
- ライター:奈良 昌紀
- 通信事業者のデータセンターにおいてネットワーク・サーバー運用を経験した後、ネットワンシステムズに入社。帯域制御やWAN高速化製品担当を経て、2008年から仮想化関連製品を担当。現在は主にクラウドやコンテナなどの技術領域を担当。
目次
本記事は business network.jp に寄稿した「<コンテナNWの課題と展望>Kubernetes環境のネットワークの基礎を学ぶ」の内容を再編・要約したものです。詳細はこちらもご参照ください。
こちらの記事ではKubernetesのストレージ機能に関して説明しましたが、今回はKubernetesのネットワーク部分に焦点を当ててご説明します。
Dockerにおけるコンテナネットワーク
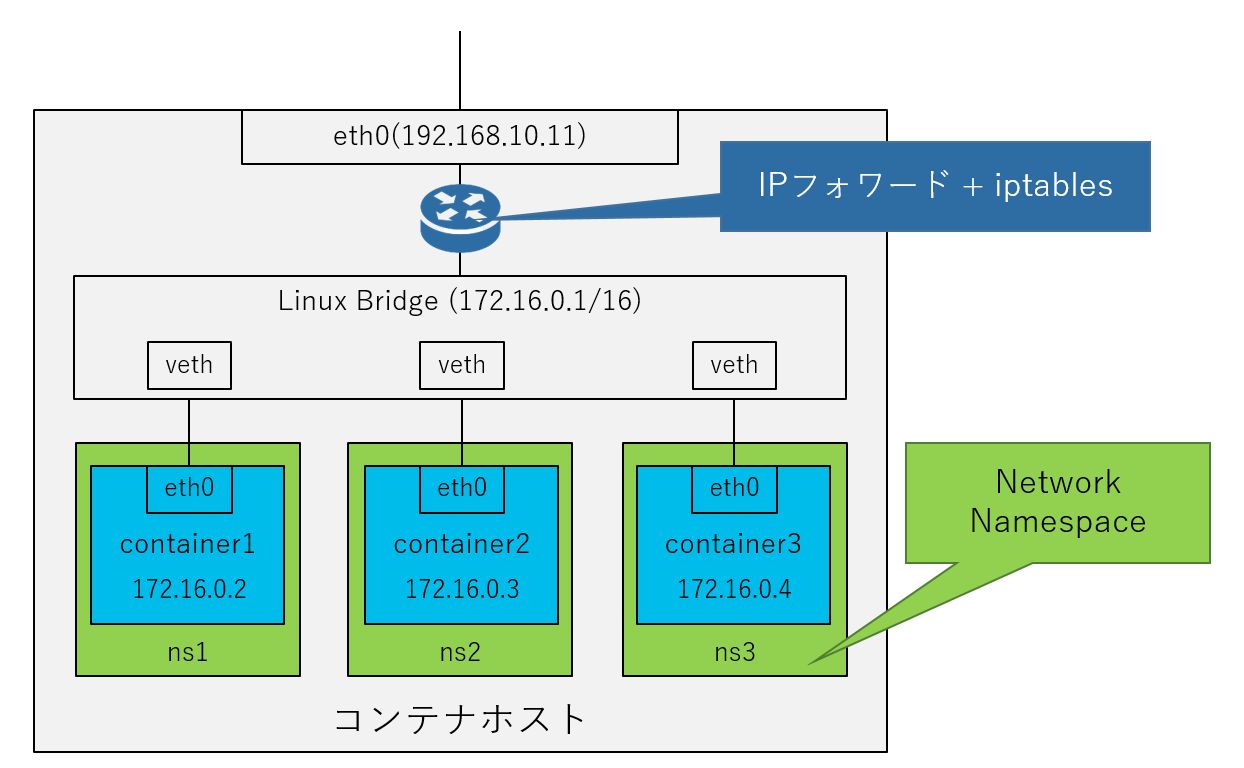
Kubernetesのネットワークを説明する前に、Dockerにおけるコンテナのネットワークに関して整理します。コンテナが起動するホストはコンテナホストと呼ばれ、コンテナホストの内部には論理的なネットワークが存在し、各コンテナはこの論理的なネットワークに接続されています。コンテナホスト内部には論理的なブリッジ(Linux Bridge)が存在し、各コンテナは仮想的なネットワークインターフェース(veth)によりこのブリッジに接続され、Linux カーネルのNetwork Namespace機能により、それぞれが独自のネットワークインターフェースを持つことを実現しています。コンテナ内で起動するプロセスから見ると、自分専用のネットワークインターフェースがあるように見えており、コンテナホストが持つネットワークインターフェースもこのブリッジに接続されています。コンテナとして起動するサービスを外部に公開する場合は、コンテナホストの特定ポートに対するアクセスをコンテナに対してiptablesによりDNATすることで、コンテナに対するアクセスを実現しています。
Kubernetesにおけるコンテナネットワーク
Pod間通信
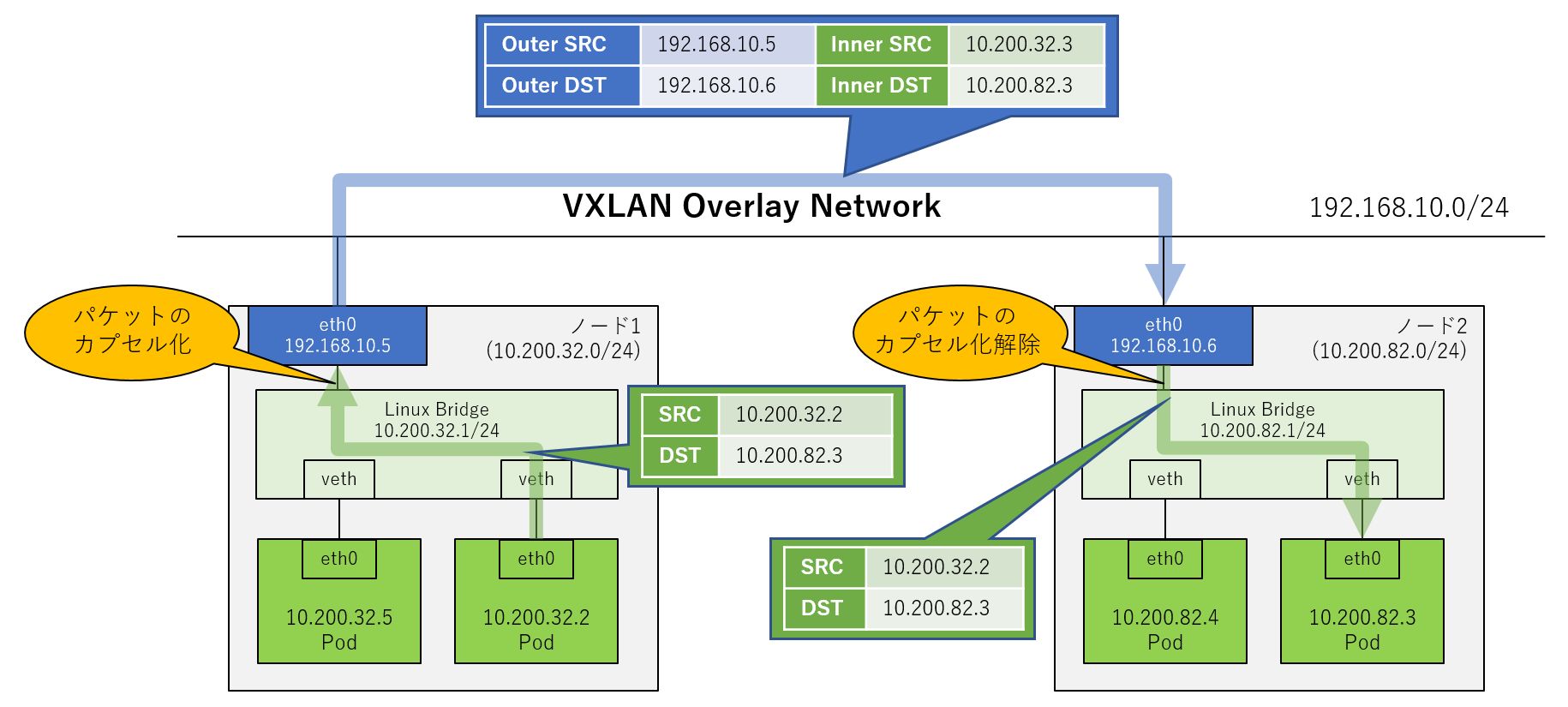
Kubernetesではコンテナをクラスター環境で実行するため、コンテナ(以下Podと呼びます)間の通信が課題となります。Dockerと同じように各Podには独立したIPアドレスが割り当てられますが、これはコンテナホストであるNode内でのみ有効なものであり、Pod同士がNodeを跨いで通信しようとすると、そのままのIPアドレスで通信することは困難です。Dockerではこの課題を解決するためにNATを利用していますが、Pod作成の度にNATテーブルを操作するのは効率的ではありません。そこで、多くのコンテナネットワークソリューションではオーバーレイネットワークを採用しています。
オーバーレイネットワークは送信されたパケットをカプセル化して宛先に届け、受信側でカプセル化を解いて宛先に届けます。既存のSDNソリューションにはVXLANによるオーバーレイネットワークを利用するものが多くありますが、コンテナ環境でもVXLANが利用されます。Podから送信されたパケットはNode内のブリッジを経由して、Linuxカーネルでカプセル化され、宛先Nodeに送信されます。受信したNodeは受信したパケットのカプセル化を解いて宛先のPodにパケットを届けます。このようなオーバーレイネットワークをNode間で構成することにより、複数Node環境におけるPod間通信を実現します。FlannelやOpenShift SDNはオーバーレイネットワークを採用しています。
また、別の実装としてPodが持つIPアドレスをNodeネットワークに公開する方法もあります。Calicoは、Podに割り当てられるIPアドレスをBGPによりNode外部に広報し、各Node上で機能するBGPの機能がPodに対する経路情報を学習します。この手法であれば、基本的にNATは利用されないため、パフォーマンスインパクトを小さくすることができます。また、Nodeが接続されたネットワーク機器もBGPを設定することで、Pod向けネットワークをルーティングテーブル上で確認することが可能です。
ServiceによるPodの負荷分散
クラウドネイティブなアプリケーション環境では、ロードバランサーが非常に重要な役割を果たします。Kubernetes上ではPodに対する可用性やスケーラビリティ向上のためにロードバランサーを利用することができます。クラウドネイティブ環境において、可用性やスケーラビリティの向上と同じく重要なのが、「Pod同士を疎結合に構成する」という点です。具体的には、Podグループに対してロードバランサーで仮想サーバーを構成し、仮想サーバーに対する名前解決を設定します。これにより、Podが別のPodにアクセスする際に、PodのIPアドレスを指定してアクセスするのではなく、アクセス先のPodサービス名でアクセスすることが可能になります。この機能はKubernetes上で「Service」と呼ばれるリソースで実現します。この実装により、Pod同士を疎結合に構成する事が可能になり、Podグループは簡単にスケールアウトすることができるようになります。多くの実装ではこのService向けのロードバランサーはLinuxカーネルのiptablesが利用されます。
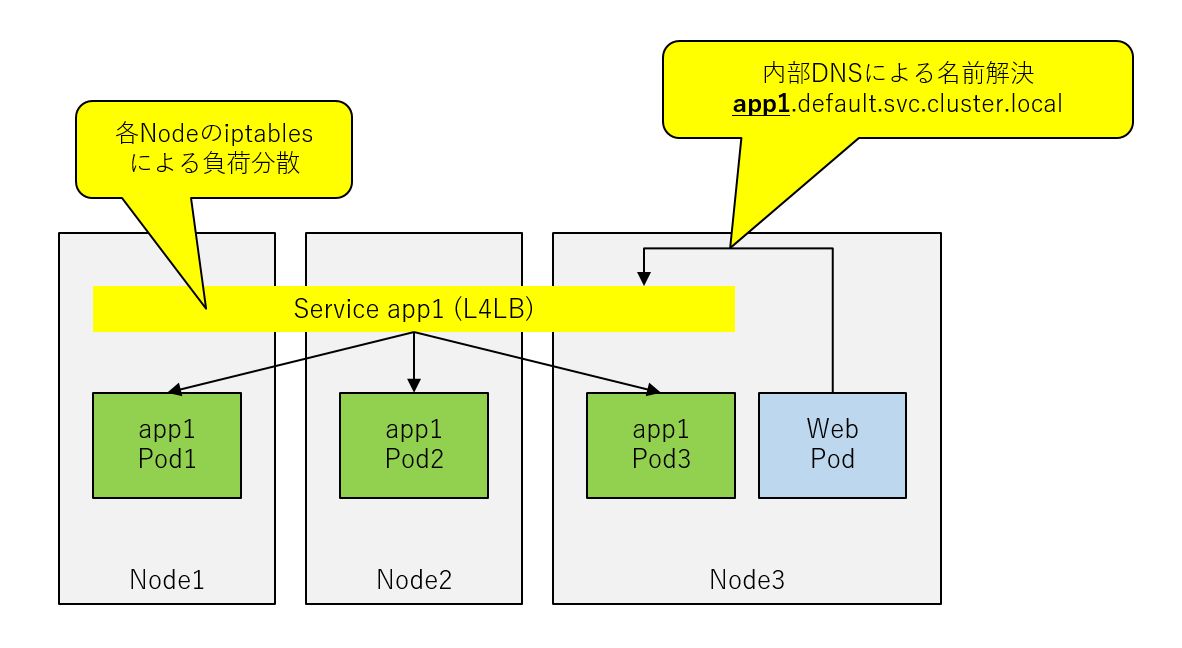
ServiceリソースにはいくつかのTypeが存在しますが、「Type: LoadBalancer」として設定することで、クラスター外部のロードバランサーを介してPodを外部向けに公開することもできます。この機能はKubernetesクラスターの外部の機能との連携が必要になります。例えば、パブリッククラウド上でKubernetesクラスターを構成している場合、クラウドサービスが提供するロードバランサーサービスが利用されます。
Kubernetesクラスター外部へのサービスの公開
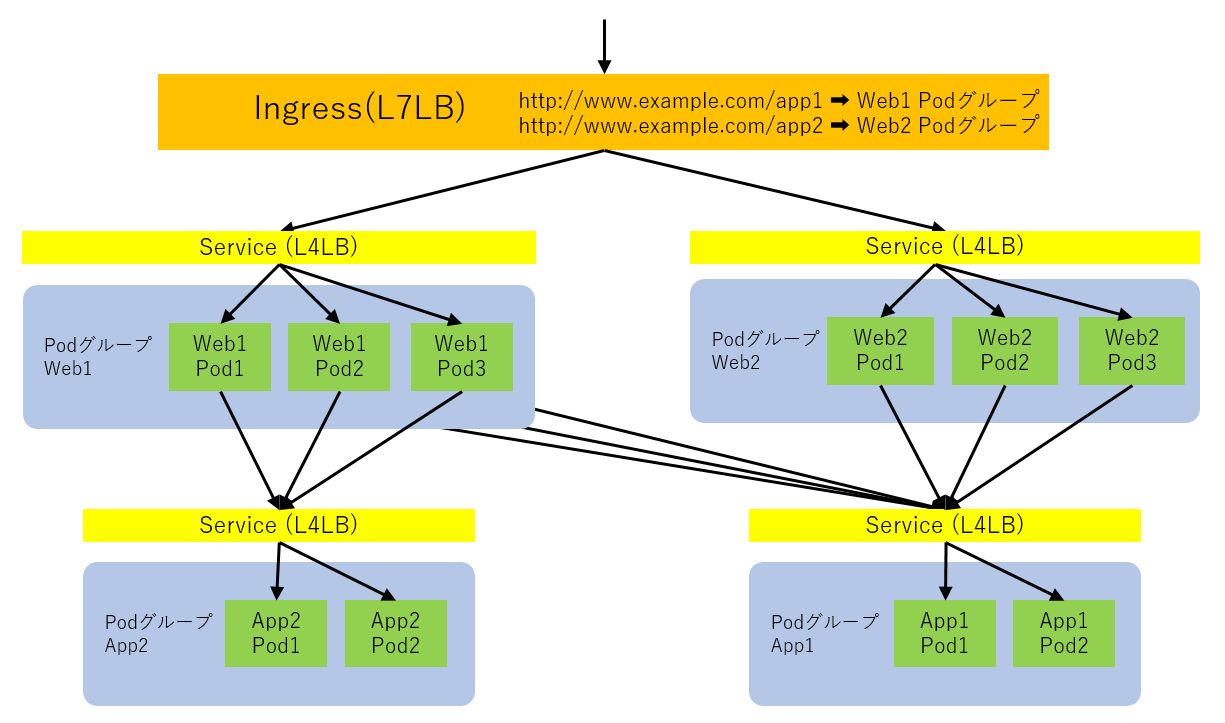
KubernetesにIngress Controllerと呼ばれる機能を追加することで、L7ロードバランサーを使用してサービスを外部に公開する事も可能です。Ingressはクラスター外部からのアクセスを前述のServiceに対してルーティングします。L7ロードバランサー機能はバーチャルホストとパスベースのルーティングに対応しているため、パス毎に異なるサービスにルーティングすることができ、きめ細かい負荷分散機能を利用することが可能です。Ingressによりサービスをクラスター外部に公開し、クラスター内のPod間通信をServiceによって制御することで、以下のようにマイクロサービスアーキテクチャを構成することが可能です。
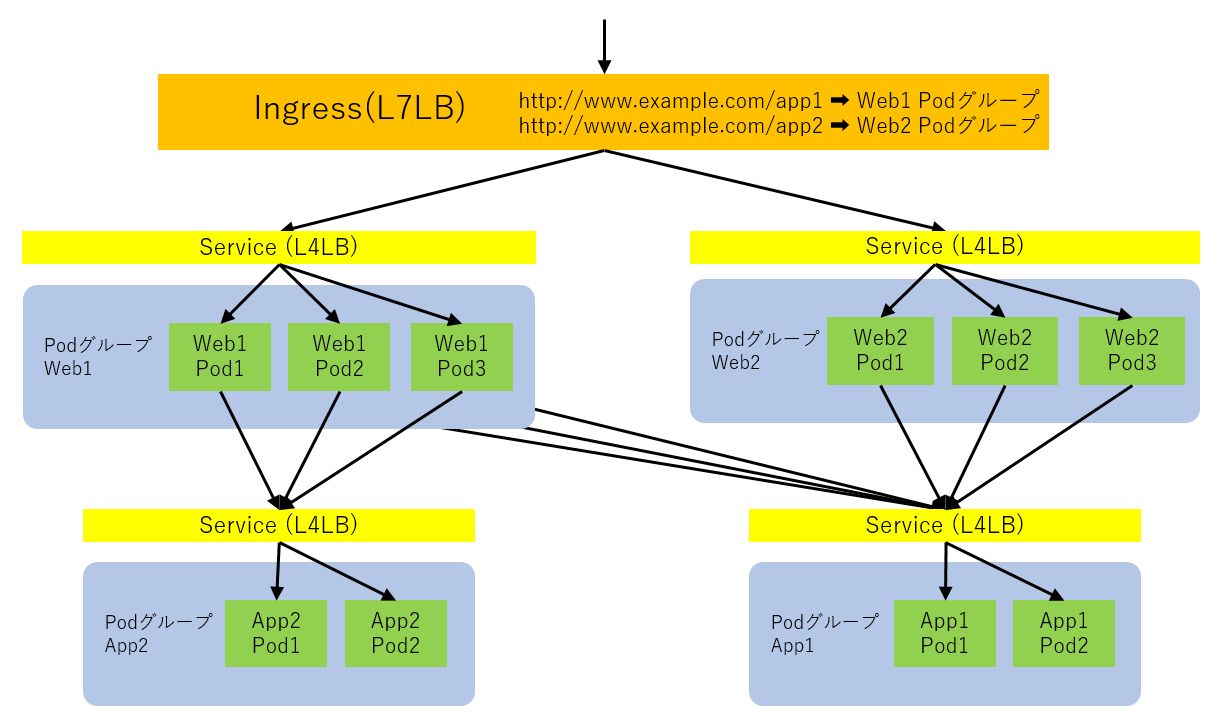
ベンダーソリューションを活用したコンテナネットワークの運用管理
コンテナネットワークはオープンソースによる実装が数多くありますが、ネットワーク機器ベンダーやインフラベンダーもコンテナネットワーク向けソリューションを提供しています。KubernetesのコンテナネットワークはCNI(Container Networking Interface)と呼ばれる仕様に対応しており、ベンダーがCNI向けプラグインを提供していれば、こうしたベンダーのソリューションをKubernetesのネットワーク機能として利用することが可能です。
例えば、Cisco社はCisco ACIのCNIプラグインを提供しており、Kubernetes環境のネットワークとしてCisco ACIを利用することができます。KubernetesにはPod間の通信制御を行うNetwork Policyと呼ばれる機能がありますが、ACIを利用することでACIのEndpoint GroupやContractを利用してNetwork Policyを実現します。また、ACIにロードバランサーを連携させることで、L4ロードバランサーやIngress機能もAPIC経由で管理することができます。ACIとKubernetesの連携に関してはこちらの匠コラムで詳細をご紹介しています。
また、VMware社もNSX-T Data Center用のCNIプラグインを提供しています。NSX-TがNode間のオーバーレイネットワークを提供し、L4/L7ロードバランサーはEdgeと呼ばれるNSX-Tのネットワークノードが提供します。また、Nodeが起動するハイパーバイザー内にインストールされたNSXモジュールが持つ分散ファイアウォール機能によりKubernetesのNetwork Policyを利用してPod間の通信制御を行うことも可能です。
これらの商用SDNソリューションを利用することにより、インフラ管理者は従来のネットワークとコンテナネットワークを統合管理することが可能になます。各社ともネットワークソリューション向けの運用管理ツールを提供しており、これらを利用することにより従来のネットワークの運用管理手法を使って、コンテナネットワークを可視化、運用することができます。
まとめ
コンテナネットワークはサーバー内部で機能するため、従来のサーバー管理者・ネットワーク管理者の責任分界点はより曖昧になります。しかし、テクノロジーとしては従来から存在するSDNを活用しているため、ベンダー各社が提供する商用SDNソリューションを利用することで、従来のネットワークと管理を統合し、可視化を実現することが可能になります。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


