
- ライター:片野 祐
- ネットワンシステムズに新卒入社し、PF, NW, SW, AIといった様々な製品、技術の担当として技術検証、提案導入支援、データ分析等を行ってきた。その後、よりお客様に近い立場でSW開発支援や自動化技術を中心とした案件推進活動を実施。現在は自動化技術を中心に扱うチームで製品担当やソリューション開発に従事。
目次
はじめに
これまで、「データ」の活用に関してブログ(①、②、③)や匠コラム(①、②等)で紹介してきました。関連する技術を追う中で、増え続けるデータをどのように扱うか、ということを最近よく考えるようになりました。データを貯めるたけでなく、貯めたデータをどのように活用するかも重要になります。社内でもデータに関する重要性の理解や関心は高まっており、今年度からは自社データ分析コンペが開催されるようになりました。
そこで今回のブログでは自社のデータ分析コンペの紹介と、コンペに参加した感想を綴ってみたいと思います。社内の取り組みの紹介を軽い気持ちで見ていただければと思います。
自社データ分析コンペの概要
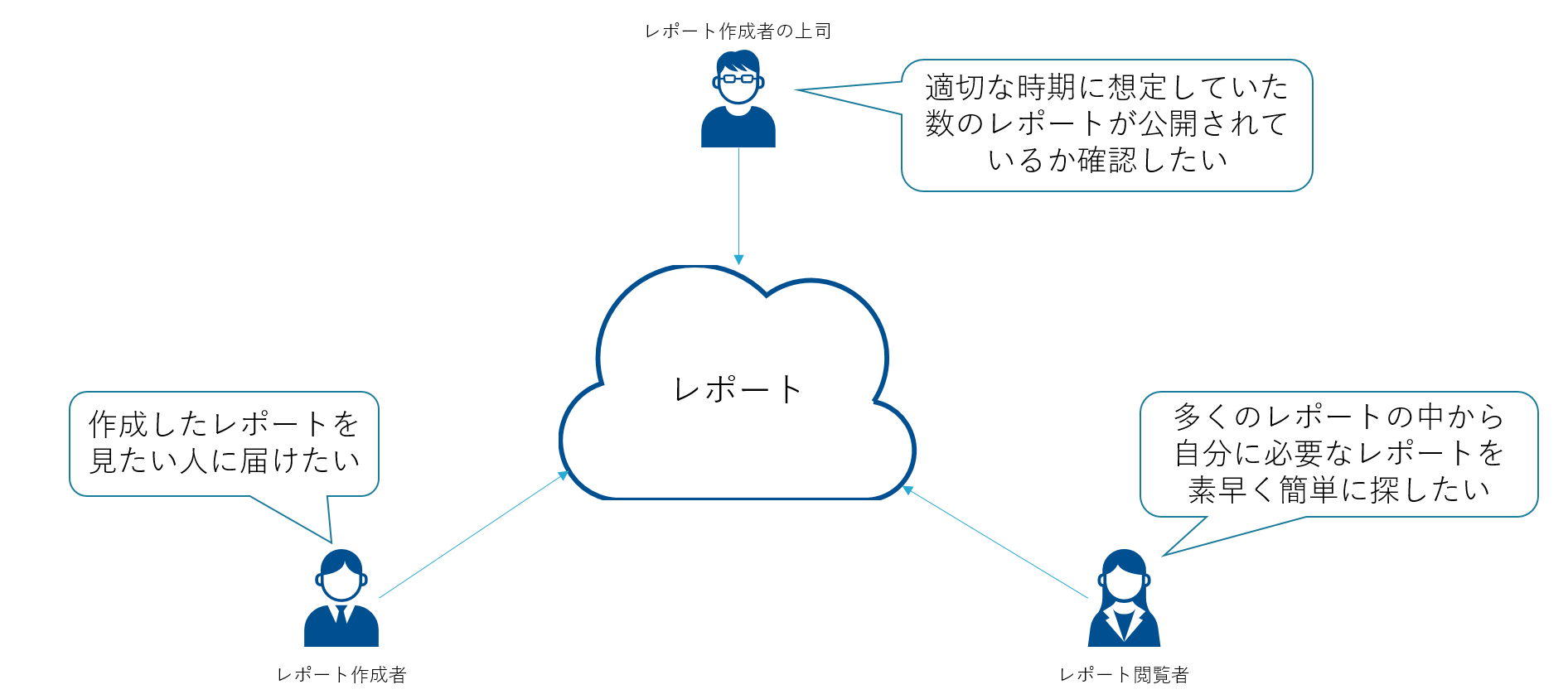
今回の課題は「社内技術レポートのテキスト分析・可視化」というものです。私が所属するビジネス開発本部では製品やソリューションの技術検証のレポーティングが業務の一つですが、その技術レポートが今回の分析対象となっています。いわゆる「テキストマイニング」です。分析のテーマは参加者が各自自由に設定でき、分析結果、考察をまとめて提出したあと、採点者が評価するという形式をとっています。今回はあらかじめ分析対象となるレポートの中身(テキスト)が抽出されており、抽出されたテキスト、id、レポートのタイトルの3つがまとめてあるCSVファイルが提供されました。私はコンペの参加にあたり4人でチームを組み、レポートの作成者視点と閲覧者視点を入れてどのように分析を進めていくか、何を目的に分析・可視化をするのか検討を始めました。
チームでの検討の結果、「レポート作成者は見たい人に正確にレポートを届ける、レポート作成者の上司はレポートの公開状況を把握できる、レポート閲覧者は見たいレポートを検索して早く見つける」ということを目的に進めることにしました。
「(日本語と英語を含んだテキストの)データ分析では(想像以上の)前処理(と継続的な処理と確認)が重要だ」
「データ分析では前処理が重要だ」ということは、よくわかっているつもりでしたが、今までやったことのなかったテキストマイニングでは想像を超えて様々な前処理と継続した処理が必要でした。以下はその一例です。
生データを見ることで理解が深まる
レポート内のテキストはあらかじめ抽出されていましたが、生データ(レポート自身)を見ることでわかることもあります。文字数が他のレポートよりも極端に多いものがあり、実際にレポートを見てみるとレポートにネットワーク機器のコンフィグが貼ってあることがわかりました。また、CSV形式で提供されたので私は迷わずMicrosoft Excelでファイルを開いたのですが、「1セルに32,767文字までしか入らない」という制約があることも初めて知りました。他にも文字コード等、分析に入るまでに確認することも多くありました。

日本語は難しい
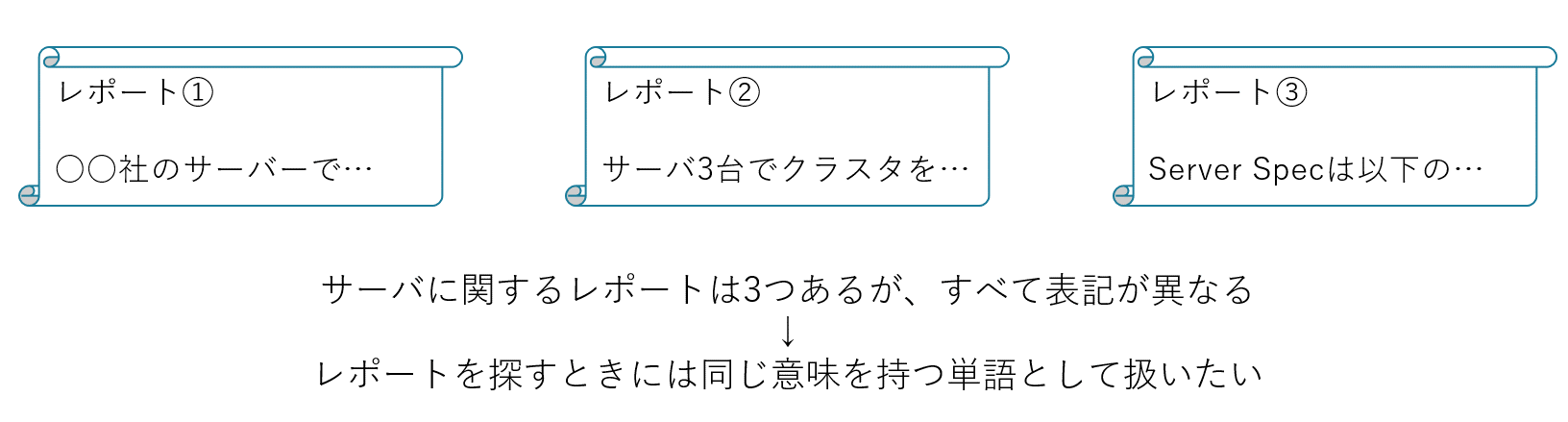
レポートは基本的には日本語で書かれるため、分析のために日本語に対する処理が必要になります。英語であれば単語と単語がスペースで区切られており、文章を単語で区切るのは簡単なのですが、日本語ではそうもいきません。そこで書かれているテキストに対して形態素解析をする必要があります。形態素解析によって抽出された単語に対してもいくつか処理をします。例えばIT業界ではよくある「サーバ」と「サーバー」、「コンピュータ」と「コンピューター」のような調音の処理であったり、「ネットワンシステムズ」と「ネットワン」、「NOS」のような表記は違えどすべて弊社を表している語をどうするかであったり、そういう単語を見つけては辞書登録する…といった地道な作業も必要でした。単語の処理のために品詞の種類も調べてみると想像を超える種類があり、普段使っている日本語が非常に難しく感じました。分析の途中で今の状態を知るために、可視化ツールを使うことも有効でした。また、そもそもレポートを提供する身として、誤字脱字に気を付けるという当たり前のこともレポートを探している人に正確に届けるためには必要なことだと感じました。
データを豊かにする
今回提供されたデータはテキスト、id、タイトルだったのですが、テキストを分析し始めると他の情報や比較対象が欲しくなりました。そこで提供されたデータ以外にも社内で公開されている情報をもとにデータを付与することにしました。例えばレポートの作成日を入れることで、古いレポートは検索対象に含めないことや、タグ付けをすることで技術領域等で検索できるようにすることを視野に入れて、データの付与をしていきました。タグはレポートの公開ページについていたのでそれを活用したのですが、各自が自由にタグを付けていたため、様々な粒度のタグがすでに100個以上ある状態でした。タグに一度しか使われていないようなものも多くあり、これでは付けたタグを有効活用することはできないので、タグの粒度を最初に決め、適切に付けるべきだと感じました。
分析の結果、何ができあがったか
社内のレポートデータを使っているため、具体的な分析結果をお見せできないのですが、分析結果のレポートとともに今後活用できそうなダッシュボードを作成しました。
レポート作成者視点
- レポート内に含まれる単語を抽出し、付けるべきタグの候補を表示できる
- 自分の作成したレポートを複数選択することで、自身のレポートでよく使われる単語や得意な領域が見える
レポート作成者の上司視点
- どの時期に何件レポートが出されたか把握できる
- 期初に立てた目標レポート数に対する現在の割合が見える
- 出されたレポート内でよく使われている単語、タグ一覧から公開したレポートの技術領域を表示できる
レポート閲覧者視点
- レポートでよく使われる単語、タグをクリックすると、見るべきレポートを表示できる
- 使われている単語のタグクラウドからレポートのトレンドがわかる
他にもやりたいことの構想はありましたが、コンペの終了日になってしまったため、ここで分析を終えることにしました。さて、このブログを書いている頃はまだコンペの結果待ちの状態です。果たして結果はどうなるのか、楽しみに待ちたいと思います。
おわりに
自分の技術領域の近くに「分析」や「検索」というものがあり、検索を生業にしている方々の話も聞いたことがあったので大変さはなんとなく知っていたのですが、実際にやってみると大変さが身に染みてわかりました。今回は分析対象となるデータ数もそれほど多くなかったのでまずは「見つけたい資料を見つける」ことに注力しましたが、資料が増えていくと「関連性の高い資料を上の方に表示させる」ことや「関連のありそうな資料をレコメンドする」ことが要望として挙がることが考えられ、検索を便利にするためにやりたいことは非常に多いと感じました。また、自分がよく使う検索サイトの裏で頑張っている人の苦労が少しわかった気がした、そんなコンペになりました。
※本記事の内容は執筆者個人の見解であり、所属する組織の見解を代表するものではありません。


