

- ライター:知念 紀昭
- メーカーで生産ライン業務を経験後、製品の評価・設計を担当。
その後SIerでシステム設計構築業務を経てネットワンシステムズに入社。
入社後は仮想化ハードウェア・ソフトウェアの評価・検証業務、クラウドソリューション業務などを担当。
現在は、主にデータの利活用・機械学習ビジネスを推進している。
目次
AIを活用して仮想環境の運用を高度化
前回は、AIを活用してITインフラやサービス全体を監視・運用および分析するツールSplunk IT Service Intelligence(ITSI)を紹介いたしました。
今回は、Splunk ITSIを用いた仮想環境の運用高度化の例をご紹介します。
仮想環境のデータ収集
vSphere環境のHypervisor情報やVM情報をvCenterからSplunk Data Collection SchedulerとSplunk Data Collection Nodeの機能で収集し、SplunkのIndexerに格納します。格納された情報をもとに、Splunk IT Service Intelligence(ITSI)によってAIOpsを実現します。
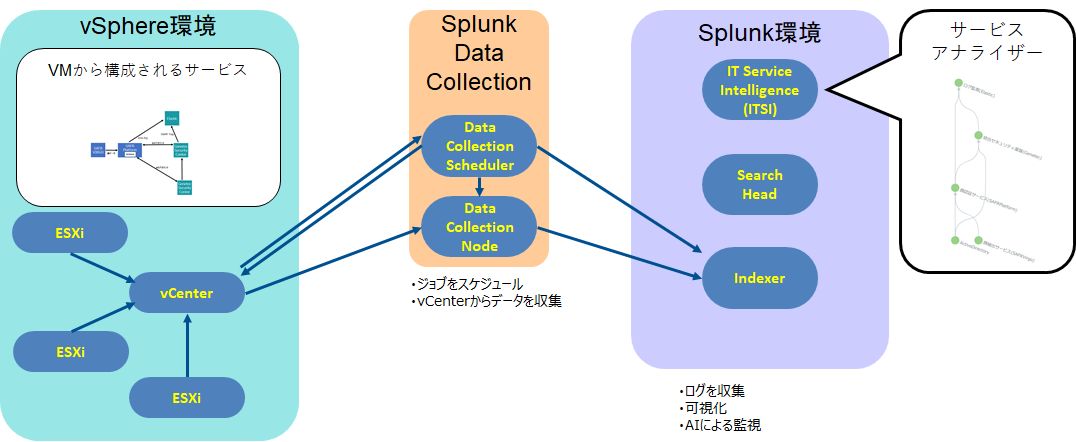
図1:vSphereとSplunkの連携構成図
連携Appによる仮想環境データの自動取得
Splunk ITSIでサービスを定義するためには、実態となるHypervisorやVMのエンティティの登録が必要となります。本アーキテクチャではAdd-on for VMware Metrics Appを用い、vCenterを登録するだけでHypervisorやVMのエンティティが自動登録されます。下図では2つのvCenterを登録しています。
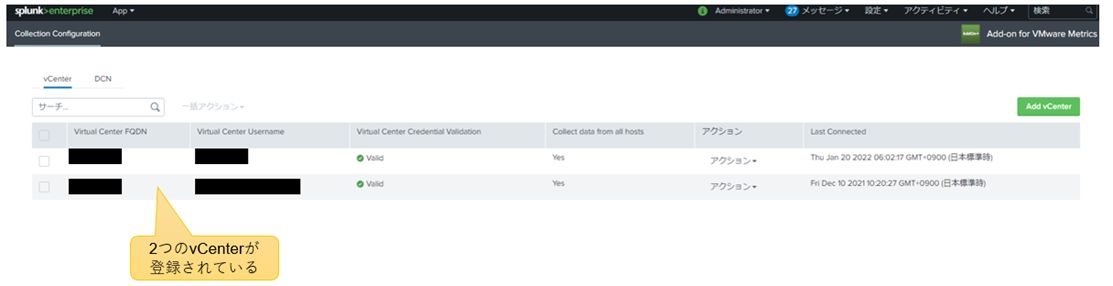
図2:vCenterの登録
vCenterを登録しただけで、vCenterエンティティやESXiエンティティやVMエンティティが自動登録され、同時にメトリック情報を収集開始します。そのため、各エンティティの手動インストールが不要となり、工数削減が図られます。
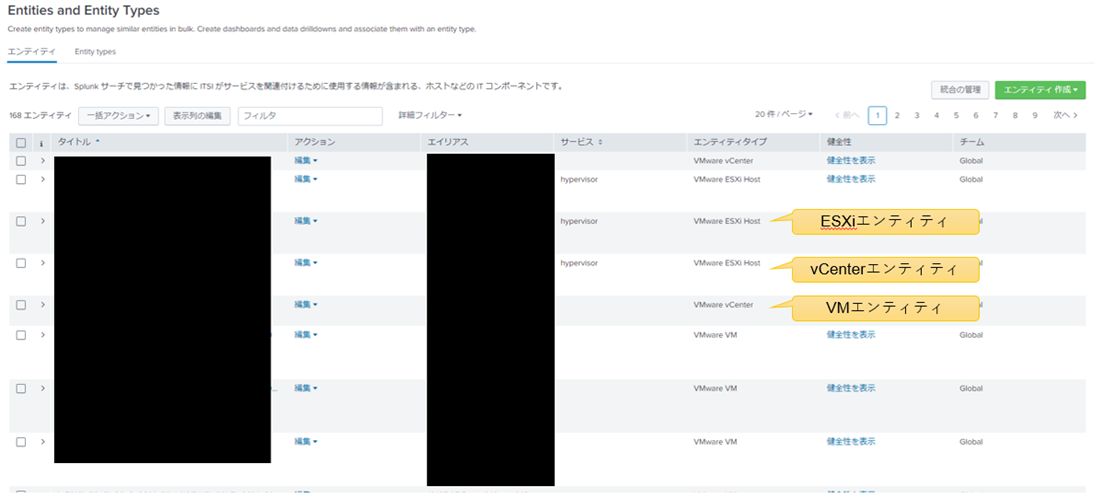
図3:自動的に収集されたvSphere環境情報
Splunk ITSIへのサービス登録
2020年に掲載した「顔認証とADを活用した入退室サイバー・フィジカル・セキュリティ」サービスを例にして、サービスの登録方法について説明します。まずサービスに登録するエンティティをフィルタ機能で選びます。フィルタの条件により、複数のエンティティを束ねることも可能です。この機能はスケールアウトモデルと親和性が高いと言えます。
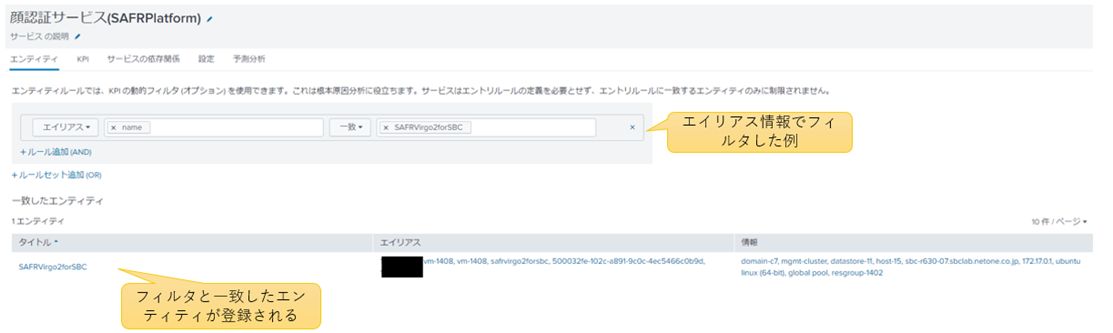
図4:エンティティの選択
KPI(Key Performance Indicator)とはサービスを監視する指標で、サービスに対して複数のKPIを登録することができます。メトリックスインデックスは以下の例ではvmware-perf-metricsから登録します。
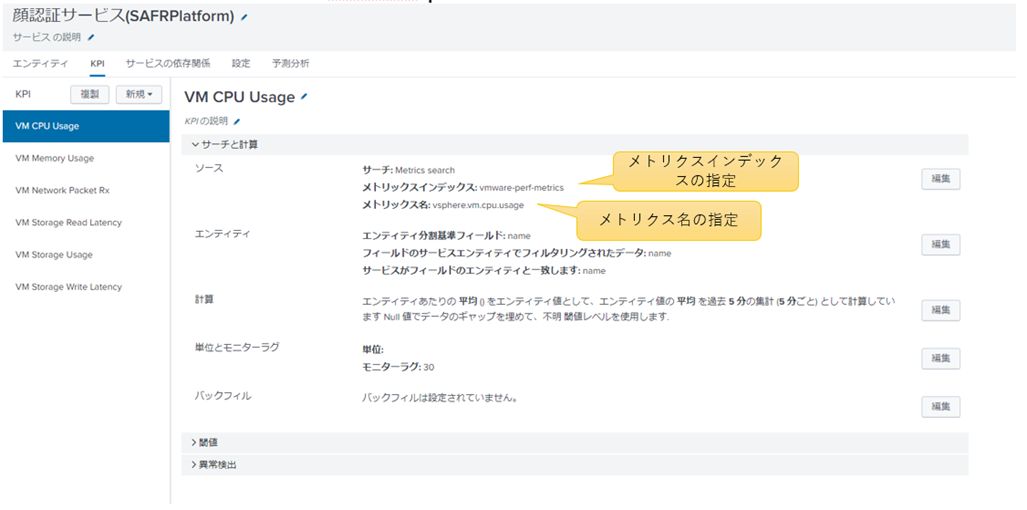
図5:KPIの登録
サービスの依存関係を設定できます。 設定されたサービスの関係性は、後述のダッシュボードで可視化されます。

図6:依存するサービスの設定
サービスの健全性は、KPIを用いたサービス健全性スコアで計算されます。サービス健全性スコアは、サービス間の関係性も考慮して算出されます。
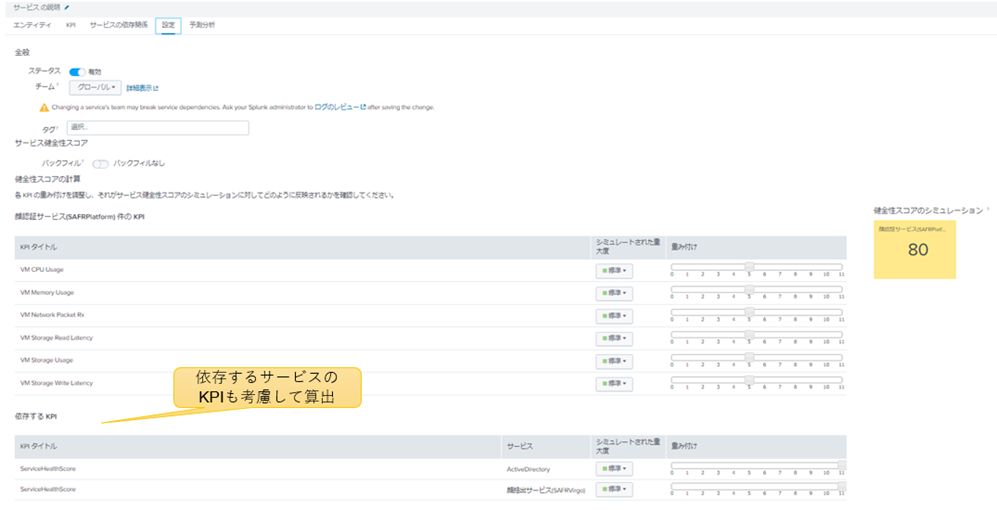
図7:サービス健全性スコア
KPIに対して静的閾値を複数設定可能です。
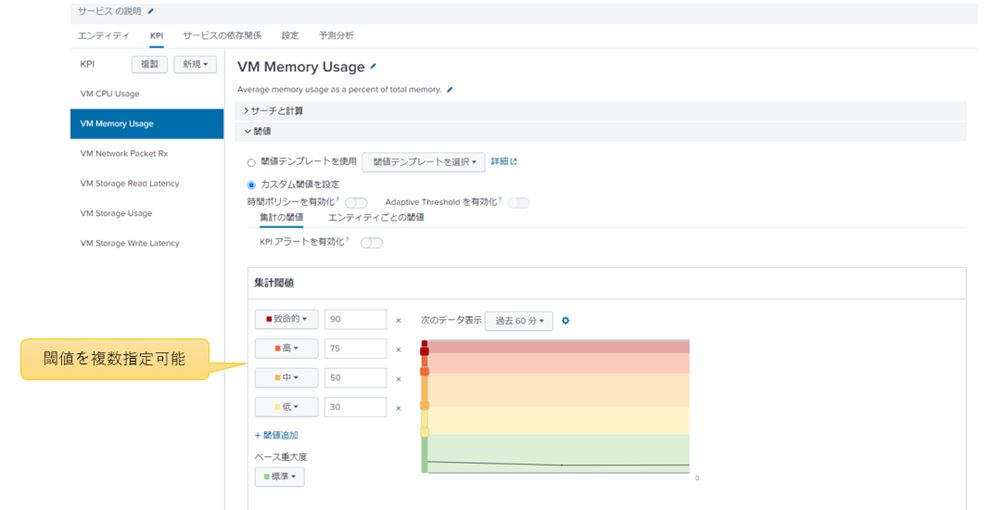
図8:KPIに対する静的閾値の設定
静的閾値では検知できない「いつもとは違う」KPI異常をAIによる動的閾値で検知できます。従来の監視ツールでは検知できないサイレント障害を検知できる可能性があります。
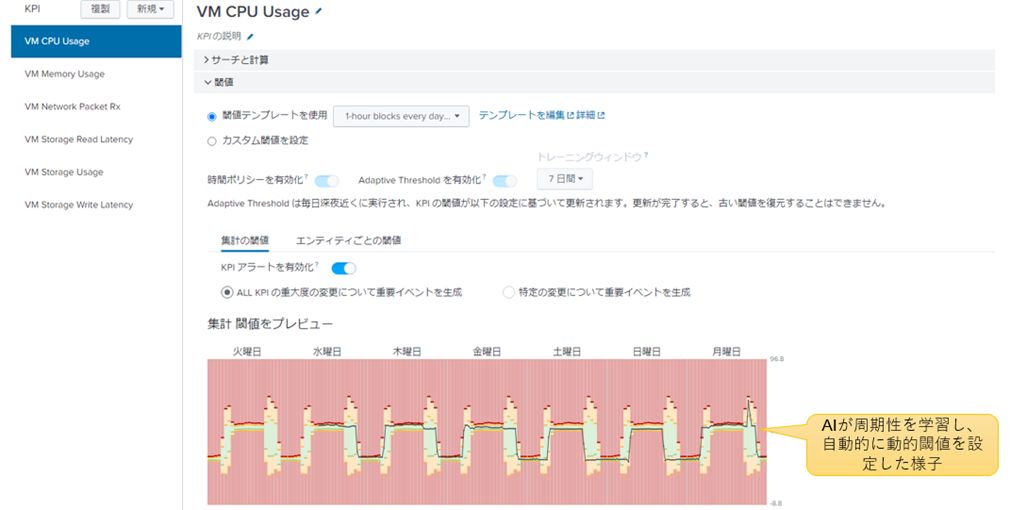
図9:KPIに対する動的閾値の設定
サービス異常発生時のトラブルシュート
あるサービスに異常が発生し、サービス全体が影響を受けた場合のトラブルシュート手法の一例を紹介します。このケースでは、SAFRVirgoというサービスに対してCPU負荷をかけます。
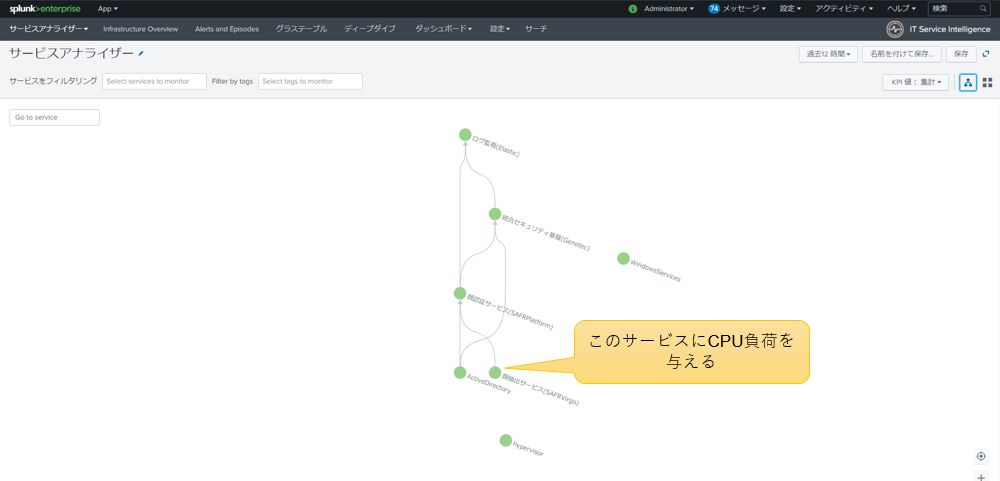
図10:CPU負荷による障害発生例
サービス健全性スコアやKPIが悪い順にサービスアナライザーダッシュボードで可視化されます。負荷のかかったKPIの値が下がり、他のサービスのKPIも影響を受けている様子が確認できます。
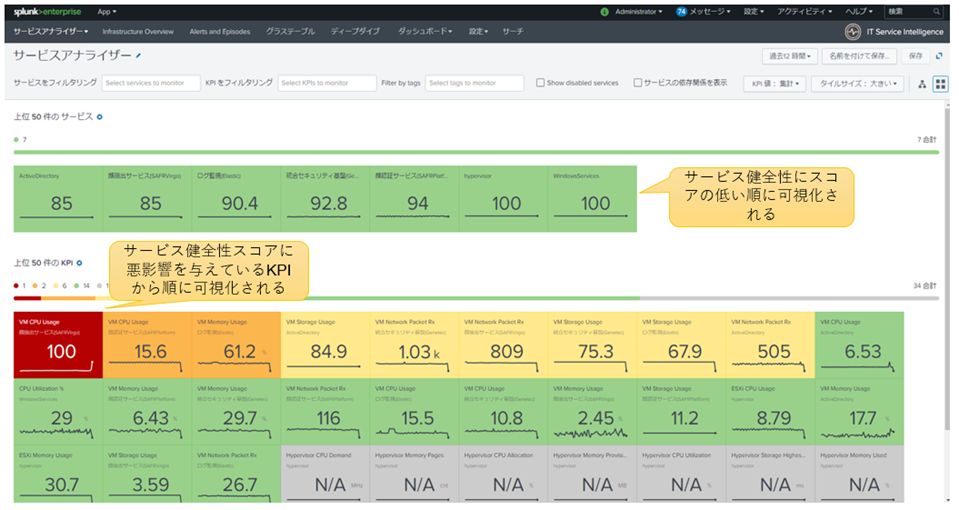
図11:サービスアナライザーダッシュボードで影響を受けているサービスとKPIを可視化
サービスアナライザーのツリー形式を確認すると、SAFRVirgoサービスのサービス健全性スコアが低下したため、依存するサービスのサービス健全性スコアも影響を受けている様子が確認できます。
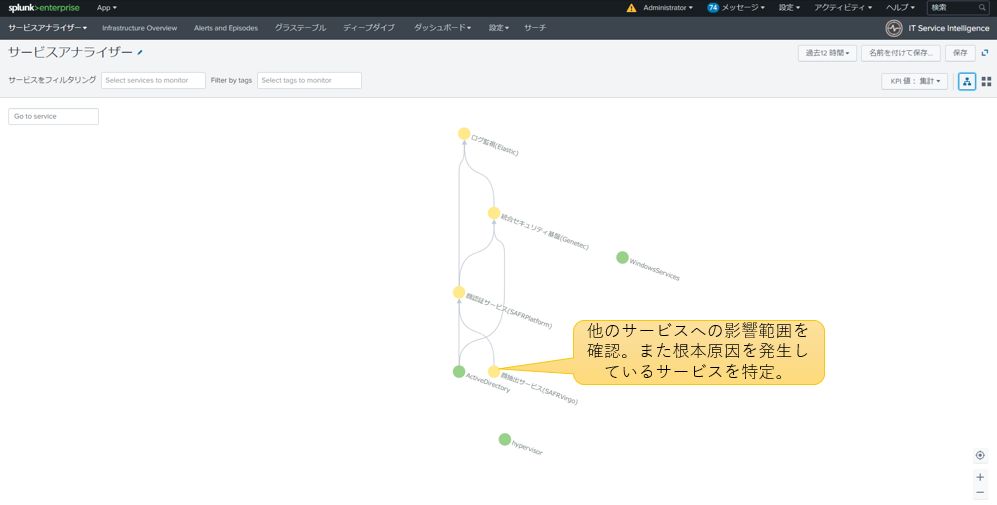
図12:サービスアナライザーダッシュボードのツリー形式で根本原因のサービスを特定
サービスアナライザーのダッシュボードで問題のある個所をクリックすることで、ドリルダウン形式で深掘りしながらトラブルシューティングを行うことができます。この例では、問題のあったKPIを掘り下げて確認しています。
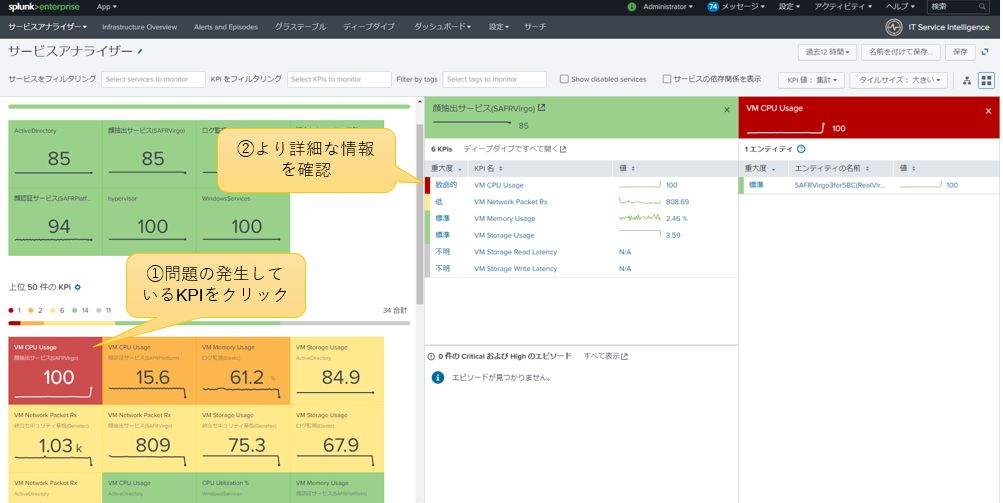
図13:ドリルダウン形式でトラブルシュート
更にクリックすることにより、トラブルシューティングの深掘りが行えます。この例では、SAFRVirgoをクリックし、対象エンティティの詳細を確認しています。直近でCPU負荷が上昇していることを確認できました。
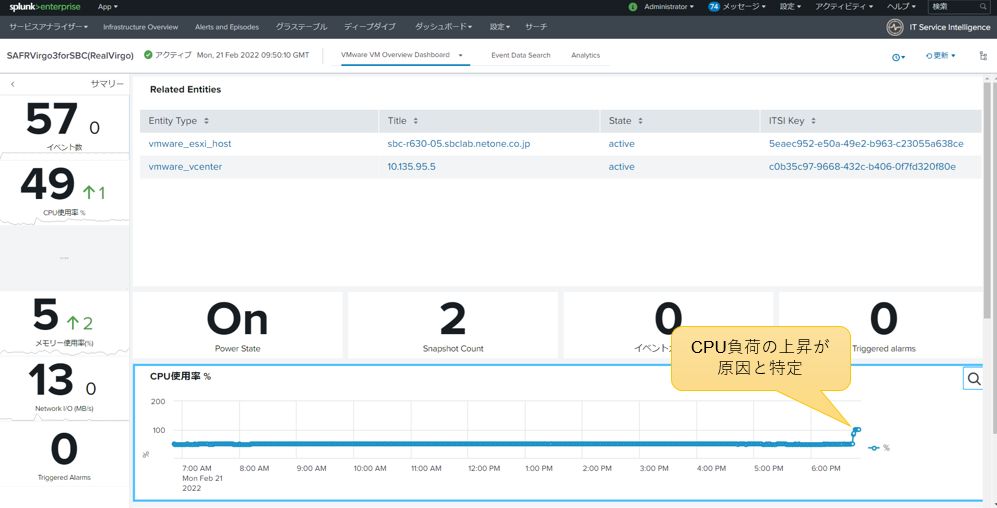
図14:ドリルダウンで原因を特定
最後に
今回はAIOpsを用いた仮想環境の運用高度化と、障害発生時のトラブルシューティング例をご紹介致しました。様々な分野へのデータ利活用・AI活用に挑戦するネットワンシステムズに今後もご期待ください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


