
本記事は、RapidMiner Studioで使用可能な大規模言語モデル連携オペレータを紹介します。

- ライター:大河原 昂也
- 2021年、ネットワンシステムズに入社。現在は主にクラウド、インフラ管理、自動化を担当。
目次
1章 はじめに
RapidMiner StudioはAltair Engineeringが提供するワークフローデザイナー型のデータ分析ツールです。機能をもつブロック(RapidMiner Studioではオペレータとよぶ)をつなげることで、様々な処理をシンプルにGUIで記述することができます。詳細は、こちらをご覧ください。2023年、新たに「Generative Models」とよばれる大規模言語モデルとの連携機能が拡張機能として登場しました。本記事は、この「Generative Models」を紹介します。一部、実際に動かし挙動を確認しました。
2章 「Generative Models」の紹介
前述のとおり、「Generative Models」はRapidMiner Studioの拡張機能のひとつです。この機能により、RapidMiner StudioからOpenAIとHuggingface(詳細は2.2節)上の大規模言語モデルを利用することができ、自然言語関連のタスク(要約、テキスト分類、翻訳など)を簡単に処理することができるようになります。本章では、OpenAIとの連携、Huggingfaceとの連携と2節に分けて各機能についてご紹介します。
2.1節 OpenAIとの連携
まず、OpenAIとの連携についてです。「Generative Models」はgpt-4などのOpenAIモデルへのプロンプト送信オペレータやファインチューニングオペレータなどを提供します。プロンプトに基づくタスク処理だけではなく、OpenAIモデルのファインチューニングもGUI操作で実現できます。OpenAIとの接続は、OpenAIアカウントのOrganization IDとAPIキーがあれば行うことができます(API利用には基本的に料金がかかるため、Billingの設定も必要です)。
今回は、gpt-4を用いたテキスト文章の要約タスクを行います。国土交通省が公表する自動車の不具合情報をデータとして用います。このデータには、いつ、どの車で、どのような不具合が発生したかなどが記載されています。また、「申告概要」列には、不具合の詳細情報がテキストで書かれています。例えば、「満タン給油をすると、車室内でガソリン臭がする。」、「アイドリングストップから復帰時にエンジンストップし、油圧警告灯が点灯する。」などです。本記事では、RapidMiner Studioからgpt-4を使用することで、「申告概要」列の情報をもとに自動車の故障個所を予想させてみました。
今回使用したワークフローは図1のとおりです。「Send Prompt」がOpenAIモデルへのプロンプト送信オペレータを表します。
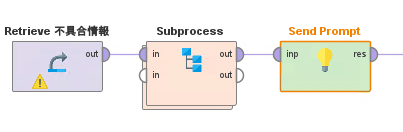
図1:自動車の故障箇所を予想するワークフロー
また、「Send Prompt」のパラメータは図2のように設定しました。
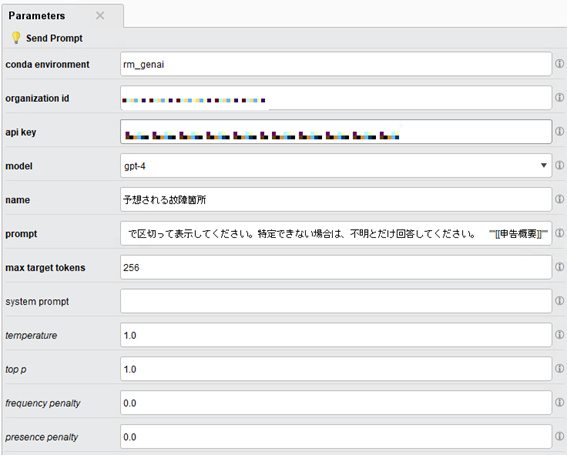
図2:「Send Prompt」のパラメータ
それぞれのパラメータは何を表すか、一部かいつまんで記載します。
- conda environment:使用するconda環境名
- organization id:OpenAIアカウントのOrganization ID
- api key:作成したOpenAIのAPIキー
- model:使用するモデル(選択式)
- name:プロンプトの回答が格納される列名
- prompt:プロンプト
ここでは、「prompt」の詳細のみを説明します。「prompt」には、モデルに送るプロンプトを記載します。上の設定では、「""""内の文章から、自動車の故障部品を特定したいです。自動車のパーツ名を名詞形で回答してください。複数ある場合は、「、」で区切って表示してください。特定できない場合は、不明とだけ回答してください。 ""[[申告概要]]""」と記載しています。[[列名]]を用いることで、参照する列名を指定できます。その他のパラメータの詳細に関しては、公式ドキュメントに記載されています。また、このページにはconda環境の準備方法なども記載されていますので、適宜ご参照ください。
図1のワークフローを実行した結果を図3に示します。左側の列に「申告概要」が記載されています。また、右側の「予想される故障箇所」列にgpt-4の回答結果が記載されています。

図3:自動車の故障箇所を予想するワークフローの実行結果
一部抜粋したものを以下に記載します。「申告概要」→「予想される故障箇所」という風に表記しています。
- 「レーンディパーチャーアラートが過剰作動する。」→「レーンディパーチャーアラート」
- 「右ヘッドライトが異常振動することに気が付き、ディーラーに対応を求めたところ、ライトの光軸調整用アクチュエーターの不良であるとのことで、交換の見積もりが提示されている。」→「右ヘッドライト、光軸調整用アクチュエーター」
- 「満タン給油をすると、車室内でガソリン臭がする。」→「燃料タンク、燃料ライン」
以上のとおり、おおむねそれらしい回答が得られていることがわかります。
2.2節 Huggingfaceとの連携
次に、Huggingfaceとの連携について述べます。Huggingfaceは、機械学習モデルやデータを共有するプラットフォームです。自然言語処理で有名なTransformerなどもHuggingfaceで利用することができます。「Generative Models」はHuggingfaceにある様々なモデルをGUI操作だけで簡単に利用できます。本記事では、FinBERTというモデルを用いて、弊社の直近8回の決算短信における「損益の状況」の金融感情分類を行います。FinBERTはBERTモデルを金融ドメインに対応するよう再事前学習させたモデルです。また、金融感情分類は、金融関連のテキストをポジティブ、ネガティブ、中立と分類するタスクを指します。
今回使用したワークフローは図4のとおりです。「Send Prompt」は2.1節で述べたOpenAIモデルにプロンプトを流すオペレータです。ここでは、「損益の状況」を英訳する役割を果たします。FinBERTは日本語には対応していないため、この処理を入れています。そして、「Text Classification」がFinBERTによる金融感情分類の役割を担います。
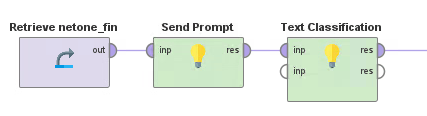
図4:金融感情分類ワークフロー
「Text Classification」におけるパラメータは、図5のとおりです。「model」には、Huggingfaceのどのモデルを使用するかを入力します。
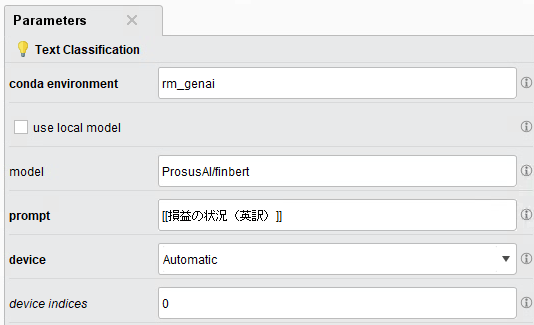
図5:「Text Classification」のパラメータ
実行結果は、図6のとおりです。決算短信ごとの金融感情分類の結果が「prediction」列で確認できます。「confidence_*」列は中立、ポジティブ、ネガティブそれぞれにおけるソフトマックス関数の出力値です。この値が一番大きいものが分類結果となります。例えば、2023年度のQ3では「confidence_positive」が最大なので、「prediction」がpositiveになります。
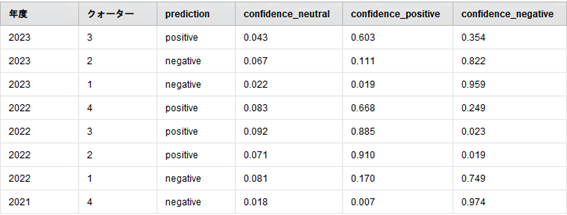
図6:金融感情分類ワークフローの実行結果
ポジティブな分類が顕著である2022年度の2Q(confidence_positive=0.910)を確認してみます。この時の「損益の状況」は、「売上高の増加に伴い、売上総利益は229億63百万円(前年同四半期比4.0%増)となりました。販売費及び一般管理費が146億44百万円となった結果、営業利益は83億19百万円(前年同四半期比84.1%増)、経常利益は86億83百万円(前年同四半期比78.1%増)、親会社株主に帰属する四半期純利益は51億75百万円(前年同四半期比52.6%増)となりました。」です。要するに、前年同四半期に比べ、
- 売上高が増加した
- 売上総利益が増加した
- 営業利益が増加した
- 経常利益が増加した
- 親会社株主に帰属する四半期純利益が増加した
ということです。FinBERTの言うとおり、ポジティブな内容です。
次に、ネガティブな分類が顕著である2021年度の4Q(confidence_negative=0.974)を確認してみます。この時の「損益の状況」は、「機器納期の長期化の影響で約120億円にわたる複数案件の売上時期が遅延したことで、売上総利益は517億86百万円(前年同期比7.4%減)となりました。販売費及び一般管理費が349億95百万円(前年同期比3.4%減)となった結果、営業利益は167億90百万円(前年同期比14.7%減)、経常利益は168億32百万円(前年同期比7.6%減)、親会社株主に帰属する当期純利益は112億25百万円(前年同期比8.9%減)となりました。成長戦略に沿って、受注高をはじめとして好調に事業が推移したものの、機器納期の長期化によって売上時期が遅延したことで、中期事業計画期間の目標とした、売上高2200億円、営業利益210億円、営業利益率9.5%、サービス比率50.0%、ROE16.8%には至りませんでした。」です。要するに、機器納期の長期化の影響によって前年同期に比べ、
- 売上総利益が減少した
- 営業利益が減少した
- 経常利益が減少した
- 親会社株主に帰属する当期純利益が減少した
- ROEなどの各指標が目標を達成しなかった
ということです。こちらもたしかにネガティブな内容に感じます。
最後に、ばらつきが比較的大きそうな2023年度の3Q(confidence_positive=0.603、confidence_negative=0.354)を確認してみます。この時の「損益の状況」は、「売上高及び売上総利益率が前年同四半期比で改善したことで、売上総利益は370億27百万円(前年同四半期比7.1%増)となりました。販売費及び一般管理費が249億32百万円となった結果、営業利益は120億95百万円(前年同四半期比7.1%減)、経常利益は116億36百万円(前年同四半期比9.1%減)、親会社株主に帰属する四半期純利益は79億37百万円(前年同四半期比18.2%減)となりました。」です。要するに、前年同四半期と比べて、
- 売上高、売上総利益率、売上総利益は増加した
- 営業利益、経常利益、親会社株主に帰属する四半期純利益は減少した
ということです。ポジティブ要素とネガティブ要素がある内容のため、ばらつきが生じる結果になったようです。改善、増、減という言葉がポジティブあるいはネガティブに関連するため、中立には分類されなかったのかもしれません。
3章 まとめと今後の展開
本記事では、RapidMiner Studioの拡張機能として登場した「Generative Models」について、実際の挙動を交えて紹介しました。「Generative Models」を使うことで、ChatGPTやHuggingface上のモデルをGUI操作だけで簡単に利用できることがわかりました。データ分析の領域では、テキストデータにおけるデータクレンジング、テキストデータに基づく特徴量エンジニアリングなどに応用が利きそうです。
今後の展開としては、今回あまり触れられていないファインチューニングオペレータに関して機能の深掘りをしたいと思います。また、公式ドキュメントには「Generative Models」を利用することでRAGを構成できるということなので、こちらにも挑戦したいと思います。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


