

- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
今日、AIや機械学習の基盤では多くのGPUが活用されています。GPUはリアルタイム画像処理を目的として開発されましたが、高い演算能力と並列計算に強いという特徴があり、NVIDIAが提供するCUDA(Compute Unified Architecture)はこのGPUを画像処理以外の汎用計算に利用することを可能にしました。CUDAの登場により、その演算能力の高さから大量のデータの解析や、機械学習モデルの作成、モデルを利用した推論に利用されるようになりました。
機械学習における課題とコンテナの活用
一般的に機械学習を行う際は、数多く存在するフレームワークやライブラリの中で必要なものを組み合わせて利用します。このときGPUドライバやCUDAのバージョンやTensorFlow、各種フレームワークライブラリはいずれもコンパチビリティ・相性を考慮して環境を構築する必要があるため、機械学習を開始するまでに非常に多くの時間を要してしまいます。この問題を解決するためにコンテナが活用され、環境構築に要する時間を大きく削減しています。NVIDIAが提供するNVIDIA Container Toolkitは、Docker等のコンテナランタイム上で実行されるコンテナワークロードから、ホストOSが持つGPUを利用することを可能にします。機械学習に必要なCUDA Toolkit、pythonやTensorFlow等各種フレームワークやライブラリ、アプリケーションなどのソフトウェアをコンテナイメージとしてパッケージ化することで、ホストOSにはDocker、NVIDIAドライバ、NVIDIA Container Toolkitをインストールするだけで機械学習に必要な開発環境を容易に構築することが可能になります。コンテナが持つ可搬性の高さを活かすことができるため、一度コンテナ化してしまえば、異なるホスト上で同じ環境を構築することが可能になります。
このようなGPUを利用したコンテナ環境は開発者やデータサイエンティストが個人で利用するには十分ですが、複数のユーザーが共同で利用するような大規模なGPU基盤ではKubernetesが広く利用されています。Kubernetesはクラスターを構成するホストが持つGPUをプール化し、必要に応じてGPUのスケジューリングを行うことができるため、機械学習向けのワークロードに対して、プール化されたGPUを割り当てることが可能になります。
エンタープライズにおけるAI基盤の実現
コンテナを活用した大規模なGPU基盤を構築するためには以下の要件があります。これらを実現するためのソリューションとして、 NVIDIA AI EnterpriseとVMware vSphere® with VMware Tanzu® をご紹介します。
- GPU (NVIDIA-Certified Systemsとして認定されたサーバー)
- GPUを効率よく利用できるKubernetesクラスターの構築
- 開発者に対して機械学習で必要とされる様々なソフトウェアの提供
NVIDIA AI Enterprise
NVIDIA AI Enterpriseは、エンタープライズ環境におけるAI/機械学習を実現するためのインフラ向けのドライバソフトウェア、AI/機械学習に必要となるツールやフレームワークなどのソフトウェア、コンテナ・Kubernetes環境でこれらを活用するためのソフトウェア等のパッケージで構成されています。前述の通り機械学習環境を作る上で、大きな課題となるのが各種ライブラリやフレームワークのコンパチビリティです。NVIDIAはこうしたライブラリやフレームワークをコンテナイメージとしてパッケージ化したものをNGC Catalogで公開しています。NVIDIA AI Enterpriseはこれらのソフトウェアに対するサポートを提供し、VMware vSphere® 及びvSphere with Tanzu環境での実行をサポートします。
VMware vSphere with Tanzu
vSpehre with TanzuはvSphereで「ワークロード管理」機能を有効化することにより、vSphereクラスター環境をSupervisor Cluster としてKubernetes ワークロードを実行・管理するためのプラットフォームに変換できます。この Supervisor Cluster 上において、VMware Tanzu® Kubernetes Grid™ Service (TKGs) を使用して、Kubernetes クラスター(Tanzu Kubernetes Cluster - TKC)の展開や、VM サービスを使用しての仮想マシンの展開が可能となります。このvSphereクラスター環境は、従来の仮想基盤としても共有利用可能であり、Kubernetes 環境との統合管理が可能となります。
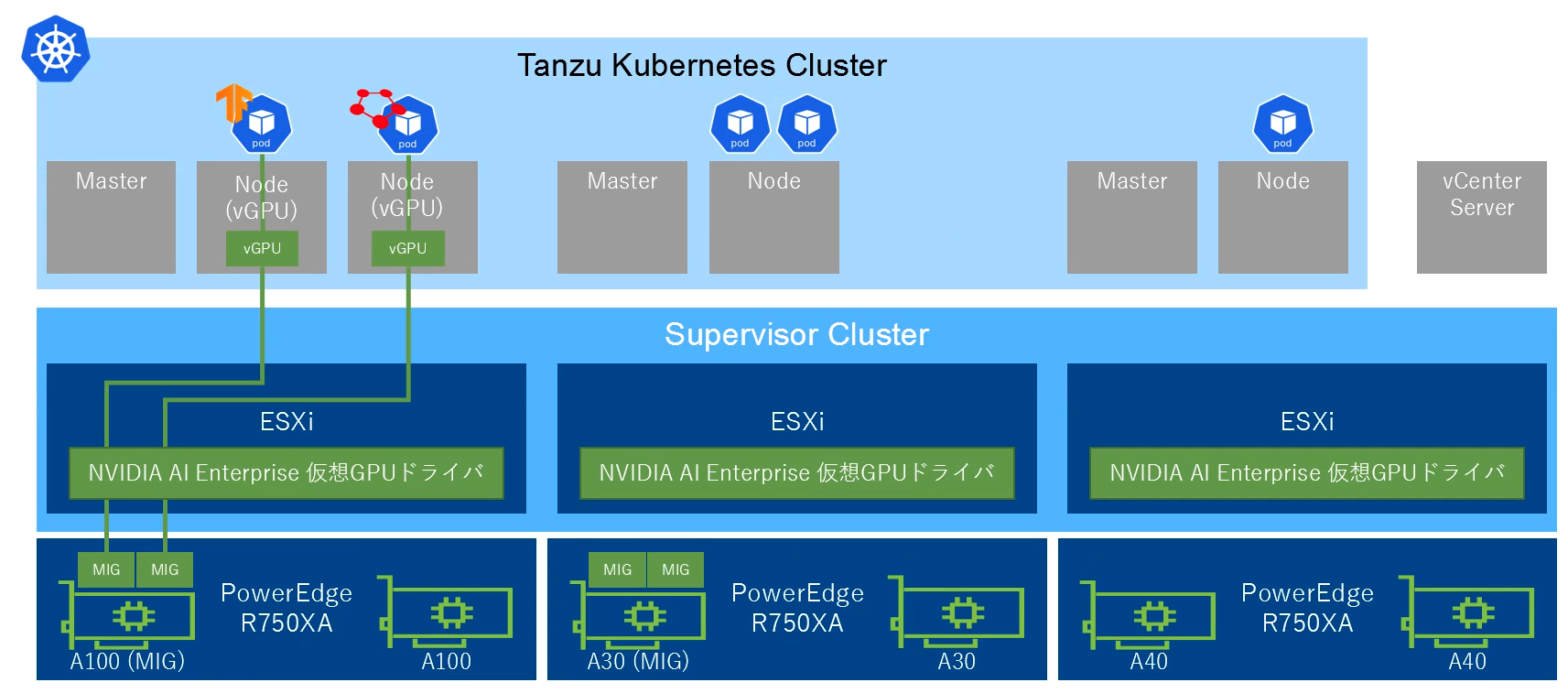
NVIDIA AI Enterprise / vSphere with Tanzuの利用方法
ここからは、実際にNVIDIA AI Enterprise 2.0とVMware vSphere with Tanzu (vSphere 7.0U3c以降)を利用して、コンテナワークロードでGPUを利用する方法をご紹介します。
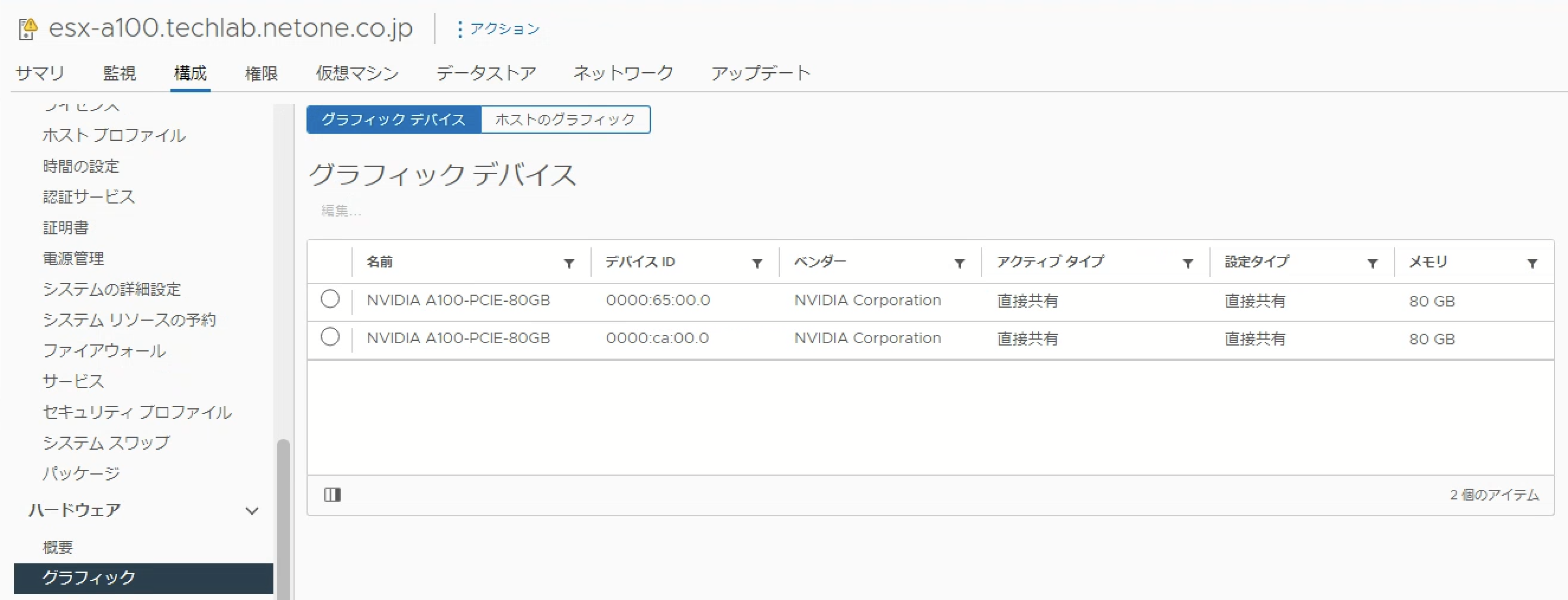
ESXiホストの準備
ESXiホストでGPUをvGPUとして利用するために以下の設定を行います。
- 仮想マシンがPCIデバイスとしてvGPUを利用するためにSR-IOVを有効化 (※Ampere)
- NVIDIA vGPU、ホストのグラフィック設定の「グラフィックデバイス」および「ホストのグラフィック」で「直接共有」を選択
メンテナンスモードを有効にし、esxcliを利用してESXiホストにNVIDIA AI Enterpriseとして提供されるvGPU Managerをインストールします。インストール完了後、ホストを再起動し、メンテナンスモードを解除します。
[root@esx-a100:~] esxcli software vib install -d /vmfs/volumes/Datastore/NVD-AIE_510.47.03-1OEM.702.0.0.17630552_19298122.zip
Installation Result
Message: Operation finished successfully.
Reboot Required: false
VIBs Installed: NVIDIA_bootbank_NVIDIA-AIE_ESXi_7.0.2_Driver_510.47.03-1OEM.702.0.0.17630552
VIBs Removed:
VIBs Skipped:
NVIDIAドライバをインストールすると、nvidia-smiを利用してGPUの状態を確認することが可能になります。CUDAは含まれていないため、CUDA VersionはN/Aとなります。
[root@esx-a100:~] nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100 80G... On | 00000000:65:00.0 Off | 0 |
| N/A 42C P0 50W / 300W | 0MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100 80G... On | 00000000:CA:00.0 Off | 0 |
| N/A 39C P0 51W / 300W | 0MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
本環境では、2枚のA100を搭載しています。NVIDIAMIGを利用することで単一のGPUカードのリソースを複数のCUDAアプリケーション向けにハードウェア的に分割して利用することが可能になります。GPUに搭載されるL2キャッシュバンク、メモリーコントローラー等のリソースは完全に独立して動作するため、同一のGPU上で実行されるMIGを利用したアプリケーション同士が相互に干渉することなく、独立したスループットを保証することが可能です。vGPUをMIGとして利用する場合はnvidia-smiを利用して各GPUに対してMIGを有効にする必要があります。MIGを有効化・無効化した場合、ESXiホストの再起動が必要です。
[root@esx-a100:~] nvidia-smi -i 0 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:65:00.0:Not Supported
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:65:00.0
All done.
[root@esx-a100:~] nvidia-smi -i 1 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:CA:00.0:Not Supported
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:CA:00.0
All done.
vSphereクラスターの準備
GPUを搭載したESXiホストで構成されるvSphereクラスターでワークロード管理機能を使って、Supervisor Clusterを有効化します。Supervisor Control VMが3台構成され、Supervisor Cluster APIが利用可能になり、Supervisor Clusterを利用してvSphere環境に仮想マシンで構成されるKubernetesクラスターと同様にネームスペースを作成し、クラスターを論理的に分離することが可能です。なお、NVIDIA AI EnterpriseはvSphereにも対応しているため、vSphere with Tanzuを利用せずにvSphere環境でvGPUを持つ仮想マシンを利用することも可能です。仮想マシンにNVIDIAドライバやCUDAをインストールすることで、GPUを持つ機械学習の環境として利用することが可能になります。
参考 : vSphere Clientにより仮想マシンを作成し、PCIデバイスとしてvGPUを追加する
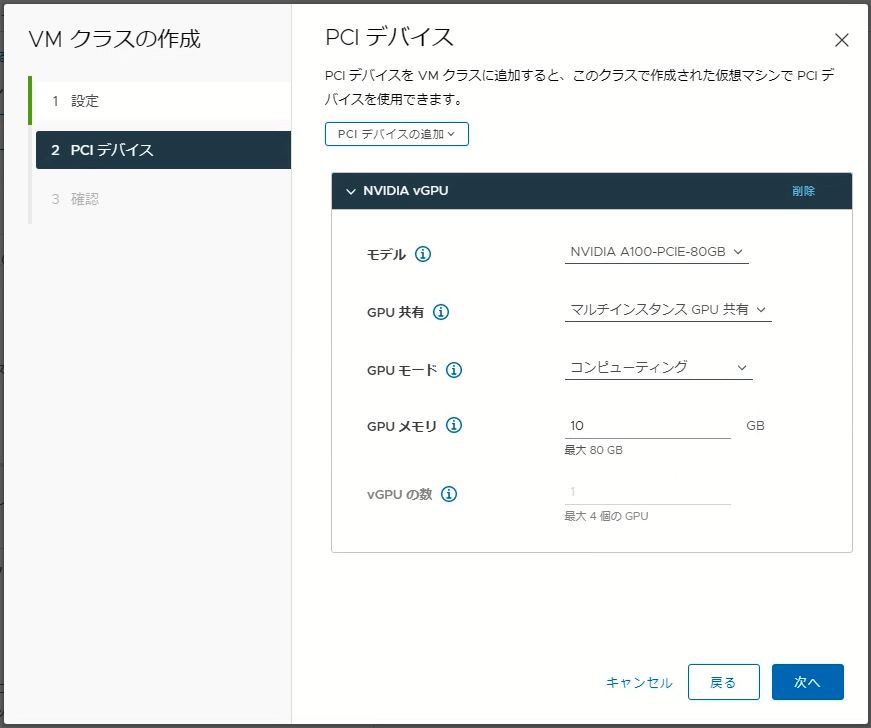
VMクラスの作成
Supervisor Cluster内で定義するVMクラスは仮想マシンのCPU、メモリー、予約などを定義します。VMクラスでPCIデバイスとして「NVIDIA vGPU」を追加し、Kubernetesクラスターのワーカーノード向けのVMクラスを定義します。GPU共有モードとして「マルチインスタンスGPU共有」(Multi-Instance GPU Sharing)と「時刻の共有」(Time Sharing)のどちらかを選択することが可能です。GPUメモリーにはGPUカードに搭載されたメモリーの中でこの仮想マシンに割り当てるGPUメモリー容量を指定します。MIGモードを指定する場合は、GPUが対応するMIGプロファイルに応じたGPUメモリー容量を指定する必要があります。vGPU の数は最大 4vGPU まで指定できますが、GPU メモリー容量を最大値に設定している場合のみ複数 vGPU 数を指定可能です。GPU メモリーの設定が最大値未満の場合は vGPU数は 1 となります。
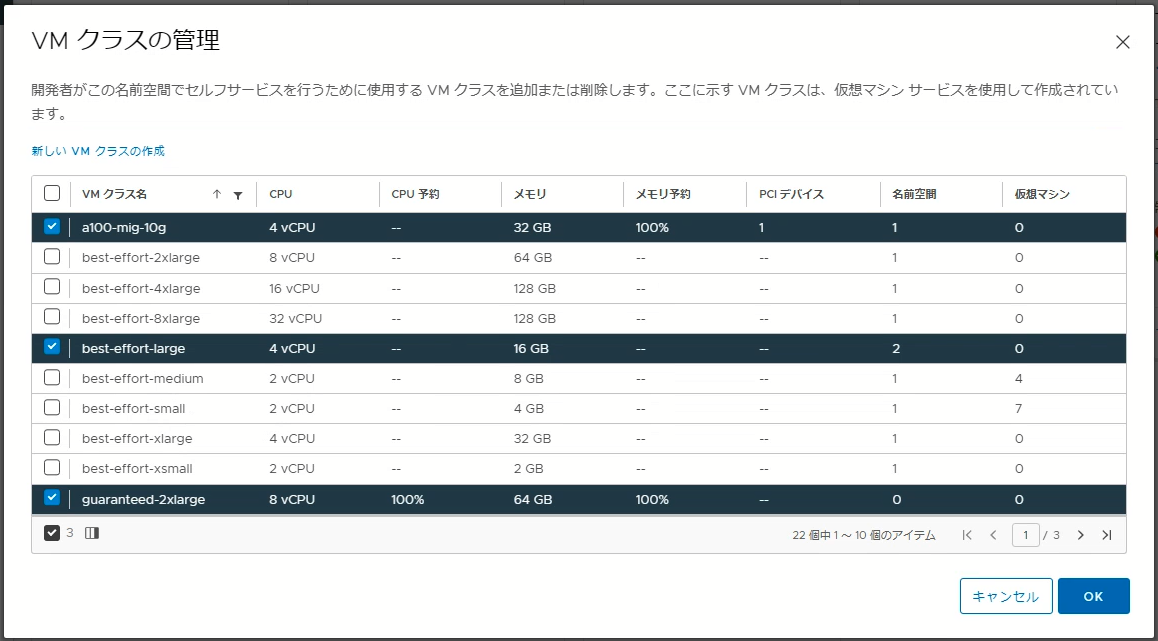
作成したVMクラスは、Supervisor ClusterのNamespaceに割り当てることによりネームスペース内で利用可能になります。
Tanzu Kubernetes Clusterの作成
Supervisor Clusterを利用してTanzu Kubernetes Clusterを作成します。Tanzu Kuberntes Clusterとして利用できるKubernetesのバージョンは、TanzuKubernetesReleaseとして確認することが可能です。TanzuKubernetesReleaseはゲストOSとしてPhotonOSまたはUbuntuを利用可能ですが、GPUを利用するためにはゲストOSを利用する必要があり、PhotonOSは使用できません。Ubuntuを利用するTanzuKubernetesReleaseとしてv1.20.8とv1.21.6が利用可能です。
$ kubectl get TanzuKubernetesRelease -l os-name=ubuntu
NAME VERSION READY COMPATIBLE CREATED UPDATES AVAILABLE
v1.20.8---vmware.1-tkg.2 1.20.8+vmware.1-tkg.2 True True 5d18h [1.21.6+vmware.1-tkg.1]
v1.21.6---vmware.1-tkg.1 1.21.6+vmware.1-tkg.1 True True 5d18h
今回のvSphere with Tanzu環境ではTanzu Kubernetes Clusterのバージョンとして最新のv1.21.6---vmware.1-tkg.1を指定します。3台のMasterと、2種類のNode Poolを構成し、vGPUを持つNode Pool a100-mig-10g-poolとしてvGPU付きのノードを2台、Node Pool best-effort-largeとしてGPUを持たいないノード2台が混在する合計7台の仮想マシンで構成されるKubernetesクラスターを構成します。
apiVersion: run.tanzu.vmware.com/v1alpha2
kind: TanzuKubernetesCluster
metadata:
name: a100-vgpu-cluster
spec:
distribution:
version: 1.21.6+vmware.1-tkg.1
settings:
storage:
classes:
- unity-k8s
defaultClass: unity-k8s
topology:
controlPlane:
replicas: 3
storageClass: unity-k8s
vmClass: best-effort-large
nodePools:
- name: a100-mig-10g-pool
vmClass: a100-mig-10g
replicas: 2
storageClass: unity-k8s
volumes:
- capacity:
storage: 50Gi
mountPath: /var/lib/containerd
name: containerd
storageClass: unity-k8s
- capacity:
storage: 50Gi
mountPath: /var/lib/kubelet
name: kubelet
storageClass: unity-k8s
- name: best-effort-large
vmClass: best-effort-large
replicas: 2
storageClass: unity-k8s
上記マニフェストによりTanzu Kubernetes Clusterを作成すると、Supervisor ClusterのNamespacesリソースプール配下にa100-vgpu-clusterが作成されます。
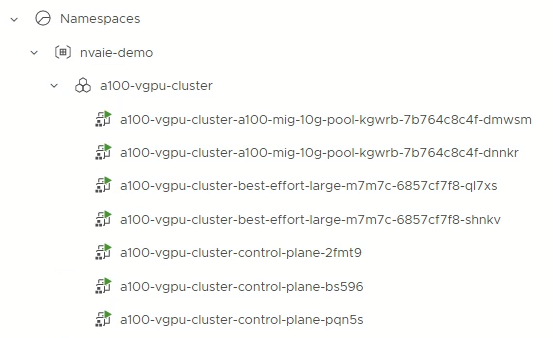
vGPUを持つ2台の仮想マシン(a100-vgpu-cluster-a100-mig-10g-pool-kgwrb-7b764c8c4f-xxxxx)は、初期配置時のvSphere DRS機能により、必要なGPUリソース(今回はA100)が搭載されたesxiホスト上で起動します。このesxiホスト内でnvidia-smiを実行すると、2つのMIGが構成され、それぞれのMIGが2台の仮想マシンで利用されていることが確認できます。
[root@esx-a100:~] nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100 80G... On | 00000000:65:00.0 Off | On |
| N/A 55C P0 107W / 300W | 18944MiB / 81920MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100 80G... On | 00000000:CA:00.0 Off | 0 |
| N/A 37C P0 50W / 300W | 0MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 13 0 0 | 9472MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+----------------------+-----------+-----------------------+
| 0 14 0 1 | 9472MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 13 0 8256379 C+G ...ol-kgwrb-7b764c8c4f-dmwsm 9472MiB |
| 0 14 0 8256744 C+G ...ol-kgwrb-7b764c8c4f-dnnkr 9472MiB |
+-----------------------------------------------------------------------------+
GPU Operatorの構成
ここまでで、vGPUを持った仮想マシン(ノード)で構成されるKubernetesクラスターを作成できました。このKubernetesクラスター上でGPUワークロードを実行するには、vGPUを持つ仮想マシンでNVIDIAドライバや、NVIDIA Container Toolkitを構成し、PodからGPUを利用できるようにする必要があります。通常のLinuxホストであれば、各ノードにこれらをインストールする必要がありますが、Kubernetes環境ではGPU Operatorと呼ばれる仕組みによって、Kubernetesのplugin機能を利用してvGPUを持つノードに対するソフトウェアのインストールを簡単に行うことが可能です。NVIDIA AI EnterpriseにはGPU Operatorも含まれており、Tanzu Kubernetes Gridをサポートするバージョンが提供されます。GPU Operatorは、NGC上でHelmチャートと呼ばれるKubernetes向けパッケージで提供されており、これをKubernetesクラスターにインストールすることでNVIDIAドライバ等がKubernetesクラスターの各ノードにインストールされます。GPU Operatorが利用する各種コンテナイメージはNGCで公開されており、NGCにアクセスするためのAPIトークン(以下の例では${NGC_TOKEN})をNGC上で生成して利用します。
$ nvidia helm repo add nvaie https://helm.ngc.nvidia.com/nvaie --username='$oauthtoken' --password=${NGC_TOKEN}
&& helm repo update
$ helm search repo nvaie
NAME CHART VERSION APP VERSION DESCRIPTION
nvaie/gpu-operator v1.8.1 v1.8.1 NVIDIA GPU Operator creates/configures/manages ...
nvaie/gpu-operator-1-1 v1.9.1 v1.9.1 NVIDIA GPU Operator creates/configures/manages ...
nvaie/gpu-operator-2-0 v1.10.0 v1.10.0 NVIDIA GPU Operator creates/configures/manages ...
nvaie/network-operator-1-1 1.1.0 v1.1.0 Nvidia network operator
nvaie/network-operator-2-0 1.1.0 v1.1.0 Nvidia network operator
GPU Operatorをインストールするネームスペースを作成し、NGC上のコンテナイメージを取得するためのAPIトークンをngc-secretとして作成します。
$ kubectl create namespace gpu-operator
$ kubectl create secret -n gpu-operator docker-registry ngc-secret \
--docker-server=${NGC_REGISTRY} --docker-username='$oauthtoken' \
--docker-password=${NGC_TOKEN} \
--docker-email=username@netone.co.jp
vGPU利用時はソフトウェアライセンスが必要となります。NVIDIAドライバがNVIDIA License Serverからネットワーク経由でソフトウェアライセンスをリースします。 ライセンスされたNVIDIAドライバが停止すると、ライセンスはNVIDIA License Serverに返却されます。オンプレミス環境に構築するライセンスサーバーの情報をgridd.conf、ライセンスサーバーで発行したアクセス用のTokenをclient_configuration_token.tokとして作成し、これらをlicensing-config ConfigMapとして構成します。
$ kubectl create configmap -n gpu-operator licensing-config \
--from-file=./gridd.conf --from-file=./client_configuration_token.tok
GPU Operatorをhelmコマンドでインストールします。
$ helm install --wait gpu-operator nvaie/gpu-operator-2-0 -n gpu-operator
注意点
2022年4月15日 現在 gpu-operator-2-0:v1.10.0 に不具合があり、helm install時のパラメータとして--set operator.repository='nvcr.io/nvaie' --set driver.repository='nvcr.io/nvaie'を追加する必要があります。NVIDIAは本問題を認識しており、今後修正される予定です。
【2022年7月11日 追記】上記問題は gpu-operator-2-0:v1.10.1で修正済みです。
GPU Operatorはgpu-oepratorネームスペース内で各種Podを起動します。
$ kubectl get pod -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-clsb4 1/1 Running 0 3m16s
gpu-feature-discovery-x6d7n 1/1 Running 0 3m16s
gpu-operator-5859d7996c-p8g9j 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-master-57f77d46f9-n5n7s 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-2mxmc 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-cgw8c 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-fxngz 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-gbvtw 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-ltxrq 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-n4k65 1/1 Running 0 6m31s
gpu-operator-node-feature-discovery-worker-vhdz9 1/1 Running 0 6m31s
nvidia-container-toolkit-daemonset-54m86 1/1 Running 0 3m16s
nvidia-container-toolkit-daemonset-j9z2l 1/1 Running 0 3m16s
nvidia-cuda-validator-nhdws 0/1 Completed 0 111s
nvidia-cuda-validator-qlbxg 0/1 Completed 0 99s
nvidia-dcgm-exporter-9ld7c 1/1 Running 0 3m16s
nvidia-dcgm-exporter-lq86v 1/1 Running 0 3m16s
nvidia-device-plugin-daemonset-58tq2 1/1 Running 0 3m16s
nvidia-device-plugin-daemonset-fc8bw 1/1 Running 0 3m16s
nvidia-device-plugin-validator-bmf9d 0/1 Completed 0 95s
nvidia-device-plugin-validator-fnzjx 0/1 Completed 0 88s
nvidia-driver-daemonset-7qzjz 1/1 Running 0 5m59s
nvidia-driver-daemonset-qhdn7 1/1 Running 0 5m59s
nvidia-mig-manager-74w9k 1/1 Running 0 68s
nvidia-mig-manager-t26vg 1/1 Running 0 66s
nvidia-operator-validator-jrf9d 1/1 Running 0 3m16s
nvidia-operator-validator-mrhcq 1/1 Running 0 3m16s
GPUを持つノードにのみDaemonSetとしてnvidia-driver-daemonset Podが作成され、ノード上でNVIDIA GPUドライバーとCUDAが利用可能になります。
また、GPU OperatorによってDCGM (Data Center GPU Manager)もインストールされます。これはGPU監視ツールであり、この出力をPrometheusに格納することでGPUのステータスをGrafanaによりグラフィカルに監視できるようになります。
$ kubectl get pod -n gpu-operator -l app=nvidia-driver-daemonset -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nvidia-driver-daemonset-7qzjz 1/1 Running 0 8m45s 172.20.4.4 a100-vgpu-cluster-a100-mig-10g-pool-kgwrb-7b764c8c4f-dnnkr <none> <none>
nvidia-driver-daemonset-qhdn7 1/1 Running 0 8m45s 172.20.5.4 a100-vgpu-cluster-a100-mig-10g-pool-kgwrb-7b764c8c4f-dmwsm <none> <none>
Pod内でnvidia-smiを実行すると、コンテナ内からNVIDIA Driverを介してGPUが認識されていることが確認できます。
$ kubectl exec -it nvidia-driver-daemonset-7qzjz -- nvidia-smi
Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, k8s-driver-manager (init)
Mon Apr 11 01:40:36 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GRID A100D-1-10C On | 00000000:02:00.0 Off | On |
| N/A N/A P0 N/A / N/A | 0MiB / 10240MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 0 0 0 | 0MiB / 8811MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 4096MiB | | |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
GPU Operatorによって展開されたNVIDIA Driverはライセンスサーバーからライセンスのリースを受けていることも確認できます。
$ kubectl exec -it nvidia-driver-daemonset-7qzjz -- nvidia-smi -q | grep 'License Status'
Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, k8s-driver-manager (init)
License Status : Licensed (Expiry: 2022-4-12 1:34:13 GMT)
Podの作成
以下のようなマニフェストを利用してNGCを通じて提供されているTensorFlow 2をPodとしてデプロイし、Jupyter Notebookを起動してみます。GPUを利用するためコンテナのresourcesとしてnvidia.com/gpu: 1を指定します。この指定によりKubernetesクラスターはPod が GPUを持つノードにスケジューリングします。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: demo-notebook
name: demo-notebook
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-notebook
template:
metadata:
labels:
app: demo-notebook
spec:
imagePullSecrets:
- name: ngc-secret
containers:
- image: nvcr.io/nvaie/tensorflow-2-0:22.02-tf2-nvaie-2.0-py3
name: jypter
command: ["jupyter"]
args: ["notebook","--ip=0.0.0.0","--allow-root","--NotebookApp.token=''"]
resources:
limits:
nvidia.com/gpu: 1
上記マニフェストによりDeploymentを作成して、しばらく待つとPodがGPUを持つノード上で起動します。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pod/demo-notebook-7b7bd8d8bc-tnwkn 1/1 Running 0 92s
起動したPodをクラスターの外部に公開します。vSphere with Tanzuではtype: LoadBalancerをサポートしているためLoadBalancerにより公開可能です。
$ kubectl expose deploy/demo-notebook --port=80 --type=LoadBalancer
service/demo-notebook exposed
$ kubectl get service demo-notebook
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo-notebook LoadBalancer 10.96.42.228 10.44.187.7 80:31077/TCP 10s
公開されたEXTERNAL-IPにブラウザからアクセスすると、Jupyter Notebookを利用することが可能です。Podとして実行されるNotebookで実行される、TensorFlowからGPUデバイスを確認するとGPUデバイスが認識されています。
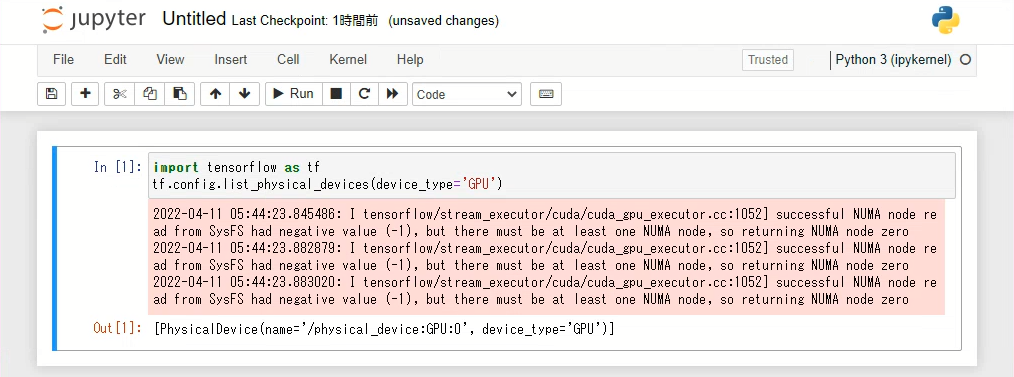
Tanzu Mission Control によるクラスターの作成
VMware Tanzu® Mission ControlTM (TMC)はVMwareが提供するKubernetesクラスターの統合管理サービスです。vSphere with TanzuのSupervisor ClusterをTMCに登録すると、TMCを介してTanzu Kubernetes Clusterをプロビジョニングすることが可能です。GPUを搭載したホストを含むSupervisor ClusterをTMCに登録すると、Tanzu Kubernetes Cluster作成時のNode Pool設定で「Worker instance type」として GPU を利用するための VM クラスを指定して、TMC を介して GPU Kubernetes クラスターをプロビジョニングすることが可能です。
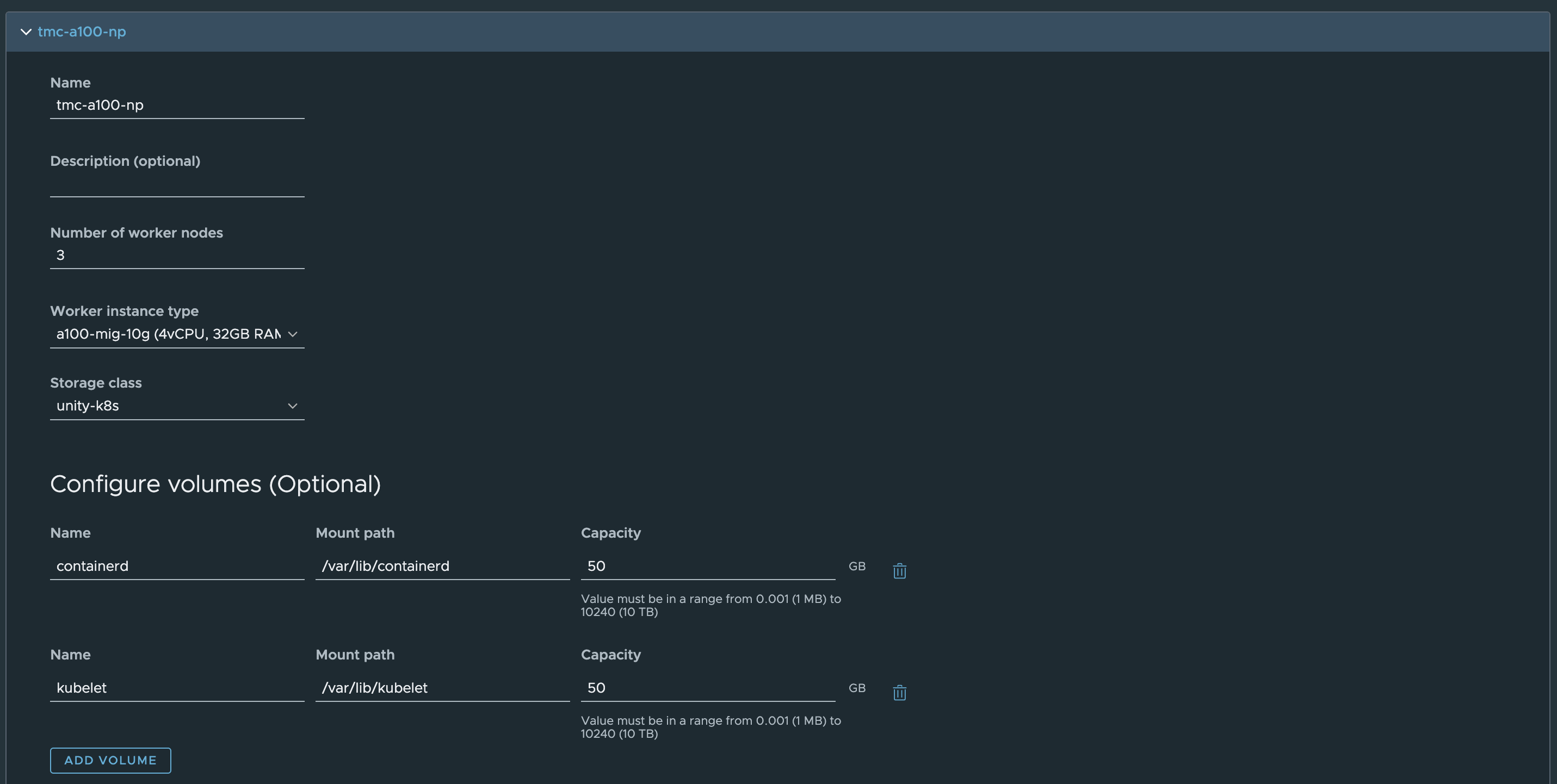
作成されたKubernetesクラスターはTMCのポリシー機能により様々な制御をかけることが可能です。
まとめ
NVIDIA AI EnterpriseとvSphere with Tanzuを利用することによりコンテナを活用したGPU基盤の構築と運用が可能になります。インフラ管理者は従来のインフラストラクチャと同じ仮想基盤上でGPUの利用が可能なKubernetesクラスターを構成・管理し、開発者やデータサイエンティストはこのGPU基盤を利用してNGC上で公開されている各種ソフトウェア・コンテナイメージを利用し速やかに開発や機械学習を行うことが可能となるため、インフラ管理者と開発者・データサイエンティスト両者にとって魅力的なGPU基盤を構築することが可能です。NVIDIA AI EnterpriseとvSphere with Tanzuの導入に関しては、是非弊社までお問合せください。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


