- ナレッジセンター
- 匠コラム
データ収集基盤のどこでデータを加工するのか
- 匠コラム
- データ利活用
ビジネス開発本部 第1応用技術部
第1チーム
片野 祐
はじめに
これまでも匠コラムやネットワンブログでネットワークを流れるデータの収集、分析、機械学習を用いた異常検知(こちらのシリーズ)やどこでデータの加工を行うべきなのか(こちら)について紹介してきました。本コラムではデータの加工場所とそれにともなう検討事項について、もう少し掘り下げた内容を共有したいと思います。
検証環境情報
- Elasticsearch: 7.0.0
- Kibana: 7.0.0
- Logstash: 7.0.0
- SNMP取得対象ルータ
※データをどこに貯めるか、可視化のソフトウェアはいくつか候補がありますが、今回は今までの匠コラムやネットワンブログに則ってElastic Stackを使いました。Elastic Stackの細かい説明は過去の匠コラム(こちら)をご覧ください。
準備:SNMPデータの取得
ネットワークの状態を監視するプロトコルとして代表的なSNMPですが、Elastic Stackで収集、可視化を行うためにLogstashのSNMP input pluginを使っています。以前はSNMPTrapにのみ対応していましたが、2018年の10月頃にPollingもできるようになりました。ネットワーク機器にSNMPの設定を入れ、Logstashには以下のようにOIDやホストの情報を入れるだけで、データの取得が可能になります。
input {
snmp {
get => ["[OID]"]
hosts => [{host => "udp:[IP Address]/161" community => "[community name]"}]
}
}
デフォルトのPolling間隔は30秒ですが、もちろん設定可能です。取得したデータは以下のようにElasticsearchに格納されます。
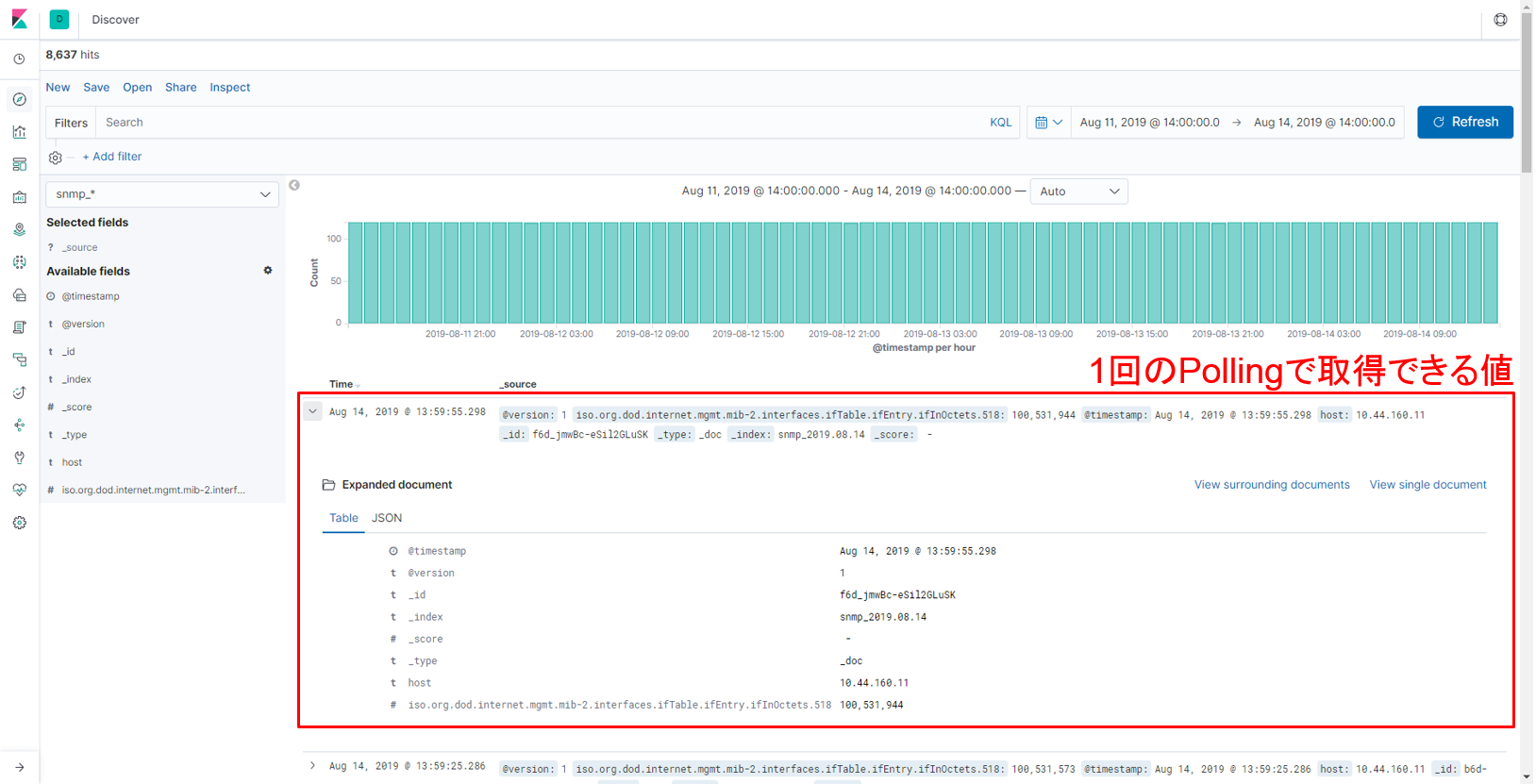
【図:取得したSNMPのデータ】
Elasticsearchにはfield:valueの形式でデータが格納されますが、上記のように “iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifInOctets.518” というfieldに “100,531,944” というvalueが格納されていることがわかります。では次に、このデータを用いて加工、可視化を行います。
データの加工場所と検討事項
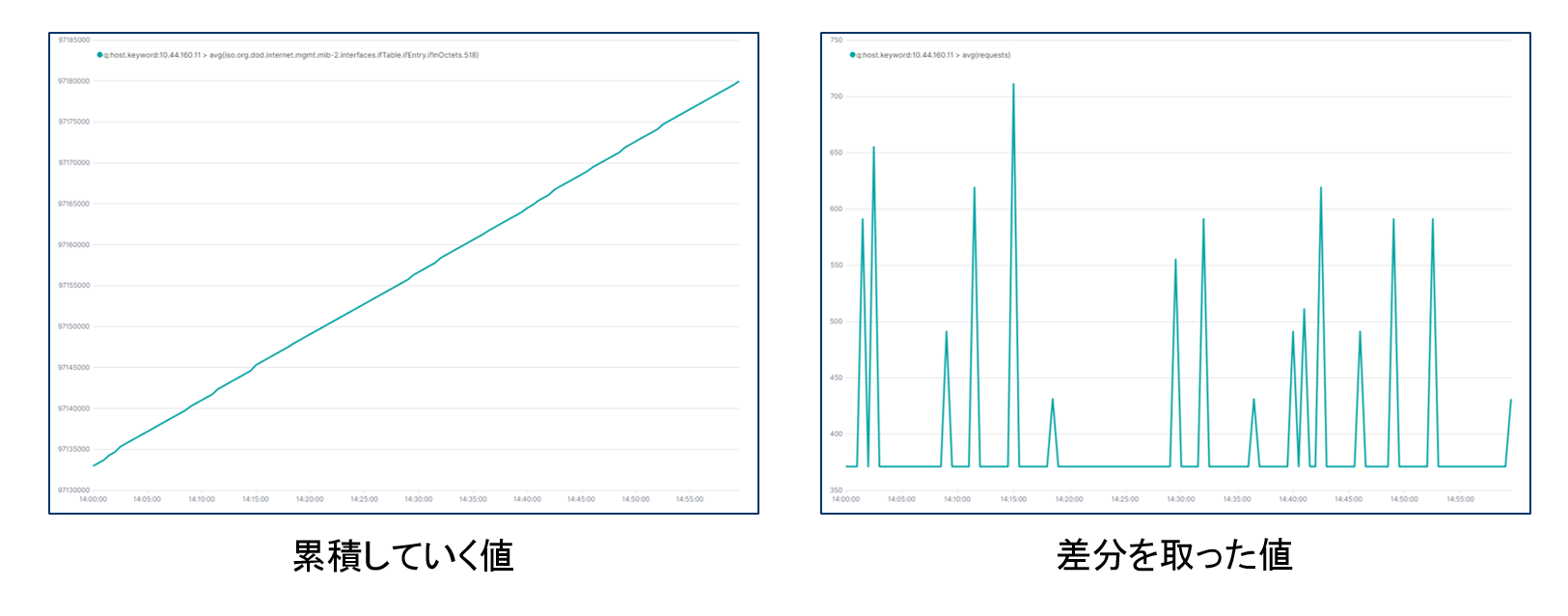
今回はSNMPで取得できるインターフェースが受信した総バイト数(ifInOctets)を対象にデータの収集を行いました。このifInOctettsは 100→200→300 のように、過去からの累積した値が取得されます。そのため、そのまま取得したデータの可視化を行うと常に上昇した(または変化がない)グラフが作られます。この値をそのまま使うと、特定の時間にどれだけのバイト数を受信したのか、についてはわかりにくい状態になってしまいます。そこで以下の2つのパターンでデータの加工、可視化を行い、それぞれでできることや課題を検討してみました。やりたいことは「累積していく値をそのまま使うのではなく、前回の値との差分を取った値を可視化したい」ということです。
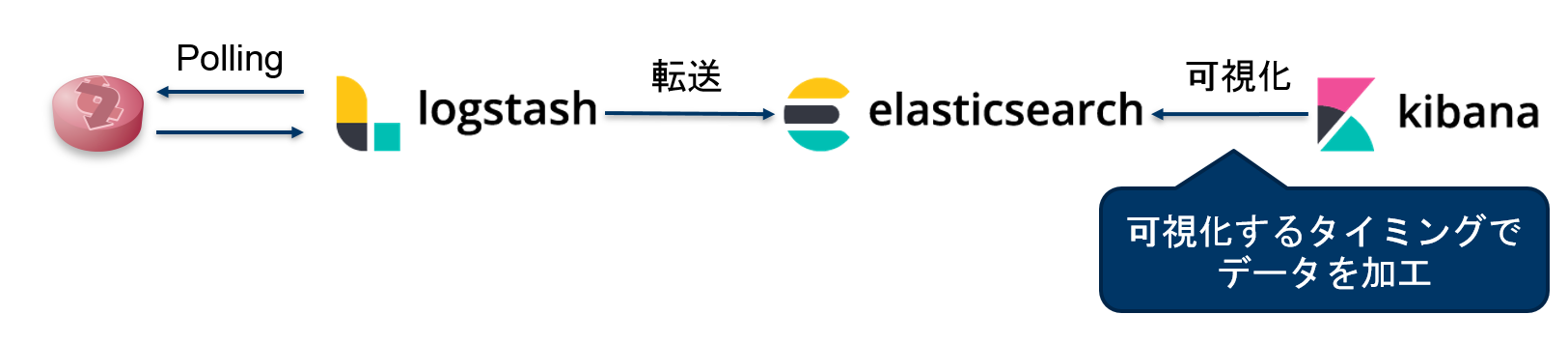
【図:パターン① 可視化するタイミングでデータを加工】
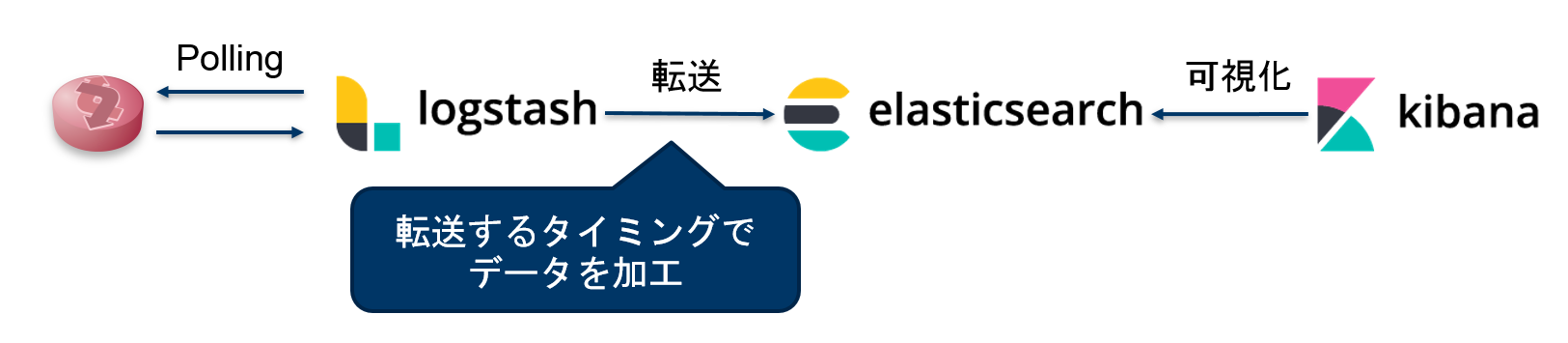
【図:パターン② 転送するタイミングでデータを加工】
パターン① 可視化するタイミングでデータを加工
まず、Elasticsearchに入れたデータをKibanaで見せ方を変える方法を試してみました。Elasticsearchに格納したデータを加工する場合、Scripted Fieldという機能を使うこともできますが、時系列を跨いだ計算ができないため、今回はVisualizeのTimelionにあるsubtract関数を使いました。
※subtract関数:あるグラフから、特定の時間遡ったグラフを引き算をする関数
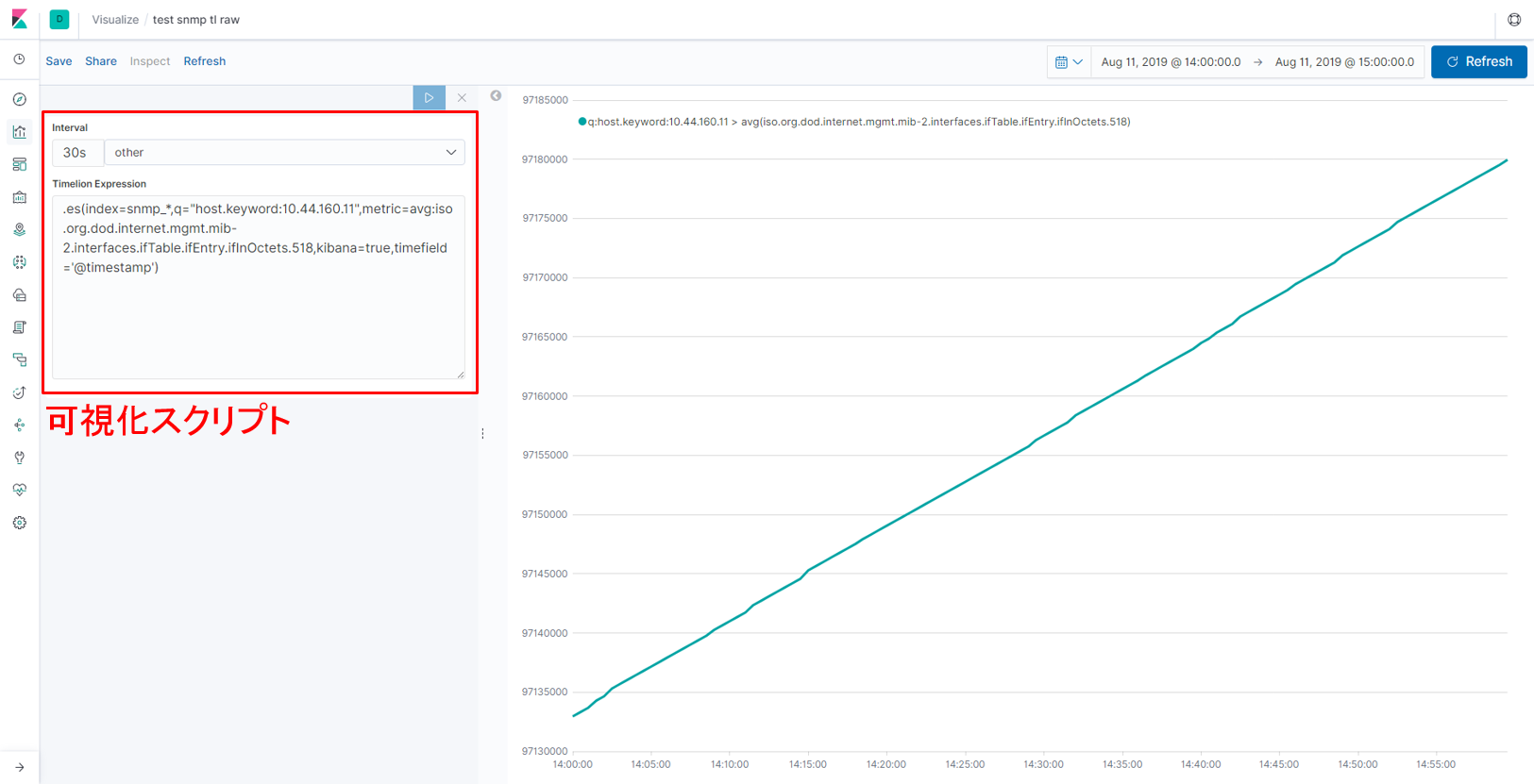
【図:取得したデータをそのまま可視化】
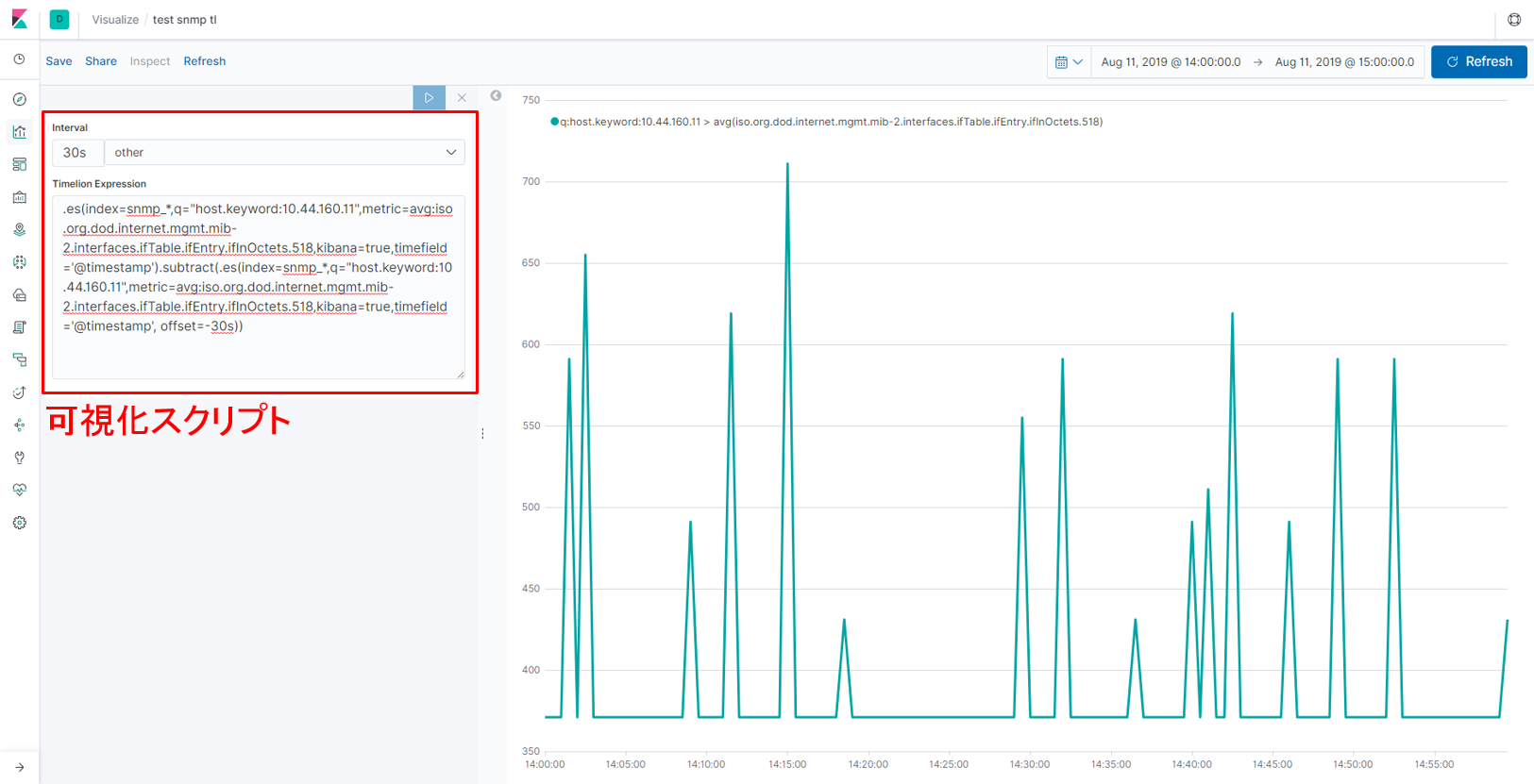
【図:subtract関数を用いて差分を取った値を可視化】
可視化のために記述したスクリプト(図の左側)の細かい解説はここでは省略しますが、「1つ前に取得した値と差分を取った値を可視化する」ことを実現しています。ただし、可視化の次のステップ(分析等)を考えたとき、この可視化方法はElasticsearchに格納されたデータの見せ方を一時的に変えているだけなので、ここで可視化した値(差分を取った値)自身の実体はありません。そのため値の二次利用を行うことはできません。
パターン② 転送するタイミングでデータを加工
パターン②では1つ前に取得した値と差分を取った値をあらかじめ計算し、Elasticsearchに格納しています。差分を計算する方法や、計算を行う場所はいくつか考えられますが、今回はLogstashのRuby filter pluginを使って、差分の計算を行いました。以下のように “requests” というfieldに計算した値を格納しています。
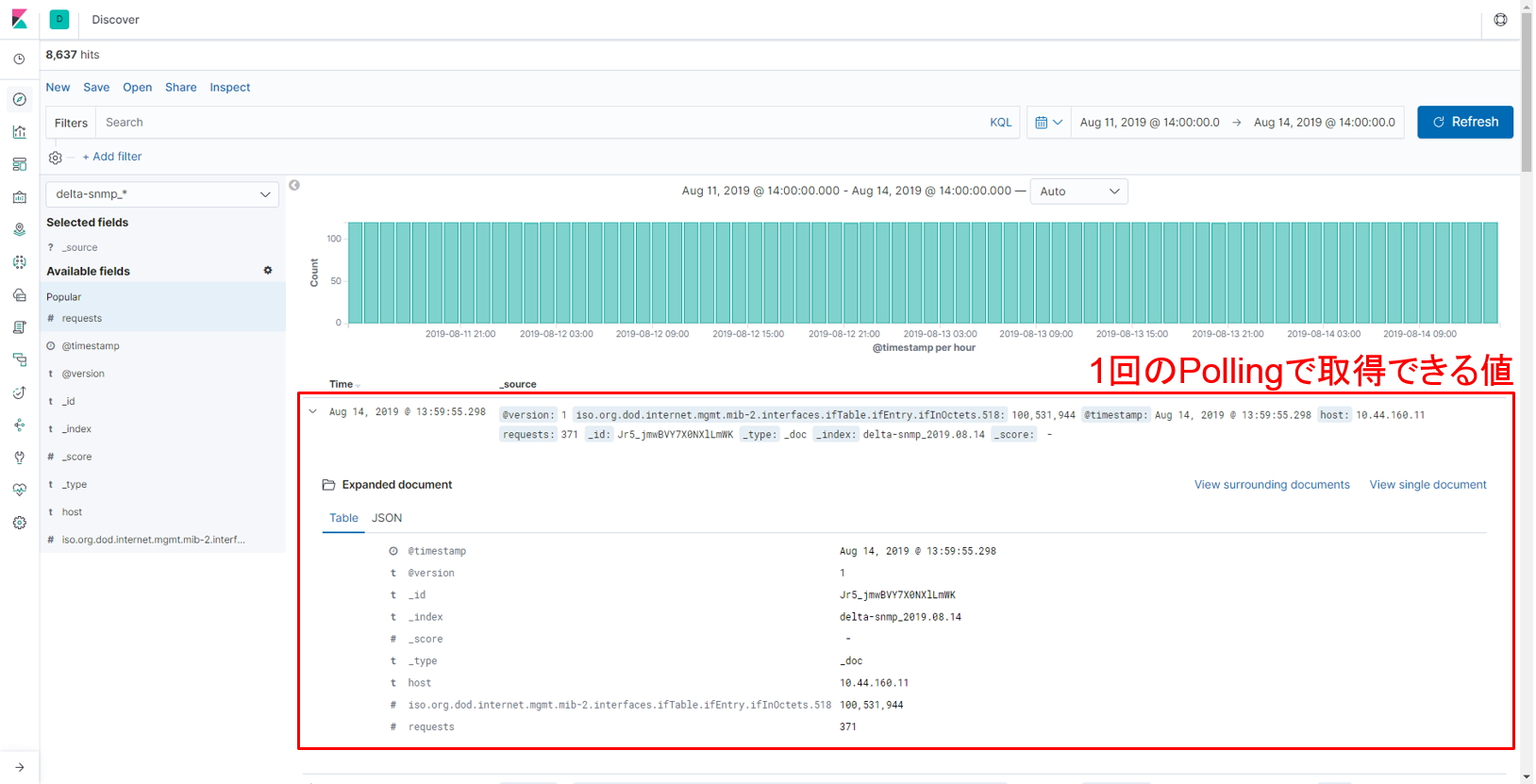
【図:差分を取った値もElasticsearchに格納】
この値(requests)を使ってグラフを描くと、パターン①と同様の可視化を行うことができます。あらかじめ可視化したい値そのものがElasticsearchに格納されているので、可視化のためのスクリプトも非常に短くなります。
※今回は比較のためTimelionでグラフを描いていますが、可視化したいデータそのものがElasticsearchに格納されていれば数クリックで同様のグラフを描くことができます。
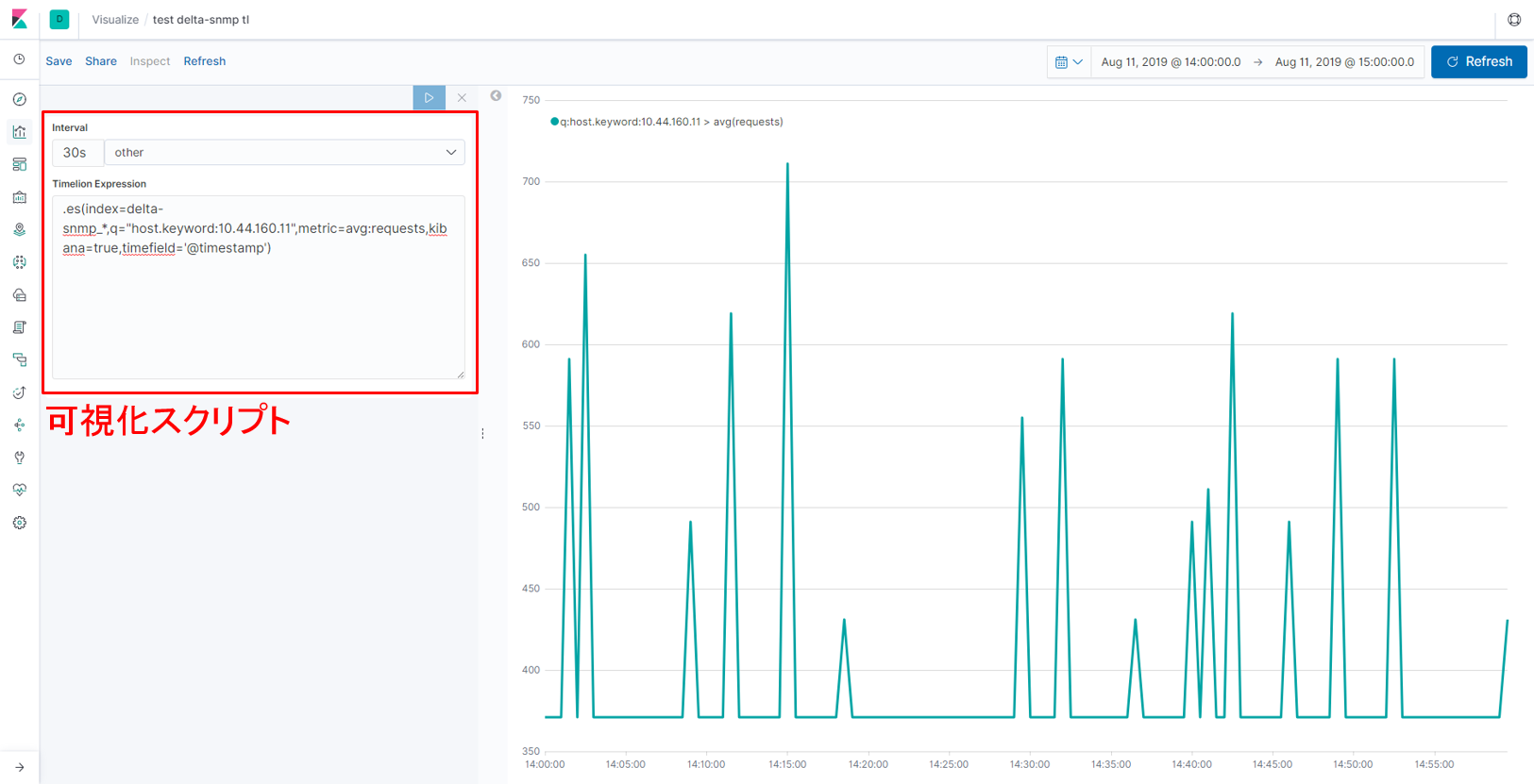
【図:差分を取った値の可視化】
データを格納する前に加工しておくことで可視化を簡単に行うことができるようになりましたが、それと引き換えに新しくデータを生み出した分、格納するための保存領域を多く使っていることになります。そのため、生データは格納しない等のデータの取捨選択を行わないと、データ量が膨大になっていってしまいます。
2つのパターンで差分を取った値の可視化を行いましたが、両方に共通した課題もあります。それは累積していく値そのものがリセットされる(32bitや64bitを超えると値が0に戻る)タイミングで一度負の値を取るため、意図したデータが取れずグラフも大きく崩れてしまうことです。これに対する対処をしないと、次のトピックである機械学習を使った異常検知をしようと思っても誤検知が生まれる可能性があります。
また、今回は検証のため1台のルータの1つのインターフェースから、1つのメトリック(ifInOctets)を取ったため、可視化もそれほど大変な作業ではありませんが、これが1000台のルータの48のインターフェースから複数メトリックを取得するとなると、同じように可視化を行うのは現実的ではありません。この場合、field名の変更や新しくタグを付ける等、さらに加工やデータの付与が必要になると考えられます。データの加工にも計算リソースを使うので、そのリソースをどこにかけるか、という視点も必要になってきます。
ここまでは可視化を目的にしてきました。ここからはデータの活用を目的として、Elastic Machine Learningを使って分析した結果を共有します。
Elastic Machine Learningの利用
Elastic Stackではこちらで紹介したように教師なし機械学習(ElasticMachineLearning)を行うことができます。この機械学習に使えるデータはElasticsearchに格納されているデータになるので、差分を取った値を使いたい場合は先ほどのパターン②でデータを取得する必要があります。今回は比較のために、累積していく値(生データ)と差分を取った値の2つで機械学習を行い、異常検知の結果を見てみました。
【図:機械学習を行った2つのグラフ(一部の時間帯を抜粋して表示)】
累積していく値(生データ)を使った場合
以下の図が累積していく値に対して機械学習を行い、異常検知を行った結果です。青い実線が実測値、うすい水色の部分が機械学習が導き出した値の範囲(通常であればその中に値が収まる範囲)です。一部で異常が検知(グラフ内に印がついている点)されたように見えますが、実際にはまわりの値をそれほど変わりはなく、本当に異常であったかどうかは疑問が残ります。もちろん、より値の変化が大きい場合は異常として人間も納得する結果になるかもしれませんが、Elastic Machine Learningは「いつもの状態を学習し、いつもの状態から外れたところを異常とする」ものなので、累積していく値はElastic Machine Learningにはあまり適していないデータであったことが推測されます。機械学習を行う際には、どのようなデータを扱うのかも重要な検討事項となります。
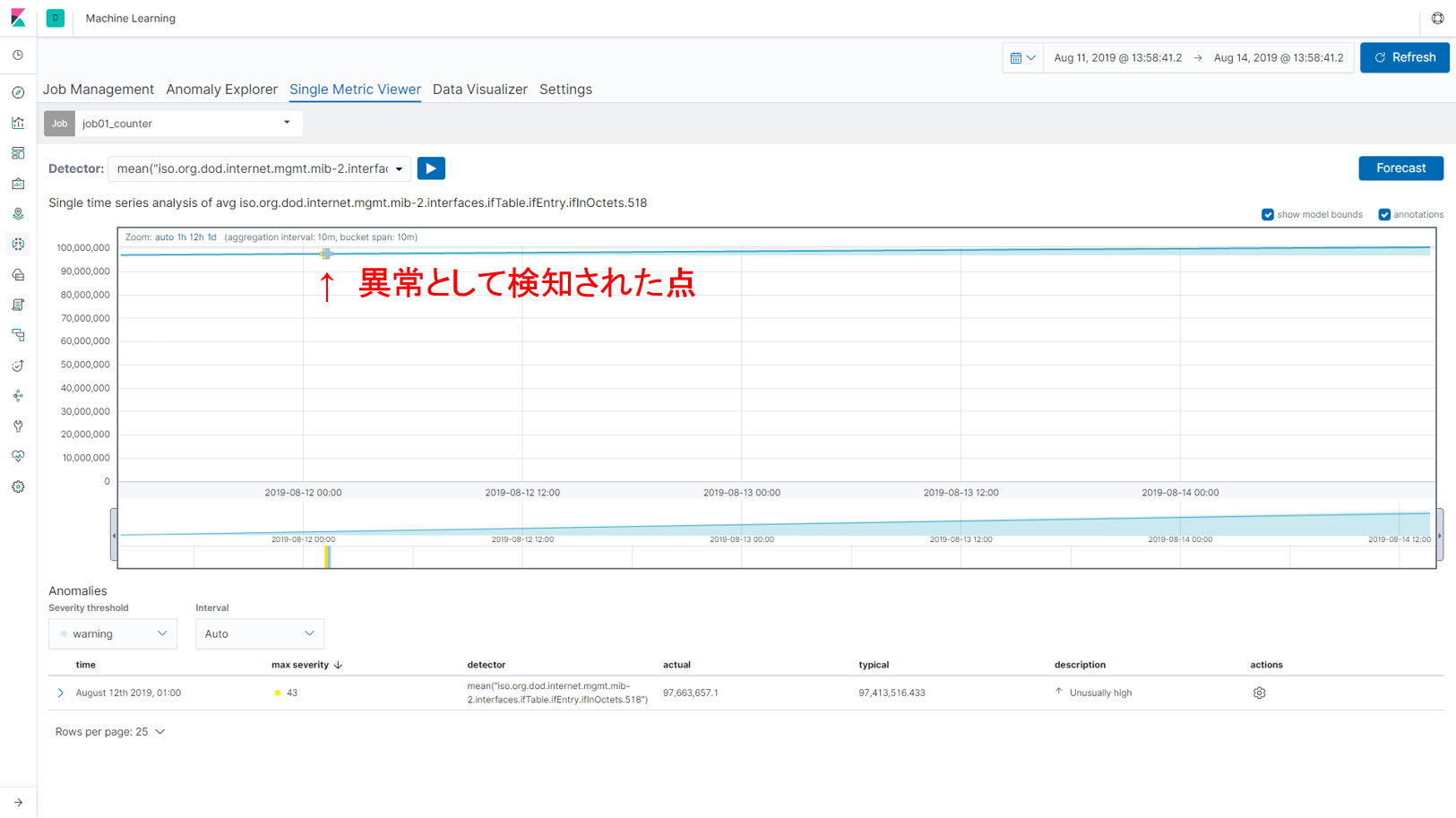
【図:累積していく値を使った異常検知結果】
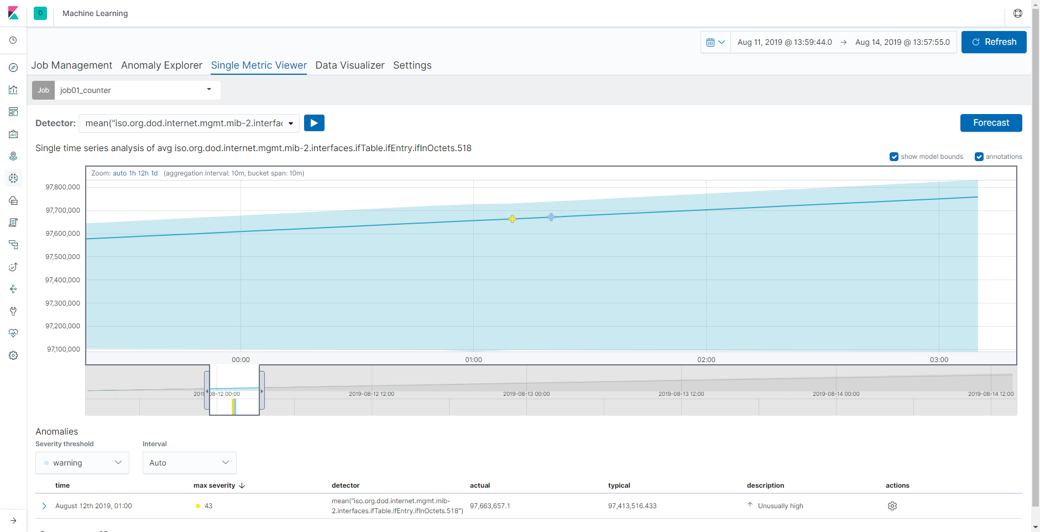
【図:累積していく値を使った異常検知結果(拡大図)】
一方、Elastic Machine Learningには値のforecast機能もあり、こちらを試してみると、精度の高い予測ができているように見えます。この機能を使えば、将来を見据えた設定変更やリソースの見直しができます。Elastic Machine Learningを使う目的によっては、累積していく値をそのまま使うことも十分考えられます。
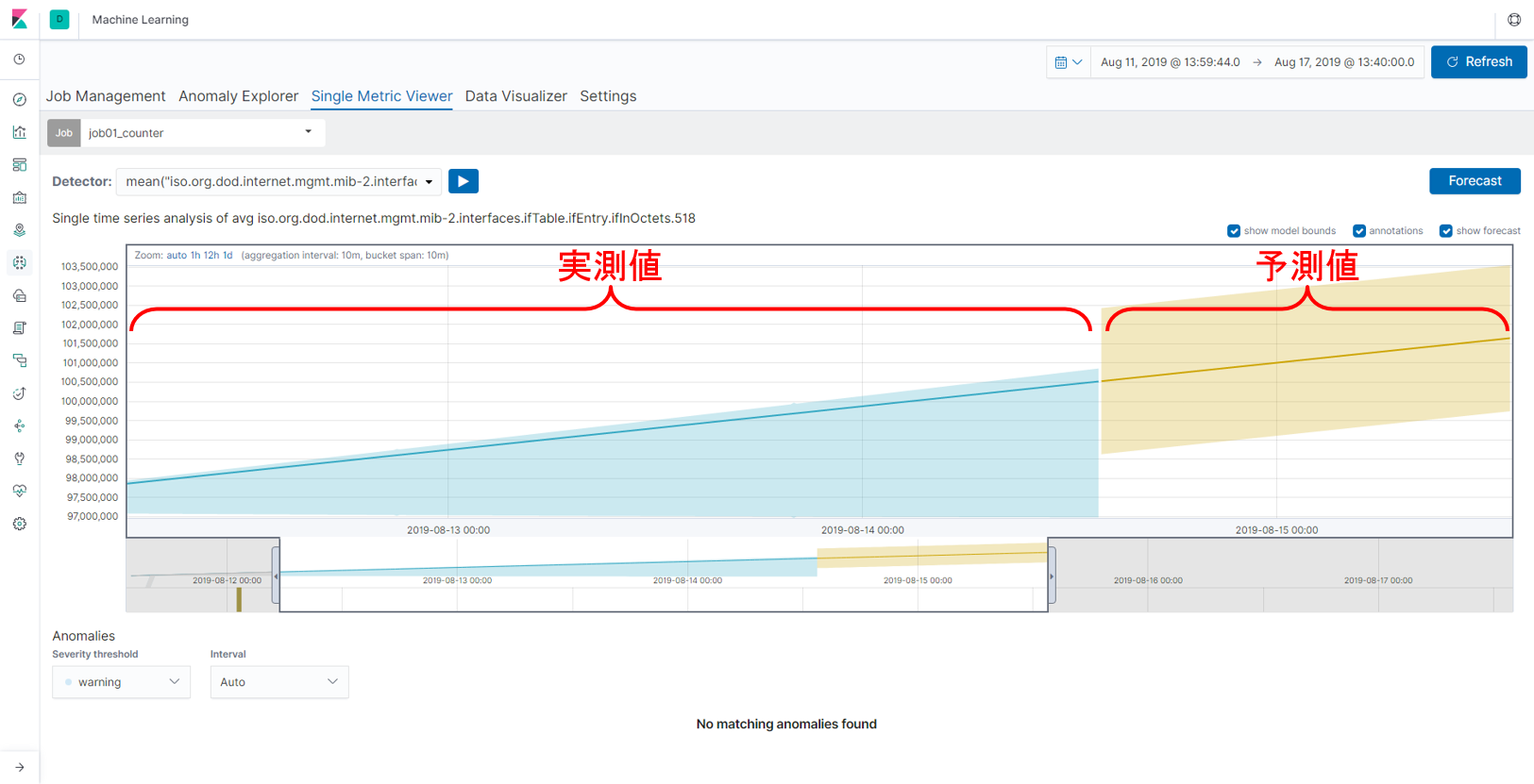
【図:forecast機能を使った将来の値の予測】
差分を取った値を使った場合
差分を取った値に対して機械学習を行い、異常検知をした結果が以下の図です。機械学習が導き出した「いつもの値の範囲(うすい水色の部分)」がある程度の範囲に収まり、微小な変化でも異常として検知していることがわかります。今回は検証用に準備したルータからデータを取得しているため、差分を取った値がほぼ同じ値(同じペースで値が累積していく)です。微小な変化でも異常として検知していますが、日中はトラフィック量が多く、夜間は少ないといった周期性のあるデータであれば、それも加味して機械学習のモデルが作られるため、より異常を正しく検知してくれることが期待されます。
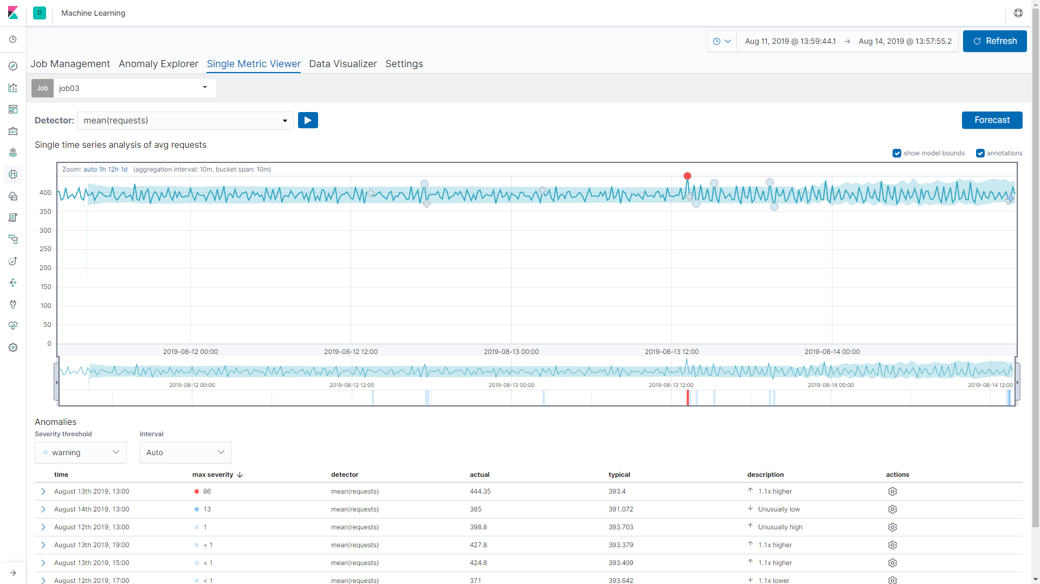
【図:差分を取った値を使った異常検知結果】
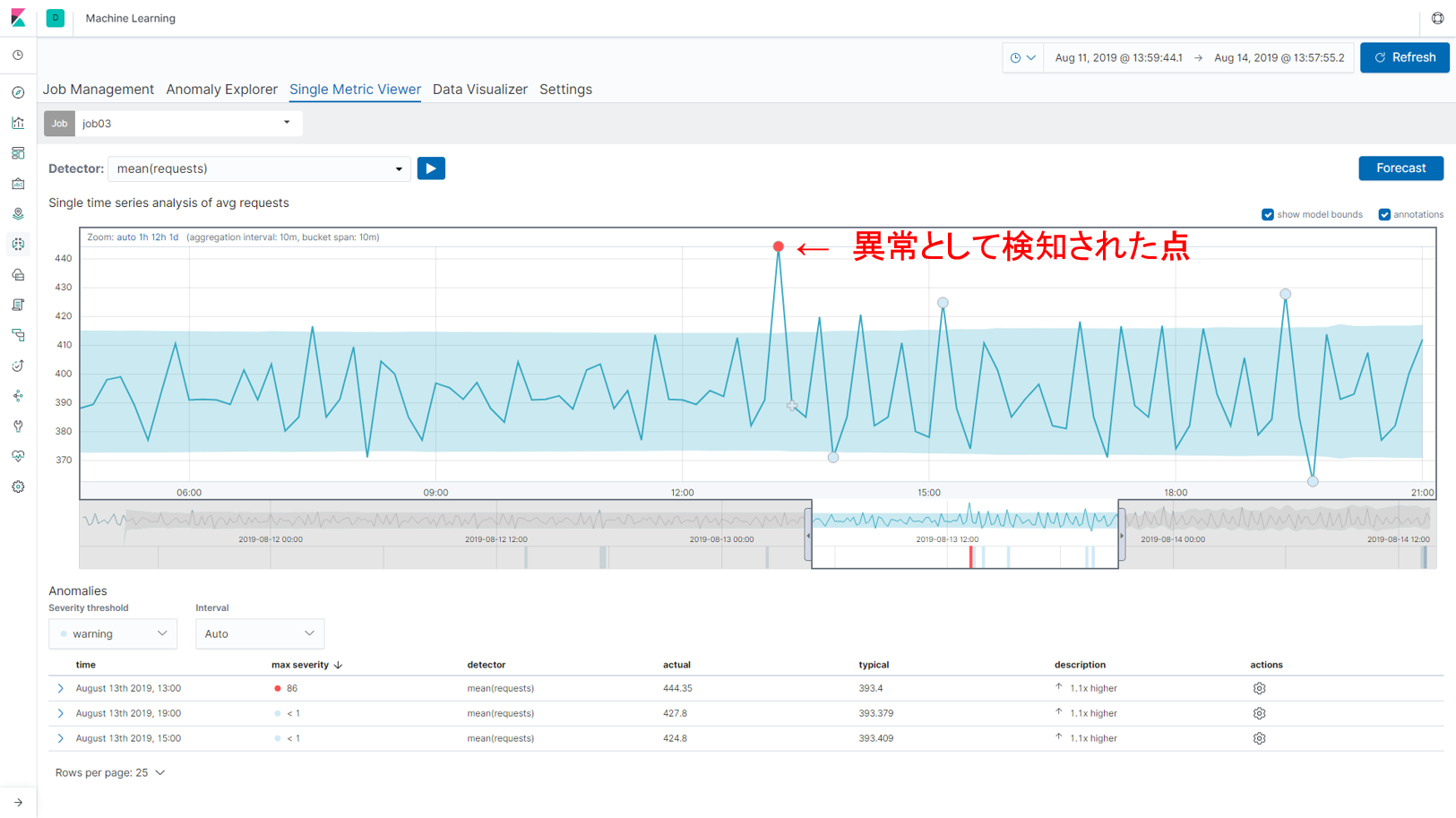
【図:差分を取った値を使った異常検知結果(拡大図)】
実際はトライ&エラーを繰り返しながら検証を繰り返し、機械学習に使う値を決めていくことになりますが、上記のように、使う値によって実現できる内容が変わってくるため、データを格納する段階から先の分析について考えておく必要があります。
おわりに
本コラムではデータの加工場所と可視化、加工したデータの利用について紹介しました。一概に「ここでデータの加工を行うべきだ」と断定することはできませんが、検証を通してあらためて検討すべきことがいくつもあることがわかりました。ネットワンでは、ネットワークデータだけでなく様々なデータソースから生まれるデータをどこに、どのように貯めるべきか、アーキテクチャを検討しています。そちらに関しても今後ご紹介していければと思います。
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス開発本部
第1応用技術部 第1チーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索