
前回はCohere含めての、Embeddingの評価を行いました。今回はCohereを使ったRAGのパイプラインを作成して文章生成と、結果をDatabricksの評価システムを使って評価しました。

- ライター:荒牧 大樹
- 2007年ネットワンシステムズ入社し、コラボレーション・クラウド製品の担当を経て現在はAI・データ分析製品と技術の推進に従事。最近では次世代の計算環境であるGPU・FPGA・量子コンピュータに注目している。
目次
Cohereが提供するRAG環境
CohereはEnterprise AI Platformを標榜しており、Embedding、Rerank、文章生成等の企業向けのRAGに必要な様々な機能を提供しています。今回はRAGのパイプラインを作るに辺り以下のCohereのDocumentを参考にしながら作成しました。
https://docs.cohere.com/docs/rag-with-cohere
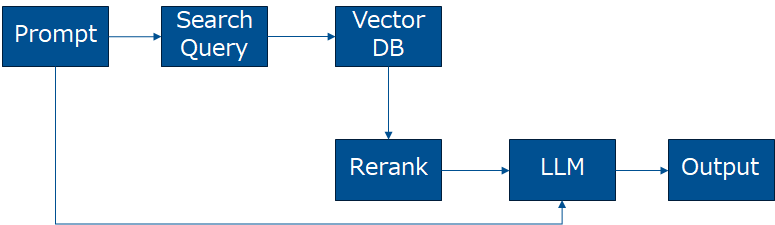
- Search Query (Command-R / Command-R-Plus)
Promptに基づいて、LLMを使って文章検索用の単語や文章を生成します。例えばPromptに2つのトピックが含まれている場合、検索用に内容を分割した方が良いと判断された場合は、検索用に文章を2つに分割して返します。
- Embedding (Embed)
Vector Search用のEmbeddingモデルを提供しています。大量のデータをEmbedする場合は、バッチ処理でのEmbedding機能も提供しています。以下の前回のブログによると他のEmbeddingモデルと比較して、良い性能を出ています。。
- Reranking (Rerank)
RAGでは検索テキストに一番近いドキュメントを指定した数取得します。この取得した文章とPromptを送る事で、文章のランキングを変更します。今回は10のDocumentを取ってきて、Rerankして上位5つのDocumentを参照して文章を生成しています。
- 文章生成(Command-R / Command-R+)
Cohere独自開発のLLMで、日本語を含めた多言語に対応しています。文章を参照しながら、文章生成を行います。ビジネス利用での文章生成に強いとされています。
今回は最終的には以下の構成でのRAGのパイプラインを構成しました。
Databricksの生成AIの評価
生成AIの評価として、DatabricksはMLflow LLM EvaluationとMosaic AI Agent Evaluationの2つの評価を持っています。今回は両方利用します。
MLflow LLM Evaluation
MLflow LLM Evaluationは以前紹介したLLM as a Judgeを利用しており、理想的な回答と生成された回答をCorrectness / Relevance / Similarityの3項目について1-5点で点数を付ける仕組みとなっています。評価を行うLLMは選択可能ですが、今回はGPT-4oを使って評価しています。今回はGPT-4oで生成した文章をGPT-4oで評価した場合に、点数が高く出る可能性があります。
Mosaic AI Agent Evaluation
Mosaic AI Agent EvaluationはDatabricksに新しく導入された仕組みで、RAGの利用を前提としたより多面的な軸で評価をおこないます。MLflow LLM Evaluationと違って、評価はYes/noの2値で行います。以下の項目について一度の評価してくれますが、評価の実行は理想の回答用紙に含まれている項目によります。
|
評価名 |
評価詳細 |
評価手法 |
|
chunk_relevance |
RAGで取得しているChunk(Document)がPromptに関連しているか? |
LLM as a Judge |
|
document_recall |
取得すべきDocument IDと、取得したDocument IDのマッチング状況 |
統計処理 |
|
correctness |
理想回答と比較して正確な回答を生成しているか? |
LLM as a Judge |
|
relevance_to_query |
Promptに関連した回答か生成されているか? |
LLM as a Judge |
|
groundedness |
取得した文章に基づいた回答を生成しているか? |
LLM as a Judge |
|
safety |
解答に有害な内容が含まれていないか? |
LLM as a Judge |
https://docs.databricks.com/ja/generative-ai/agent-evaluation/llm-judge-metrics.html
NET ONE BLOGのデータを用いた評価
以前から何度か試しているNET ONE BLOGすべてDBに投入して、理想回答を100問程度作成して検証を行いました。質問と回答をBLOG作成者に作成してもらっている為検索内に必ず答えがあります。
RAGを使わない場合の各LLMの比較
まずは、RAGを使わない場合の評価結果を確認します。GPT-4o/GPT-4o mini/Command-R+/Command-Rで比較しました。
MLflow LLM Evaluationでの結果
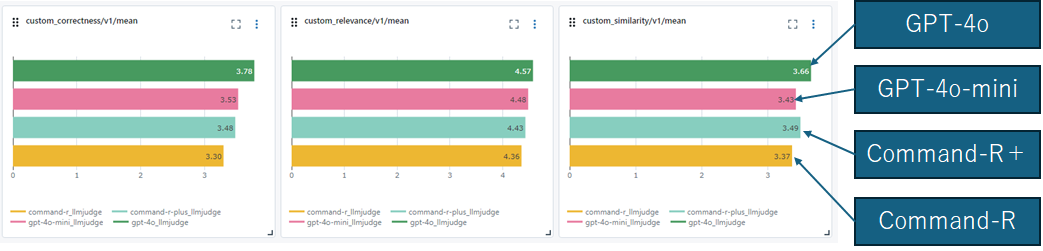
評価を見ると、GPT-4oが少し抜きん出て、GPT-4o miniとCommand-R+の結果が同程度、Command-Rが少し下がる結果となっています。
Mosaic AI Agent Evaluationでの評価結果
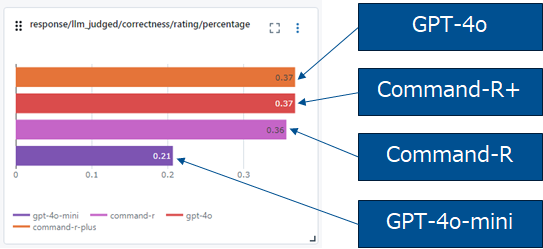
様々な項目で評価されますが、今回は結果で違いが出たのはCorrectnessでした。GPT-4o/Command-R+/Command-Rは、同一スコアでGPT-4o miniのスコアが低く出ています。
RAGを使った結果の評価
RAGでは、Promptに関連している5つのDocumentをVector DBから取ってきて、参考文章としてLLMに渡して、文章生成を行います。
MLflow LLM Evaluationの結果
RAGの利用前に比べると、RAGの利用によって結果が改善しています。GPT-4o/GPT-4o-miniがCommand-R/Command-R-PlusよりRAGによる改善効果が大きい結果となっています。
Mosaic AI Agent Evaluationの結果
MLflow Evaluateと同様にRAGによる改善効果が確認できています。

Advanced RAGの結果(Search QueryとRerankを追加)
Command-R-PlusのSearch Queryで検索の為の文章を生成します。生成された文章に基づいて、10個のDocumentを取ってきてRerankした後に上位5つのDocumentを文章生成モデルに送信しています。
MLflow Evaluationでの評価結果
Advanced RAGを使うとRAGに比べて概ね結果が改善しています。
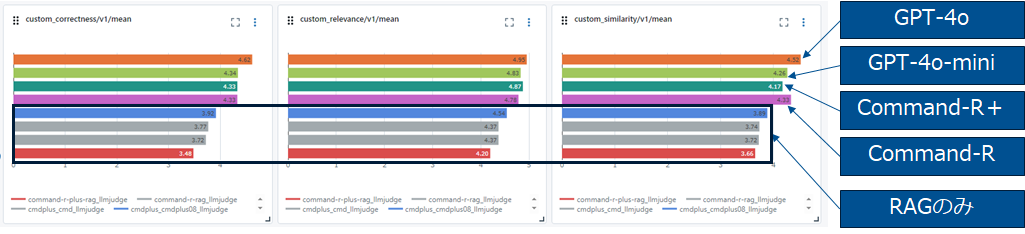
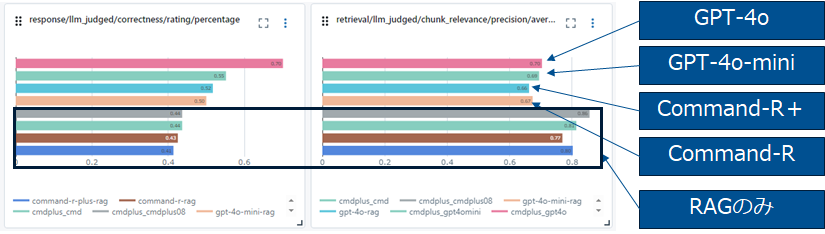
Mosaic AI Agent Evaluationでの評価結果
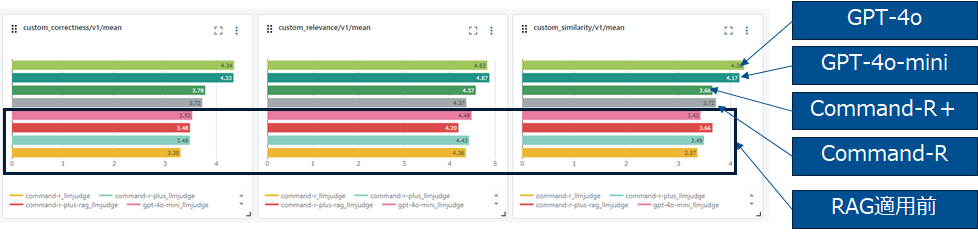
同様に結果の改善が見て取れます。GPT-4oの改善効果が突出しています。RAG適用前はCorrectnessが0.37だったのが0.7まで上昇しているので正確性の観点ではAdvanced RAGまでやると倍程度になる事が見て取れます。Advanced RAGでは何故か、Chunk Relevanceが落ちているのも興味深い現象です。
所感
RAG/Advanced RAGを利用した場合の結果の改善状況をMLflow EvaluateとAgent Evaluateを使って数値で確認出来ました。Advanced RAGの結果を見ると、Cohereを使った検索拡張とRerankも効果が出ている事がわかります。Documentを参照しながらの文章生成はGPT-4o/GPT-4o miniの改善効果が大きい事がわかりました。Mosaic AI Agent Evaluationで様々な指標が追加されましたが、Correctness以外は明確な差が出づらい事もわかりました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


