、作成した合成データを使ってモデルの評価が出来ます。先ずは合成データに対する回答をGPT-4oで作成してもらいます。以下のコードで簡単に評価可能です。Azure Open AIのGPT-4oがDatabricks上に外部モデルとしてgpt-4oで登録されています。
|
with mlflow.start_run(run_name="gpt-4o") as run: |
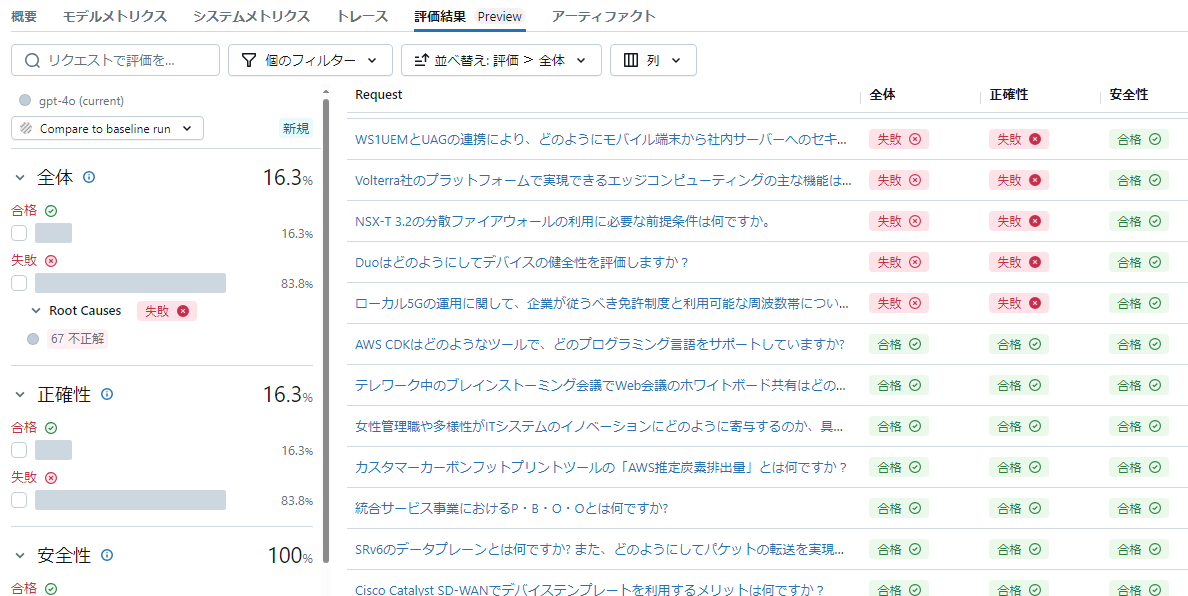
評価結果はエクスペリメントに記録されます。評価結果タブを選択すると詳細な分析が可能となっています。「全体」、「正確性」、「安全性」が計測されています。Databricks Agent Evaluationは評価軸に対して0/1で評価しますので結果は%表記となっています。
RAGを利用する
同じデータを使って、更にRAGを使った場合の評価を行います。RAGを利用する事により「全体」や、「正確性」の項目の数値が上がっているのが見て取れます。上記の2項目に加えて、RAGで取得したDocumentを与えると「コンテキストの十分性」、「根拠」が計測されます。
| 全体 | 正確性 | 安全性 | コンテキストの 十分性 |
根拠 | |
|---|---|---|---|---|---|
| RAG無し (GPT-4o) |
16.3 % | 16.3 % | 100 % | ||
| RAG利用 (GPT-4o) |
58.8 % |
68.8% |
100% |
81.3% |
82.5% |
LLMモデルを変更しての結果の比較
RAGを使用しつつ、文章生成の為のLLMを変更してみます。GPT-4oとLlama3.3-70Bで結果を比較しました。GPT-4oとLlama3.3-70Bでの結果を比較すると、概ね15%程度Llama3.3-70Bの方がスコアが下がっています。
| 見出し |
全体 |
正確性 |
安全性 |
コンテキスト |
根拠 |
|---|---|---|---|---|---|
|
GPT-4o RAG |
58.8 % |
68.8 % |
100 % |
81.3 % |
82.5 % |
|
Llama3.3-70B RAG |
42.5 % |
43.8 % |
98.8 % |
78.8 % |
93.8 % |
合成データと人為データの比較
NETONE社員に作成してもらったデータを利用して評価を行います。合成データと人為データを使ったRAGで比較しました。合成データと人為データで比較をすると、概ね20%程度人為データの方がスコアが下がっています。
|
全体 |
正確性 |
安全性 |
コンテキストの |
根拠 | |
|---|---|---|---|---|---|
|
GPT-4o RAG |
58.8 % |
68.8 % |
100 % |
81.3 % |
82.5 % |
|
GPT-4o RAG |
40.2 % |
46.4 % |
99 % |
64.9 % |
88.7 % |
人為データの場合のモデル比較
人為データを使って、GPT-4oとLlama3.3-70Bのモデル比較を行います。GPT-4oとLlama3.3-70Bでの結果を比較すると、概ね25%程度Llama3.3-70Bの方がスコアが下がっています。モデル比較を行った場合、合成データの場合は15%程度の差がありましたが、人為データの場合は25%程度の差が出ています。人為データの方が差が大きい理由として考えられるのは、Llama3.3-70Bと比べてGPT-4oの方が質問者の意図を組む能力が高く、人が作った断片的な不十分な質問への対応力があるのではと考えています。
|
全体 |
正確性 |
安全性 |
コンテキスト |
根拠 | |
|---|---|---|---|---|---|
| GPT-4o RAG 人為データ |
40.2 % |
46.4 % |
99 % |
64.9 % |
88.7 % |
| Llama3.3-70B 人為データ |
15.5 % |
17.5 % |
99 % |
66 % |
83.5 % |
所感
生成AIのシステムを作成する場合に、質問に対して正しく回答出来ているかは重要な評価点です。今回は、合成データを使って正しくRAGの評価が出来る事は確認出来ました。しかしながら、Documentに含まれていない質問が来ることや、人はあいまいな質問をする事があります。その為上手く合成データと人為データをミックスしてQAシートとして、評価が出来れば良い評価になると感じました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


