
Red Hat OpenShift AI(以下、OpenShift AI)はRed Hat OpenShift(以下OpenShift)上でAI/MLの開発・利用を推進するための機能を提供し、MLOpsプラットフォームを可能にします。本記事ではOpenShift AIを利用した開発環境の作成と、モデルサービングを利用したLLMの利用例をご紹介します。

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
Red Hat OpenShift AIとは
AI/ML開発で必要となるミドルウェア・ライブラリ・ドライバは非常に数が多く、これらの依存関係を担保し、環境の整備や維持を行うことは困難です。この課題を解決するためにAI/MLの開発にはコンテナ技術が活用されています。ミドルウェアやライブラリを動作可能な組み合わせとしてコンテナとしてパッケージ化して利用することで、AI/MLの開発を行うデータサイエンティストはデータの分析やモデルの開発に集中することが可能になります。更に、開発の中で繰り返し行う処理を、コンテナ化された実行環境上でパイプラインとして構成することで、データサイエンティストの業務量を大きく削減します。また、開発したモデルの提供にもコンテナが活用されており、コンテナイメージ化されたモデルサービング機能を利用することで、簡単にモデルを提供することが可能になります。
Red Hat OpenShift AI(以下、OpenShift AI)はRed Hat OpenShift(以下OpenShift)上で、こうしたAI/MLの開発・利用を推進するための機能を提供し、MLOpsプラットフォームを可能にします。本記事ではOpenShift AIを利用した開発環境の作成と、モデルサービングを利用したLLMの利用例をご紹介します。OpenShift AIはオープンソースとして開発されているOpen Data Hubをアップストリームとする製品です。
本記事作成にあたり利用しているOpenShift環境ではNVIDIA GPU Operatorにより、OpenShift上でGPUを利用可能にしています。GPU Operatorの利用方法はこちらの記事をご参照ください。
OpenShift AIのインストール
OpenShift AIはOperatorにより提供されており、DataScienceClusterリソースとして簡単に構成することが可能です。
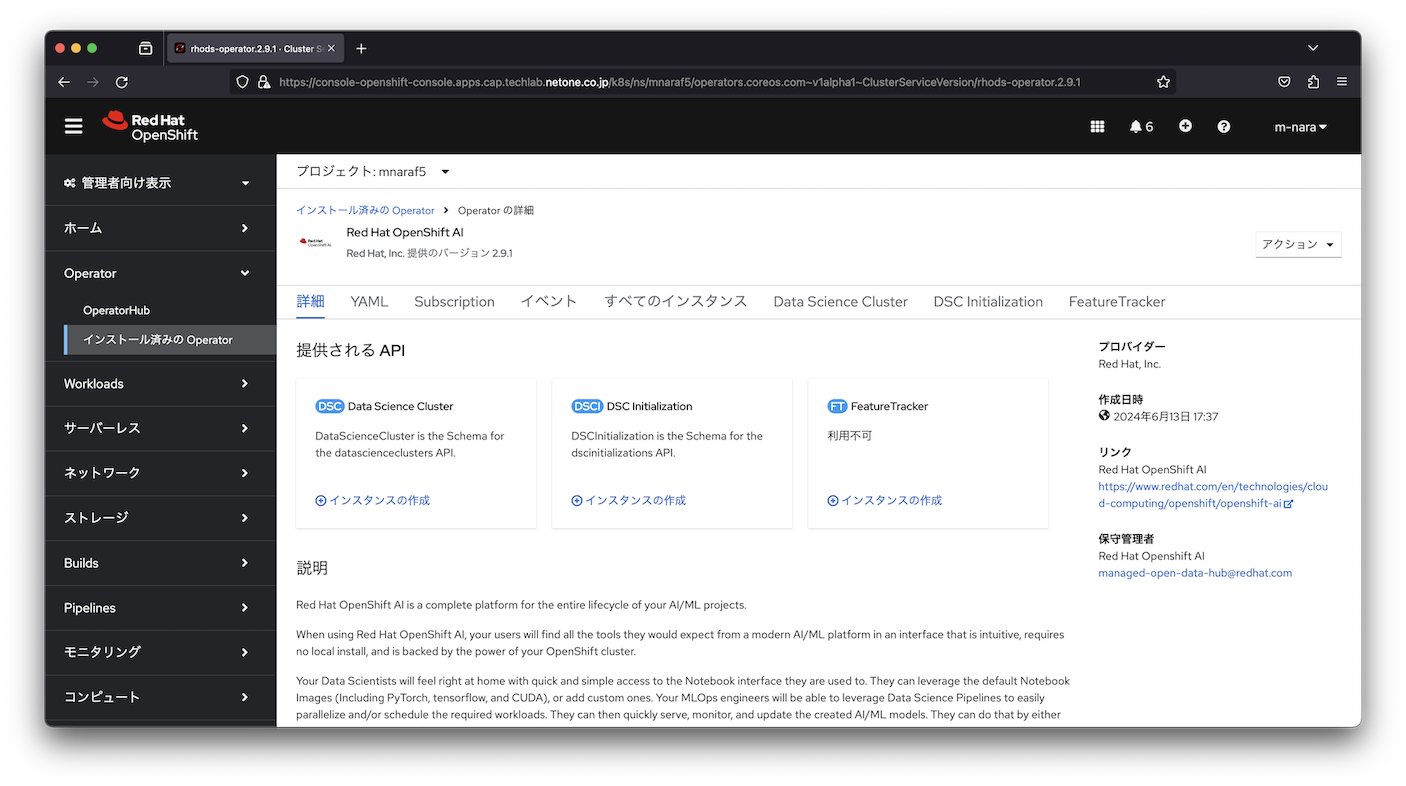
DataScienceClusterには、Jupyter Notebookを提供するnotebook-controller、モデルサービングを提供するkserve-controller・modelmesh-controller、分散学習に利用するcodeflare-operator・kuberay-operatorなど様々なコンポーネントが含まれています。
# oc get pod -n redhat-ods-applications
NAME READY STATUS RESTARTS AGE
codeflare-operator-manager-5f85fd77d7-8t52r 1/1 Running 0 31h
data-science-pipelines-operator-controller-manager-7ccc884zwt9x 1/1 Running 0 31h
etcd-5cd44cd8dd-9q6zd 1/1 Running 0 31h
kserve-controller-manager-5c76b6cc84-wb4v4 1/1 Running 0 31h
kuberay-operator-cc8c5c675-6w4n6 1/1 Running 0 31h
kueue-controller-manager-9b8989b44-p47n8 1/1 Running 0 31h
modelmesh-controller-d4fcbfc65-db7ml 1/1 Running 0 31h
modelmesh-controller-d4fcbfc65-hxt4k 1/1 Running 0 31h
modelmesh-controller-d4fcbfc65-kzds9 1/1 Running 0 31h
notebook-controller-deployment-6ff4cd5f8f-6x4tp 1/1 Running 0 31h
odh-model-controller-59db9f895b-6mg7k 1/1 Running 0 31h
odh-model-controller-59db9f895b-cl87b 1/1 Running 0 31h
odh-model-controller-59db9f895b-rpnvm 1/1 Running 0 31h
odh-notebook-controller-manager-5cd6659c4-cxk8b 1/1 Running 0 31h
rhods-dashboard-8f687bb85-6r7qt 2/2 Running 0 31h
rhods-dashboard-8f687bb85-bqxnv 2/2 Running 0 31h
rhods-dashboard-8f687bb85-fmzsb 2/2 Running 0 31h
rhods-dashboard-8f687bb85-pzfg9 2/2 Running 0 31h
rhods-dashboard-8f687bb85-v2q6s 2/2 Running 0 31h
学習環境(Notebook)の利用
データサイエンティストはJupyter Notebookを学習用環境として利用します。OpenShift AIにはKubeflow Notebook Controllerを拡張した「Workbench」機能があり、利用者がセルフサービスで安全にJupyter Notebookが利用できるようになっています。OpenShift AIにはNotebook向けのイメージも同梱されており、以下のイメージを利用可能です。
- Minimal Python
- Standard Data Science
- CUDA
- PyTorch
- TensorFlow
- TrustyAI
- HabanaAI
- Code-server
これらのイメージにはデータサイエンティストが利用するパッケージがあらかじめインストールされています。例えば、Tensorflow 2024.1であれば以下のパッケージがインストールされています。
TensorFlow v2.15, Tensorboard v2.15, Boto3 v1.34, Kafka-Python v2.0, Kfp v2.5, Matplotlib v3.8, Numpy v1.26, Pandas v2.2, Scikit-learn v1.4, Scipy v1.12, Odh-Elyra v3.16, PyMongo v4.6, Pyodbc v5.1, Codeflare-SDK v0.16, Sklearn-onnx v1.16, Psycopg v3.1, MySQL Connector/Python v8.3
Notebook環境は利用者自身がオンデマンドで作成することが可能です。作成時にはイメージの選択、Container sizeの指定(CPU、Memory割当のサイズ)、アクセラレーターの指定(GPUの有無)、Notebook環境の環境変数、永続ストレージの接続、Data Connectionを指定することが可能です。
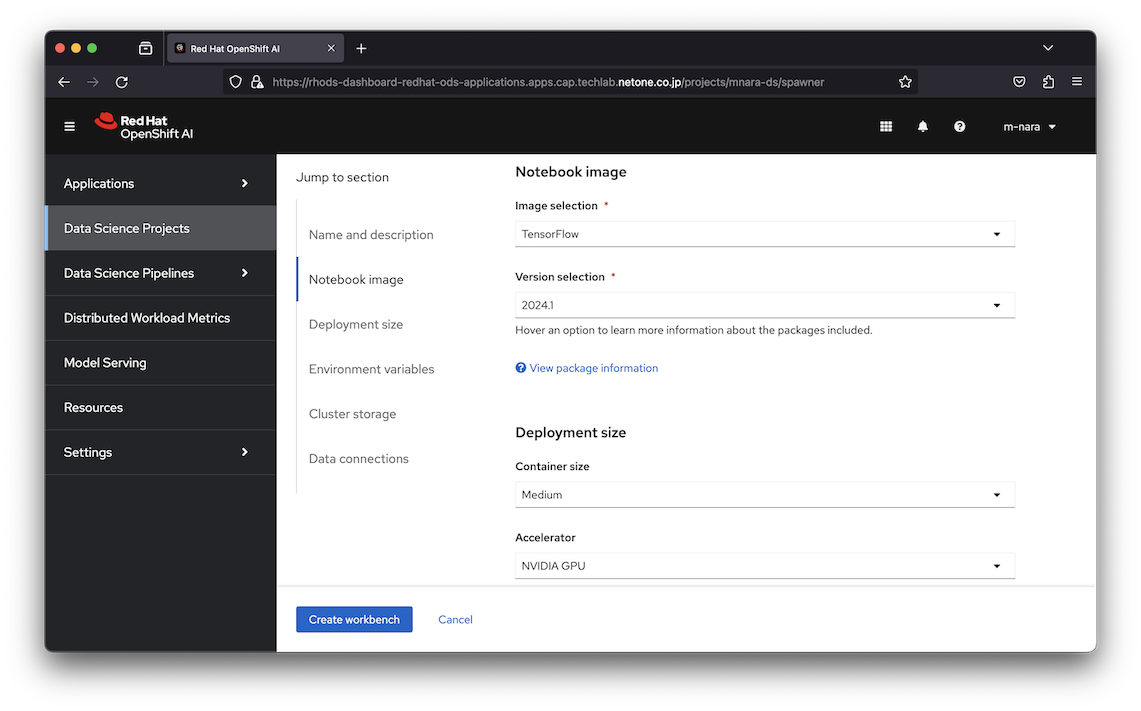
Workbenchを作成すると指定した構成でNotebookが起動し、利用可能になります。
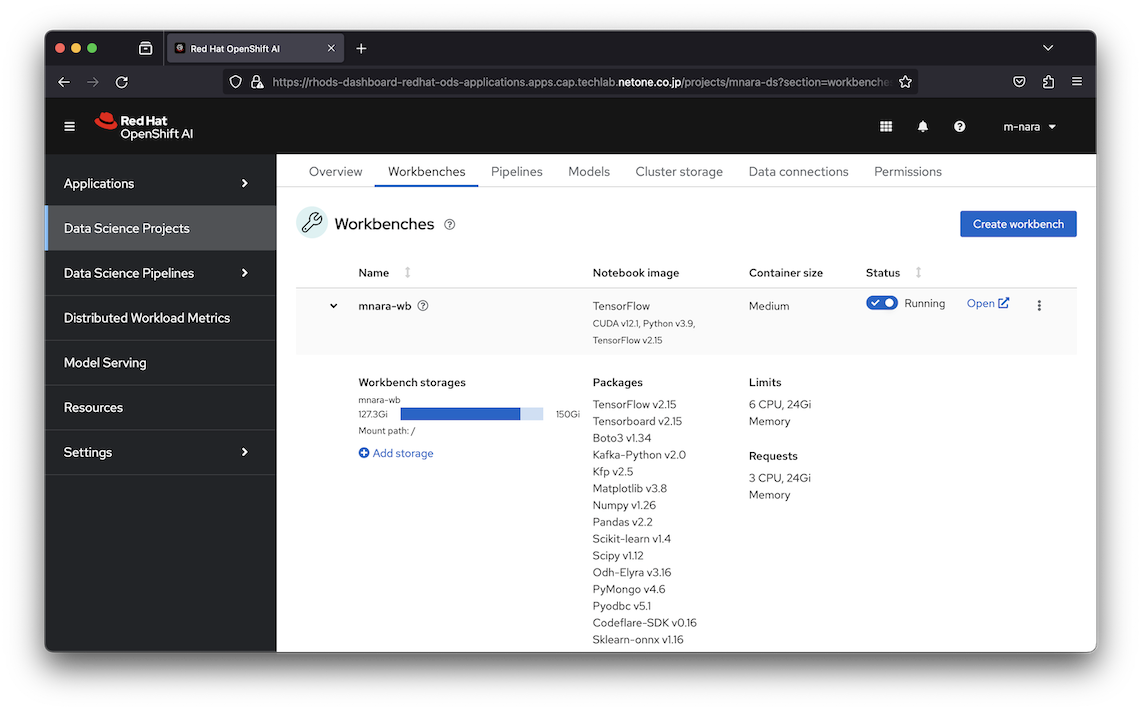
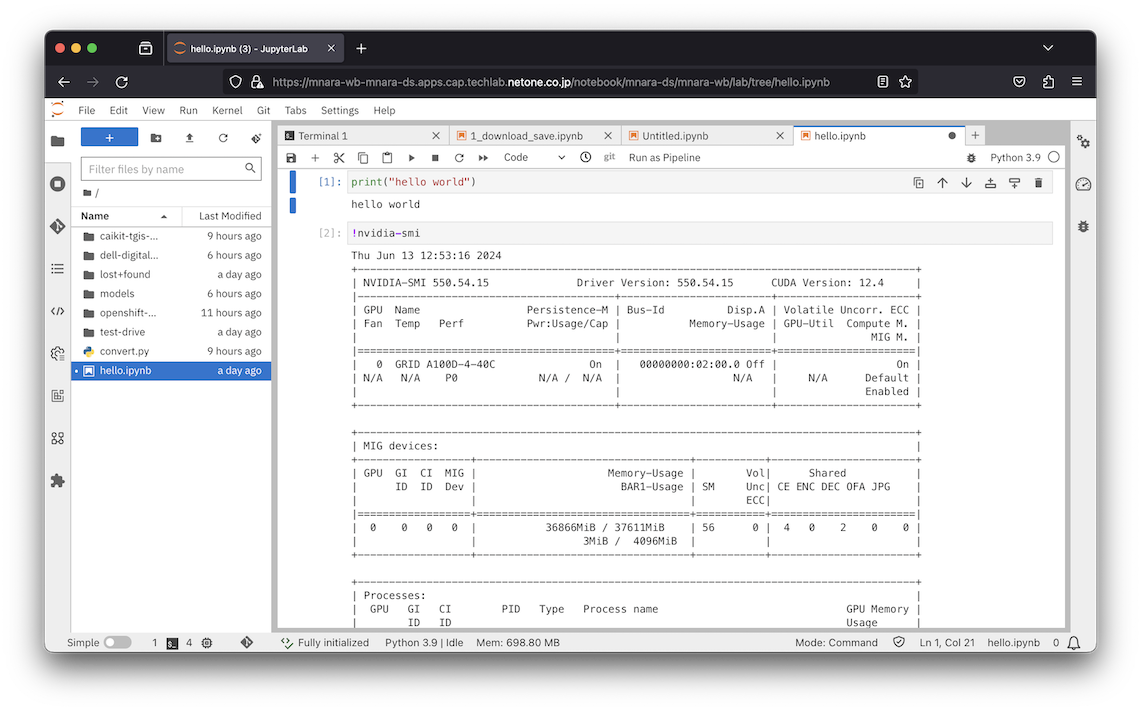
アクセラレーターとしてGPUを接続した場合、Notebook内からGPUを確認することが可能です。NotebookへのアクセスにはOpenShiftのOAuthが利用され、プロジェクトを共有する他のユーザーとNotebookを共有することができるため、安全に共同作業を行うことが可能です。
Data Connectionはオブジェクトストレージへの接続情報を管理するためのリソースです。以下の例は、オンプレミス環境のNetApp ONTAP S3に対する接続情報をData Connectionとして登録する例です。
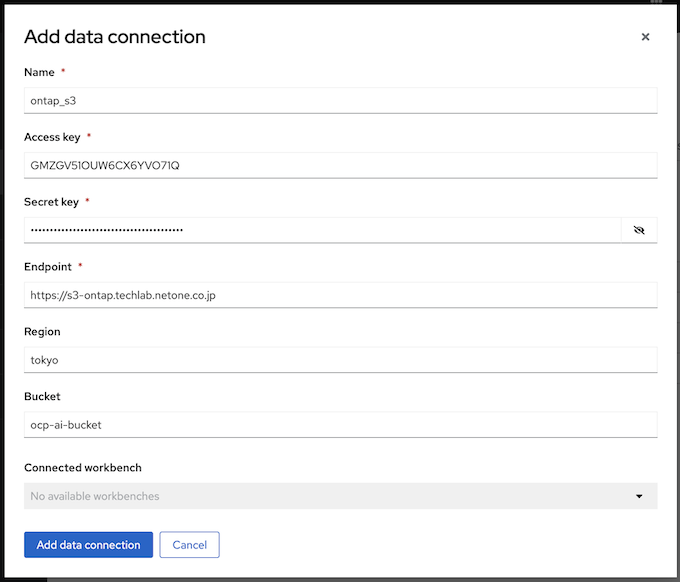
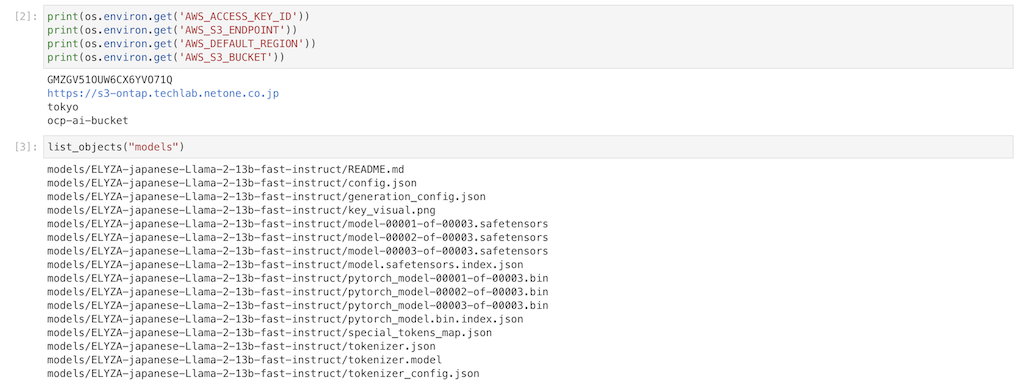
これらの値はOpenShift上にSecretとして登録され、Workbench内の環境変数として構成されるため、学習環境であるNotebook内で生成したモデルの保存や、既存モデルの参照などにオブジェクトストレージを利用することが可能になります。今回は株式会社ELYAZAがHuggingFaceで公開しているモデル (ELYZA-japanese-Llama-2-13b-fast-instruct)をNotebookにダウンロードし、Data Connectionを利用してオブジェクトストレージに保存しました。
モデルサービング
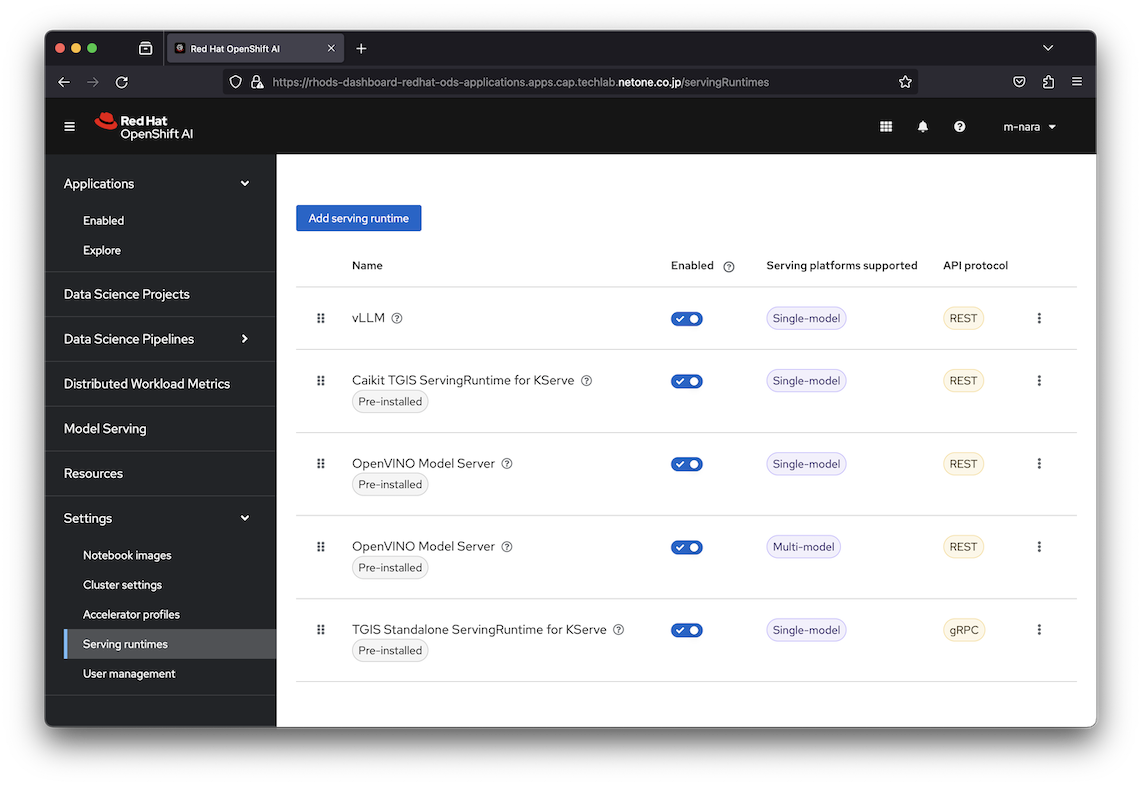
OpenShift AIの一部としてインストールされるKServeはモデルのサービング機能です。サービング機能は、モデルに対して外部からアクセスするためのAPIインターフェースを提供します。KServeはKnativeによりPodとしてモデルを展開し、Istioにより外部からアクセス可能なAPIを提供するため「Red Hat OpenShift Serverless」と「Red Hat OpenShift Service Mesh」オペレーターが利用されます。
OpenShift AIでは、以下の4種類のModel Serving Runtimeが提供されています。KServeは大規模なモデル向けのSingle-model Serving platformと、中小規模の複数のモデルを組み合わせてModel Meshを構成し、単一のサービスとして実行するMulti-model Serving platformを利用可能です。
- Caikit TGIS ServingRuntime for KServe (Single-model)
- TGIS Standalone ServingRuntime for KServe (Single-model)
- OpenVINO Model Server (Single-model)
- OpenVINO Model Server (Multi-model)
大規模なLLMのサービングには、Single-modelが利用されます。本記事ではオブジェクトストレージに保存したモデル (ELYZA-japanese-Llama-2-13b-fast-instruct)をvLLMで実行するため、Model Serving Runtimeとしてこちらを参考にvLLMを追加しました。
Serving runtimeとして追加したvLLMを指定し、AcceleratorとしてGPUを追加して、Model Servingを作成します。Model LocationはData Connectionを利用してHuggingFaceからダウンロードしたオブジェクトストレージ上のelyza/ELYZA-japanese-Llama-2-13b-fast-instructを指定しています。
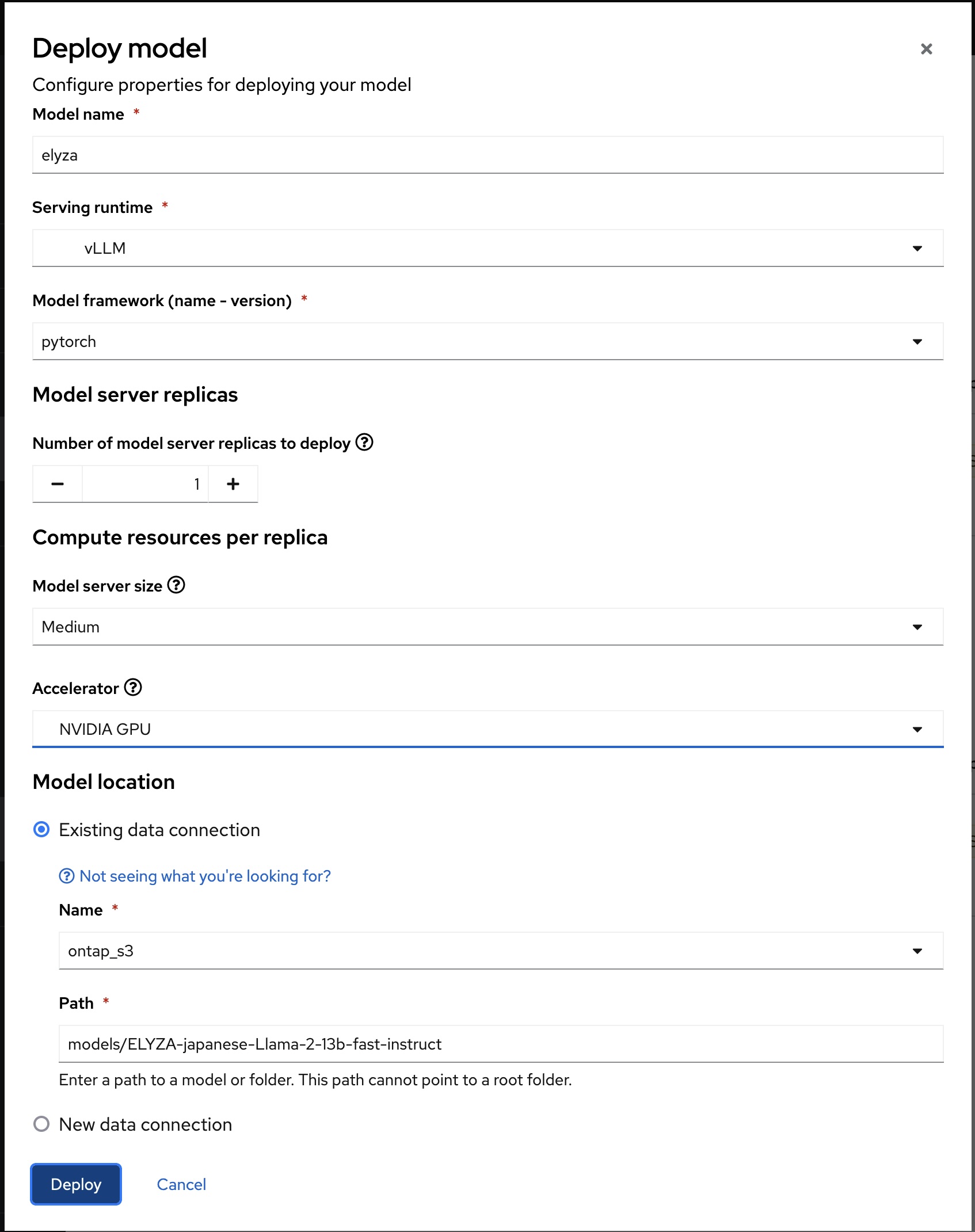
Model Servingを構成するとKServeのリソースであるInferenceServiceとServingRuntimeリソースが作成され、推論用のPodが起動します。このPodは起動時に指定したStorage Connectionを利用してオブジェクトストレージ上のモデルをPod内に格納し、IstioのvLLMによってモデルをサービングします。
# oc get inferenceservices.serving.kserve.io
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
elyza https://elyza-mnara-ds.apps.cap.techlab.netone.co.jp True 100 elyza-predictor-00001 2m3s
# oc get servingruntimes.serving.kserve.io
NAME DISABLED MODELTYPE CONTAINERS AGE
elyza pytorch kserve-container 2m21s
# oc get pod
NAME READY STATUS RESTARTS AGE
elyza-predictor-00001-deployment-64d4948886-rdg87 3/3 Running 0 2m23s
mnara-wb-0 2/2 Running 0 3h28m</span
モデルをサービングするために、InferenceServiceリソースに関連する形でKnativeやIstioのリソースが作成されています。
# oc tree inferenceservices.serving.kserve.io elyza
NAMESPACE NAME READY REASON AGE
mnara-ds InferenceService/elyza True 13m
mnara-ds ├─Service/elyza - 11m
mnara-ds ├─Service/elyza-metrics - 13m
mnara-ds │ └─EndpointSlice/elyza-metrics-wvh6l - 13m
mnara-ds ├─Service/elyza-predictor True 13m
mnara-ds │ ├─Configuration/elyza-predictor True 13m
mnara-ds │ │ └─Revision/elyza-predictor-00001 True 13m
mnara-ds │ │ ├─Deployment/elyza-predictor-00001-deployment - 13m
mnara-ds │ │ │ └─ReplicaSet/elyza-predictor-00001-deployment-64d4948886 - 13m
mnara-ds │ │ │ └─Pod/elyza-predictor-00001-deployment-64d4948886-rdg87 True 13m
mnara-ds │ │ ├─Image/elyza-predictor-00001-cache-kserve-container - 13m
mnara-ds │ │ └─PodAutoscaler/elyza-predictor-00001 True 13m
mnara-ds │ │ ├─Metric/elyza-predictor-00001 True 13m
mnara-ds │ │ └─ServerlessService/elyza-predictor-00001 True 13m
mnara-ds │ │ ├─Endpoints/elyza-predictor-00001 - 13m
mnara-ds │ │ │ └─EndpointSlice/elyza-predictor-00001-qg7s2 - 13m
mnara-ds │ │ ├─Service/elyza-predictor-00001 - 13m
mnara-ds │ │ └─Service/elyza-predictor-00001-private - 13m
mnara-ds │ │ └─EndpointSlice/elyza-predictor-00001-private-s4q6w - 13m
mnara-ds │ └─Route/elyza-predictor True 13m
mnara-ds │ ├─Ingress/elyza-predictor True 11m
mnara-ds │ │ ├─VirtualService/elyza-predictor-ingress - 11m
mnara-ds │ │ └─VirtualService/elyza-predictor-mesh - 11m
mnara-ds │ └─Service/elyza-predictor - 11m
mnara-ds ├─ServiceMonitor/elyza-metrics - 13m
mnara-ds └─VirtualService/elyza - 11m</span
UIを確認すると、Inference endpointが作成されており、このエンドポイントはIstioのVirtualServiceによって構成されています。
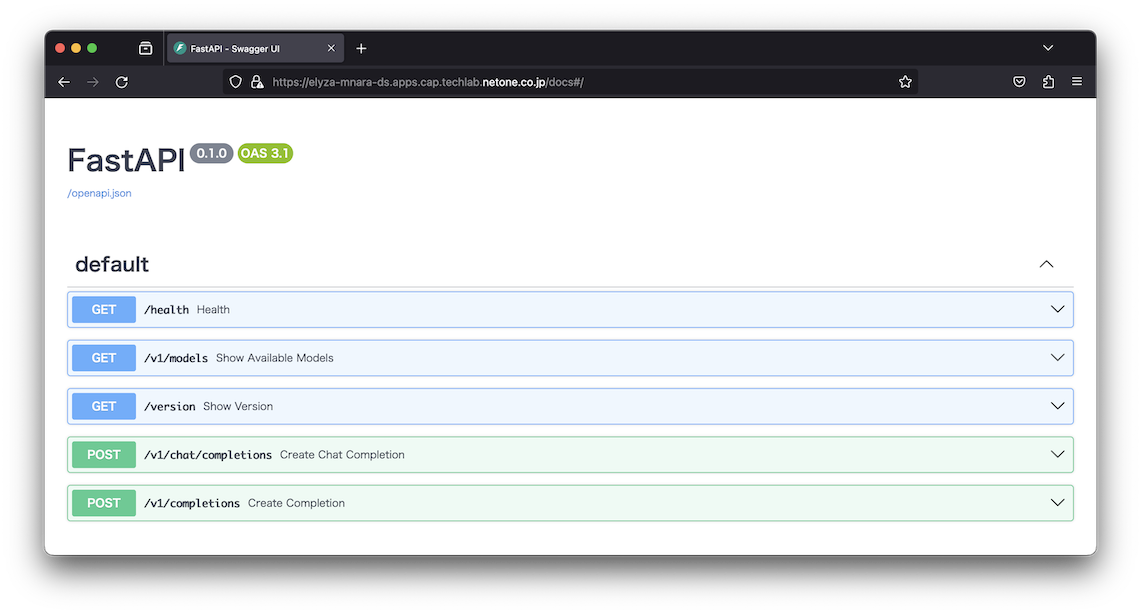
Inference EndpointではSwagger UIが有効になるため、ブラウザを利用してエンドポイントの確認が可能です。
curlでエンドポイントの動作を確認すると、文章が生成されていることが確認できました。
# curl -X POST -k https://elyza-mnara-ds.apps.cap.techlab.netone.co.jp/v1/completions -H "Content-Type: application/json" -d '{"model": "/mnt/models/","prompt": "[INST]<>あなたは誠実で優秀な日本人のアシスタントです< >お名前は?[/INST]","max_tokens": 200,"temperature": 0}'
{
"id": "cmpl-910ddd248dc24e959f0b262450ba3e30",
"object": "text_completion",
"created": 1718282560,
"model": "/mnt/models/",
"choices": [
{
"index": 0,
"text": " 私はELYZAによって訓練されたAIです。ユーザーからの質問に答えたり、様々なタスクを実行したりすることができます。",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 29,
"total_tokens": 57,
"completion_tokens": 28
}
}</span
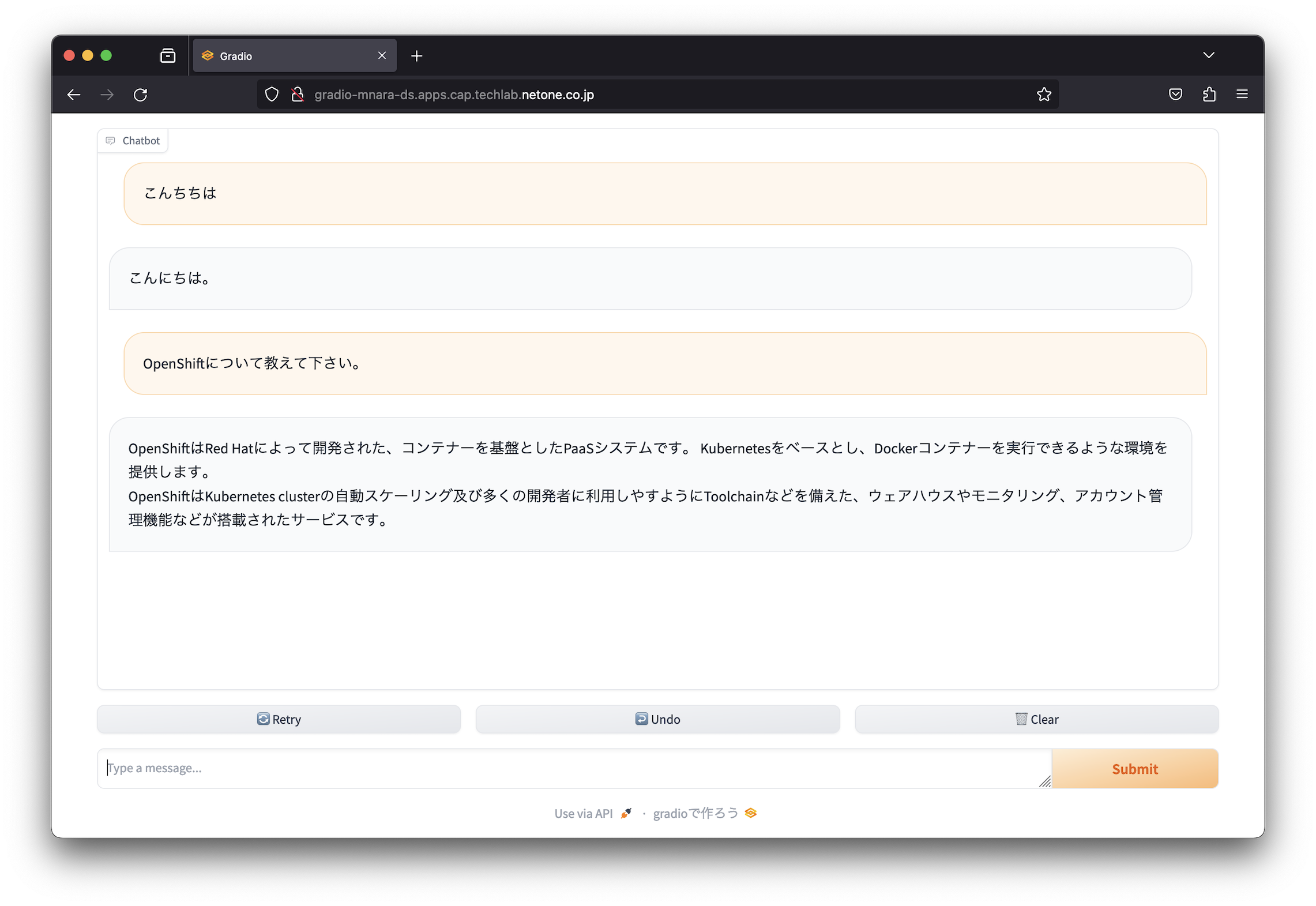
簡易的なUIをGradioで作成してPodとして実行することで、簡易的なチャットボットを作成することができました。
まとめ
本ブログ記事ではOpenShift AIを利用したノートブックとモデルサービング機能に関して簡単にご紹介しました。OpenShift AIを利用することで、Notebookによる実験や、モデルのサービング等、AI/ML開発に必要な環境をOpenShift上に簡単に構築できました。Jupyter NotebookやTensorFlow、PyTorch、Kubeflow等オープンソースとして開発されているメジャーなツールやフレームワークを活用することができるため、AI/ML開発者やデータサイエンティストにとって魅力的なMLOpsプラットフォームを提供し、企業におけるAI導入を加速するプラットフォームになりそうです。
今後、企業でのAI活用が進むにつれて、このようなMLOpsプラットフォームを自社で持つというニーズが高まることが予想されます。大規模なAI基盤の構築には、GPUやプラットフォームだけではなく、ネットワークも重要となります。ネットワンシステムズではネットワークやサーバー・GPUといったインフラストラクチャからプラットフォームまで、お客様のAI基盤の導入をご支援させていただいています。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


