本記事では、RapidMiner Studioを用いたRetrieval Augmented Generation (RAG)の構築方法を紹介します。

- ライター:大河原 昂也
- 2021年、ネットワンシステムズに入社。現在は主にクラウド、インフラ管理、自動化を担当。
目次
はじめに
こちらの記事にて、RapidMiner Studioの「Generative Models」機能を紹介しました。今回は、この「Generative Models」機能を用いて、Retrieval Augmented Generation (RAG)を構築します。RapidMinerの公式ドキュメントを参考に行います。なお、使用するRapidMiner Studioのバージョンは10.3系です。上記のNET ONE BLOGでは10.2系で行ったため、「Send Prompt」オペレータのパラメータ設定などが異なります。
RAGについて
ChatGPTに代表される大規模言語モデルを用いたサービスは、プロンプトに基づきあらゆる自然言語タスクを処理できる一方、最新ニュースや社内資料などの知らない情報を扱うことはできません。RAGはこのような問題に対処する方法として知られています。RAGの基本的な枠組みは、事前定義したベクトルデータベースから必要な情報を取得し、その情報を踏まえてLLMに指示するというものです。ベクトルデータベースは、ある情報と意味的に関連する情報をベクトル類似度から見つけることが可能なデータベースです。RAGでは、このベクトルデータベースにLLMが未学習の情報をあらかじめ格納します。ベクトルデータベースの基本的な作成方法は、以下のとおりです。
- LLMが未学習の文章から文字列を分割
- 分割された文字列がエンベディングモデルによりベクトル化
- そのベクトルをベクトルデータベースに格納
ユーザがRAGを利用するときの基本的な流れは以下のとおりです。
- ユーザはプロンプトを作成
- エンベディングモデルがそのプロンプトをベクトル化
- ベクトルデータベースの中からそのベクトルに類似する文章を取得
- この文章を文脈として新たにプロンプトを構成
- 新たに構成されたプロンプトをLLMに入力し、何かしらの出力をユーザが取得
このようにRAGはLLMの知らない情報をうまく補完することで、ユーザを支援できます。RAGを活用することで、社内情報の検索性向上、顧客へのQ&A対応の品質向上などにつながります。
RAGの構築と出力結果
本記事では、gpt-3.5-turboが知らない日本野球機構(NPB)の2023年11月6日から2024年3月11日までの移籍情報を補完するRAGをRapidMiner Studioによって構成します。その後、RAGによって作成された質問に対するgpt-3.5-turboの回答結果を確認します。
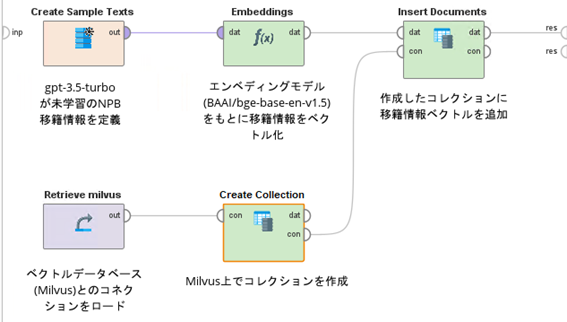
まず、RAGの構築ワークフローを図1に示します。
図1:RAG構築ワークフロー
図1の「Create Sample Texts」オペレータには、図2のようにNPB移籍情報をもとに作成した文章を格納しています。

図2:NPB移籍情報をもとに作成した文章(一部)
図1の「Embeddings」オペレータは、「Embeddings (FastEmbed)」オペレータをリネームしたものです。このオペレータは、エンベディングモデルをもとに図2の文章情報をベクトル化します。モデルは選択式で選べますが、ここでは「BAAI/bge-base-en-v1.5」を用いています。
図1の「Retrieve milvus」オペレータは、事前にRapidMiner Studioで定義しているベクトルデータベースMilvusとのコネクション(コネクション名はmilvus)をロードしています。コネクションのタイプは「Dictionary」で、事前に作成したMilvusのインスタンスのURI(http://<IPアドレス or hostname>:<Port>)を「uri」キーで格納しています。また、「token」キーには<user>:<password>を格納しています。本記事執筆時点では、RapidMiner StudioはMilvusのほかにQdrantにも対応しています。
図1の「Create Collection」オペレータは、「Create Collection (Milvus)」オペレータをリネームしたものです。このオペレータは、コレクション(類似の特性や用途を持つベクトルを保存するための場所)を任意の名称でMilvus上に作成します。「Insert Documents」オペレータは「Insert Documents (Milvus)」オペレータをリネームしたものです。このオペレータは、作成したコレクションにエンベディングモデルがベクトル化した情報を追加します。このようにRapidMiner Studioではオペレータを組み合わせることで簡単にRAGが構築できます。
次に、RAGを用いて質問文を再作成し、それをgpt-3.5-turboに投入するワークフローを図3に示します。
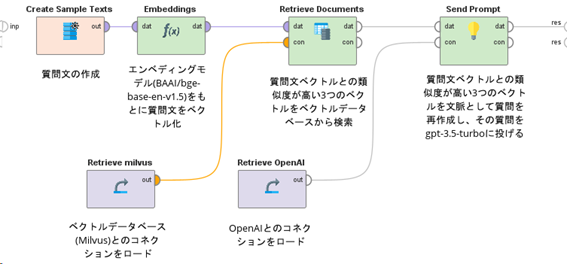
図3:RAGを用いた質問文投入ワークフロー
図3の「Create Sample Texts」オペレータには、図4のようにオリジナルの質問文を格納しています。

図4:オリジナルの質問文情報
図3の「Embeddings」オペレータと「Retrieve milvus」オペレータは図1のものと同じです。図3の「Retrieve Documents」オペレータは「Retrieve Documents (Qdrant)」オペレータをリネームしたものです。このオペレータは、図4の質問文から生成されるベクトルと類似度が高い3つのベクトルをベクトルデータベースから検索する役割があります。
図3の「Retrieve OpenAI」オペレータは、事前にRapidMiner Studioで定義しているOpenAIとのコネクション(コネクション名はOpenAI)をロードしています。コネクションのタイプは「Dictionary」で、OpenAIのAPIキーを「api_key」キーで格納しています。図3の「Send Prompt」オペレータは、「Send Prompt (OpenAI)」オペレータをリネームしたものです。
このオペレータは、「Retrieve Documents」オペレータで計算される類似度が高い3つのベクトルを文脈として質問を再作成し、その質問をgpt-3.5-turboに入力します。図5は、「Send Prompt」オペレータにおける「prompt」パラメータの中身です。

図5:「prompt」パラメータの中身
[[query]]が図4記載の質問文で、[[result_1_Texts]]が[[query]]と類似度の1番高い文章です。[[result_2_Texts]]、[[result_3_Texts]]は、それぞれ類似度が2番目、3番目となる文章です。
図3で示したワークフローを起動すると、図6の結果が得られました。

図6:回答結果
「query」列にオリジナルの質問文、「answer」列に回答結果が格納されています。山川選手は、2023年シーズンオフにFA宣言で福岡ソフトバンクホークスに移籍したため、意図した回答が得られていることがわかります(RAGを使わず、gpt-3.5-turboに上記の質問をしたところ、「読売ジャイアンツ」という回答でした)。なお、類似度の高い文章はそれぞれ
- [[result_1_Texts]]:「山川 穂高は福岡ソフトバンクホークスに所属するプロ野球選手です。」
- [[result_2_Texts]]:「元山 飛優は埼玉西武ライオンズに所属するプロ野球選手です。」
- [[result_3_Texts]]:「長谷川 威展は福岡ソフトバンクホークスに所属するプロ野球選手です。」
でした。たしかに類似性のある文章がベクトルデータベースからピックアップされています。
まとめと今後の展開
本記事では、RapidMiner Studioの「Generative Models」機能を用いてRAGを構成しました。そして、それを用いることでgpt-3.5-turboの知らない情報に対して、意図した回答が得られることを確認しました。しかし、実装したフローでは、ベクトルデータベースに格納する文章データを適宜作成する必要があります。加えて、RapidMiner Studio上でプロンプトを定義する必要もあります。そのため、実用的に使うにはもう少し工夫が必要です。RapidMiner AI-Hubを用いることでプロセスのバッチ処理やAPIによる外部連携が可能になります。
つまり、AI-Hubを利用することで、指定のストレージから最新ファイルを定期的に読み込み、そこで得られる文書をベクトル化し、その情報をベクトルデータベースに格納したり、コラボレーションツールへのチャットをトリガーにRAGワークフローを利用したり、などが想定できます。今後は、AI-Hubと連携し、より実用的な仕組みを作成したいと思います。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


