ビジネス推進本部 第1応用技術部
コアネットワークチーム
由原 亮太、川畑 勇貴
昨今、企業におけるMicrosoft Office365(以下O365)の採用が進むにつれて、O365を導入する場合の課題が明確になってきました。その課題の一つがO365の通信は従来の企業ネットワークでは想定されていなかった大量のセッションを張るという点です。
O365の大量セッションの影響により、企業ネットワークインフラにあるゲートウェイルータ、ファイアウォール、プロキシサーバのいずれかに負荷がかかってしまい、インターネット通信の低速化や不安定化を起こして企業業務に支障が出る可能性があります。
本コラムではこのO365通信を最適な通信経路へ変更させる自動化の検討についてご紹介致します。
O365宛て通信に対する経路制御
従来、企業のインターネット通信では支社(拠点)からデータセンタを経由し、インターネットアクセスを実現するのはよく見られる設計でした。しかしながら、この設計は支社(拠点)から大量のトラフィックがデータセンタを経由してインターネットへ抜けていくことは想定されていない場合があり、O365等の大量のトラフィックを送受信するクラウドサービスの利用には不向きであると言われるようになってきました。この課題の回避策にはいくつかの手段がありますが、最もシンプルな手段はO365宛て通信を識別し、データセンタにあるファイアウォールやプロキシサーバを経由させずに支社から直接インターネットへ抜ける通信(ローカルブレイクアウト)をさせることです。
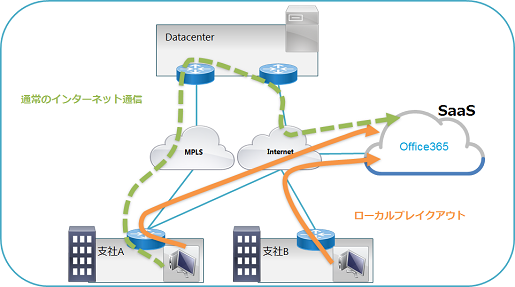
ローカルブレイクアウトは、Microsoftが公開しているXML形式のアドレスリストを基にO365通信を識別して経路を曲げ、データセンタを経由させずに支社から直接インターネットアクセスを行う事で従来よりも効率的なO365利用を実現します。
※現在はXML形式ではなく、RESTベースのリストが公開されています。
XMLのアドレスリストの中にはO365と通信する際に使用されるIPv4、IPv6、FQDNの一覧が羅列されており、こちらの情報を元にO365通信を制御するための設定をルータ等のインターネット接続機器に入れ込む必要があります。
Office365の宛先情報
提供されているアドレスリストには下記のようにサービスごとにIPv4、IPv6、FQDNの情報がまとめられています。
1.アドレスリストXMLの構造
<product name="WAC">
<addresslist type="IPv6">
...
</addresslist>
<addresslist type="IPv4">
...
</addresslist>
<addresslist type="URL">
...
</addresslist>
</product>
<product name="Sway">
...
</product>
<product name="Planner">
...
</product>
|
このままの状態でも活用することは可能ですが、アドレス形式ごとに並べ替えた方が自動化ツールなどに読み込ませる際に便利です。
そのため、今回はアドレス一覧を利用しやすい形にするためにPythonを用いて分割し、整形してみることにします。
活用しやすい形へ変換
今回は以下4つの手順にてアドレスリストの情報を変換してみます。
[手順]
1.O365アドレスリストの取得
2.O365アドレスリスト(XML)をDict型に変換
3.Dict型に変換後、パースし必要箇所を置換と抽出し配列にする
4.抽出した配列をCSVファイルとして保存する
2.今回作成したPythonソースコードの全体
import urllib
import xmltodict
import csv
import ipaddress
import pprint
def o365list(content_type):
# Office365アドレス一覧公開元URL
URL = 'https://support.content.office.net/en-us/static/O365IPAddresses.xml'
# パース結果格納用変数
results = []
# アドレス一覧の取得
url_open = urllib.request.urlopen(URL)
# xmlデータをdict形式に変換
o365_xml = url_open.read()
o365_dict = xmltodict.parse(o365_xml)
# dict形式に変換したアドレス一覧から指定した種類の情報のみを洗い出して結果をresultsに格納
if(content_type=="IPv4"):
results.append([content_type,"subnet","wildcard"])
for x in range(len(o365_dict["products"]["product"])):
for y in range(len(o365_dict["products"]["product"][x]["addresslist"])):
try:
if "address" in o365_dict["products"]["product"][x]["addresslist"][y]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"][y]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"][y]["@type"]:
ip4 = ipaddress.ip_network(o365_dict["products"]["product"][x]["addresslist"][y]["address"][z])
results.append([ip4.network_address,ip4.netmask,ip4.hostmask])
except:
if "address" in o365_dict["products"]["product"][x]["addresslist"]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"]["address"][z]])
else:
results.append([content_type])
for x in range(len(o365_dict["products"]["product"])):
for y in range(len(o365_dict["products"]["product"][x]["addresslist"])):
try:
if "address" in o365_dict["products"]["product"][x]["addresslist"][y]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"][y]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"][y]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"][y]["address"][z]])
except:
if "address" in o365_dict["products"]["product"][x]["addresslist"]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"]["address"][z]])
# 結果を返す
return results
# 絞り込んだ情報を基にCSVファイルを作成
def createcsv(filename, address_list):
with open(filename,'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(address_list)
if __name__ == "__main__":
# IPv4・IPv6・URLそれぞれの情報を取得し、ファイルへ出力
list_IPv4 = o365list('IPv4')
list_IPv6 = o365list('IPv6')
list_URL = o365list('URL')
createcsv('O365_IPv4.csv', list_IPv4 )
createcsv('O365_IPv6.csv', list_IPv6 )
createcsv('O365_URL.csv', list_URL )
|
[手順1]
O365のアドレスリストはMicrosoft社のページ<https://support.content.office.net/en-us/static/O365IPAddresses.xml>にXMLで公開されてます。PythonでO365アドレスリストのXMLを編集する為に、本コラムでは、Pythonの標準ライブラリ”urllib”を使用しています。
# Office365アドレス一覧公開元URL
URL = 'https://support.content.office.net/en-us/static/O365IPAddresses.xml'
# パース結果格納用変数
results = []
# アドレス一覧の取得
url_open = urllib.request.urlopen(URL)
|
[手順2]
XMLの中身はプロダクトの名前ごとにアドレスリスト<IPv4>、<IPv6>、<FQDN>が格納されている構造となっています。このままでは自動化作業に適さない為、XMLを辞書型へ変換しパースします。
辞書型への変換にはライブラリ”xmltodict”の”parse”メソッドを使用しています。
(”xmldtodict”は標準ライブラリではないため”pip install xmltodict”コマンドでライブラリをインストールする作業が必要です。)
# xmlデータをdict形式に変換
o365_xml = url_open.read()
o365_dict = xmltodict.parse(o365_xml)
|
XML Format
<products updated="7/11/2018">
<product name="WAC">
<addresslist type="IPv6">
<address>2603:1010:2::cb/128</address>
<address>2603:1010:200::c7/128</address>
<address>603:1020:200::682f:a0fd/128</address>
・・・
</addresslist>
<addresslist type="IPv4">
<address>13.107.6.171/32</address>
<address>13.107.140.6/32</address>
<address>52.108.0.0/14</address>
・・・
</addresslist>
<addresslist type="URL">
<address>*broadcast.officeapps.live.com</address>
<address>*excel.officeapps.live.com</address>
<address>*onenote.officeapps.live.com</address>
・・・
</addresslist>
|

Dict Format
[('products',
OrderedDict([('@updated', '7/11/2018'),
('product',
[OrderedDict([('@name', 'WAC'),
('addresslist',
[OrderedDict([('@type', 'IPv6'),
('address',
['2603:1010:2::cb/128',
'2603:1010:200::c7/128',
'2603:1020:200::682f:a0fd/128',
・・・)]),
OrderedDict([('@type', 'IPv4'),
('address',
['13.107.6.171/32',
'13.107.140.6/32',
'52.108.0.0/14',
・・・])]),
OrderedDict([('@type', 'URL'),
('address',
['*broadcast.officeapps.live.com',
'*excel.officeapps.live.com',
'*onenote.officeapps.live.com',
・・・])])])]),
・・・]
|
[手順3]
変換したディクト型の構造を元にfor文を使用し、アドレスリストの中から<IPv6>、<IPv4>、<FQDN>のみをそれぞれ抽出します。コラム後編で、Ciscoルータのコンフィグ自動化のため<IPv4>はIPアドレス、サブネット、ワイルドカードの3要素に置換しIOS-XEのACLに対応させています。変換したディクト型の階層構造には複数パターンが存在しているため例外処理で複数パターンの処理に対応させています。抽出結果は配列に返します。
# dict形式に変換したアドレス一覧から指定した種類の情報のみを洗い出して結果をresultsに格納
if(content_type=="IPv4"):
results.append([content_type,"subnet","wildcard"])
for x in range(len(o365_dict["products"]["product"])):
for y in range(len(o365_dict["products"]["product"][x]["addresslist"])):
try:
if "address" in o365_dict["products"]["product"][x]["addresslist"][y]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"][y]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"][y]["@type"]:
ip4 = ipaddress.ip_network(o365_dict["products"]["product"][x]["addresslist"][y]["address"][z])
results.append([ip4.network_address,ip4.netmask,ip4.hostmask])
except:
if "address" in o365_dict["products"]["product"][x]["addresslist"]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"]["address"][z]])
else:
results.append([content_type])
for x in range(len(o365_dict["products"]["product"])):
for y in range(len(o365_dict["products"]["product"][x]["addresslist"])):
try:
if "address" in o365_dict["products"]["product"][x]["addresslist"][y]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"][y]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"][y]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"][y]["address"][z]])
except:
if "address" in o365_dict["products"]["product"][x]["addresslist"]:
for z in range(len(o365_dict["products"]["product"][x]["addresslist"]["address"])):
if content_type in o365_dict["products"]["product"][x]["addresslist"]["@type"]:
results.append([o365_dict["products"]["product"][x]["addresslist"]["address"][z]])
|
[手順4]
配列にした抽出結果をCSVファイルとして保存します。
# 絞り込んだ情報を基にCSVファイルを作成
def createcsv(filename, address_list):
with open(filename,'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(address_list)
|
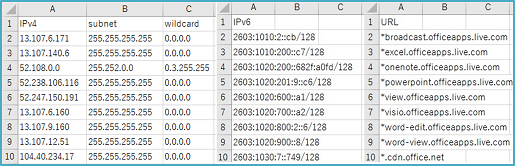
上記のように形式毎に分割されたアドレスリスト一覧をCSVファイル化することができます。今回は種類によってCSVファイルが3つ作成されるようにしています。
今回のまとめ
変換されたDict型の構造を見抜くのに手間取りましたが、Pythonを使って必要なアドレス情報を抽出し、CSVファイル化することができました。CSV化することによってAnsibleやChefといった、昨今トレンドとなってきている構成管理ツール等で容易に活用することが可能になります。
本連載の後編では、CSV化したファイルから実際にルータへの設定を自動化させるためのツールや手法について紹介したいと思います。これによりO365通信のローカルブレイクアウトを自動化させる事が可能になります。
執筆者プロフィール
由原 亮太
ネットワンシステムズ株式会社 ビジネス推進本部
第1応用技術部 コアネットワークチーム
所属
新卒入社で応用技術部に配属されてから今日までCisco社ルータ製品(ISR/ASR1000シリーズ)の担当として、評価・検証および様々な案件サポートに従事。
ネットワークの可能性を広げるためにプログラミングスキルを活かして奮闘中。
川畑 勇貴
ネットワンシステムズ株式会社 ビジネス推進本部
第1応用技術部 コアネットワークチーム
所属
ネットワンシステムズに入社し、Ciscoミドルエンド・ローエンドルータ製品を担当。
ネットワークに関わる先進テクノロジーの調査、研究に従事している。
執筆者プロフィールに「・CCIE」と載せるべく日々研鑽中。
ナレッジセンターを検索する