- ナレッジセンター
- 匠コラム
仮想アプライアンスの提案で直面する致命的な課題とその対策 (DPDKに代表されるネットワークパフォーマンス改善手法)- 前編 -
- 匠コラム
- 効率化・最適化
- ネットワーク
ビジネス推進本部 応用技術部 コアネットワークチーム
井上 勝晴
2013年にETSI NFV ISGによりNFVの全体像を形作るGroup Specificationが公開されてから
3年が経過し、「NFV」という単語を当たり前のように耳にするようになりました。
弊社ネットワンシステムズはNFV PoC(Proof-of-Concept)を自社ラボに構築し、「可用性、運用保守性、柔軟性」をKeywordとした幾つかの実証試験を行いました。(ネットワン NFV の全貌と市場への挑戦②)
このような活動の中、複数のお客様より、NFVが汎用x86サーバー上で提供されるが故のパフォーマンス面への懸念点を多く頂戴しました。そのような背景もあり、NFV環境におけるパフォーマンス課題とその解決方法について、実環境である弊社PoCを用いて実証実験を行いましたので、その結果を本コラムにて前編・後編に分けてご紹介したいと思います。(前編)
| 連載インデックス |
|---|
NFVの性能課題
先ずは実際のNFV性能課題を確認すべく、実機を用いたパフォーマンス計測を行いました。
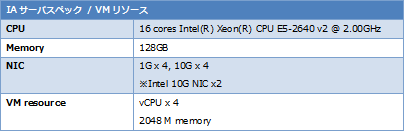
パフォーマンス測定は、下図にあるようなVLANでネットワークを構成した一般的なOpenstack環境にて計測しています。
(Compute nodeに対し試験機より20Gbps双方向のトラッフィックを印可し計測)
試験は「OVS折り返し」と「VM折り返し」の2パターンにて、それぞれ計測しています。
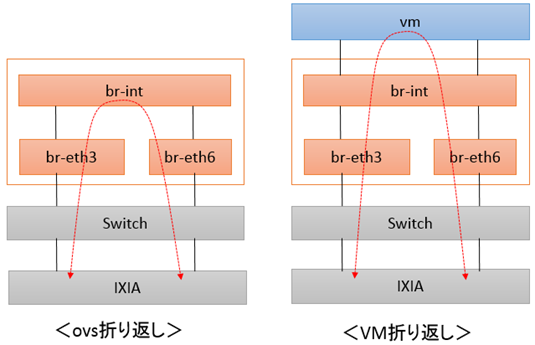
OVS折り返しパターンの試験結果は以下となりました。
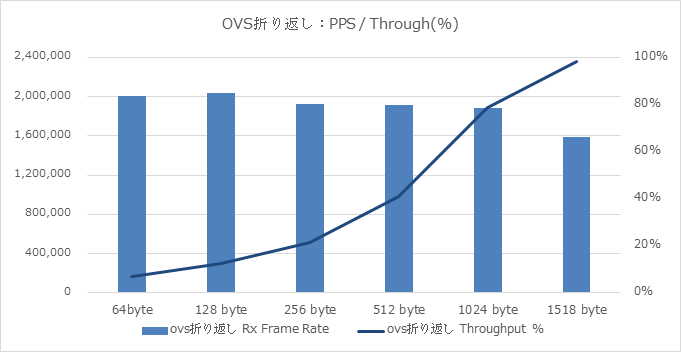
上記グラフは、20 Gbps双方向印可時の達成率(Throughput)とFrame rate(pps)のデータとなります。
印可Packetが1518Byte長で若干ラインレートに届かない程度、512Byte長では約40%程度、64Byte長では約7%程度のスループットであり、傾向としては、
- Short Packetの性能劣化が顕著に発生
- 200万 pps 程度で頭打ち
と言う結果でありました。
続いてVM折り返しパターンの試験結果を記載します。
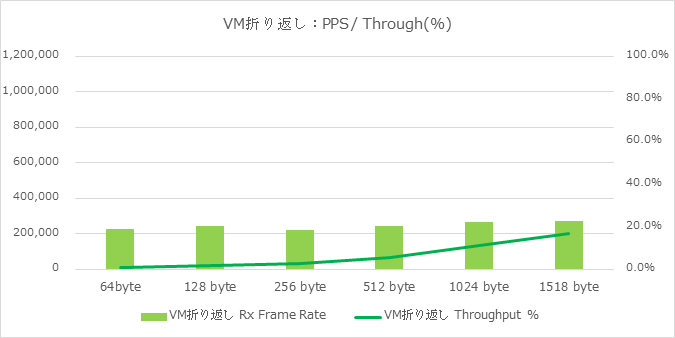
先程と同様に、20 Gbps双方向印可時の達成率(Throughput)とFrame rate(pps)のデータとなります。
このVM折り返しパターンでは、1518Bye長のようなLong Packet印可時においても大幅な性能低下が確認されており(1518Byte長にて約17%)、傾向としては、
- Long Packet印可時においても大幅な性能低下
- およそ20万pps強で性能が頭打ち
と言う結果でありました。
下記は、「OVS折り返し」と「VM折り返し」の試験結果を纏めたデータとなります。
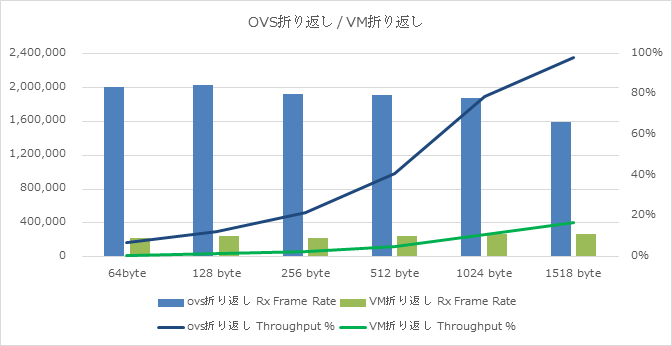
このグラフから、
- 性能劣化の大部分がVMにて(VMを跨ぐ箇所にて)発生している
- NFVのような同一NFVIに複数VMが動作する環境や、East-west通信と呼ばれるVM-VM間通信が多い環境では、OVS側の性能も課題に成り得る
という2点の課題が見えてきました。NFVを進めいていく上では重要な課題であると言えます。
x86 architecture / 仮想環境:Packet処理ボトルネックポイント
ではここで改めて、x86汎用サーバー及び仮想化環境における、Packet処理のボトルネックポイントについて整理したいと思います。
下図は汎用サーバー上に展開された一般的な仮想環境となります。
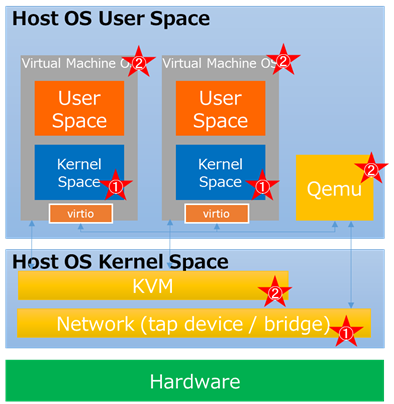
Hardwareの上にHost OSが展開され、そのHost OSはKernel spaceとUser Spaceを其々保持しています。仮想化レイヤに相当するKVMはKernel Spaceに存在し、VMに対するDeviceエミュレーション機能を持つqemuは、Host OSの1アプリケーションとして動作しますので、Host OSのUser Spaceに展開されます。
そして、この仮想化レイヤ上にGuest OSであるVirtual Machineが展開され、このVirtual Machineも同様に、Kernel spaceとUser Spaceを其々保持する事となります。
この様な一般的な仮想化環境において、Packet転送処理のボトルネックポイントが幾つか存在します。
1つ目のボトルネックポイントとしては、Kernel Space内のNetwork Switchとなります。
Linuxに代表される汎用OSはネットワーク処理専用に開発された物では無く、様々な要因で割り込み処理が発生するため、kernelが提供するネットワーク機能はPacket転送処理におけるボトルネックと成り得ます。(上図:★①)
2つ目のボトルネックポイントとしては、仮想化レイヤとなります。
Virtual Machine管理の負荷、つまり仮想化レイヤその物の負荷も、Packet転送処理に対するボトルネックになり得ます。(上図:★②)
これまでVirtioによるqemuとゲストOS間での改善や、vhostによるゲストOSとホストカーネル間でのダイレクトパスによる改善もありましたが(下図:vhost)、まだまだ性能的には不十分である事が、前述の試験結果からも解ると思います。
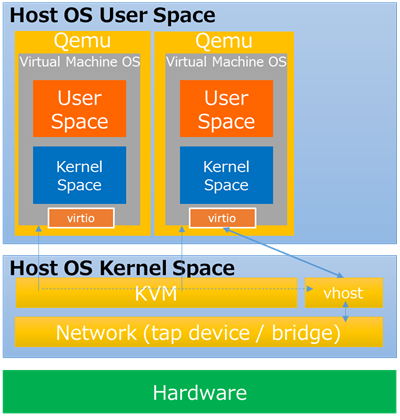
このように、NFVの様な仮想化環境においては、複数個所にボトルネックが存在し、それらへの対処が必要となります。
技術論:スループット向上手法
このようなボトルネック問題に対し、複数の方策が提供されています。
DPDK(Data Plane Development Kit)
DPDKはPacketの高速処理を目的とした、複数ドライバと複数ライブラリより構成されています。Kernel Space上で動作していたネットワーク処理機能を、User Space上の1つのアプリケーションとして動作させ、Kernel space上のネットワーク処理のボトルネックを解消するアプローチになります。
PCI Pass Through with SR-IOV(Single Root I/O Virtualization)
PCI Pass Throughは、VMがホスト側のPCI Deviceに直接アクセスする事を可能とする技術であり、仮想レイヤをBypassしてDeviceを直接制御するため細かな制御も可能となり、Nativeに近いパフォーマンスが可能になる技術です。これにSR-IOV併用する事でPCIデバイス側での仮想化により、1つの物理ポートを複数の仮想ポートに分割する事が出来るようになります。
vhost-User
DPDKをOVSに適用させると、VMからのトラッフィックには、OVSがHost kernelとVMの間に介在する事になり、煩雑なContext switchが存在してしまいます。これは転送性能の低下につながります。vhost-Userはこの動作を解決するために考案された手法です。
後編ではご紹介致しましたこれらスループット向上手法について詳細をご説明致します。
関連記事
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索