- ナレッジセンター
- 匠コラム
ネットワークが創生する価値 再考④:Workflow エンジンによる管理の自律化
- 匠コラム
ビジネス開発本部 第1応用技術部
第1チーム
ハディ ザケル
これまで、本連載コラムでは次世代 SNMP とも呼べる「Telemetry」について、その登場背景や技術要素を説明し、Telemetry 情報の活用方法について記載しました。連載の最終回として「Workflow エンジンによる管理の自律化」について紹介したいと思います。
| 連載インデックス |
|---|
ネットワークデバイス運用管理の自律化へ
ネットワークデバイスの自動化に向けての取り組みは歴史が長く、古くはスクリプトの利用、最近では Ansible を使った自動化などがあります。これらの取り組みはいわゆる Day0 と Day1(インストール及び構築) にフォーカスを当てたやり方で、初期設定、運用開始までの作業自体の工数削減が主な目的でした。本連載の最終回となる今回では、ネットワーク運用時の(Day2 以降)自動化・自律化に焦点を当て、現在どういったことが可能なのかをご紹介します。
本コラムの「ネットワークデバイス運用管理の自律化」とは、安定したネットワーク機能を提供し続けることを意味しています。この概念を実現するためには、ネットワーク内の異常な振る舞いや状態遷移があった場合、自動的に”正常”な状態に戻せる能力が必要になります。この一連の動作を機械のみで実現したい場合、
- 正常な状態の定義
- 異常となりうる状態の洗い出し
- 異常度合いの事前定義
- 異常時の対処方法の洗い出し
上記の各項目を人間の手で事前に実施する必要があります。しかし、現時点であらゆる状態にこれらの定義及び洗い出しが完了していないたため、対処範囲をしっかりと見定めた上で自動化や部分最適化(以下ネットワーク自動最適化)を検討すべきだとネットワンは考えています。
さて、本連載のメイントピックである Telemetry と今回のネットワーク自動最適化の繋がりですが、質の良い可視化は自動化の第一歩だと考えています。自動的にネットワークに対して何か制御をしたい場合、”今”ネットワーク内で起きている事象を正確に把握する必要があり、結果としてリアルタイム可視化が重要になってきます。例えば SNMP だとポーリング間隔は分単位(5分~30分)であり、平均化された情報をもとにネットワーク制御をしてしまうとネットワークの実態に伴わない制御になる可能性が出てきます。一方で監視対象デバイスの負担が少なく、秒単位で状態を取得できる Telemetry の場合、起きている事象に対して即座にアクションが実行することが可能になります。
Telemetry データを使ったネットワーク自動最適化
下図は Telemetry データを起点としたネットワーク自動最適化 PoC の概要になります。各種ネットワークデバイスから送られてくる Telemetry データを用いて、「データ収集基盤」にてデータの整形、蓄積、可視化及び分析を行います(データ収集基盤の詳細については本連載の①、②、番外編 – 前編、後編をご参照ください)。分析の結果、異常と判断した内容があれば、その内容を基にしてワークフローエンジンに作業依頼を実施し、ワークフローエンジン側では、指示に基づいた、ネットワークデバイスの自動最適化作業(コンフィグ変更等)を実施します。
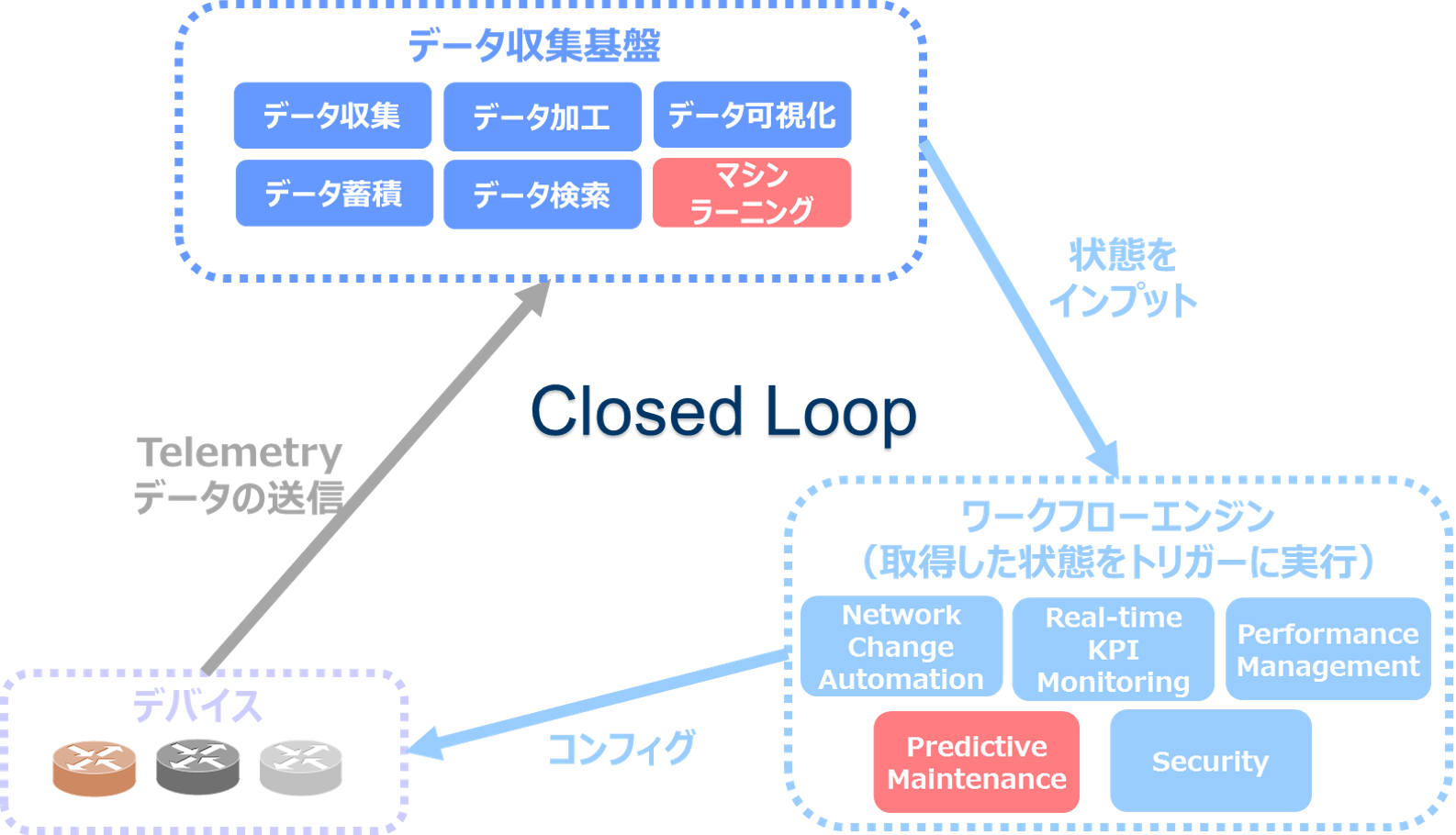
ネットワーク自動最適化 PoC の構成コンポーネント
今回の PoC では、ワークフローエンジンとして Stackstorm を利用しており、これは IFTTT(If This Then That)と呼ばれるツールの一つで、イベントが発生した場合そのイベントに対してアクションを実施します。本コラムで Stackstorm の詳細は割愛しますが、主に Trigger と Action の2つの機能を持っており、これらを組み合わせることで Rule(もしくはもっと複雑な Workflow)と呼ばれる“一連の動作の組み合わせ“の定義が可能です。今回の環境では、Stackstorm 経由で Ansible Playbook の実行、Linux サーバ上のファイル操作の監視及び、チャットツールへの自動的なファイル添付を実現しています。
※ Stackstorm 英語版のサイト、Stackstorm Exchange(Pack 一覧)
その他のコンポーネントとして下記を利用しています。
- データ収集基盤:各種 Frontend ツール、Kafka、データ変換スクリプト、Logstash、Elasticsearch、Kibanaで構成
- Node-RED : API 変換ツール(https://nodered.jp/)
- Cisco Webex Teams:チャットアプリ
- Ixia:BGP ルート注入及びトラフィック生成器
- MX240:物理ルータデバイス(Telemetry 情報配信装置)
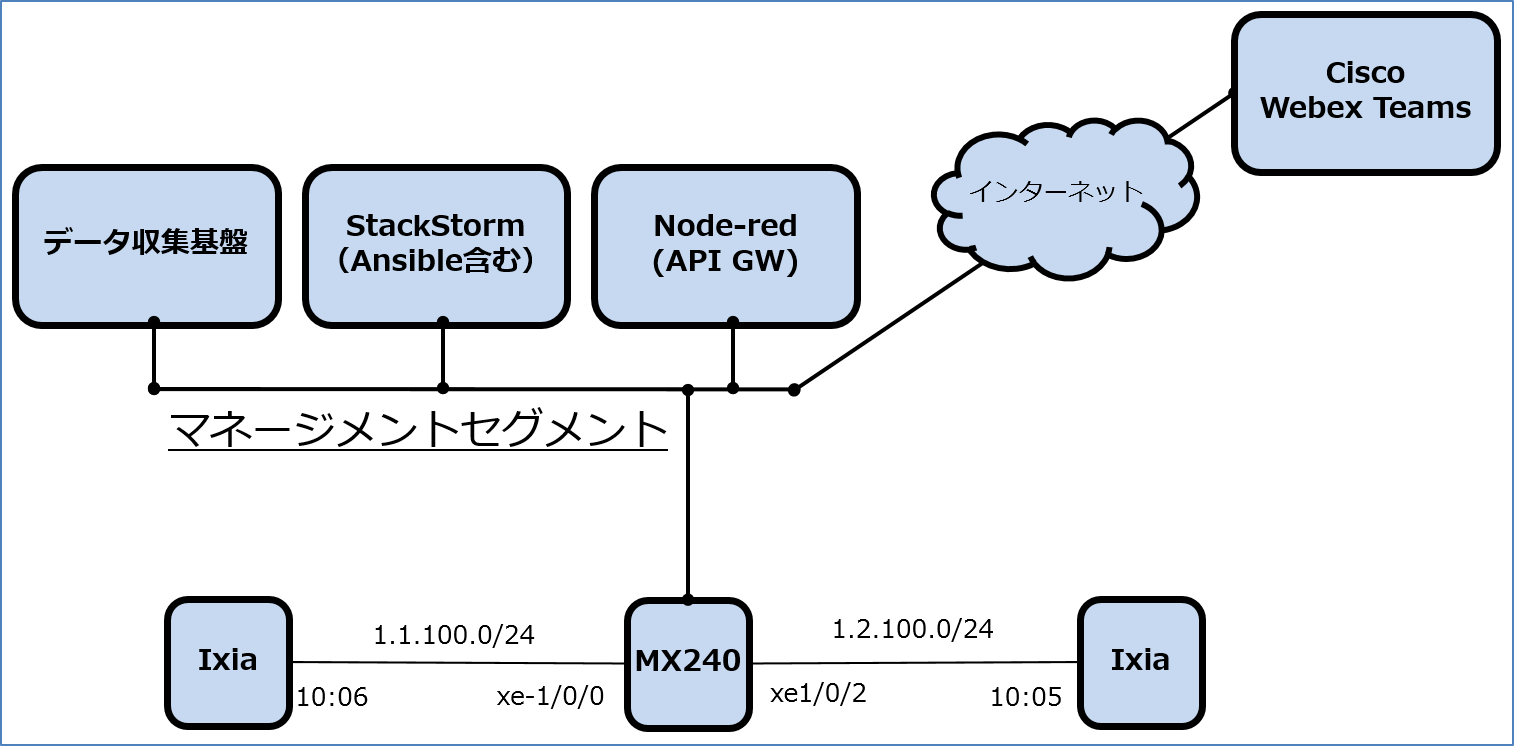
シナリオ:BGP Peer からアドバタイズされているルート数の監視
ネットワークデバイスの自動最適化のシナリオは、特定の BGP Peer からアドバタイズされているルート数をリアルタイムで監視し、Elastic の機械学習機能(Machine Learning)を利用することで、定常パターンから外れる異常な状態が発生した場合、Stackstorm 経由でその該当の BGP セッションをシャットダウンさせる内容になります。合わせて、ネットワークデバイス上で実施した設定変更のログをチャットツールに通知を行います。
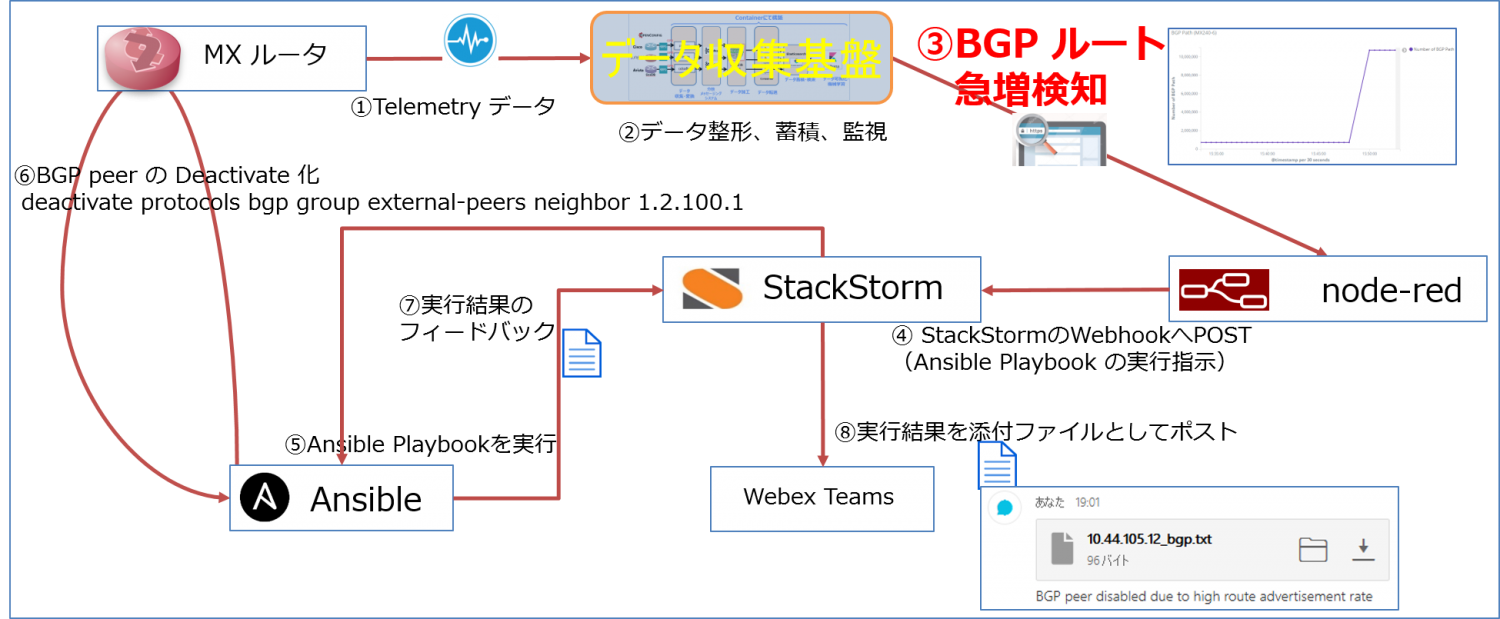
一連の流れとして、
① 物理デバイスから下記のセンサーパスにおけるカウンター情報を Telemetry の仕組みを使って発信「/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/afi-safis/afi-safi/state/prefixes/accepted」
② データ収集基盤にて、データの整形、蓄積、監視を実施。合わせて、機械学習機能を使ったルータデバイスのルート学習状況の正常な動きを把握
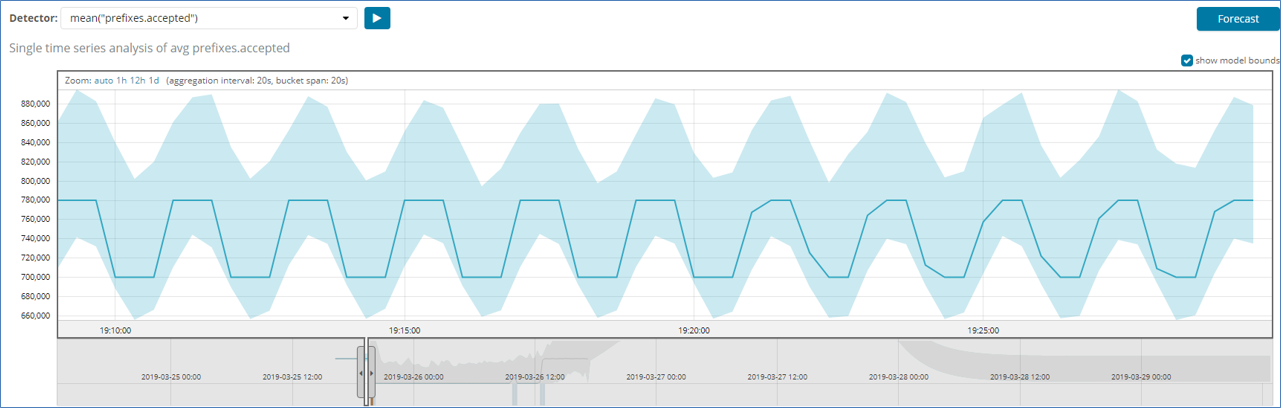
※ Ixia からのルート注入情報として、70万 prefix をベースとしてアドバタイズ、変動するルート数として、8万ルートを追加で注入し60秒間キープする。その後の追加で注入した8万ルートを withdraw し、60秒間をこの状態をキープ。(1分置きに、78万ルートと70万ルート間を行き来する状態)
③ 異常状態を発生させる目的で、Ixia より200万ルートを追加で注入した場合、機械学習で得られたパターンから外れた値になるため、下記のとおり、異常として検知することになる。(anomaly score は 49)
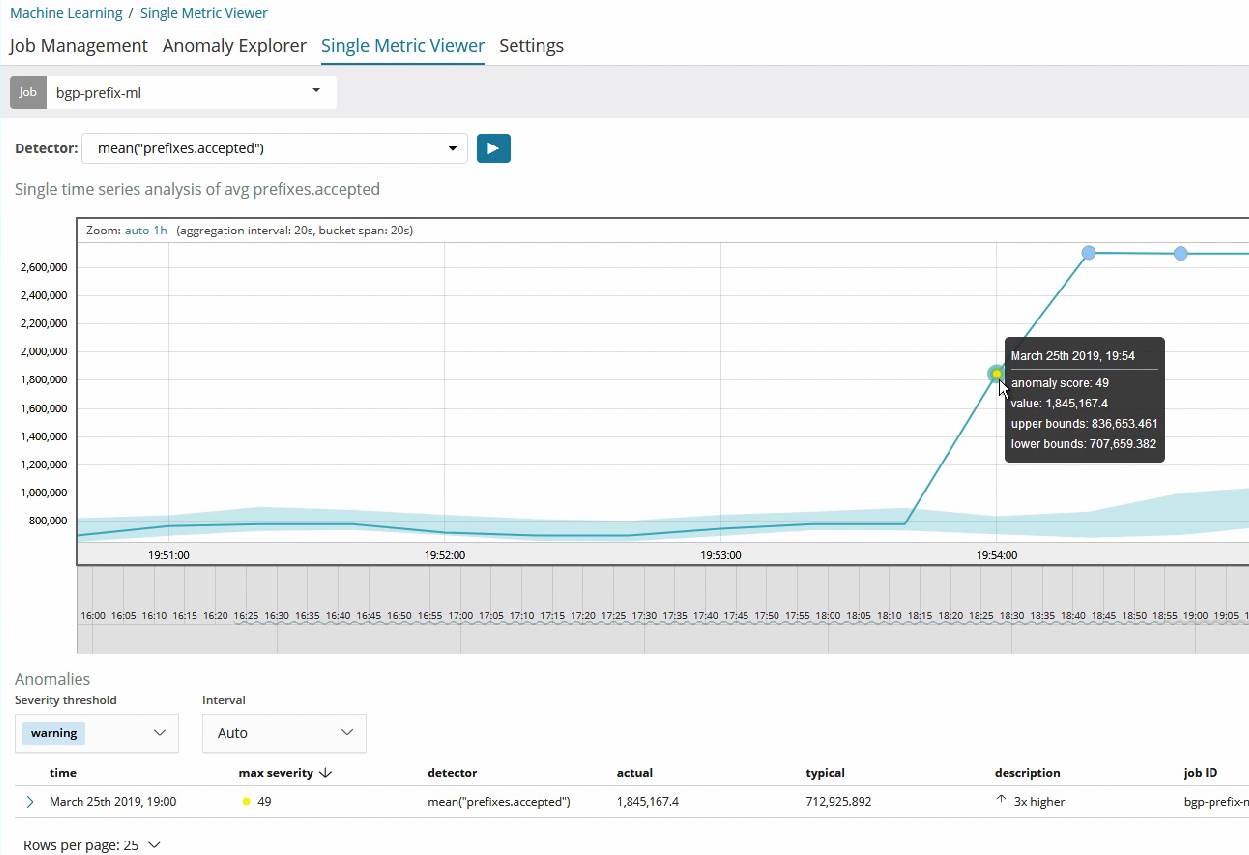
この様に異常を検知した場合、Elastic の通知機能(Watcher)を使って、Node-RED に対して通知を行う。
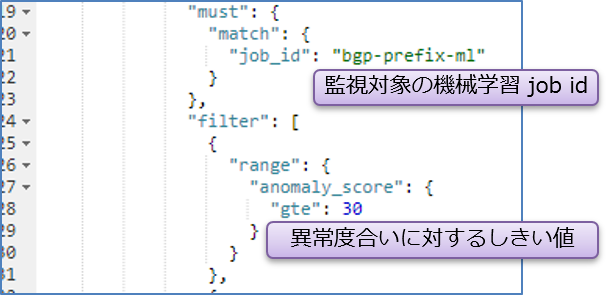
※この設定例では、anomaly score が30以上になった場合、外部通知を行う設定になります。
④ Node-RED で通知を受け取ると、API コールの変換を行い、次の Stackstorm を呼び出す。ここでは HTTP の API コールを HTTPS に変換する処理のみ実施している。
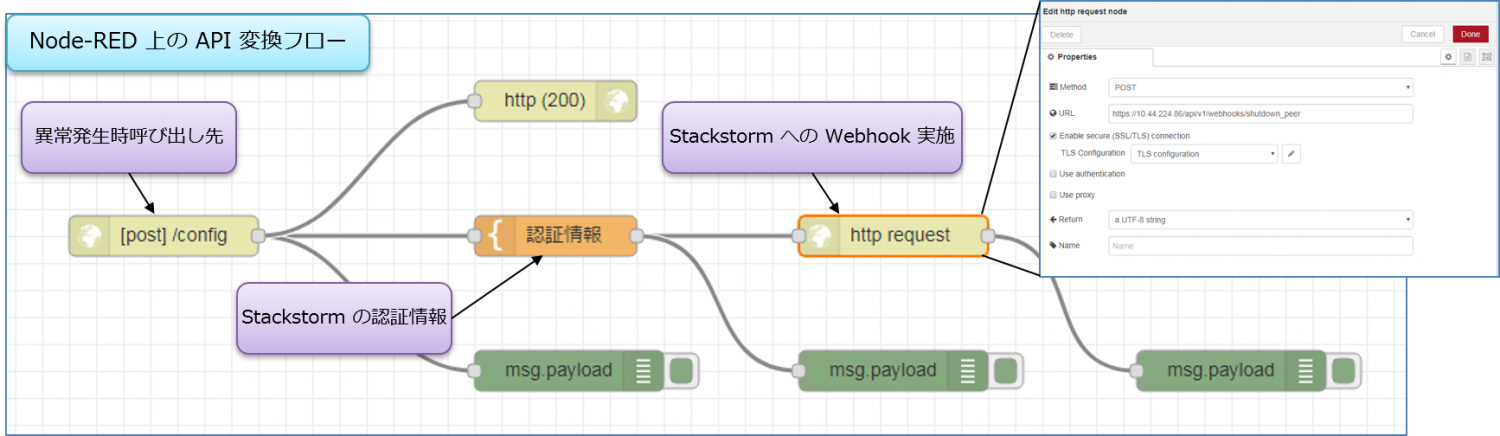
⑤ Stackstorm に対する Webhook の結果、事前に準備している Ansible Playbook が呼び出され、実行される動きになる。
下記は、Ansible Playbook の例:
root@st2:/etc/ansible# cat shutdown_bgp_peer.yml
---
- name: automating junos
hosts: junos
roles:
- Juniper.junos
connection: local
gather_facts: no
tasks:
- name: shutdown bgp peer
juniper_junos_config:
config_mode: "private"
load: "set"
lines:
- "deactivate protocols bgp group external-peers neighbor 1.2.100.1 "
register: response
- local_action: copy content={{ response.diff_lines }} dest=/etc/ansible/savefile/{{ inventory_hostname }}_bgp.json
vars:
MX240:
host: "{{ inventory_hostname }}"
username: "{{ ansible_ssh_user }}"
password: "{{ ansible_ssh_pass }}"
|
⑥ ⑤の Ansible Playbook でも記載されているとおり、実行結果の .json 形式の出力結果が所定のディレクトリ(/etc/ansible/savefile)配下に保存される。
⑦ 上記の保存先フォルダを Stackstorm のデフォルト搭載 Pack の一つである Linux 関連の Pack と inotify-tools の inotifywait を組み合わせてファイル操作を監視しており、新規の操作があった場合、操作されたファイルが検知できる仕組みとなる。
⑧ 手順⑦でファイル操作の検知ができると、ファイルそのものを Cisco Webex Teams に添付して一連の動作が完了。
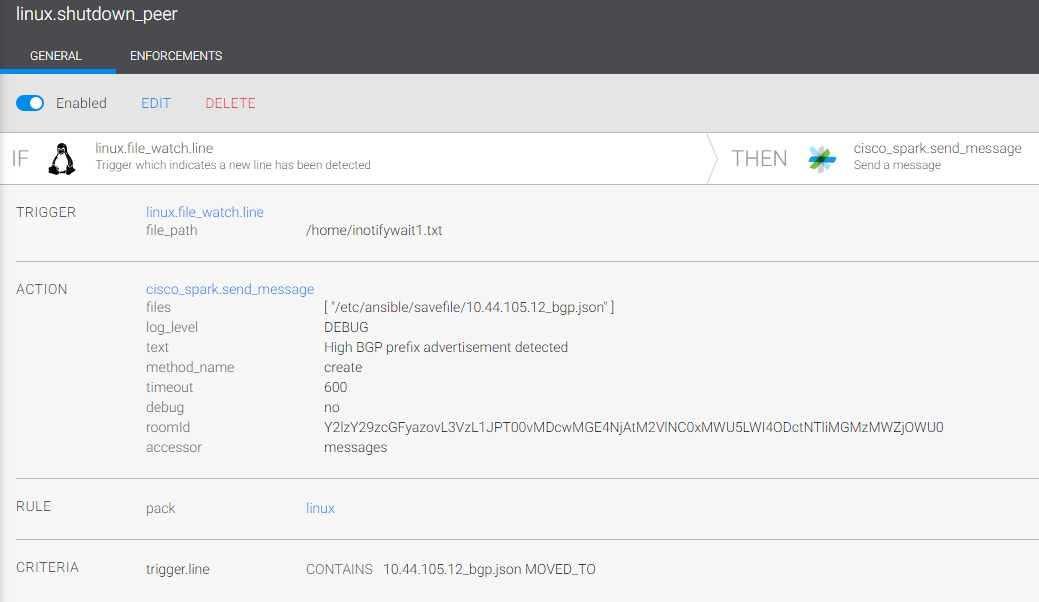
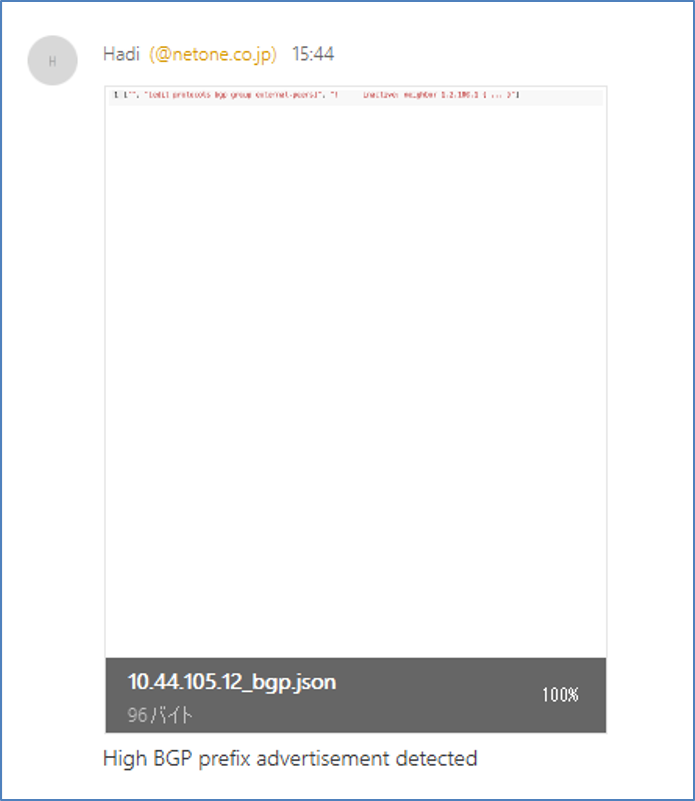
MX240 上で確認:
user@MX240-6> show system commit
0 2019-03-29 15:44:19 JST by user via netconf
1 2019-03-29 15:44:04 JST by user via cli
<snip>
user@MX240-6> show configuration protocols bgp
group external-peers {
type external;
neighbor 1.1.100.1 {
peer-as 101;
}
inactive: neighbor 1.2.100.1 {
family inet {
unicast {
accepted-prefix-limit {
maximum 100000;
}
}
}
peer-as 102;
}
}
|
以上が、機械学習の機能を使ったネットワーク内の異常検知とその対処方法に関する自動最適化シナリオの説明です。
リアルタイムネットワーク可視化に関する業界動向
Telemetry が本連載の基本コンポーネントではありますが、Janog でも取り上げられている通り、Telemetry は One of them に過ぎないことは事実です。例えば、Telemetry を使ってトラフィックのバースト性を検知できても、バーストの原因となる Flow は検知できません。そこでネットワーク業界の動きとして、例えば In-band Network Telemetry(INT)及び、 In-situ Flow Information Telemetry (iFIT) も検討されています。これらは比較的新しい技術であり、特定のデバイスでしか実装されないのが現状です。今後これらの技術でリアルタイムトラフィックの実態を正確に把握できれば、より最適な対処方法の適用が可能になります。
※ In-band Network Telemetry、In-suit Flow Information Telemetry
まとめ
ネットワークの自動最適化という点において、まだまだ課題が多いのは事実です。理由として、ネットワークの形態が複数種類存在し、同一の事象が発生したとしても、影響範囲や対処方法はネットワークの種類によって異なってくるからです。ネットワンとして、ネットワークの自動最適化を行う場合、対象となるデバイスやプロトコルの範囲を見極め、その範囲内で自動最適化を実現させた上で範囲を広げて行くアプローチが適切だと考えています。
Telemetry を使ったネットワーク自動最適化の紹介はここまでになりますが、今後は上記で挙げた課題とその解決策になり得る手法の検討及び検証を実施していきます。
関連記事
- ネットワン NFV の全貌と市場への挑戦①
- ネットワン NFV の全貌と市場への挑戦②
- NFV動向: NFVとOpenStack①
- NFV動向: NFVとOpenStack②
- NFV動向: NFVとOpenStack③
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 – 前編 –
- 仮想アプライアンスの提案で直面する致命的な課題とその対策 – 後編 –
- ネットワークが創生する価値 再考①:Hyper Scale DC Architectureとその手法
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 前編 –
- ネットワークが創生する価値 再考②:脚光を浴び始めたTelemetry とは – 後編 –
- 番外編:OSSツールで作る、Telemetry初めの一歩 – 前編 –
- 番外編:OSSツールで作る、Telemetry初めの一歩 – 後編 –
- ネットワークが創生する価値 再考③:Data Platform のビジネス利用
執筆者プロフィール
ハディ ザケル
ネットワンシステムズ株式会社 ビジネス開発本部 第1応用技術部 第1チーム
主にハイエンドルータ製品の担当として、評価・検証および様々な案件サポートに従事
現在は、SP-SDN分野、コントローラ関連、標準化動向について調査及び連携検証を実施中
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索