- ナレッジセンター
- 匠コラム
キャリアエッジルータの最新ラインカードとその特徴(前半)
- 匠コラム
- ネットワーク
ビジネス推進本部 第1応用技術部
コアネットワークチーム
渡部 満幸
2015年に入り、Cisco、Juniper、Alcatel各社の大型ルータで、高密度100GEポートを搭載したラインカードのリリースが相次いでいます。
これらのラインカードを実現するために搭載されている各社のNPU(Network Processing Unit)の特徴をご紹介します。
第1回目は各社最新ラインカードの性能をまとめました。
| 連載インデックス |
|---|
免責事項
本コラムでは各メーカが公表した2015年5月現在のデータを使用しています。
記載するスループット等はHalf-duplexであり、例えば100Gbpsと記載している場合はInput 50Gbps + Output 50Gbps の合計値を意味します。
記載する数値は最も条件の良い場合の値であり、実運用時のパフォーマンスを保証するものではありません。
参考情報としてご利用ください。
メーカ公証値との差異がある場合、正確性の観点からメーカ公証値をご利用ください。
キャリアエッジルータについて
本文で指すキャリアエッジルータとは、サービスプロバイダエッジ(PE)やデータセンタコア、ラージエンタープライズコア(CE)等、比較的大規模なネットワークが外部と接続するための境界(エッジ)に配置される高機能ルータです。
例えば、Cisco ASR9000シリーズ、Juniper MXシリーズ、Alcatel-Lucent SRシリーズです。
これらを指してMulti Service Edge(MSE)ルータ、あるいはEthernetの集約が主流になりつつあるため、Ethernet Service Edge(ESE)ルータ等と呼ぶ場合もあります。
Cisco CRSシリーズやNCSシリーズ、Juniper PTXシリーズ、Alcatel-Lucent XRSシリーズについては、本文では便宜上コアルータとして分類します。
エッジルータには大容量、多機能、高性能の3点が求められます。
| 大容量 | 高速インタフェースを多数収容でき、1台当たり100Gbps~数Tbpsの転送能力を有する |
|---|---|
| 多機能 | Ethernet/ATM/POS等の多様なインタフェース Layer 2 Ethernet VPN(VPLSやVPWS) IPv4/v6 VPN(MPLS) Unicast/Multicast VPN(MPLS) BGP/OSPF/ISIS/RIP/LDP/RSVP/PIM/IGMP/MLD等の各種制御プロトコル |
| 高性能 | 数百万単位のルーティングテーブルを保持 数百万単位のMACアドレステーブルを保持 数万単位のパケットフィルタリングテーブルを保持 数万単位のQoSポリシー、キューを保持 数千単位のVPNインスタンス(VRF等)を保持 |
これらの高い要求を満たす必要があるため、スイッチ製品と比べて高価で、ポート密度も低くなる傾向があります。
Network Processing Unit : NPU
NPUはエッジルータのパケットやフレーム転送処理を担う中核チップです。
近年では、この部品の性能がそのネットワーク機器の性能限界を決定する重要なものになっています。
NPUは今回紹介するCisco/Juniper/Alcatel-Lucentの各社共通で、パケットバッファ、フォワーディングテーブル(Forwarding Information Base:*FIB)、フォワーディングチップ、ファブリックアクセスチップで構成されています。
| パケットバッファ | 一時的にパケットを貯留するためのメモリ。 QoSバッファとしても利用されます。 このメモリの容量が、設定可能なQoSクラスの最大数等を決定します。 |
|---|---|
| フォワーディングテーブル | パケットの転送先を最適化して保持する高速なI/O性能を持つメモリ。 MACアドレステーブルやパケットの転送先ネクストホップ等を格納。 このテーブルのサイズが、実質的に収容可能な最大経路数の上限値を決定します。 ルックアップメモリとも呼ばれます。 エッジルータではこの部分にRAMを使用するアーキテクチャが主流です。 スイッチ製品ではTCAMが使われます。 |
| フォワーディングチップ | パケットの転送処理を実行するチップ。 パケットヘッダを読み取り、フォワーディングテーブルを走査してパケットを適切な宛先へ送り出す処理を行う。 パケットデータを必要に応じてパケットバッファにコピーし、TTL減算やヘッダの変更等、転送に必要な書き換え処理も実行する。 このチップの処理能力が、実質的に転送能力(スループット)の上限値を決定します。 高性能なCPUといえます。 |
| ファブリックアクセスチップ | フォワーディングチップとファブリックを接続する転送チップ。 ファブリックとはラインカード同士をルータのシャーシ内で相互に接続している転送用の回路を指します。 大抵の場合、ファブリックアクセスチップはフォワーディングチップの性能より転送容量が大きく、この部分がボトルネックになることはほとんどありません。 しかし、ファブリックカードの冗長(シャーシに2つ以上搭載)を前提としたラインカード性能の場合、シングルファブリック時はラインカードの性能を十分発揮できないケースもあります。 |
この他にもVLANタグの識別やパケットフィルタリング、QoSの分類等に使用するためのTCAM(Ternary Content Addressable Memory)を包含している場合もあります。
スイッチ製品ではフォワーディングテーブルの格納先としてTCAMを使用しているものもあります。
TCAMはハードウェア回路として、ルックアップメモリとは違いCPU1サイクルで探索を完了するといった非常に高速なルックアップ性能を提供し、容量が少なければ比較的安価に製造することが可能である一方、格納可能なテーブルの形式や容量、使い方に制限があることや、ハードウェア自体の開発コストも非常に高くなる傾向があります。
また、大容量化するためには回路(TCAMセル)自体を単純に追加し、大規模化する必要があります。これは消費電力の増大や、物理的な大きさ、価格の大幅な上昇、開発コストの上昇といったデメリットを伴います。
そのため、エッジルータのように、大規模なテーブルを保持し、多様な使い方が想定されるルックアップメモリとして使用するには、TCAMは向いていません。
エッジルータではTCAMの使用は最低限に抑え、フォワーディングメモリには大容量のRAM、フォワーディングエンジンには非常に高速なCPUを使用し、CPUパワーでゴリ押しする実装が主流です。
特に、高速なI/Oが可能なRLDRAMで実装されるのが一般的です。
Cisco Live BRKSPG-2772
Internet Week 2011 S8 Part 2
https://www.nic.ad.jp/ja/materials/iw/2011/proceedings/s08/s08-03.pdf
このような事情もあり、エッジルータのラインカードはスイッチ製品とは比べ物にならないほど大きなテーブルを保持しながら大容量のパケット転送が可能であり、価格も非常に高価になっています。
*FIB : 本文ではRouting Information Base(RIB)/ルーティングテーブルとは区別し、別のものとして扱います。
それでは次の項から各社のラインカードの具体的な性能を紹介していきます。
Cisco ASR9000シリーズラインカード
この項ではCiscoプライベートセミナーであるCisco Liveの資料及びメーカ公式サイトの情報等をもとに、ASR9000シリーズラインカードを紹介していきます。
ASR9000シリーズラインカードでは、NPUは以下のコンポーネントから構成されています。
下図はTomahawk 8X100GEの一部抜粋です。
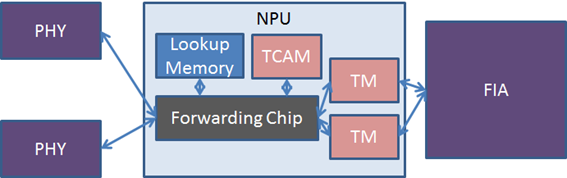
Tomahawk NPUでは各コンポーネントに特別な呼称は無いようで、構成コンポーネントが役割に応じた名称で列記されています。
| PHY | 物理的にインタフェースを意味しています |
|---|---|
| Lookup Memory | FIBやMACテーブル、Adjacency(CEF)情報を格納しています |
| Forwarding Chip | 転送処理を行います |
| TCAM | パケットフィルタやQoS分類、VLANタグ識別等の分類を行います |
| TM | トラフィックマネージャ
パケットバッファやQueueing、Shaping等のQoS処理を行います |
| FIA | ファブリックインターコネクト |
ASR9000シリーズのラインカードはNPU別に大きく3種類の系列が存在します。
| 第1世代 Trident NPU ラインカード Ethernet Line card -販売終了- |
A9K-40GE-E/B/L A9K-2T20GE-XX A9K-4T-XX A9K-8T-XX A9K-16/8T-XX |
| 第2世代 Typhoon NPU ラインカード Enhanced Ethernet Line card (Carrier Ethernet Line card) MOD80 = 2 x Typhoon MOD160 = 4 x Typhoon 24X10GE = 8 x Typhoon 36X10GE = 6 x Typhoon 1X100GE = 2 x Typhoon 2X100GE = 4 x Typhoon ASR9001 = 2 x Typhoon |
A9K-MOD80-XX A9K-MOD160-XX A9K-24X10GE-XX A9K-36X10GE-XX A9K-40GE-TR/SE A9K-4T16GE-XX A9K-1X100GE-XX A9K-2X100GE-XX ASR-9001(-S) |
| 第3世代 Tomahawk NPU ラインカード High Density Carrier Ethernet Line card 8X100GE = 4 x Tomahawk |
A9K-8X100G-LB-XX |
表中の-XXはQoS関連機能の拡張性を意味する TR(Transport Optimized) あるいは SE(Service-edge Optimized)等が入ります。
各ラインカードの比較
| Typhoon NPU | Tomahawk NPU | |||
|---|---|---|---|---|
| -TR | -SE | -TR | -SE | |
| 転送性能 | 120Gbps/NPU N/A pps/NPU |
120Gbps/NPU N/A pps/NPU |
480Gbps/NPU N/A pps/NPU |
480Gbps/NPU N/A pps/NPU |
| 最大FIB容量 | 4M(IPv4+v6) | 4M(IPv4+v6) | 4M(IPv4)+2M(IPv6) (10M IPv4 / 5M IPv6 Future) |
4M(IPv4)+2M(IPv6) (10M IPv4 / 5M IPv6 Future) |
| 最大MACテーブル容量 | 2M | 2M | 2M (6M Future) |
2M (6M Future) |
| QoS | 8 queue/port | 256k queue/NPU | 8 queue/port | 1M queue/NPU |
Juniper MXシリーズラインカード
この項では O’REILY Juniper MX Series(書籍)及びメーカ公式サイトの資料等をもとに、MXシリーズラインカードを紹介していきます。
Juniperでは、NPUをPFE(Packet Forwarding Engine)と呼びます。
PFEは以下のコンポーネントから構成されています。
下図はMPC3E Cassis PFEの例です。
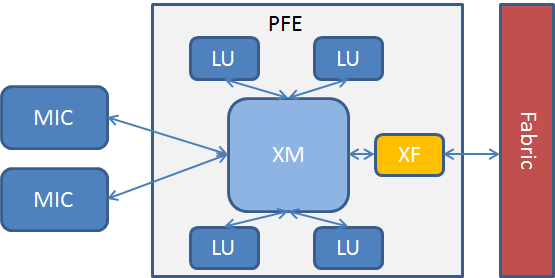
CassisではXM、XF 及び複数のLUチップを組み合わせています。
| XM | QoS分類やパケットバッファ |
|---|---|
| XF | ファブリックインターコネクト |
| LU | ルックアップメモリ及びパケット転送処理 |
MXシリーズのラインカードはPFE別で大きく2種類の系統がリリースされています。
| Trioラインカード MPC1 = 1 x Trio PFE MPC2 = 2 x Trio PFE MPC2-NG = 2 x NG-Trio PFE MX80 = 1 x Trio PFE |
MX-MPC1-3D(-**) MX-MPC1E-3D(-**) MX-MPC2-3D(-**) MX-MPC2E-3D(-**) MPC2E-3D-NG(-Q) MPC-3D-16XGE-SFPP CHAS-MX80-S CHAS-MX80-48T-S CHAS-MX5-T-S CHAS-MX10-T-S CHAS-MX40-T-S CHAS-MX80-T-S |
| Cassisラインカード MPC3 = 1 x Cassis PFE MPC4 = 2 x Cassis PFE MPC5 = 2 x Cassis PFE |
MX-MPC3E-3D MPC3E-3D-NG(-Q) MPC4E-3D-32XGE-SFPP MPC4E-3D-2CGE-8XGE MPC5E-3D-2CGE+4XGE(-**) MPC5E-3D-24XGE+6XLGE(-**) |
表中の**にはQoS性能やRouting Table上限等の性能を示すQ、EQ、X、L等が入ります。
MPC**とMPC**Eの違いはサポートする機能の違いであり、純粋なPFEパワーはほぼ同じです。
NG-PFEシリーズはルックアップメモリの増加、PFEパワーの強化が行われています。
これにより合計スループット(bps)は変更されないものの、転送能力(pps)が向上すると考えられます。
各ラインカードの比較
| Trio PFE | Cassis PFE | |
|---|---|---|
| 転送性能 | 80Gbps/PFE N/A pps/PFE |
260Gbps/PFE N/A pps/PFE |
| 最大FIB容量 | 5M(IPv4) or 5M(IPv6) | 5M(IPv4) or 5M(IPv6) |
| 最大MACテーブル容量 | 1M | 2M (6M Future) |
| QoS | 8 queue/port or 512k queue/LC (Dense Queueing Blockの容量に依存) |
8 queue/port or 512k queue/LC (Dense Queueing Blockの容量に依存) |
| NG-Trio PFE | |
|---|---|
| 転送性能 | 80Gbps/PFE N/A pps/PFE |
| 最大FIB容量 | 10M(IPv4) or 10M(IPv6) |
| 最大MACテーブル容量 | N/A |
| QoS | 8 queue/port or 512k queue/LC (Dense Queueing Blockの容量に依存) |
Alcatel-Lucent SRシリーズラインカード
この項では Alcatel-Lucentのプライベートセミナーである SReXpertsで紹介された資料及びメーカ公表データシートをもとに、SRシリーズラインカードを紹介していきます。
SRシリーズラインカードでは、NPUは以下のコンポーネントから構成されています。
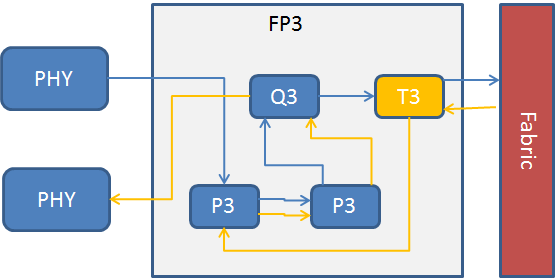
FP3はQ3、T3及び2つのP3 チップを組み合わせています。
| Q3 | QoS機能
Queueingやパケットバッファ |
|---|---|
| T3 | ファブリックインターコネクト |
| P3 | ルックアップメモリ及びパケット転送処理 |
SRシリーズのラインカードはNPU別に大きく2種類の系統がリリースされています。
| FP2 ラインカード IOM3-XP = 1 x FP2 IMM = 1 x FP2 |
IOM3-XP (Modular) IOM3-XP-B/C (Modular) IMM (Fixed) 48 x GE(SFP or Copper) 4 x 10GE(XFP) 5 x 10GE(XFP) 8 x 10GE(XFP) 1 x 40GE(Fixed) 1 x OC768(Fixed) |
| FP2 改良型ラインカード IMM = 2 x FP2+ |
IMM (Fixed) 12 x 10GE(SFP+) 3 x 40GE(QXFP) 1 x 100GE(CFP) |
| FP3 ラインカード IMM = 1 x FP3 |
IMM (Fixed) 2 x 100GE(CFP) |
各ラインカードの比較
| FP2 | FP2+ (改良型) | FP3 | |
|---|---|---|---|
| 転送性能 | 100Gbps/FP2 N/A pps/FP2 |
200Gbps/FP2+ N/A pps/FP2+ |
400Gbps/FP3 N/A pps/FP3 |
| 最大FIB容量 | 3M(IPv4+IPv6) | 3M(IPv4+IPv6) | 5M(IPv4+IPv6) |
| 最大MACテーブル容量 | 2M | 2M | 4M |
| QoS | 64k queue/Port | 64k queue/Port | 128k queue/Port |
まとめ
ここまでの前半では、Cisco、Juniper、Alcatel-Lucent各社の単純なスペックだけを列挙しました。
チップの性能公証値だけを比べれば、大きな差分は無いように見えます。
しかし、各社のハードウェア・ソフトウェアの実装は異なっており、ルータの設定や使い方によって性能に差が出てきます。
次回の後半では、具体的にどのような場合に性能差が出てくるのかをご紹介できればと思います(予定です)。
執筆者プロフィール
渡部 満幸
ネットワンシステムズ株式会社 ビジネス推進本部 第1応用技術部 コアネットワークチーム
所属
入社以来約10年以上、応用技術部でルータ製品の調査及び研究を行い、その結果をもってお客様への提案支援やネットワーク設計、障害解析等の支援を行う。
Cisco製品ではローエンドからハイエンド、キャリアグレードルータまで、Juniper/Alcatel製品では主にエッジルータを評価している。
Ethernet/IP/MPLS/PPP(oX)等、ルータ製品で動作するプロトコル全般を調査対象としている器用貧乏型
Webからのお問い合わせはこちらから
ナレッジセンターを検索する
カテゴリーで検索
タグで検索