
- ライター:根本 幸訓
- イノベーション推進部で新しい技術領域のビジネス開発(GX、ロボティクス)を担当。
2011年、ネットワン新卒入社。事業部SE(文教市場、自治体)、応用技術部(サービス開発)を経て、現在に至る。
ネットワーク、セキュリティ、サーバ、ストレージ、仮想デスクトップなどの幅広い技術知識と、提案、設計、構築、サービス開発、ビジネス開発などの幅広い業務経験。この2つの幅広さを生かして記事をお届けします。
目次
先日より、数回にわたってクラウド型の仮想デスクトップの記事を書いています。
特定ベンダを推さない日記:仮想デスクトップ編(その1)
特定ベンダを推さない日記:仮想デスクトップ編(その2)
特定ベンダを推さない日記:仮想デスクトップ編(その3)
特定ベンダを推さない日記:仮想デスクトップ編(その4)
コスト削減、工期短縮、可用性向上、の3本立てのうち、その4では「コスト削減」について記載しました。
今回は残りの「工期短縮」と「可用性向上」について記載していきます。
VDI、すぐ使えるんでしょ!?
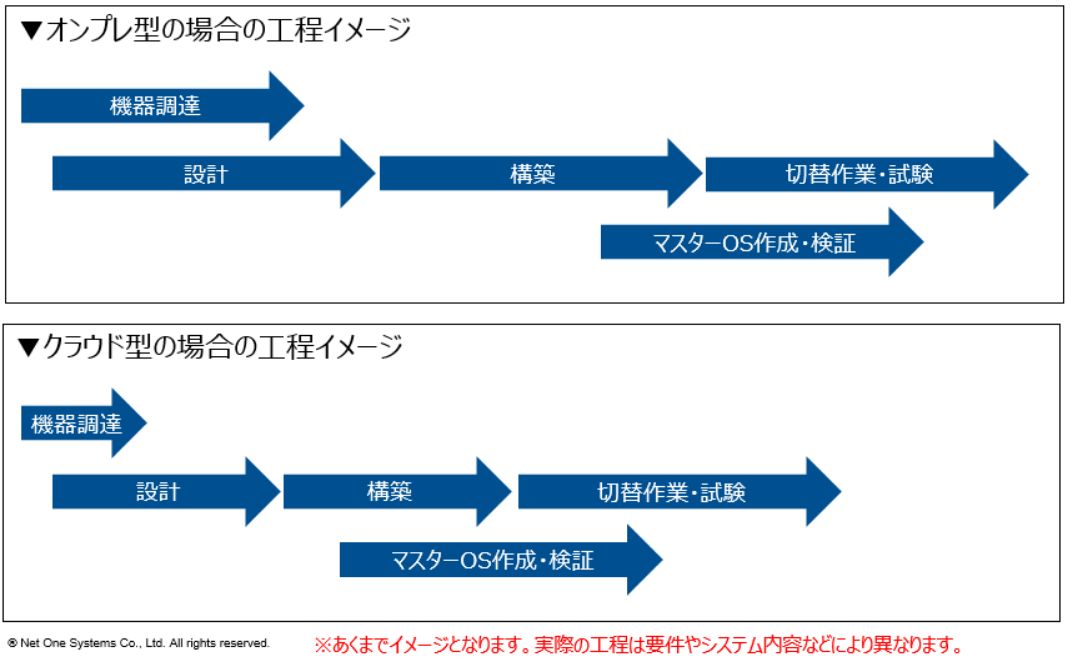
このトピックについては、正直に言って、諸説がありすぎるので、絶対にこうです、とは言えないのですが、下図のようなイメージをベースに、思ったほどすぐにVDIを利用できるわけではない、という認識を持っておいた方が安全だと思います。
従来の設計・構築においても、サーバ・ストレージ・ネットワークなどのハードウェアに費やす時間よりも、ADや、ユーザプロファイルや、VDIプールや、マスターイメージに費やす時間のほうが割合が大きかったかと思います(サーバ台数などの規模にもよりますが)。
また、なんといってもVDIの場合は、マスターイメージの作成とアプリケーションの動作確認に対して、それなりの時間をかける必要があります。この工程はクラウド型でも短縮することが難しい部分となります。
時間を要する工程がクラウド型になっても残存しており、加えてAzureなどのパブリッククラウドの場合は、RBACやハイブリッドAD構成など特有のセキュリティ関連の設計も加わってくるかと思います。
サービス、止まらないんでしょ!?
例えば、Horizon Cloudに影響が出たAzureのサービス障害として、以下の事例を挙げてみたいと思います。
(この記事自体は8月に書いています)
2020年7月1日 UTC 09時24分(JST 18時24分)
Azureの東日本リージョンにおいて、2020年7月1日のUTC 09時24分から11時15分までの間、Azure SQL Databaseの障害が発生しました。
Microsoft「Azureステータス履歴」
Tracking ID CLCK-LD0
https://status.azure.com/en-us/status/history/
同日 JST 19時ごろ
日本時間の19時ごろ、同僚よりHorizon Cloud管理コンソールにアクセスできない状態になっている旨の連絡を受けました。
この連絡を受け、Horizon Cloudを利用している全国のお客様の担当エンジニアに状況を確認してもらい、影響範囲の確認や原因の切り分けを進めていました。
管理コンソールだけでなく、新規のVDI接続が正常にできない、といった事象や、西日本でも同様の事象が発生している、といった情報も入ってきていました。
また、Horizon Clientでの接続は失敗するが、HTMLアクセスなら問題ない、といった情報もありました。
同日 UTC 13時24分(JST 22時24分)
UTC 13時24分、VMware社から、Horizon CloudがAzure Databaseの障害影響を受けていた旨の情報が公開されました。
ここまで、Azureで障害が発生してから4時間ほどの時間が経過していたことになります。
日本では水曜日の夜でしたが、4時間もの間、現場には確定情報が落ちてこず、混乱が起きていました。
VMware「Incident History」
https://status.horizon.vmware.com/incidents/cddw20w59b6x
共通認識と能動的な監視が必要!
ここで大事なことは、お客様とSIer双方で以下の認識を共有しておくことだと考えます。
まずは基本を確実に
- あらゆるクラウドサービスは停止することがある、という大前提を共有しておく
- 各社のサービス定義書などのドキュメント、特にSLA(Service Level Agreement)に関する記述をしっかり読み合わせて、年間停止時間や責任分界点に関する共通認識を持っておく
その上で、以前の記事にも記載しましたが、Microsoft社やVMware社からの報告を待つのではなく、監視システムを構築して、運用フローをあらかじめ決めておくなど、能動的にサービスの状態を把握して素早く対応できる仕組みを作っておくことが重要、と考えています。
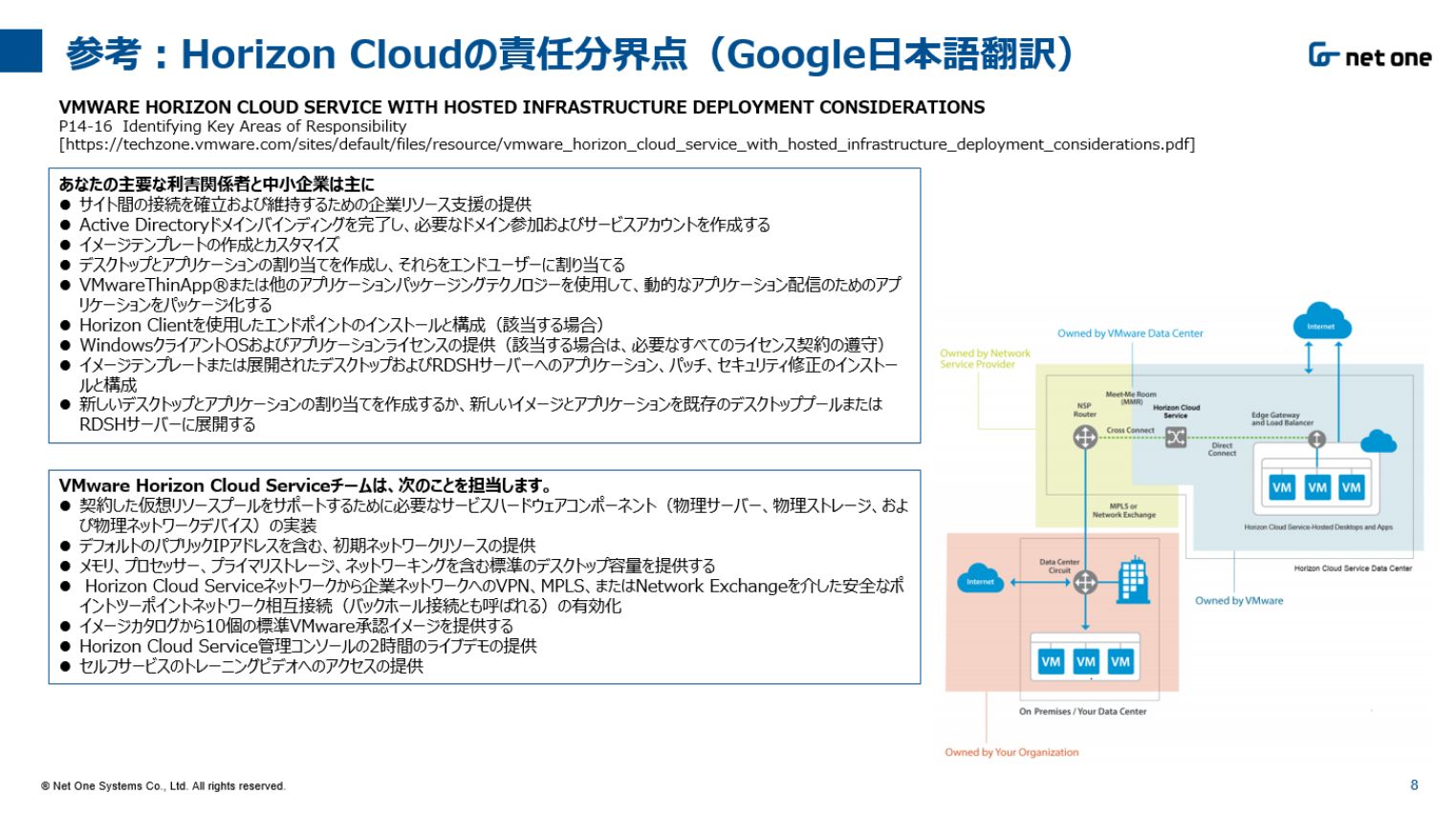
参考までにHorizon Cloudの場合の読み合わせ資料のサンプルを以下に載せておきます。
VMware「VMWARE HORIZON CLOUDSERVICE WITH HOSTED INFRASTRUCTURE DEPLOYMENT CONSIDERATIONS」
https://techzone.vmware.com/sites/default/files/resource/vmware_horizon_cloud_service_with_hosted_infrastructure_deployment_considerations.pdf
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


