- ナレッジセンター
- 匠コラム
ネットワン × AI -機械学習の取り組みを通じて見えてきたこととは?-
- 匠コラム
- データ利活用
- AI
ビジネス推進本部 応用技術部
クラウドデータインフラチーム
片野 祐
最近、”AI”という言葉を聞かない日がないくらい、この分野は盛り上がりを見せています。本コラムでは、ネットワンが機械学習の取り組みを始め、実際に手を動かしてみて実感したことや考慮すべきポイント等をお伝えします。
| 連載インデックス |
|---|
はじめに
ネットワンといえば “ネットワークの会社” というイメージが数年前までありましたが、ここ数年はプラットフォーム分野にも力を入れており、最近ではサービス事業に関しても取り組みを始めています。特にここ最近では新しい分野への取り組みも加速させており、ネットワークはネットワークでも、 “ニューラルネットワーク” のようなAIの分野の活動も開始しています。第三次AIブームと呼ばれる現在、AIという言葉を聞かない日がないくらいAIは多くの方に注目されている分野と言えるのではないでしょうか。この匠コラムでは、ネットワンが始めた新たな取り組みについて、ご紹介いたします。
ネットワンが取り組んでいる分野は、実際にはニューラルネットワークに絞らずAI(人工知能)全般についてであり、機械学習を用いたデータ分析や異常検知等にチャレンジしています。このような新しい分野へのチャレンジを始め、実際のデータを使ってデータ分析を行ってみたからこそ、身に染みてわかったことをこの匠コラムでは共有したいと思います。
人工知能、機械学習、深層学習の関係性
「はじめに」で書いたようなニューラルネットワークを始め、この分野では少なからず専門用語が出てきますが、出来るだけ専門用語を使わずに説明したいと思います。まずはここまでにも出てきた言葉ですが、 “AI” という言葉が指す範囲についてです。一般に “AI” とは、人工知能全般を指している言葉であり、細分化すると人工知能(AI)、機械学習(Machine Learning)、深層学習(Deep Learning)になると言われています。
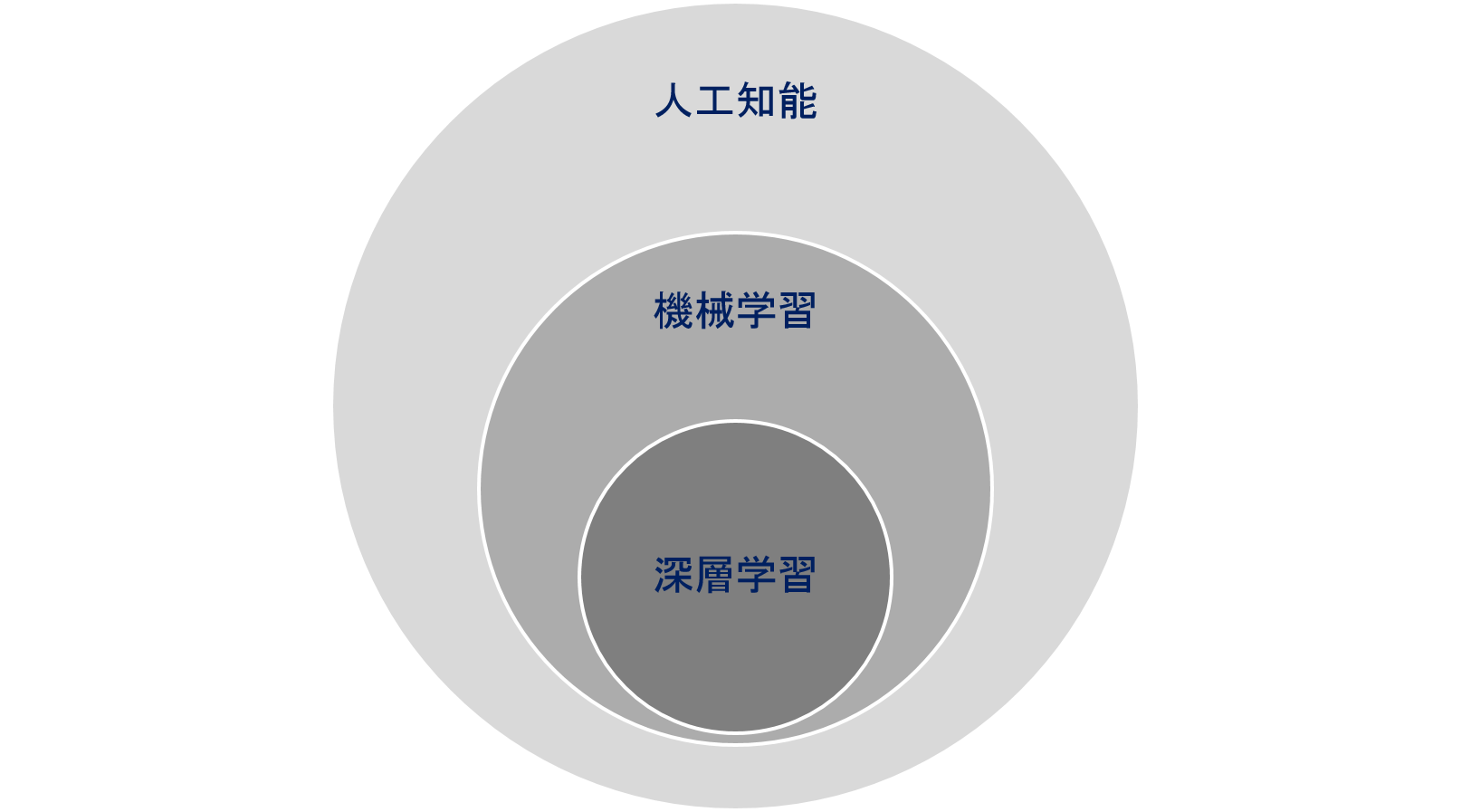
これらの関係を図で表すと図1のようになり、深層学習は機械学習の一部であり、機械学習は人工知能の一部であると言えます。例えば画像分類を例に取ってみると、機械学習では「色を特徴として判別する」や「形を特徴として判別する」というように人間が特徴を定義する必要があるのに対し、深層学習ではAIが学習データから自身で判別のための特徴を抽出してくれるといった違いがあります。一般に “AI” と言う場合、機械学習も深層学習も広く含まれているため、実際には機械学習なのか、深層学習なのか、実はそこまで達していないものなのか、注意する必要があります。実際、AIを使っていると謳っている製品やサービスの中にも、実際には決まった言葉にのみ反応できるチャットボットのようなものが含まれていることも、まだまだ多くあります。特にAIを使おうと思っている立場の方は、人工知能、機械学習、深層学習の関係性を正しく理解し、検討しているAIがどこに属するものなのか、できることは何なのかを見極めることも現在の第三次AIブームに乗っていくために必要なスキルと言えるでしょう。
ここからはネットワンが直面した経験をもとに、AIを検討する上で考えるべきポイントを以下の3つに絞り、それぞれについて考えていきます。
- AIは何でも解決できる?
- 計算結果のみ見れば良い?
- 計算に必要なデータはどこに貯まっている?
ポイント① -AIは何でも解決できる?-
AIを正しく理解していないと、期待した成果を得ることは難しいです。「とりあえずAIが流行っているから、やってみよう」、「なんとなく機械学習に使えそうなデータがあるから、ちょっとやってみよう」という始め方は、期待した結果を出せない、失敗しやすい例です。自分たちが現状困っていること、解決したい課題をしっかりと見定めた上で、その課題解決の手段として機械学習や深層学習の利用を検討しないと、満足な結果が得られないことがあります。また、あくまで機械学習や深層学習は使用するデータから結果を導き出すものなので、十分な量、質のデータがない場合や、適切なアルゴリズムが使われていない場合も満足のいく結果を導き出すことはできません。つまり、AIを使い始めたからといって突然有効な結果が出ることはなく、課題解決までのプロセスの検討やデータの収集、データのクレンジング等、しっかりとした下準備が必要になります。一般に機械学習を行う際の8割はこの下準備にかかるとも言われています。
ポイント② -計算結果のみ見れば良い?-
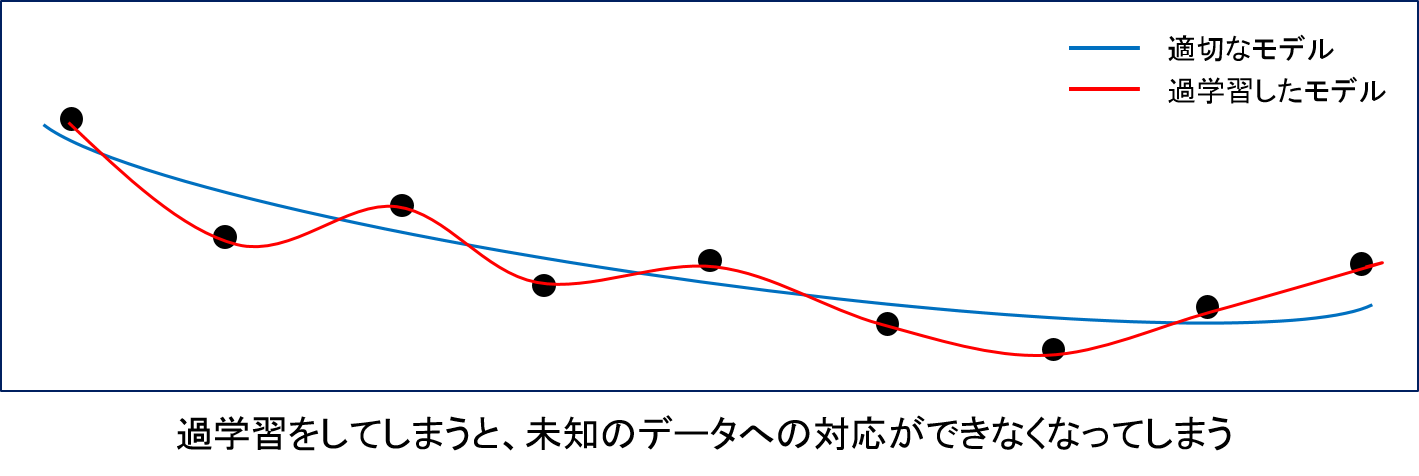
例えば機械学習によって、何かの製品を作る製造過程にセンサー等を設置し、そのセンサーデータの収集を行い、それらのデータから出来上がる製品が結果的に良品なのか不良品なのか予測することを考えてみます。このとき、データの前処理(欠損値の保管や新たな変数の生成)を行ったあと、良品と不良品を予測するためのモデルを作成します。このモデルに対して、新しく製品を製造した際のデータを適用し、良品か不良品の予測をしてみると、案外簡単に予測結果が出ます。しかし、この結果を見る際にも注意しなければならない点がいくつかあります。例えば、過学習と呼ばれるような、モデルを作る際に使ったデータの特徴を捉えすぎてしまい、新しいデータに対して適さないモデルになっていないかを注意する必要があります。モデルの構築に時間をかけ、細かく計算すればモデルの予測精度を上げることができますが、新しいデータに対応できなくなってしまうのでは意味がありません。この過学習は、機械学習のパラメータをうまく設定することで、回避することができます。
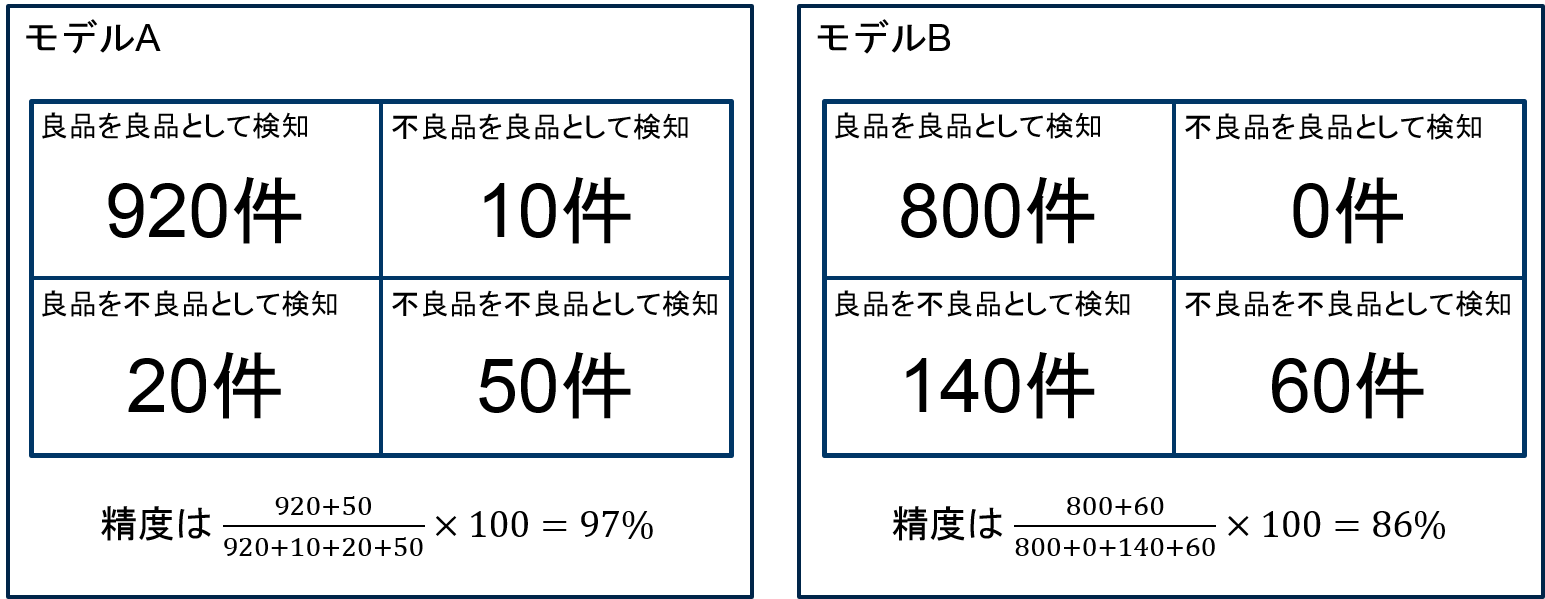
また、ただ予測精度を上げれば良いというものでもなく、正しく判定してほしいことが判定されているかを見ることも重要です。良品と不良品を予測したい場合、その多くは不良品を事前に見つけることが目的になると考えられます。モデルを作ったあとはチューニングを行い、モデルを改良していきますが、モデルを改良したら判定の精度は上がったが、実はすべて良品と判定していた、という結果ではまったく意味がありません。モデルを作る段階で全体的な予測精度だけでなく、本当は良品なのに不良品と予測されたものはいくつあるのか、本当は不良品なのに良品と予測されているものはいくつあるのか等、単純に精度と呼ばれる数値だけでなく、本来の目的(解決したい課題)を忘れずに結果を見ることも重要になります。
ポイント③ -計算に必要なデータはどこに貯まっている?-
ここ最近のAIに関する話は、モデル作成に必要な良質なデータが既に何らかの場所に貯まっている前提から始まることが多いです。AIによってできることに目が行きがちですが、実際には必要なデータを貯められていない場合や、適切に貯められていない場合が多いのが現状です。ただデータを貯めるのではなく、データが欠損していないか、得たい結果を得るために必要な時間間隔でデータを収集できているか、どれだけ過去のデータまで保管しておく必要があるか等、データの量や質も考慮する必要があります。IoTデバイスの普及からデータの供給源が増えている今、それらのデータをどのように貯めるかを考え直す時期に来ていると思います。加えてそのデータを、分析を行うところにどのように持ってくるのかというネットワーク側を考える必要や、分析を行うにあたりGPUが必要なのか等、処理性能について考える必要も出てきます。AIを用いて何を行うか想像を膨らませる前に、分析を行う基盤(ストレージ、ネットワーク、サーバ)を見直すことも重要なことの一つです。データさえ貯まっていれば、機械学習を行う前段階として、データの可視化やBIツールを用いた簡単な分析ができるようになるため、まずはデータを貯める部分を考えてみても良いかもしれません。
おわりに
ネットワンはセンサー等から収集されるデータの分析業務や機械学習を用いた異常検知、ネットワークの自律化等に取り組み始めており、新たな分野へのチャレンジを進めています。AIが使われるのが当たり前になる世の中が来る前に、AIに対する理解を進め、データを貯めるためのネットワークや基盤に目を向けることは重要なことではないでしょうか。インターネット黎明期から様々なネットワークを作ってきたネットワンが持っているノウハウと、新たなチャレンジによって得られる知見が、お客様の課題解決の手助けになればと思います。
機械学習はプログラミングが必要だと思われる方もいるかと思いますが、最近ではプログラムを書かずにGUIのみで機械学習ができるツールもいくつか存在します。次回コラムでは、それらのツールを使って、機械学習を行う際は実際にどのようなことを行うのか、見ていこうと思います。
執筆者プロフィール
片野 祐
ネットワンシステムズ株式会社 ビジネス推進本部
応用技術部 クラウドデータインフラチーム
所属
ネットワンシステムズに新卒入社し、仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の推進やデータプラットフォーム製品の技術検証、データ分析に従事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索